はじめに
kubernetesクラスタを構築しようとして、k8s-the-hard-wayに従いCNIのbridge addonで構築しようとしたところでpodから外部に接続できない事案が発生。
デバッグ目的でCNIのことを調べるうちに、コンテナとホストネットワークを繋ぐ方法がどうやらデフォルトのDockerネットワークおよびkubernetesのbridgeプラグインで使われる方法ということがわかり、実際にハンズオンで操作できたのでメモ。
ちなみに筆者の環境は centos8をVirtualBOX上にminimalインストールしたものです。
ip -V # -> ip utility, iproute2-ss180813
作業の流れ
以下の図(source)で示される、docker0(bridgeデバイス)、veth・eth0(vethデバイス)を作成するチュートリアルとなります。
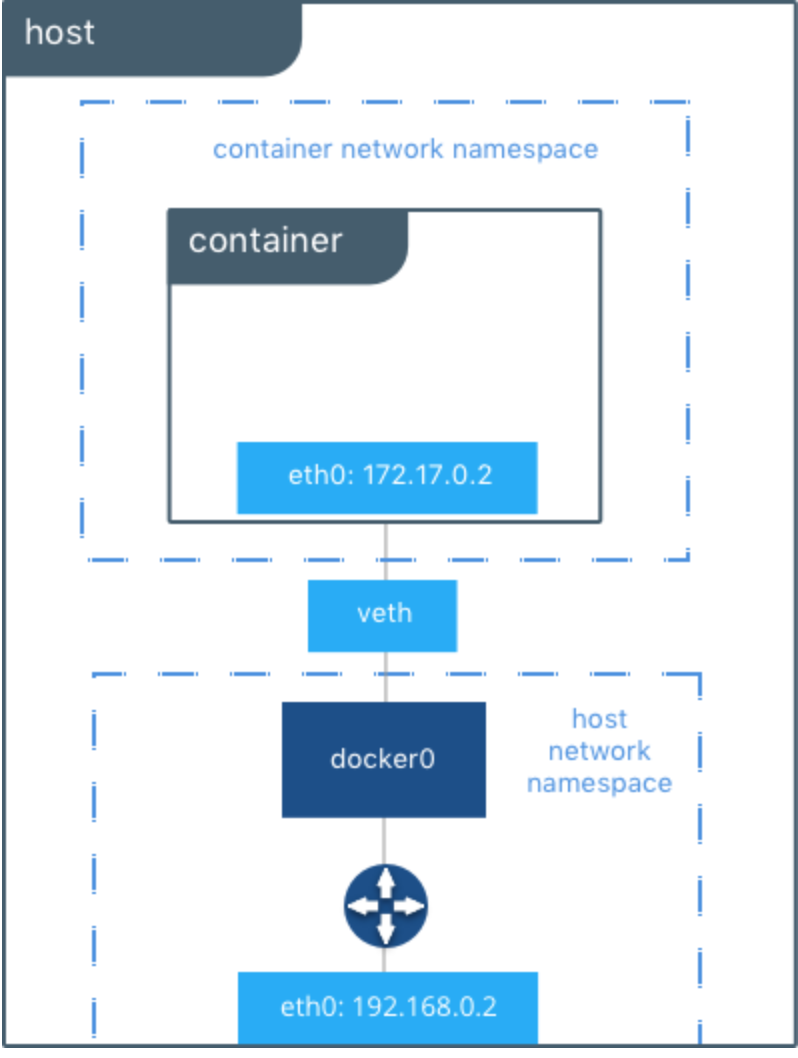
全体としては
- 名前空間・デバイスの作成
- 名前空間とデバイス間、デバイス同士の関連付け
- Netfilterの設定(外部との通信の際)
- 疎通確認
という感じになります。実際に作成するだけなら割とすぐにできる感じです。
では始めていきましょう。
事前確認
まずネットワーク名前空間とデバイスを確認します。
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:cf:36:20 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.101/24 brd 192.168.2.255 scope global dynamic noprefixroute enp0s3
valid_lft 31534789sec preferred_lft 31534789sec
inet6 2405:6580:b040:8000:dda4:8738:e56f:fa5d/64 scope global dynamic noprefixroute
valid_lft 2591789sec preferred_lft 604589sec
inet6 fe80::27b3:e5ee:aad0:538d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:2c:97:79:56 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:2cff:fe97:7956/64 scope link
valid_lft forever preferred_lft forever
$ ip netns list #何も出力されない
dockerでコンテナを作成していたとしても特にnetnsの出力はありません。
これはiproute2が認識するnetwork namespace が/var/run/netns配下に置かれた特殊なファイルのみであるため(参考:Docker containerのnetwork namespaceでdebugしたい)。
なのでコンテナの作成した名前空間と以下のやりとりを行いたい場合は上の参考手順にしたがってDockerコンテナ名前空間を操作できるようにします。
が、今回のチュートリアルでは特にそんなことはせずに自前で作ったものだけを操作していきます。
デバイス・名前空間の作成
まずテスト用の名前空間を作成します。
$ ip netns add testns
$ ip netns list
testns
次にテスト用のデバイスの作成です。
# bridgeデバイスの作成
$ ip link add testbr type bridge
# vethデバイスペアの作成
$ ip link add ve1 type veth peer name ve2
$ ip a
# ...作成したデバイスが存在することを確認
63: testbr: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 8a:cb:ef:69:e7:71 brd ff:ff:ff:ff:ff:ff
64: ve2@ve1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 62:b6:ba:63:24:88 brd ff:ff:ff:ff:ff:ff
65: ve1@ve2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether e6:4e:0c:68:1b:df brd ff:ff:ff:ff:ff:ff
vethのペアはパケットを共有する
ため、片方にipアドレスを付与すればもう片方のデバイスに対しても通信が可能になります。
Dockerデファルトの構成と同様にすることを考えると、ブリッジデバイスをデフォルトゲートウェイとし、片方のvethデバイスにコンテナ用のIPを付与します。
ここで、上で提示した図との対応は以下の通り。
| Docker default | 作成した環境 | IP |
|---|---|---|
| docker0 | testbr | 10.100.0.1/24 (Gateway) |
| veth | ve1 | (bridgeに刺さってる) |
| eth0 | ve2 | 10.100.0.2/24 (コンテナ) |
vethをブリッジングデバイスに接続することで、複数のveth間で接続することができるようになりDockerのbridgeネットワークを構成することができます。
まずvethの片側をbridgeに接続します。
$ ip link set dev ve1 master brtest
# master testbrが追加されたことを確認
$ ip a show dev ve1
65: ve1@ve2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop master testbr state DOWN group default qlen 1000
link/ether e6:4e:0c:68:1b:df brd ff:ff:ff:ff:ff:ff
次にもう片方のvethをテスト用の名前空間に移動させます。
$ ip link set netns testns dev ve2
# そのままでは確認できなくなったことを確認
$ ip a show dev ve2
Device "ve2" does not exist.
# 移動先の名前空間で確認できることを確認(ip netns exec <namespace> <command>)
$ ip netns exec testns ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
64: ve2@if65: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 62:b6:ba:63:24:88 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# ホスト上には片割れが存在することを確認
$ ip a show dev ve1
65: ve1@if64: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue master testbr state DOWN group default qlen 1000
link/ether e6:4e:0c:68:1b:df brd ff:ff:ff:ff:ff:ff link-netns testns
互いにインデックス名でペアであることが示されています(65: ve1@if64 <-> 64: ve2@if65)
またlink-netns、link-netnsidによって互いにリンクしている名前空間が示されています。
次にtestbrにデフォルトゲートウェイ用のIP、ve2にコンテナ内部用(別に今回はコンテナ作成してない)のIPを付与し、デバイスをUPします。
$ ip a add 10.100.0.1 dev testbr
$ ip netns exec testns ip a add 10.100.0.2/24 dev ve2
# これまでと同様の方法で設定が反映されていることを確認
# state up
$ ip link set dev ve1 up
$ ip netns exec testns ip link set dev ve2 up
$ ip link set dev testbr up
最後にtestns内でルーティングテーブルを設定したら準備完了です。
$ ip netns exec testns ip r add default via 10.100.0.1 dev ve2
$ ip netns exec testns ip r
default via 10.100.0.1 dev ve2
10.100.0.0/24 dev ve2 proto kernel scope link src 10.100.0.2
上記のルーティングはデバイスをUPにしてからじゃないと適用できません。
確認
異なる名前空間からホストに通信できるようになっている確認します。
まずはデフォルトGW
$ ip netns exec testns ping 10.100.0.1
PING 10.100.0.1 (10.100.0.1) 56(84) bytes of data.
64 bytes from 10.100.0.1: icmp_seq=1 ttl=64 time=0.099 ms
64 bytes from 10.100.0.1: icmp_seq=2 ttl=64 time=0.148 ms
問題ありません。
次にホスト上の任意のNICに対してです。
同一のホスト上なのでINPUT-OUTPUTのチェーンで処理されます。
ip netns exec testns ping 192.168.2.101
PING 192.168.2.101 (192.168.2.101) 56(84) bytes of data.
64 bytes from 192.168.2.101: icmp_seq=1 ttl=64 time=0.085 ms
64 bytes from 192.168.2.101: icmp_seq=2 ttl=64 time=0.045 ms
こちらも問題ありません。
次にホスト上のデフォルトGWに対して疎通を行います。
この時注意点は、
- 同一ホスト場ではないのでFORWARDチェーンを通過
- ホスト外(というか自宅のルータ)にはルーティングテーブルが設定されていないため、MASQUERADEしなければ応答が帰ってこない
です。
つまり、疎通を行う前に、まずNetfilterによって上記の点に関して設定を行う必要があります。
# FORWARDのポリシーでドロップされないようにする
$ nft add rule ip filter FORWARD oifname testbr accept
$ nft add rule ip filter FORWARD iifname testbr accept
# ホスト側につながっているネットワークデバイスで認識できるように masquerade
$ nft insert rule ip nat POSTROUTING oifname != testbr ip saddr 10.100.0.0/24 counter masquerade
# いよいよ疎通確認
$ ip netns exec testns ping 192.168.2.1
PING 192.168.2.1 (192.168.2.1) 56(84) bytes of data.
64 bytes from 192.168.2.1: icmp_seq=1 ttl=63 time=2.60 ms
64 bytes from 192.168.2.1: icmp_seq=2 ttl=63 time=2.42 ms
こちらも無事疎通できました。めでたしめでたし
clean up
bridge接続ができることを確認できたので後片付けです。
ここまでに作ったものを順に削除していきます。
ちなみに一度違う名前空間に移動したデバイスは下記のようにすることで元の名前空間に戻すことができます
$ ip netns exec testns ip link set netns 1 dev ve2
# set netns <ホスト上で稼働している何らかのPID>
# たまたまここではinitの 1
しかし削除するだけなので特に気にしなくでも大丈夫です
$ ip netns del testns
# testnsに属していたve2、片割れのve1も共に消えます
$ ip link del testbr
以上、2コマンドで終了です。
終わりに
以上、作業にしてしまえば少ないとはいえ、これだけのことを勝手にやってくれているコンテナ技術に感謝感激を感じるチュートリアルとなりました。
にしてもiproute2の機能のほんの一部しか使えていませんし、チラッと出てきたこちらでも読んで 完全に理解した くらいまでは理解を進めたいものです。また時間ができた際に取り組む気持ち(今のところ)です。。