いろいろと賑わってるローカル上でのAI駆動、記事読んでる内に自分もやりたくなってきた
やはりトークン制限気にせず走らせられるのは強い!
…と思いひとまずやってみることに
必要なハードウェアスペックは?
こちらについてAI(ChatGPT/Claude/Gemini)間でディスカッションさせて聞いてみました(別環境のDify上で組んだワークフローによる)
以下AIの出した結論
最低限のスペック(小規模モデル向け)
- CPU:AMD Ryzen7/Intel Core i7以上
- RAM:32GB以上
- GPU:NVIDIA RTX 3060(12GB VRAM)以上
- ストレージ:1TB SSD(NVMe推奨)
- OS:Ubuntu 22.04 / Windows WSL2
推奨スペック(中~大規模モデル向け)
- CPU:AMD Ryzen9 / Intel Core i9以上
- RAM:64GB以上(128GB推奨)
- GPU:NVIDIA RTX 4090(24GB VRAM) / RTX 3090 / A6000 / H100など
- ストレージ:2TB NVMe SSD(モデルデータ保存用)
- OS:Ubuntu 22.04
やっぱりGPUだとNVIDIAのやつが必要なのかーとか思いながら、各モデルに個別にも聞いてみると、やはり
「CPUはRyzen7(3000シリーズ以降)かCore i7(第10世代以降)以上(9推奨)、最低でも8コア」
「GPUはVRAM 8GB以上、65B以上とかの大規模モデルなら24GB以上」
「NVIDIA GeForce RTXの3070~4090もしくはAMD Radeon RX6700XT~7900XT/XTX」
「メモリ(RAM)は最低でも16GB、65B以上とかの大規模モデルなら64GB以上」
「ストレージとしてはSSD 1GBは必要、NVMe推奨」
などと出てくる
なおこちらの環境
では今すぐ手元に用意できる環境はどんなものかな~、と改めて注文したときのメールを掘り起こしてスペックを確認してみる
GPUは入ってたなーとか、CPUもi7ではあったなーとか考えながら出てきたのは
- CPU:Intel Core i7-7700K
- RAM:16GB(8GB*2)
- GPU:NVIDIA GeForce GTX 1060 6GB
- ストレージ:250GB SSD(M.2ですらない)
- OS:Windows 10 Pro
…まあもう8年前に買ったやつだからなぁ
とはいえNVIDIAのGPUではあるし、小規模モデルならRAMは16GB・SSDは256GBでもいいってAIも言ってるし、7700Kでもi7ではあるし(コアは4しかないが)、とりあえずやってみっかぁ
手順
やり方自体はClaudeに書いてもらいました
SSDの残容量がやや心配(残り43GBくらいだった)がまあやってみる
TODOとしては
- Difyのクローンをローカルに作成する
- Docker Composeをインストールする
- WSLバックエンドをインストールする
- ローカルにOllamaのなんかしらのモデルを落として動かす(小規模モデルでいい)
この4つ
これができるよう聞いた結果、以下のようになった
実際のやり方
Windows 10でDifyとOllamaを両方セットアップするための手順を提示します。
Windows 10でDifyとOllamaをセットアップする完全ガイド
1. WSLバックエンドのインストール
1.1 WSLを有効化する
管理者権限でPowerShellを開き、以下のコマンドを実行します:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
1.2 仮想マシン機能を有効化する
同じく管理者権限のPowerShellで以下のコマンドを実行します:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
1.3 システムを再起動します
1.4 Linux カーネル更新パッケージをダウンロードしてインストールする
以下のリンクからLinuxカーネル更新パッケージをダウンロードしてインストールします: WSL2 Linux カーネル更新パッケージ
1.5 WSL 2 を既定のバージョンとして設定する
管理者権限のPowerShellで以下のコマンドを実行します:
wsl --set-default-version 2
1.6 Linux ディストリビューションをインストールする
PowerShellで以下のコマンドを実行してUbuntuをインストールします:
wsl --install -d Ubuntu
1.7 インストールしたLinuxディストリビューションを起動し、ユーザー名とパスワードを設定します
2. Docker Desktopのインストール(Docker Compose含む)
2.1 Docker Desktopのダウンロード
以下のリンクからDocker Desktopをダウンロードします: Docker Desktop for Windows( → https://desktop.docker.com/win/main/amd64/Docker Desktop Installer.exe)
2.2 インストーラーを実行
ダウンロードしたインストーラーを実行し、指示に従ってインストールを完了します。 インストール時に「Use WSL 2 instead of Hyper-V」オプションが選択されていることを確認してください。
2.3 インストール完了後、システムを再起動します
2.4 Docker Desktopを起動
スタートメニューからDocker Desktopを起動します。初回起動時には設定が行われます。
2.5 WSL 2バックエンドの確認
Docker Desktopの設定(Settings)から「General」を選択し、「Use the WSL 2 based engine」にチェックが入っていることを確認します。
2.6 Docker Composeが正しくインストールされたか確認
PowerShellまたはコマンドプロンプトを開き、以下のコマンドを実行してDocker Composeのバージョンを確認します:
docker-compose --version
3. Difyのクローンをローカルに作成
3.1 Gitのインストール
まだGitをインストールしていない場合は、以下のリンクからダウンロードしてインストールします: Git for Windows
3.2 Difyのソースコードをクローン
PowerShellまたはコマンドプロンプトを開き、以下のコマンドを実行してDifyの最新安定版をクローンします:
# 例として最新バージョン0.15.3を指定してクローンします
git clone https://github.com/langgenius/dify.git --branch 0.15.3
3.3 環境設定ファイルの準備
クローンしたDifyのdockerディレクトリに移動し、環境設定ファイルをコピーします:
cd dify/docker
copy .env.example .env
3.4 Dockerコンテナの起動
同じディレクトリで以下のコマンドを実行してDockerコンテナを起動します:
# Docker Compose V2の場合
docker compose up -dまたは
bash
# Docker Compose V1の場合
docker-compose up -d
3.5 コンテナの状態確認
以下のコマンドでコンテナが正常に起動しているか確認します:
docker compose ps
3.6 Difyへのアクセス
ブラウザで以下のURLにアクセスして初期設定を行います:
http://localhost/install
初期設定が完了したら、以下のURLでDifyにアクセスできます:
http://localhost
4. Ollamaのセットアップと実行
4.1 Ollamaのインストール
PowerShellを管理者権限で開き、以下のコマンドを実行します:
# Ollamaのインストーラーをダウンロード
Invoke-WebRequest -Uri "https://ollama.com/download/ollama-windows-amd64.zip" -OutFile "ollama.zip"
# ダウンロードしたZIPファイルを解凍
Expand-Archive -Path "ollama.zip" -DestinationPath "C:\Ollama" -Force
# 環境変数PATHにOllamaのパスを追加
$env:Path += ";C:\Ollama"
[Environment]::SetEnvironmentVariable("Path", $env:Path, [EnvironmentVariableTarget]::User)
4.2 Ollamaサービスの起動
PowerShellで以下のコマンドを実行してOllamaサービスを起動します:
# 新しいPowerShellウィンドウを開いてOllamaサーバーを起動
Start-Process powershell -ArgumentList "-NoExit", "-Command", "cd C:\Ollama; .\ollama.exe serve"
4.3 モデルのダウンロードと実行
別のPowerShellウィンドウを開き、以下のコマンドを実行してモデルをダウンロードします(例としてllama2を使用):
# llama2モデルをダウンロード
ollama pull llama2
# モデルを実行してテスト
ollama run llama2
モデルが起動したら、プロンプトにテキストを入力して応答を確認できます。例えば「Hello, how are you today?」と入力してみてください。
4.4 Ollamaの設定とDifyとの連携(オプション)
Ollamaが正常に動作していることを確認したら、Difyの設定画面でOllamaをLLMプロバイダーとして追加できます:
Difyの管理画面にログイン「Settings」→「Model Providers」に移動「Add Provider」→「Ollama」を選択エンドポイントURLを設定(通常は http://localhost:11434 または http://host.docker.internal:11434)利用可能なモデルを選択(例:llama2)
- トラブルシューティング
- WSLの問題: wsl --status コマンドでWSLの状態を確認できます
- Dockerの問題: Docker Desktopのログを確認し、必要に応じて再起動してください
- Ollamaの問題: ファイアウォール設定を確認し、必要なポート(11434)が開放されていることを確認してください
- Difyの問題: Dockerログを確認するには docker compose logs コマンドを使用します以上の手順に従うことで、Windows 10環境でDifyとOllamaを両方セットアップして実行することができます。
迷ったところ
Difyのクローンをどこに置くか
上記の3.2「Difyのソースコードをクローン」について、どこのディレクトリで git clone するかについて迷った
こちらについて聞いてみたところ、
WSL2のLinuxファイルシステム内(ホームディレクトリ)にクローンすることで、パフォーマンスの問題や権限の問題を避けられます
と出た。
なので以下のようにした
# WSL2を起動
wsl
↓
#起動したWSL中で以下を実行する
cd ~
mkdir dify-project
cd dify-project
git clone https://github.com/langgenius/dify.git
Dokerコンテナ起動
上記の3.4「Dockerコンテナの起動」について、コマンドを実行したところ
nginx Error failed to resolve reference "docker.io/library/nginx:latest": failed to aut...
(省略)
Error response from daemon: failed to resolve reference "docker.io/library/nginx:latest": failed to authorize: failed to fetch oauth token: unexpected status from GET request to https://suth.docker.io/token?scope=repository%3Alibrary%2Fnginx%3Apull&service=registory.docker.io: 401 Unauthorized
となり、Docker Hubからのイメージpullに認証エラーが生じた
これは単にDocker Desktopを閉じてしまっていたのが原因だったので、再度開き直してログインすることで解決した
Ollamaサーバの起動
4.2「Ollamaサービスの起動」について、コマンドを実行したところ
Couldn't find "C:/Users/(自分のユーザ名)/.ollama/id_ed~". Generating new private key.
Your new public key is:
ssh-ed~ (以降sshキー)
(後略)
という感じのメッセージが表示された状態のままになった
これは単にOllama初回起動時のSSHキー生成メッセージであるということであり、開いたままにしておけば問題ないとのこと
(閉じるとOllamaサービスが停止するので、もし閉じてしまえば起動し直す必要がある)
ここまでやって、 http://localhost/ にアクセスすることでローカルのDifyにアクセスできるようになる
通常のDifyのように、ユーザ登録をすれば、次から http://localhost/signin より入れるようになっている
Dify、Ollamaの再起動
一度PCを閉じ、後日クローン済みのものを再度動かしたいとなるとどうやればいいかについて
1. WSL再起動
wsl
2. WSLでDifyのディレクトリに移動
cd ~
cd dify-project/dify
3. Dockerコンテナの起動
docker composer -f docker/docker-compose.yaml up -d
4. Ollamaサービスの再起動
#落としたOllamaのモデル全てが立ち上がる
ollama serve
これに加え、Docker Desktopをメニューなどから起動しておけば、 http://localhost/signin より再度ローカルDifyに入れる様になる
Ollamaよりモデルのダウンロード
結局は以下のコマンドで、 Gemma3の4B と Qwen2.5-coderの3Bをダウンロードした
ollama pull gemma:4b
ollama pull qwen2.5-coder:3b
ダウンロードしたモデルの追加
上記で追加したモデルについて、設定してやらないと使えない
これについては、右上メニューを開き、「設定」>「モデルプロバイダー」と進んでここで設定する
まずは「モデルプロバイダーをインストールする」より「Ollama」を追加する
ここにモデルを追加することで設定ができる
上に先ほどインストールしたOllamaが出てくるので、「モデルを追加」からモデルを追加する
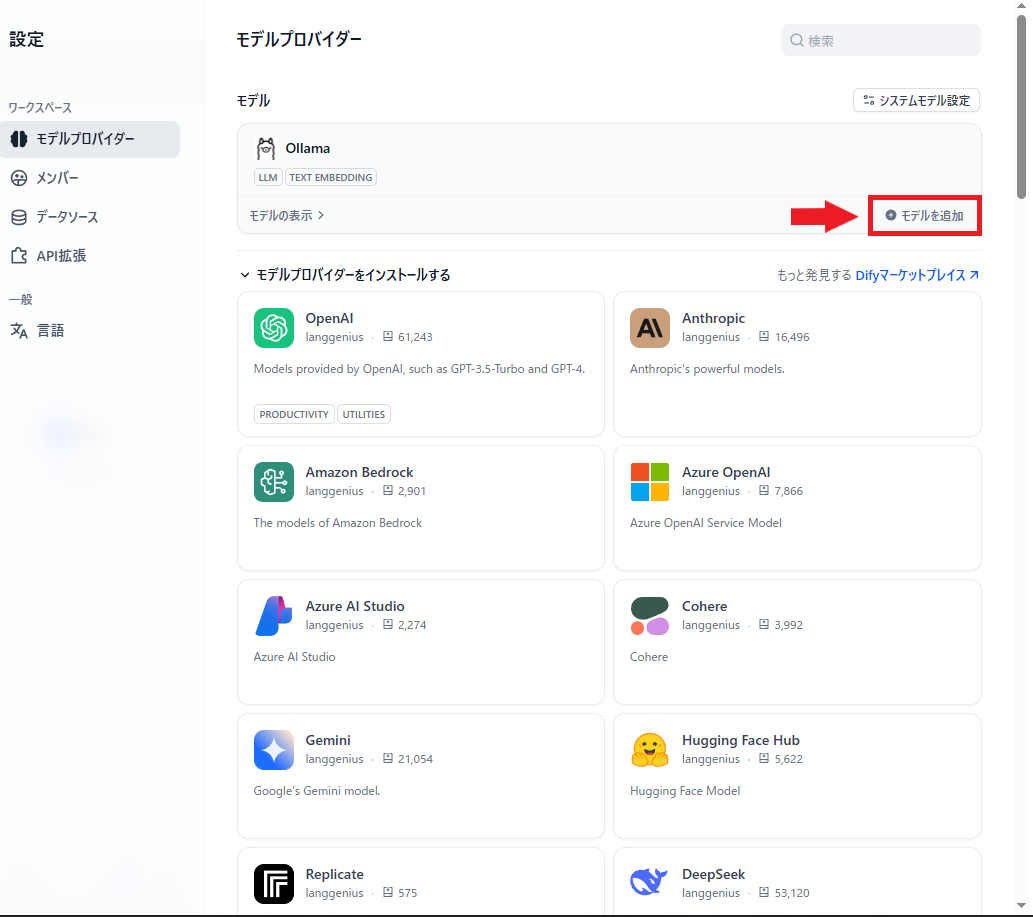
設定方法としては、「Model Name」にダウンロードしたときのコマンドと同じ名前で、Base URLには http://host.docker.internal:11434/ をそれぞれ設定すればいい
(他はまあお好みで)
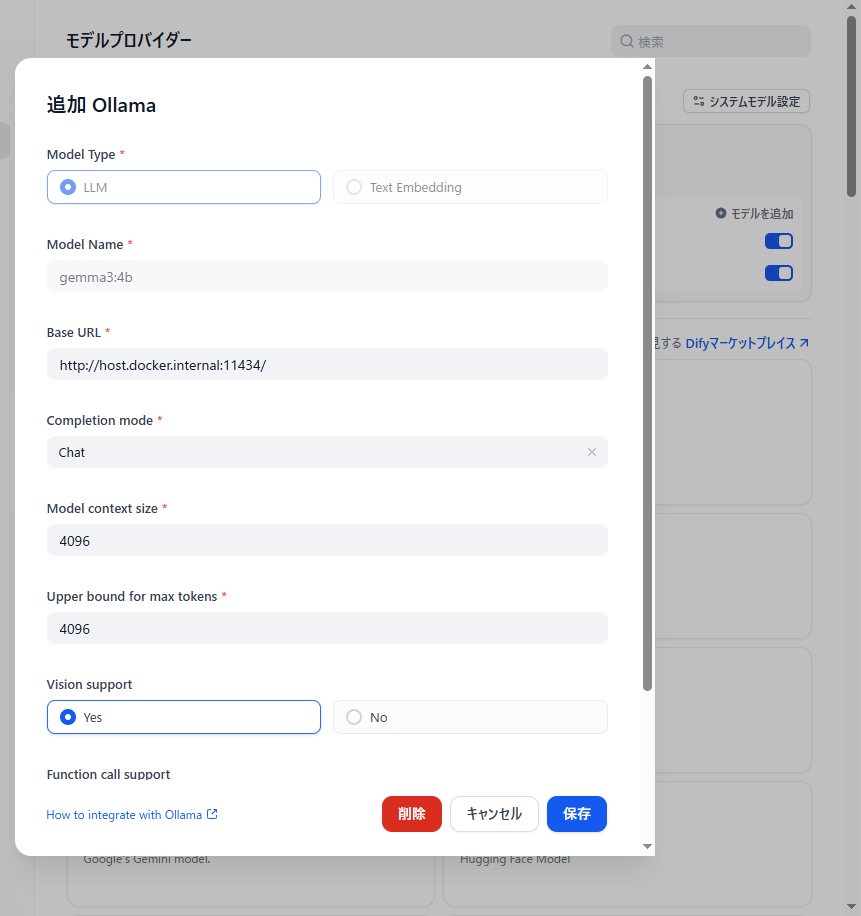
Gemma3:4bの例
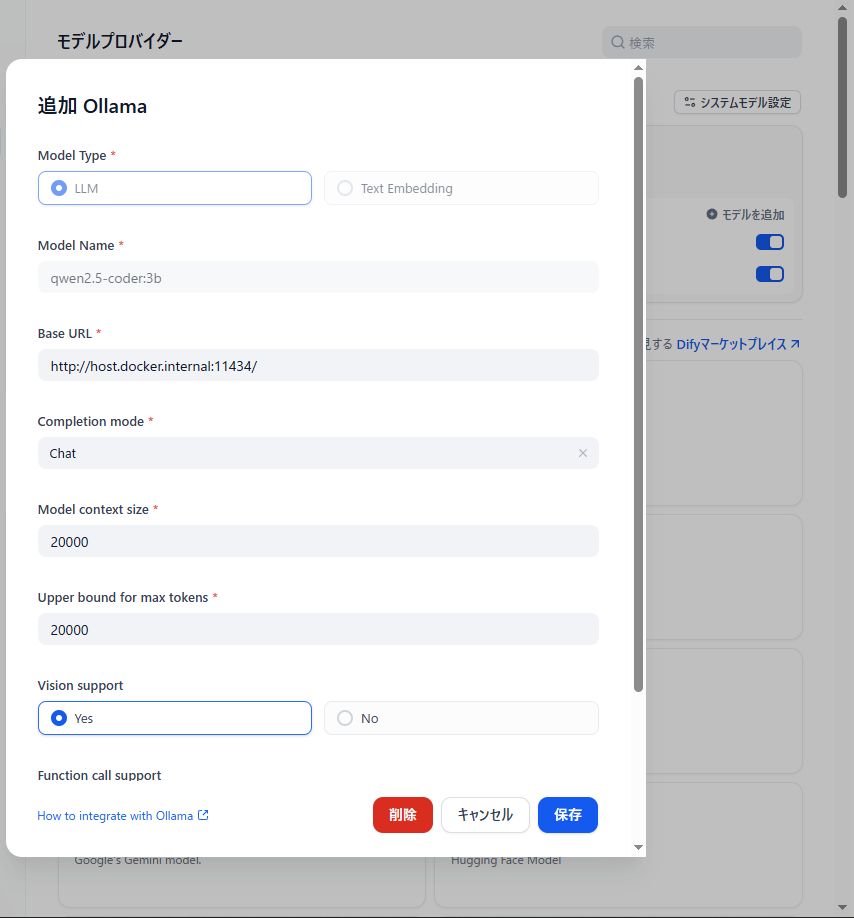
qwen2.5-coder:3bの例
URLは同じでOK、Model Nameの設定がちゃんとしていれば適切なモデルにリクエストが飛ぶとのこと
通信テスト
設定したモデルに対し、ちゃんとこちらの指示が飛び、返答を返してくれるのかを試してみる
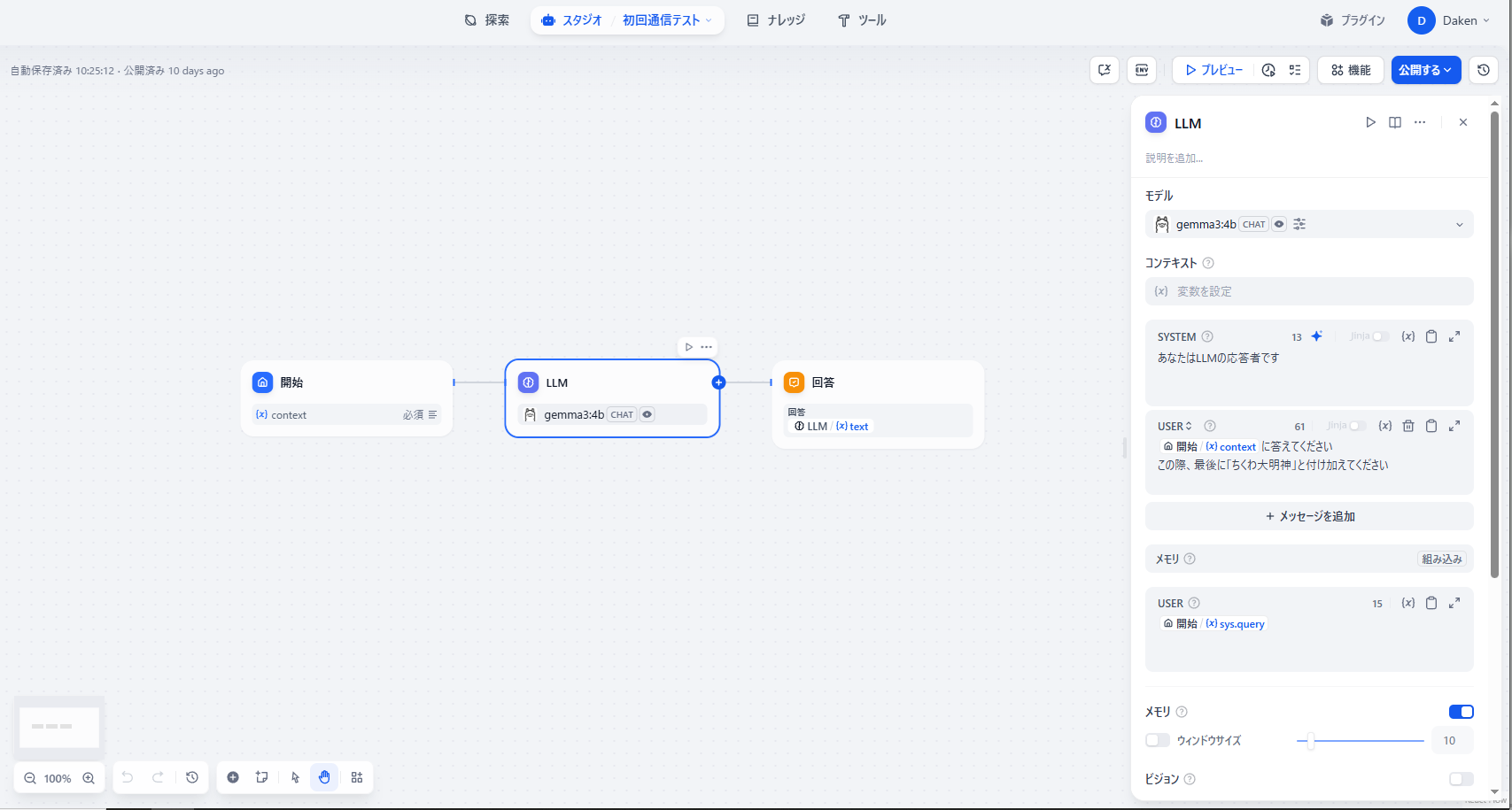
簡単なチャットフローとして、設定したモデルを「LLM」ブロックに設定し、そこに質問を飛ばして返すだけのものを用意する
これに対して何かしらの質問を投げ、適切な質問が返ってくることを確認する
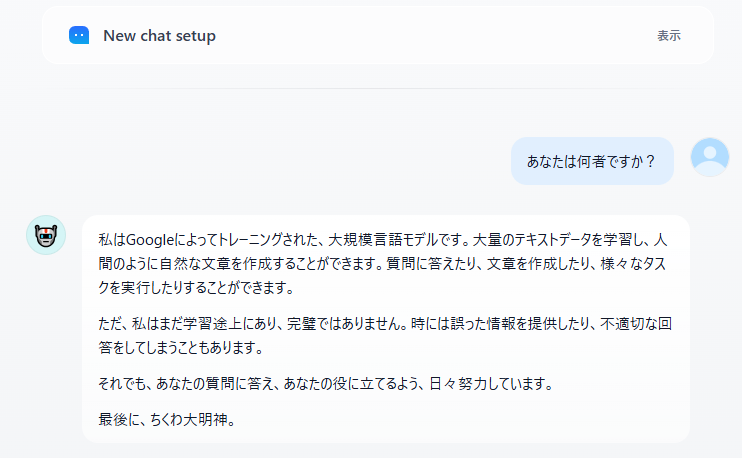
簡単な質問として、「あなたは何者か」を聞いたもの
GemmaがGoogle開発のモデルであったはずなので、ちゃんと答えが返っている
(最後につけたワードは、ちゃんと↑のチャットフロー中にあるLLMブロックを通っていることを確認するために、ここの「USER」項でつけた注文に対応するもの。意図とはやや異なるが、注文通りになっており、ちゃんとこのチャットフローを通しての回答であることがわかる)
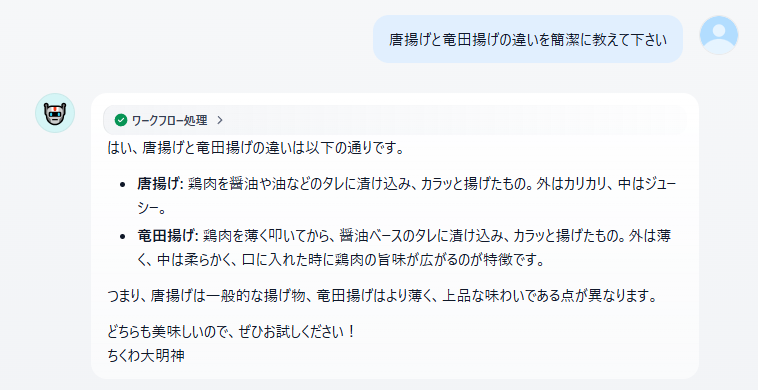
試しにもう一点くらい聞いてみる
今日の晩飯に唐揚げだったので、作ってるとき浮かんだ疑問を聞いてみた
実際にネットで調べてみると「明確な違いはないが、衣に使われるのが小麦粉か片栗粉か、あるいは下味をつけないかつけるか(ただしこれは昔のものであり、今だと唐揚げでも下味はつける)」らしいので、ややズレた答えが返ってきている気はする
不安があったのでもう一点くらい
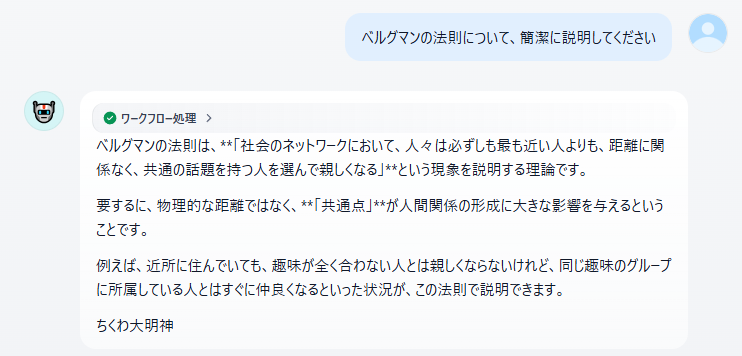
何言ってんだお前
このズレ具合は初期のChatGPTを思い出す感じはするので、実際使うならRAGでなんとかするとか、ネット検索挟むとかする必要があるかもしれない
とはいえ、「自分の(8年前の低スペックの)マシン上でLLM動かす」が実現できたので一旦ヨシ!
使い方はこれから考えるか
ちなみに43GBあった残り容量は15.5GBまで減った
パーセンテージだと残り10%切ってるが、まあ数値的にはまだ大丈夫だろう