What is this?
- 自然言語処理の超初心者である筆者が(ほぼ)はじめて形態素解析してみました
-
spaCy + GiNZAを利用して実施してみました
- 想像以上に簡単にできました!
- はじめてにしては上出来なレベル
実施環境
- Debian GNU/Linux 10
- Python: 3.9.1
- ginza:4.0.5
spaCyとは?
オージス総研によるオブジェクトの広場での解説が個人的にわかりやすかったため、引用させていただきました。
spaCy は Explosion AI 社の開発する Python/Cython で実装されたオープンソースの自然言語処理ライブラリで MIT ライセンスで利用が可能です。多くの言語をサポートし、学習済みの統計モデルと単語ベクトルが付属しています。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.html より引用)
名前の通り、Cythonで実装されているんですね。また、同記事内のspaCyの構造図に関しても、細かくは理解できていないものの、わかった気になれます。

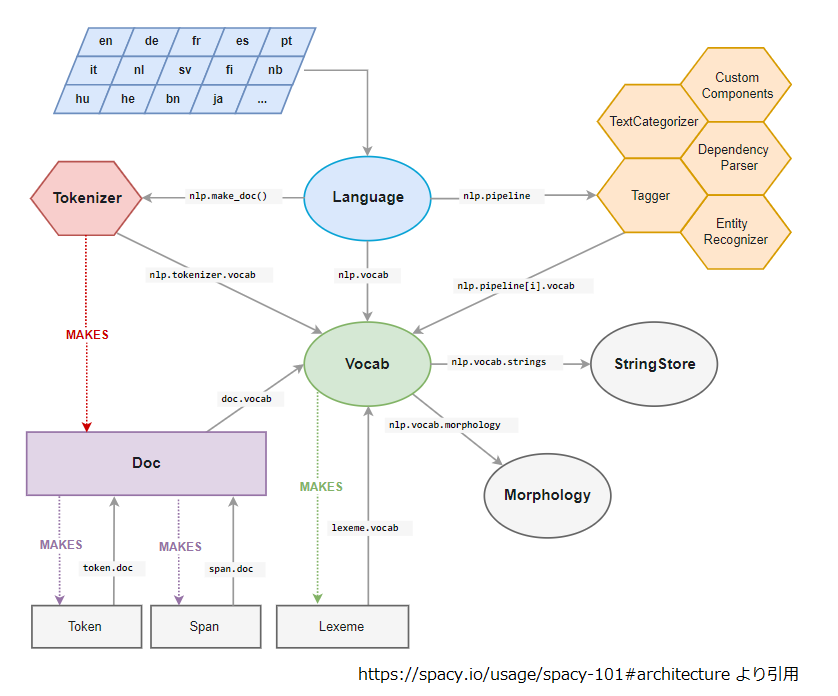
ただし、GiNZAが登場するまでは、日本語を解析する際に工夫が必要だったようです。
しかし最近まで spaCy の学習済みモデルには日本語に対応したものがなく、バックエンドに MeCab を用いた形態素解析ができる程度でした。その為、spaCy を利用して記述された自然言語処理のアプリケーションやライブラリでは日本語の文書を処理することができない状況が続いていました。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.html より引用)
GiNZAとは?
こちらも同記事の解説がわかりやすいです。
ここで、2019年4月にリクルートと国立国語研究所の研究成果である GiNZA が登場します。主な特徴をリクルート社のリリース*1から引用すると、
- 高度な自然言語処理をワンステップで導入完了
- 高速・高精度な解析処理と依存構造解析レベルの国際化に対応
- 国立国語研究所との共同研究成果の学習モデルを提供
とのことで、早い話が spaCy を日本語で利用できるようになった!pip install 一発でインストールできるので導入も簡単!!ということでよいかと思います。
(https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part4.htmlより引用)
なお、scaPyとGiNZAの関係性としては、GiNZAは上記scaPyの構造における図内では"Language"にあたる機能を提供しているようです。
余談ですが、spaCyを始めようと思って調べ始めたら、GiNZAというのが出てきたので、思考停止でそのままGoogle検索したら「銀座 日本 東京の地名」が検索結果で表示されました。そりゃそうですよね。
実行環境のセットアップ
なにかと環境構築に躓きやすいイメージのある自然言語ですが、私の環境ではpipにて簡単に構築することができました!
pip install -U ginza
*実際にはDocker環境にてrequirements.txtにspacyとginzaを記載してインストールを行いましたが、問題なく動作しました。
使い方
こちらを参考に実行しました。
https://note.com/npaka/n/n5c3e4ca67956
import spacy
import ginza
import pandas as pd
nlp = spacy.load('ja_ginza') # spacyにginzaを使用することを指定
txt = '私は機械学習を勉強しています。' # 入力文字列
doc = nlp(txt) # モデルへ適応
ginza.set_split_mode(nlp, "C") # 形態素の分割モード指定
# 結果をデータフレームに格納
result_list = []
for sent in doc.sents:
result_list = result_list + [[str(token.i), token.text, token.lemma_, token.pos_, token.tag_] for token in sent]
df_result = pd.DataFrame(result_list, columns = ['token_no', 'text', 'lemma', 'pos', 'tag'])
doc.sentsにて各文のイテレータを取得します(今回の例は1文なので、要素は1つです。)。また、sent自身をさらにループに回すことで各単語での要素を取得できます。
結果
今回はデータフレームに結果を格納したため、このようなテーブルが出力されます。
| token_no | text | lemma | pos | tag |
|---|---|---|---|---|
| 0 | 私 | 私 | PRON | 代名詞 |
| 1 | は | は | ADP | 助詞-係助詞 |
| 2 | 機械学習 | 機械学習 | NOUN | 名詞-普通名詞-一般 |
| 3 | を | を | ADP | 助詞-格助詞 |
| 4 | 勉強 | 勉強 | VERB | 名詞-普通名詞-サ変可能 |
| 5 | し | する | AUX | 動詞-非自立可能 |
| 6 | て | て | SCONJ | 助詞-接続助詞 |
| 7 | い | いる | AUX | 動詞-非自立可能 |
| 8 | ます | ます | AUX | 助動詞 |
| 9 | 。 | 。 | PUNCT | 補助記号-句点 |
特に違和感なく、形態素解析ができているかと思います。自然言語処理の素人として感じたことは、「勉強する」の「勉強」という部分が名詞タグだけれども、文の中では動詞として認識されていることが、すごいなと感じました。