はじめに
今回はTransformerで使用されている技術についてまとめておきます.
初めは自然言語処理に用いられていた構造ですが,画像分野でも大活躍中です.
なかなかとっかかりにくい分野ですが,単純なDeepLearning は一通り学べたという人は是非Transformerについて勉強しておきましょう![]()
今回はPowerPointの画像をペタペタ+αちょこっと説明という形式です.
1 Attention
下図のような🐶の画像があったときに人は背景を無視して🐶だけを注目できますが,CNNでは画像全体に同じ処理を繰り返すため,そういったことはできません.
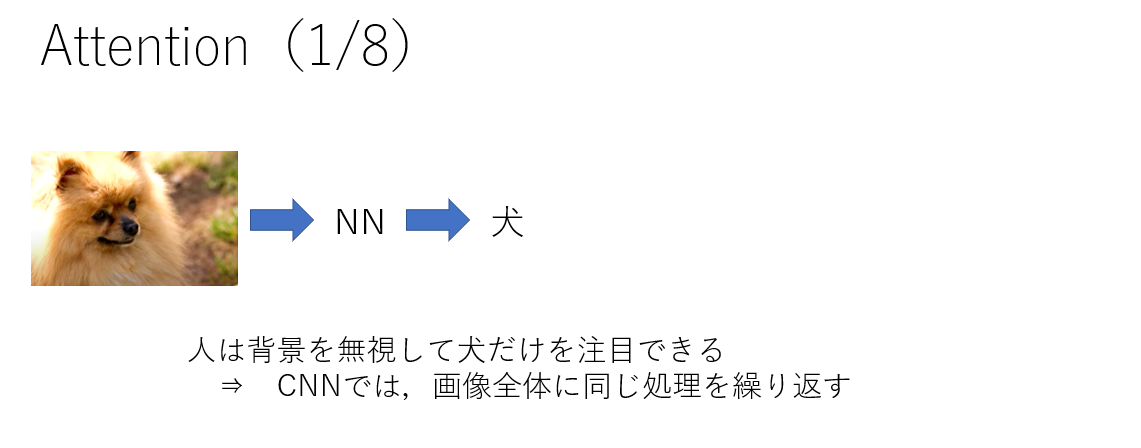
例えば,以下のような流れのモデルがあるとして,GAPでは背景も含めて画像全体の特徴を平均化します.
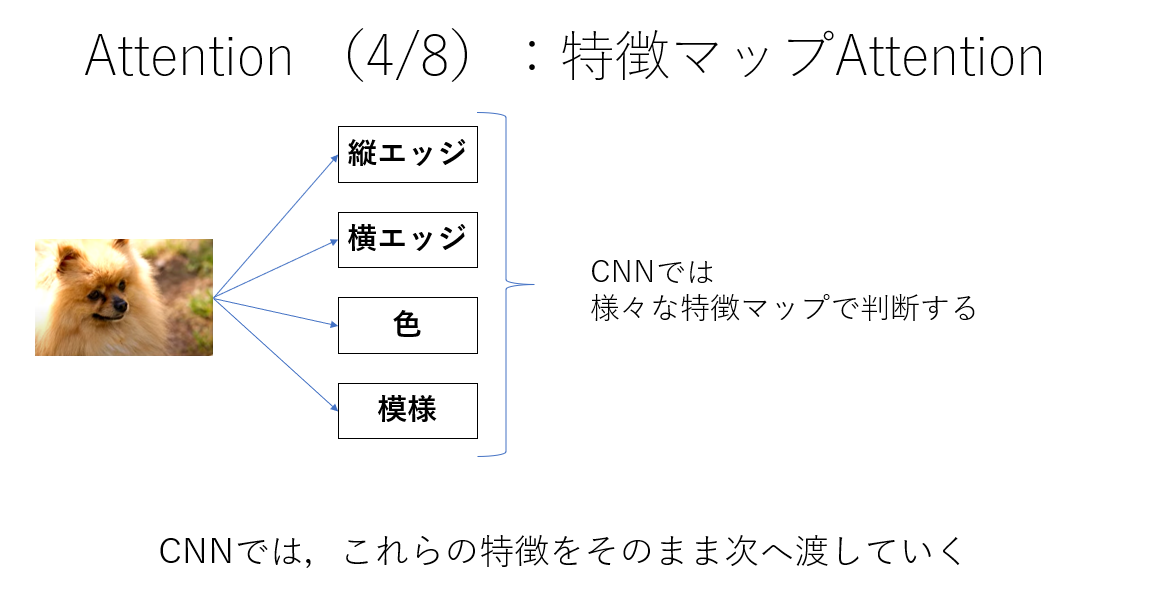
勿論大量のデータを使うことで,前景のみを注目するようにはなりますが,CNNで表現するには学習が難しくなっちゃってるんじゃない?という問題があります.
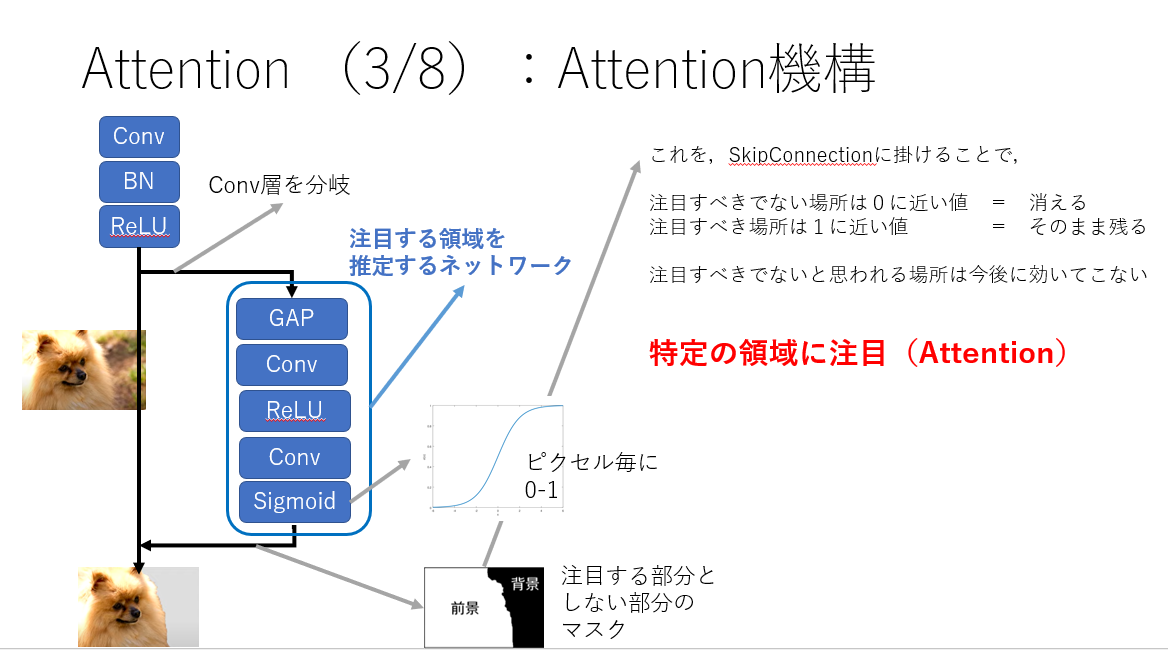
そこでAttentionが出てきます![]() Atetntionを用いると,明示的に特定の画像個所に注目するようことをNN上で実現することができます.
Atetntionを用いると,明示的に特定の画像個所に注目するようことをNN上で実現することができます.

一番簡単なAtetntionの例です.そのまま進むのはSkipConnectionです.こういった処理を行うことで,背景はこれより後には効いてこなくなるわけです.
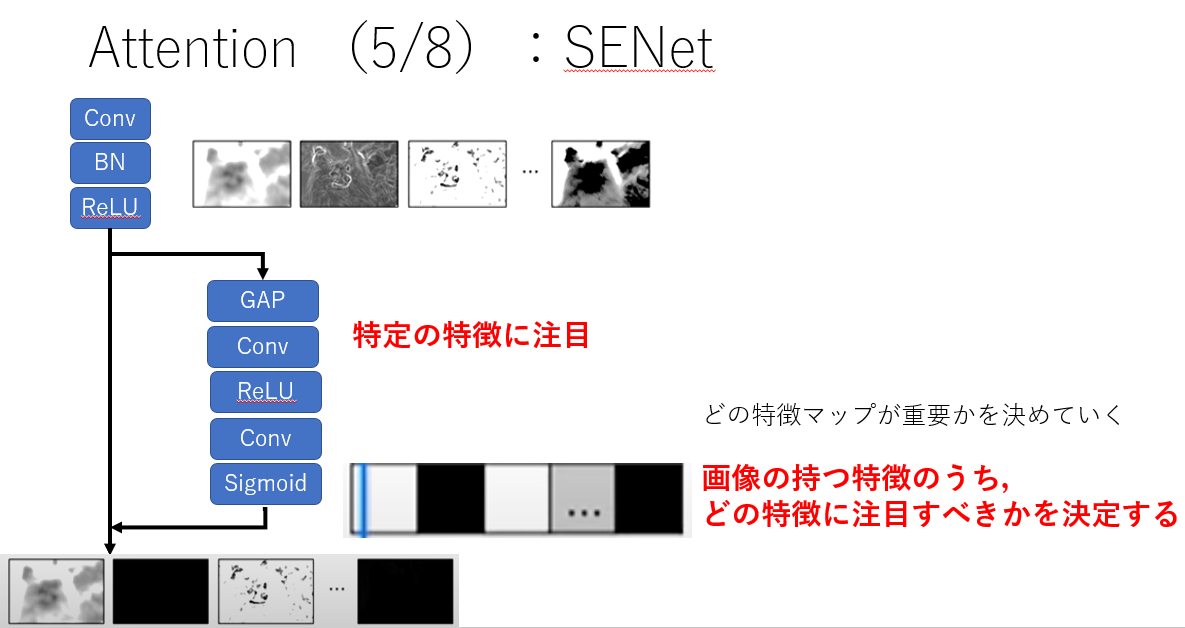
画像の特徴マップでのAttention,SENetを紹介します.画像のもつ複数の特徴からどの特徴に注目するかを決定します.
Attentionを式で考えます.Qは入力,KとVは対応すべき出力からきています.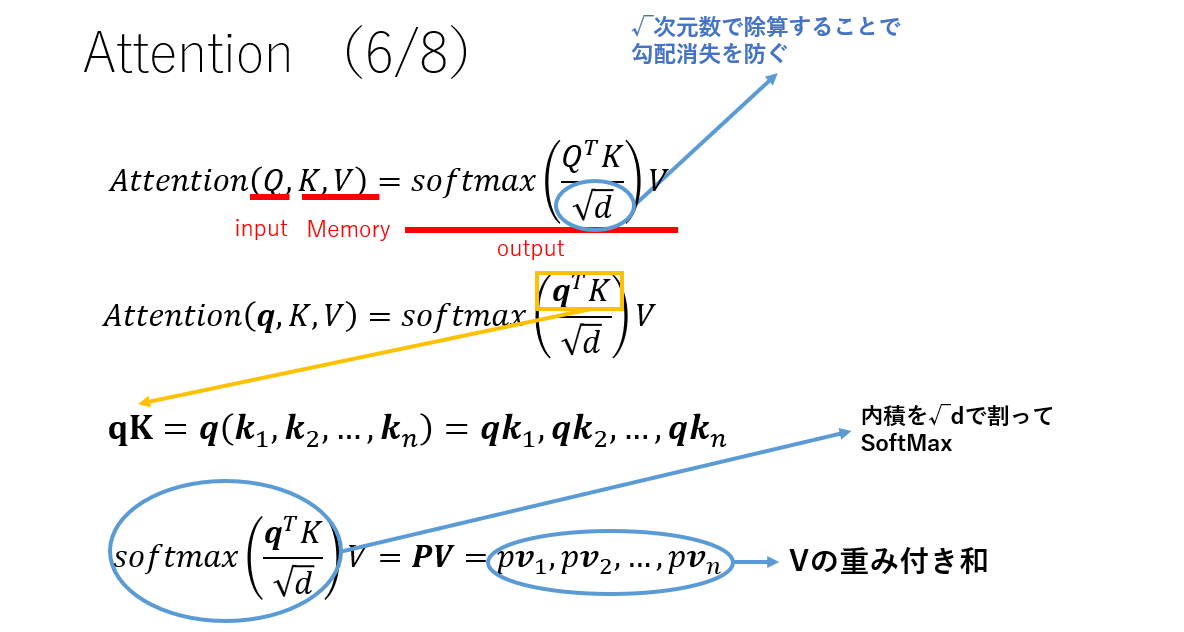
…なるほど.まったくわからん.➡ 図で考えましょう.
使うパラメータはQ, K,Vの3つです.Qは入力から,KとVは対応する出力から決定されます.
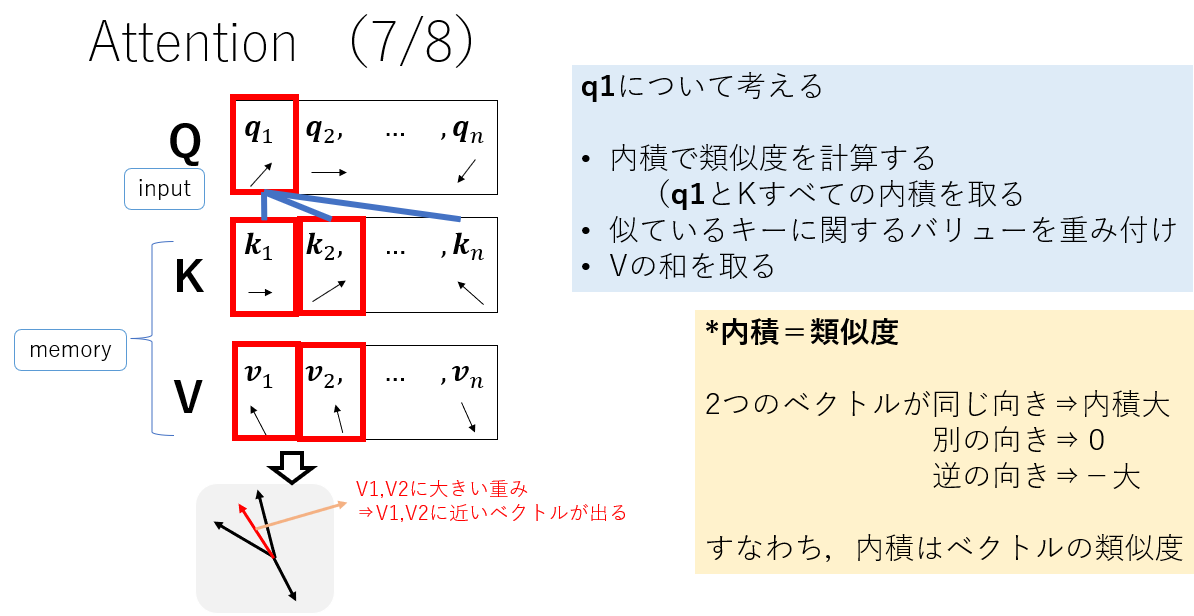
下図でq1についてを考えてみましょう.
- まず,内積ですべてのKとの類似度を計算します.今回はq1に対してk1とk2が似ており,knは似ていません.
- 次に,似ているキーに関するバリューを重み付けします.k1とk2が似ていたので,ここの部分の重みが大きくなります.
- 最後にバリューの重み付き和を取ります.すると,これらの計算によって出てくるのは,v1+v2に近いベクトルになります.
これでクエリに対するバリューが検索され,出力されたということになります.
なんで対応すべき出力をKとVに分けんの?という点ですが,注目する点を決定するためのK(キーベクトル),最終的に利用される値を示すV(バリューベクトル)を分けることでより表現力が出て,精度が良くなるといわれています.

2 Self Attention
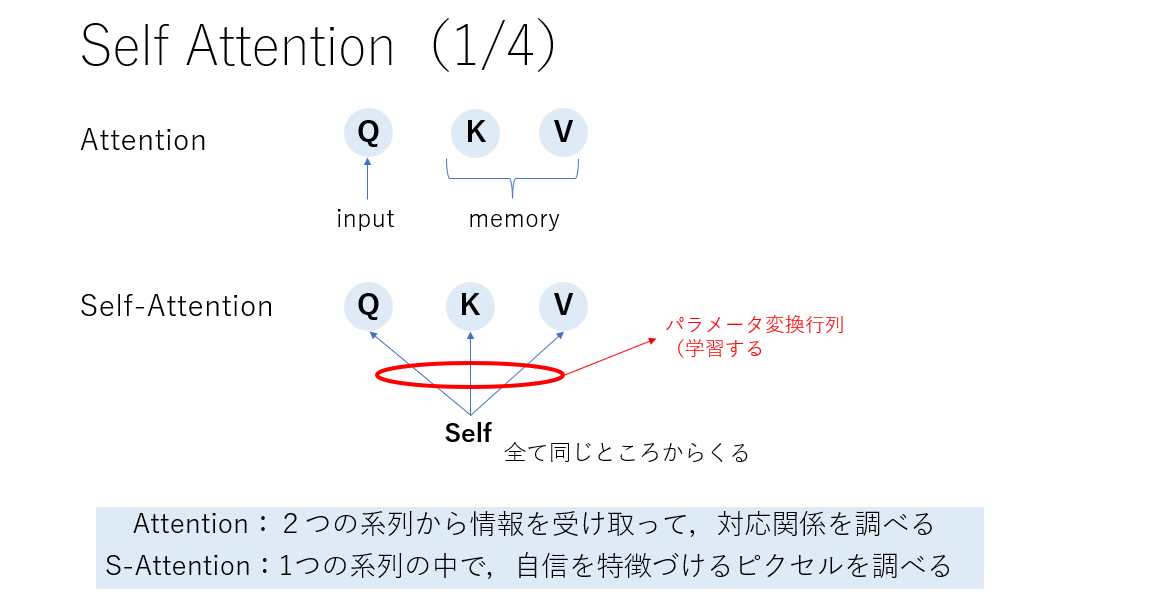
Attentionは,QはInputから,KとVはMemoryからですが,SelfAttentionでは,それらすべてが同じ場所から来ます.(それぞれに対してパラメータ変換行列を適用するので,別の値にはなります.)
SelfAttentionを使用することで,自分自身の中でどことどこが関係しているかの依存関係を捉えることができます.
では,これについてより詳細に考えていきましょう.
画像だと説明しにくいので自然言語で考えます.画像だと,単語がパッチになります.
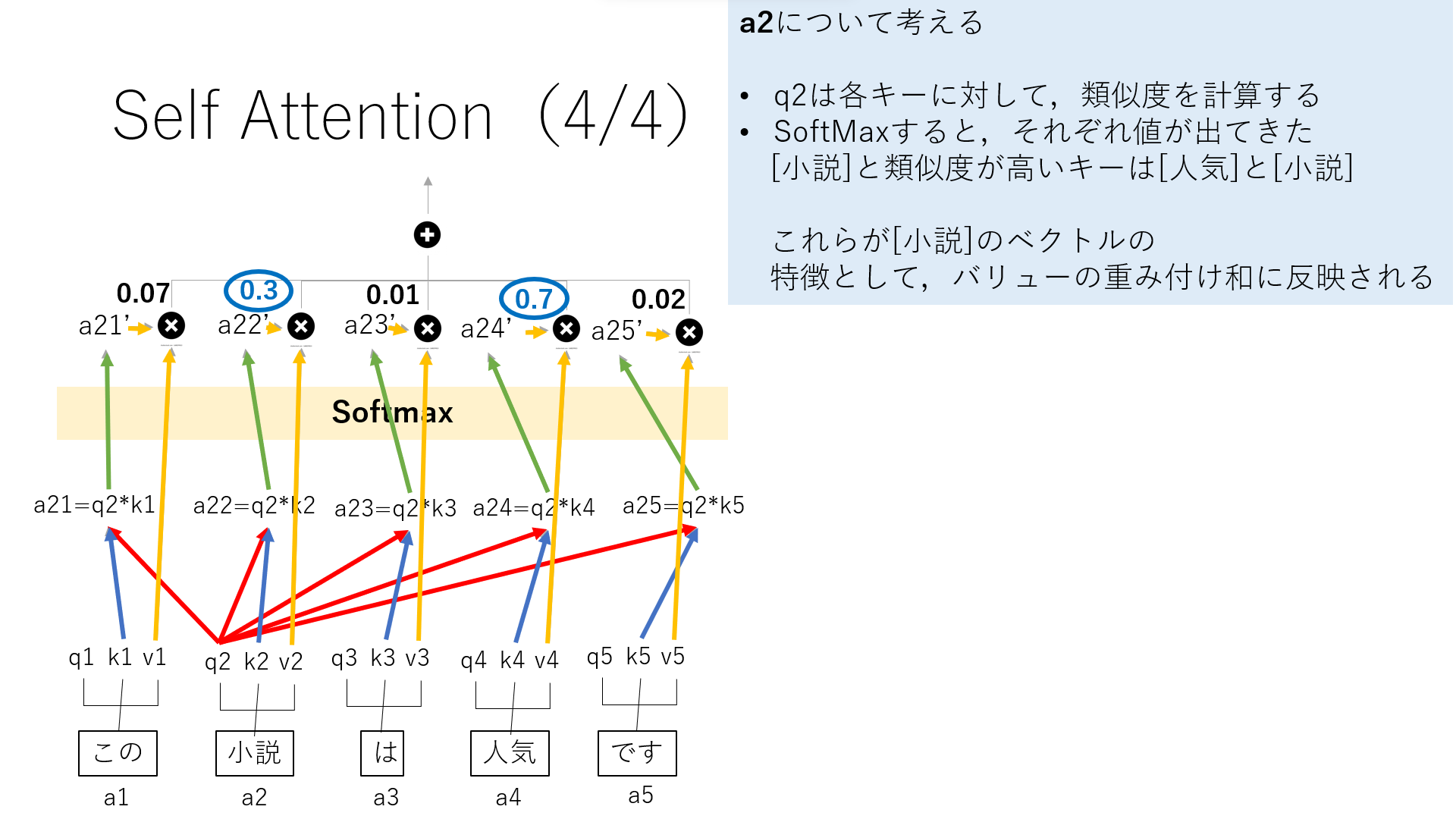
ここでは,5単語あり,今回は”小説”について考えます.
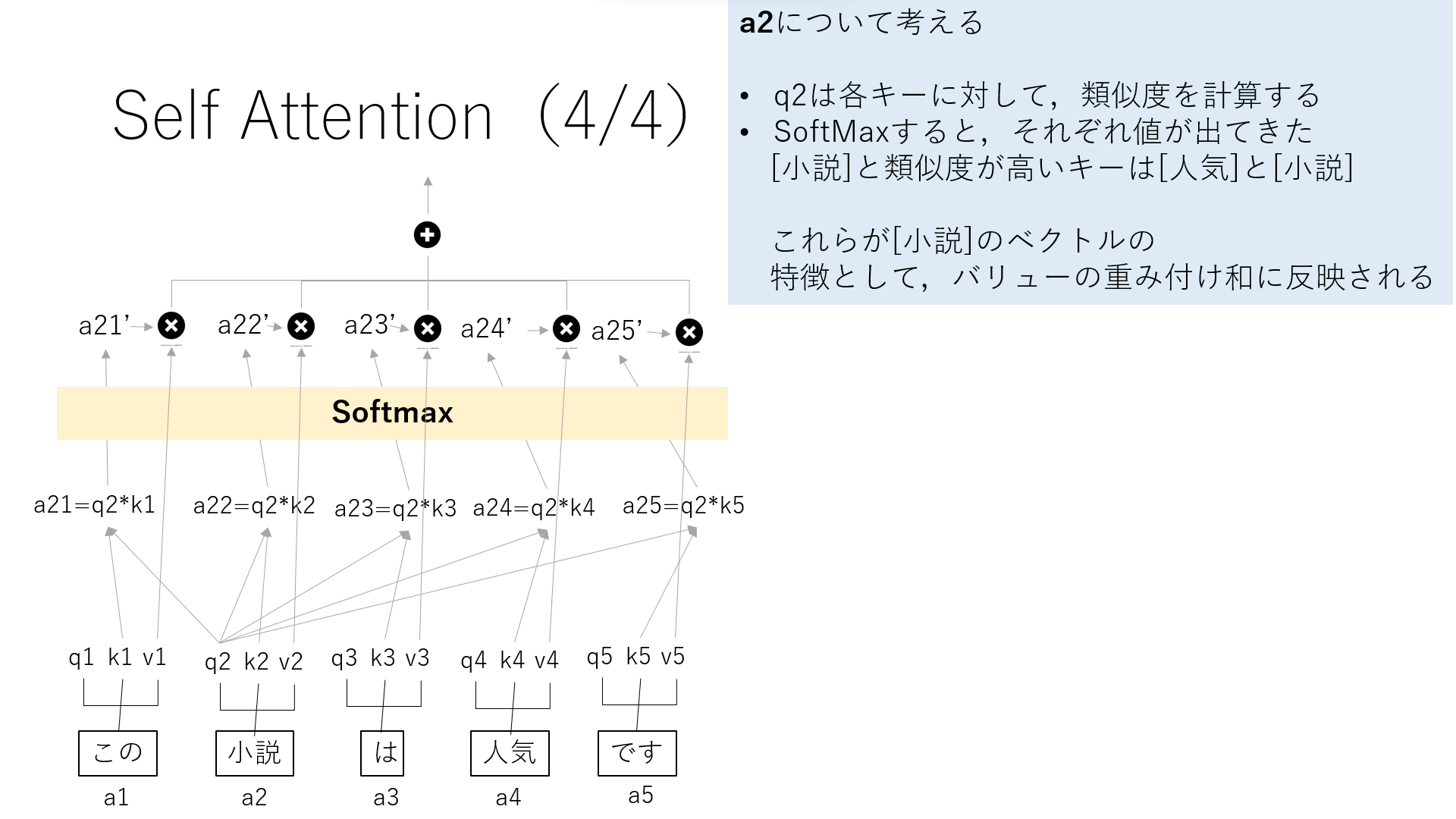
”小説”のQであるq2は各キーに対して,類似度を計算します.
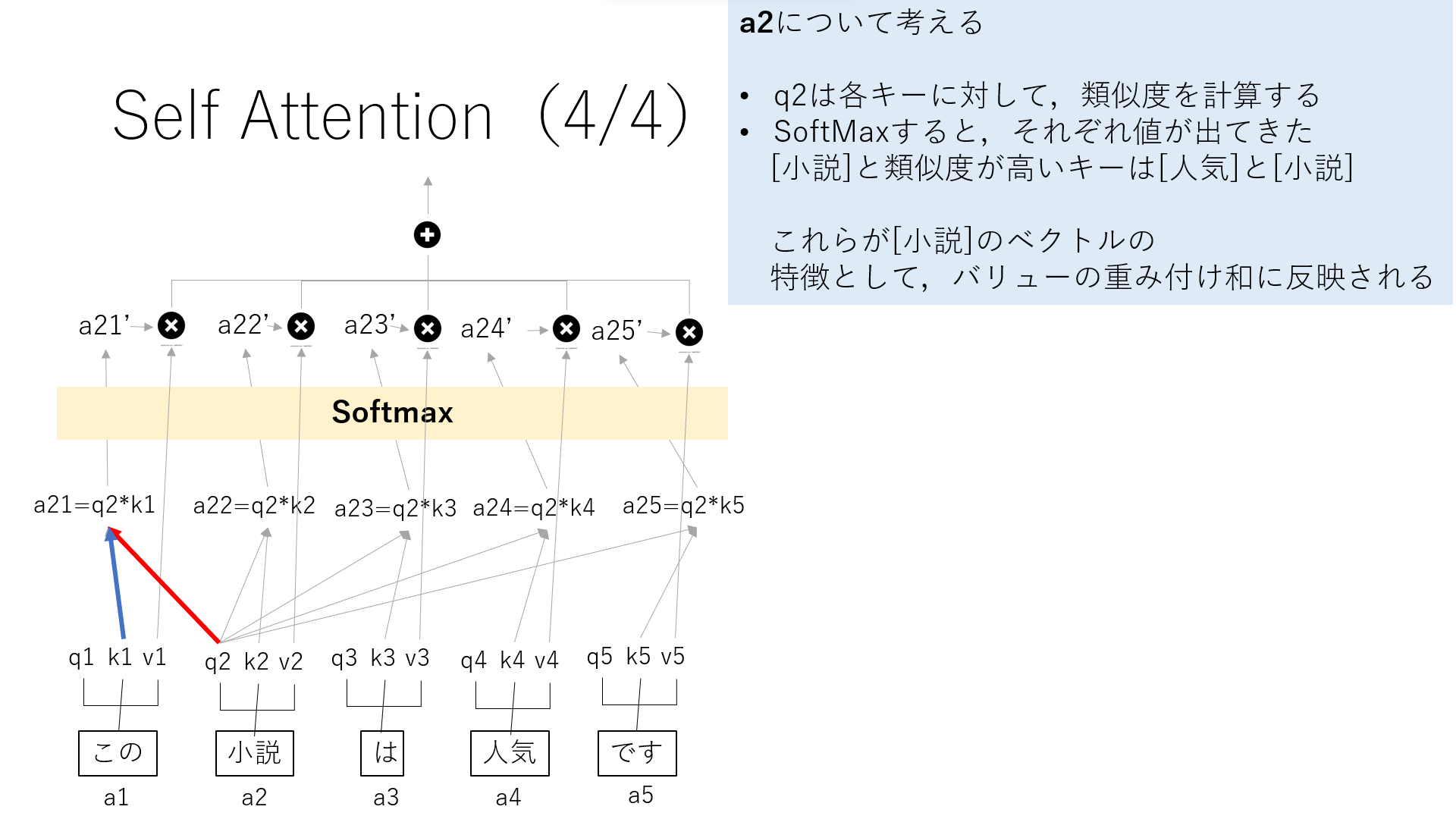

ここで出てきた値をSoftmaxします.
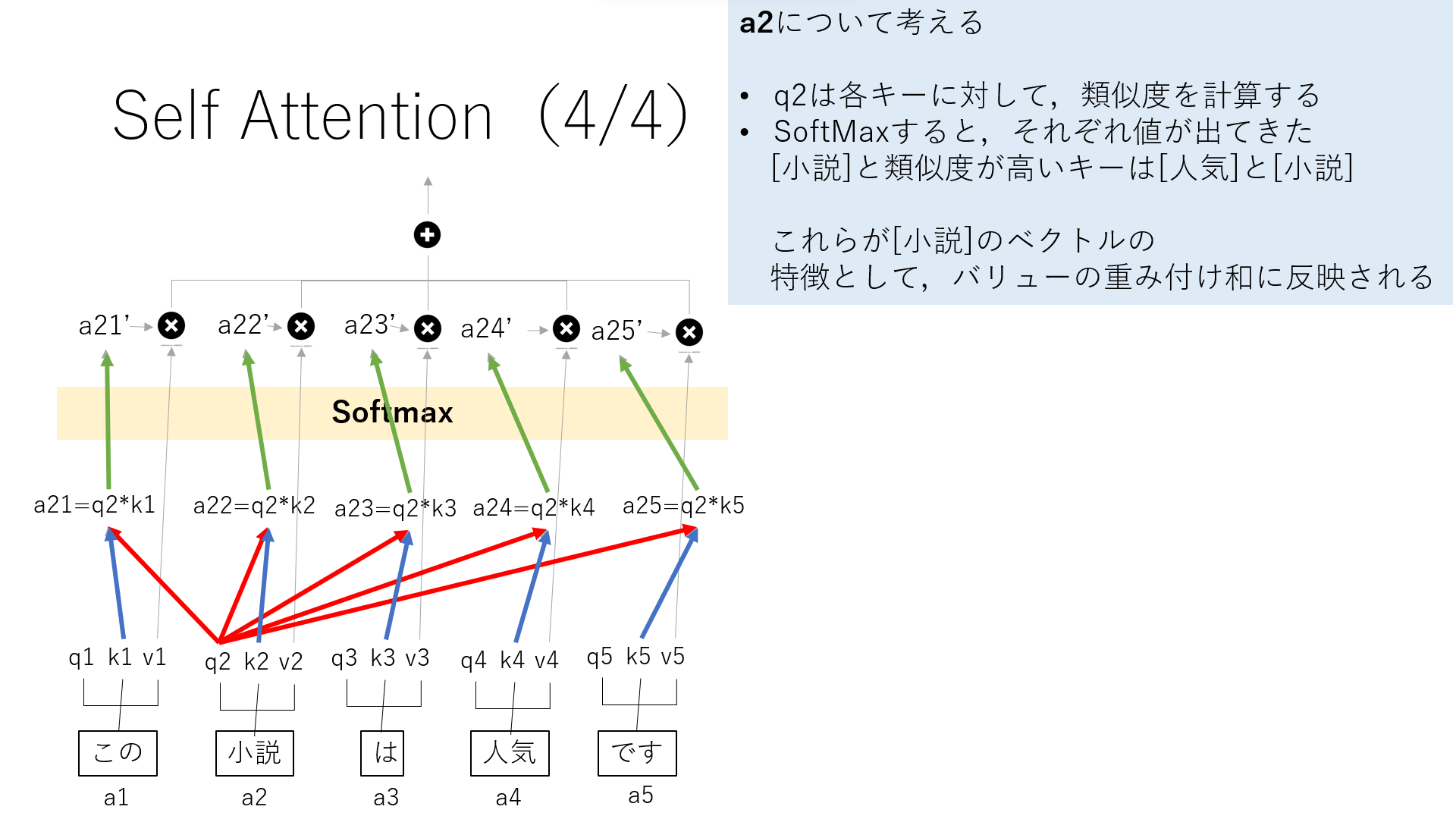
その値を,それぞれのバリューと掛け合わせると,バリューの重み付け和が出ます.これが”小説”との関連性を表しています.
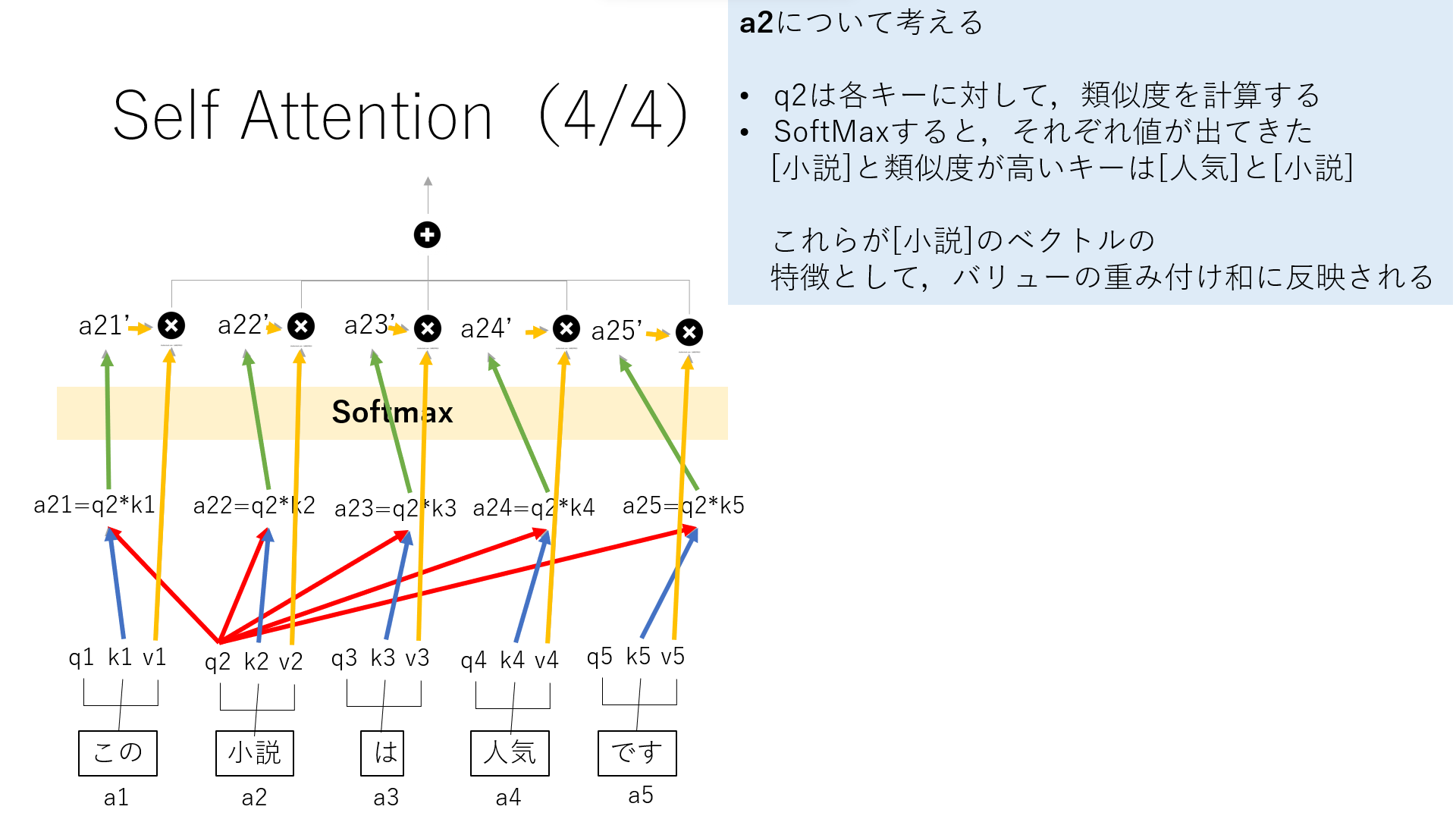
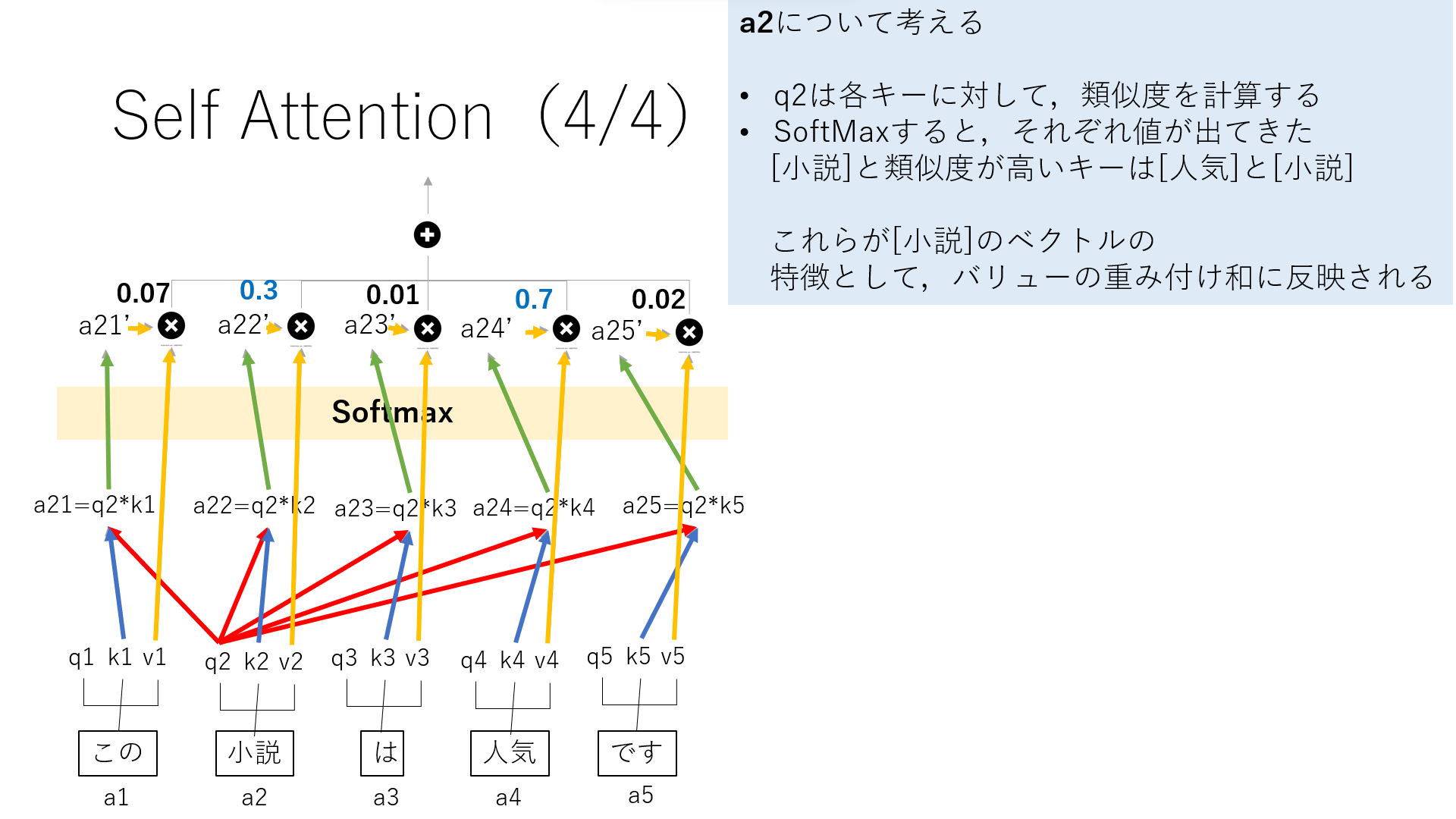
今回”小説”との関係性が強い単語は”人気”と”小説”となりました.
3 Multi Head Self Attention
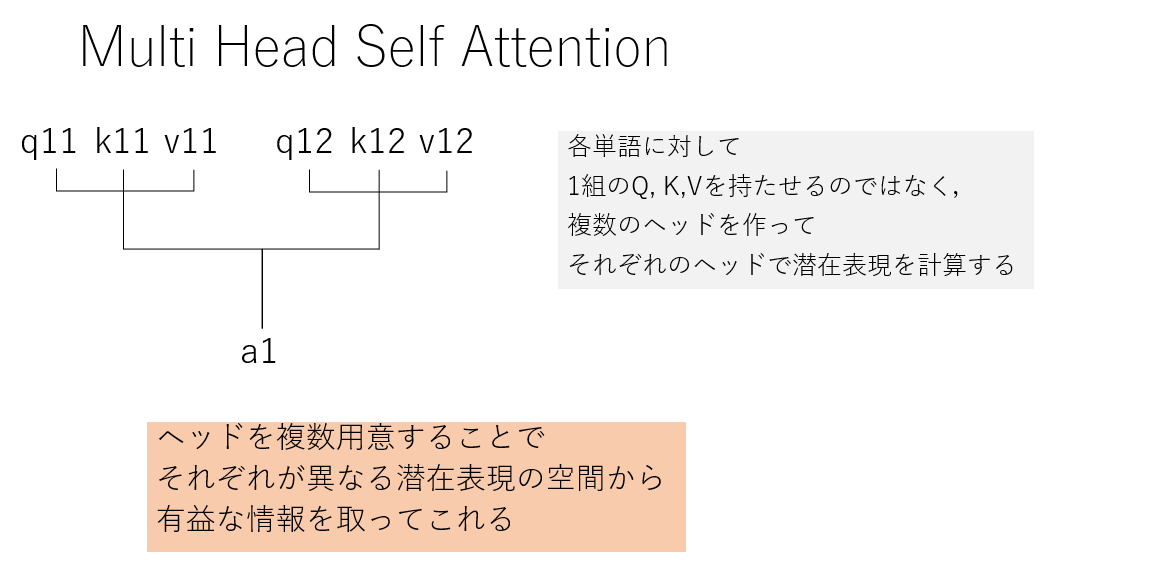
Multi Head Self Attention(MHSA)は,各単語に対して1組のQKVを用いるのではなく,複数作ってそれぞれで潜在表現を計算します.
複数用意することで,それぞれが異なる潜在表現の空間から有用な情報を取ってこれます.
4 Position Encoding
ここまでの構造で欠けているのは,順序の情報です.
Attentionだけでは位置情報が入らないので,位置情報を符号化して加えます.
ここは勉強中なのでまた今度まとめさせてください![]()
なるはやで頑張るます![]()
さいごに
随時追記予定です.
私も勉強中の身なので,面白い技術があれば是非教えて欲しいです![]()