こんな人に読んでほしい
職場でSharePointのニュース記事投稿を使って情報発信をしていて、各ページの閲覧傾向の分析をしたいような方向けの記事です。フローの実行日ごとに日付ファイル名付きのCSVをSharePointフォルダに書き出します。
こうすることで、時系列のデータを作ることができるので、Power BIを使ってCSVファイルを連結して閲覧数の増加傾向などを分析することができます。(Excel のPower Queryを使ってもよいですね。そのあたりもまた記事作ります)
SPOニュースについて おさらい
この記事を読んでいる人には説明の必要がないかもしれませんが、ニュース投稿はSharePointサイトの「+新規」から行えます。
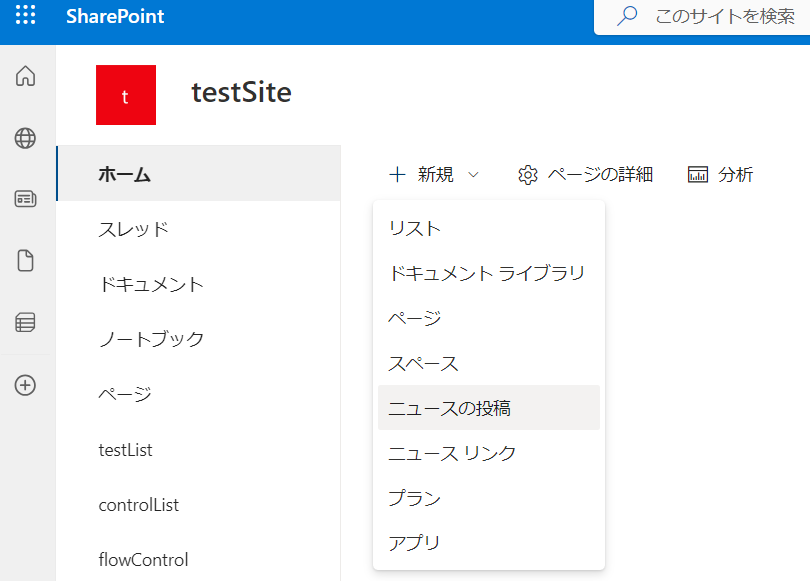
投稿された記事は「ページ」という項目のフォルダの中に、.aspxの拡張子が付いたファイルとして保存されています。隠されている「いいね」列を表示すると、いちおうここでもニュースページについているイイねの数を知ることができます。ただ、この数は瞬間の数字なので、今回の取り組みはそのスナップショットを取るようなイメージです。
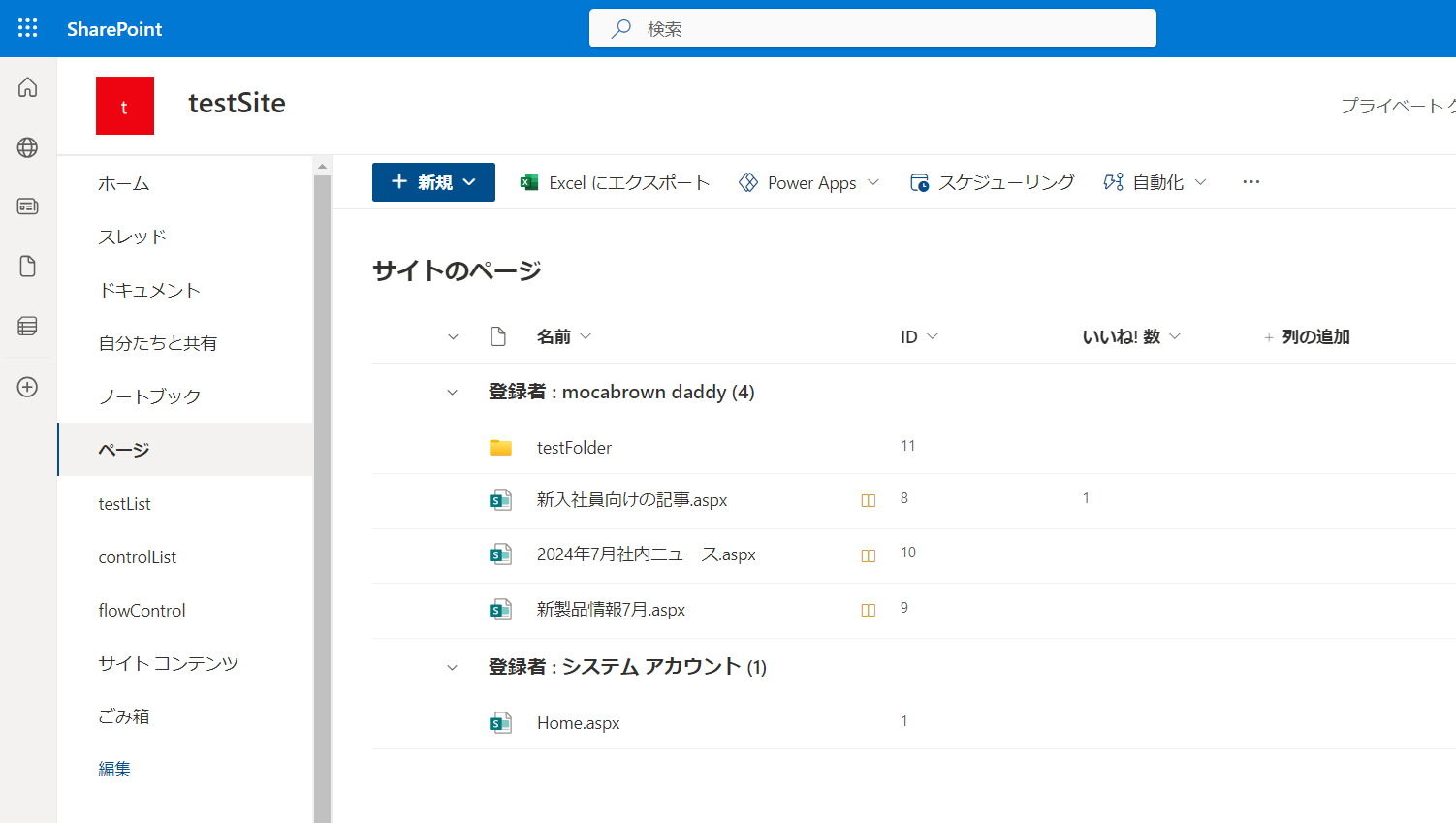
記事の各ページを開くと、下のほうに閲覧数が表示されています。この数字をスナップショットするのが今回の目的です。

まずは、サイト内の記事一覧を取得する
全体の動作としてはサイトの中の記事を一覧化して、そのあとに1記事ずつの閲覧数を取得するイメージです。
というわけで、先ほどのスクショのような記事ファイルの一覧を取ってきます。実はこの部分に少しコツがいります。
フォルダの中身 実はSPOリスト
SharePointの上にあるファイルの管理、実はSharePointリストとして管理されています。先ほどのスクショにあった「ページ」フォルダの中身に表示されている.aspxファイルの一覧もSPOリストなんです。
ということは、リストの項目一覧をPowerAutomateで取得すればよいわけです。
ここで、クラウドフローでSharePointの操作をしたことがある方ならお気づきでしょう。「複数の項目の取得」アクションで、リスト名を選択しようとしても、「ドキュメントライブラリ」や「ページ」をリストとして選べる選択肢は出てこないのです。
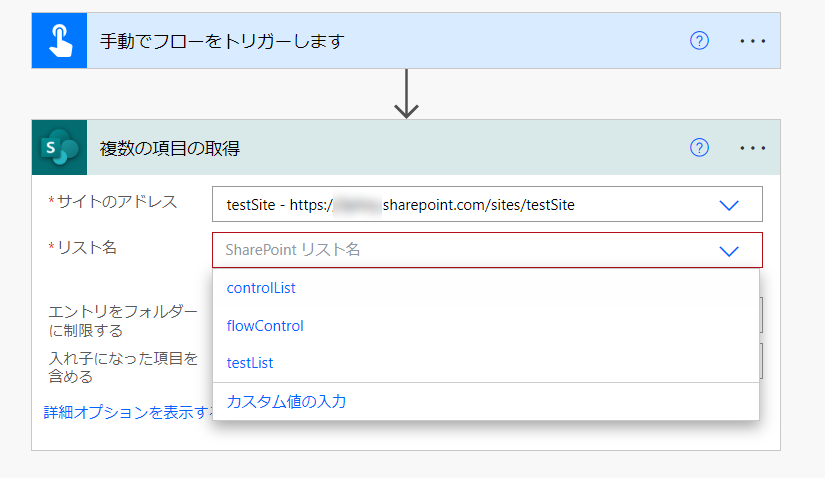
というわけで、以前にこの問題の対処法について記事にしていますのでご覧ください。
リストのIDを取得すればよいのですが、記事の一番最後に書いてある突っ込みどころ満載の解決策を使います。
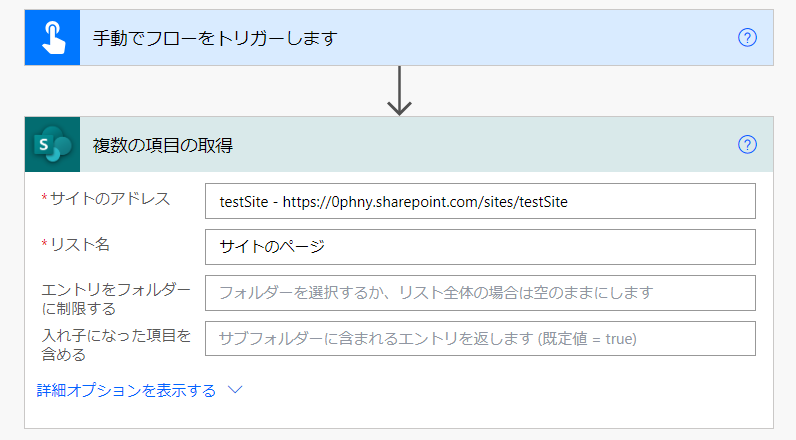
リスト名の選択項目で、カスタム値の入力をつかって「サイトのページ」と入力してやります。びっくりですよね!
必要な項目だけ「選択」でチョイス
テスト実行して、取得できたJSONをVisual Studio Codeのようなテキストエディタに貼り付けて、体裁を整えて見てみます。今回ほしいのは、
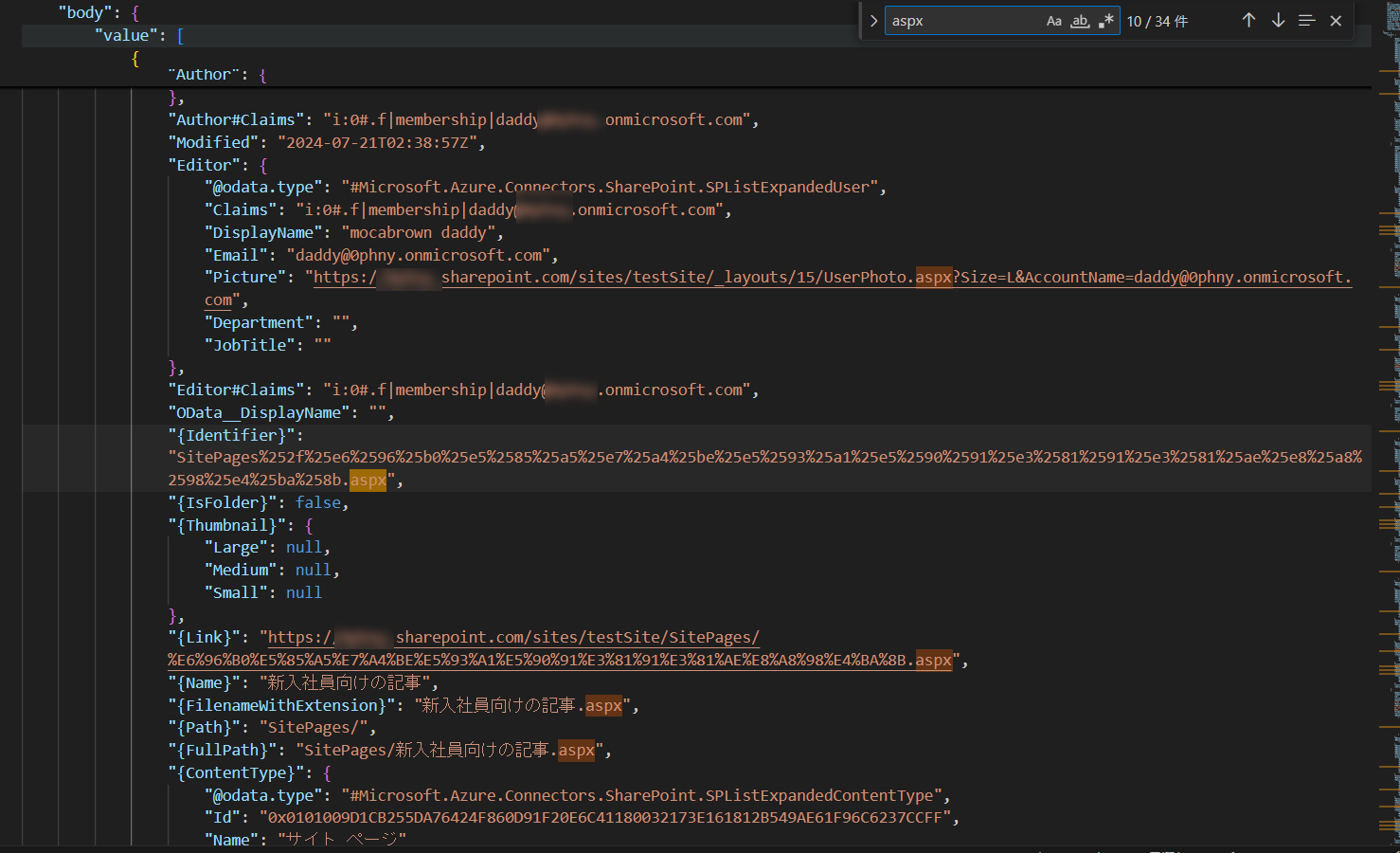
情報がたっぷりでおなか一杯なので、「選択」を使ってつまみ食いします。
item()?['{name}']
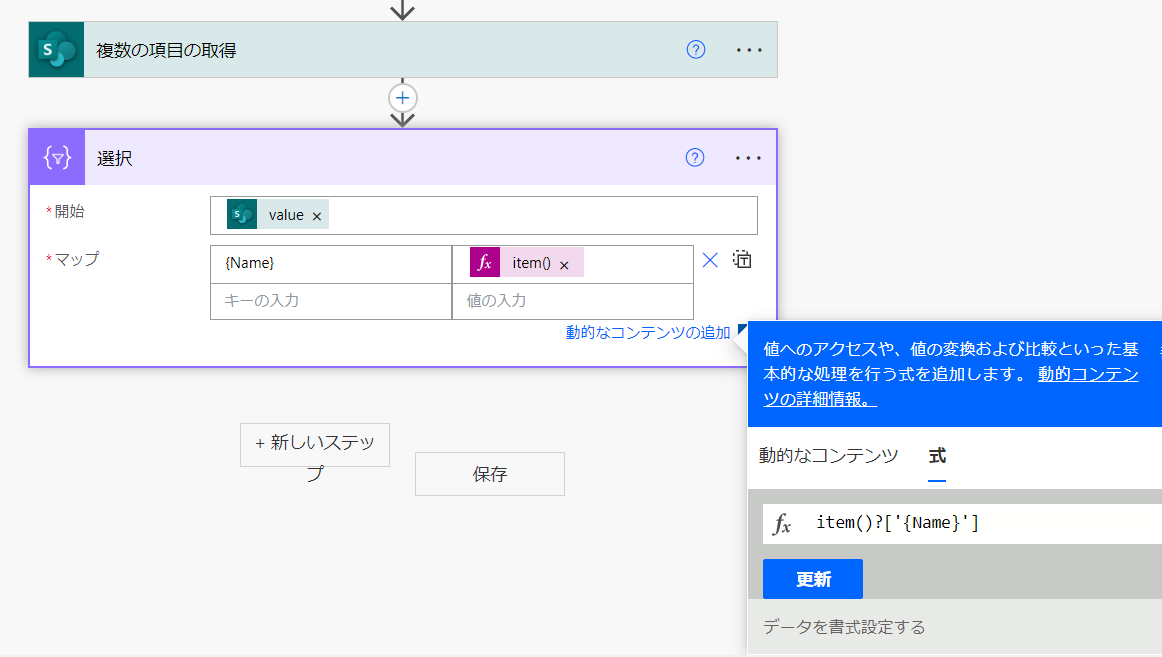
イイ感じに記事ファイルのタイトル部分だけが取得できました。
テキストエディタの中身を見ながら、調子にのって、他のほしい項目を「選択」の中に追加していきます。
item()?['ID']
item()?['{FilenameWithExtension}']
item()?['{Link}']

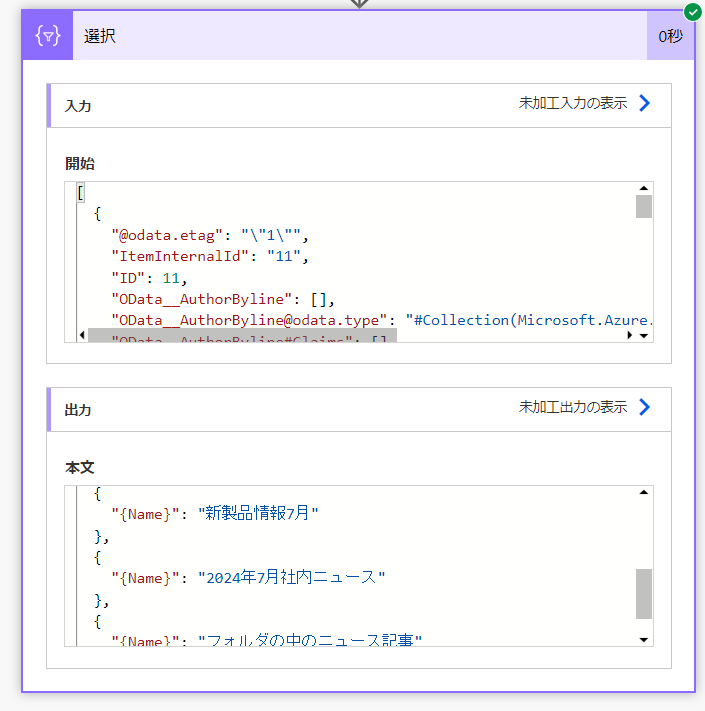
スッキリしたJSONでページの一覧を取得することができました。

情報はSPO用のHTTP要求でゲット
いよいよ、1記事ずつ閲覧数やいいね項目を取得していきます。いきなりループを使って回してみたいところですが、まずはテスト。先ほど取得した適当な記事のリンク(記事のURL)を使って、その記事の情報を取得します。
安心してください。プレミアムではない、標準コネクタのアクションです。「SharePointにHTTP要求を送信します」アクションを選択します。

各ページ単位の情報を得るには、ページのフルパスと、SelectPropertiesというオプションを使って取得したい情報を指定してやります。
とりあえずやってみます。こんな感じに指定します。かなり長いので注意してコピーしてください。特にURL直前のコロンやクォーテーション「:」や、Pathの前、URL直後のクオート「'」を忘れると動きませんので慎重に。
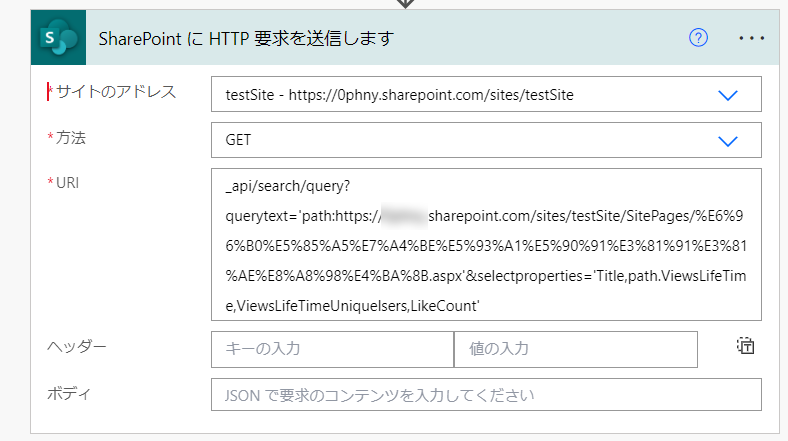
_api/search/query?querytext='path:<ページのURL>'&selectproperties='ViewsLifetime,ViewsLifetimeUniqueUsers,LikeCount'
selectpropertiesのなかで、ViewsLifetime,ViewsLifetimeUniqueUsers,LikeCountの3項目を指定しています。ちなみにLikeCount項目は指定しないと出てきません。
クラウドフローを実行してみて、再度取得できたJSONをテキストエディタで分析します。LikeCountの項目を検索すると、JSONのめちゃくちゃ深い階層にあることがわかります。

とりあえず、selectpropertiesで指定した項目は固まって同じ階層に収納されていますので、お得意の「選択」を使ってその階層だけを取り出します。
「選択」はアレイ型しか受け取ってくれないので、SPOへのHTTP要求の結果であるBodyを[]で囲っています。
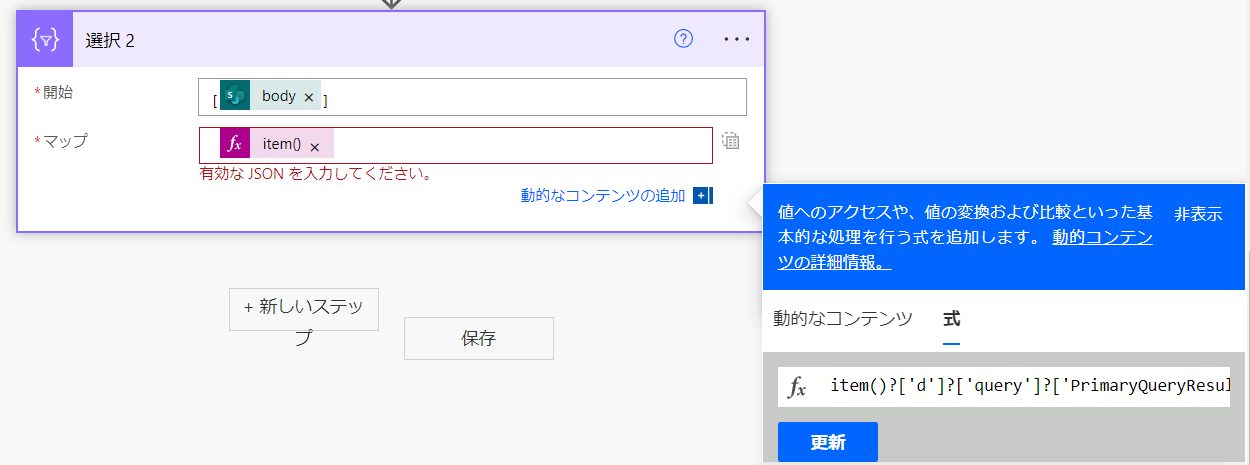
item()?['d']?['query']?['PrimaryQueryResult']?['RelevantResults']?['Table']?['Rows']?['results'][0]['Cells']?['results']
このような強烈に深いJSONの階層を読み解くのは大変です。こういう時に便利な階層分析を提供している JSON Pretty Linter Ver3 というサイトが便利です。
「選択」した結果、selectpropertiesの0番目にViewsLifetime、1番目にViewsLifetimeUniqueUsers、2番目にLikeCountを取得することができました。

ここまでできたら、再度「選択」を使って各項目だけのJSONに再加工ができそうです。selectpropertiesの配列の0番目、1番目、2番目のValueの項目にある値を取得したいので、式はこのようになります。
item()?['selectproperties'][0]?['Value']
item()?['selectproperties'][1]?['Value']
item()?['selectproperties'][2]?['Value']
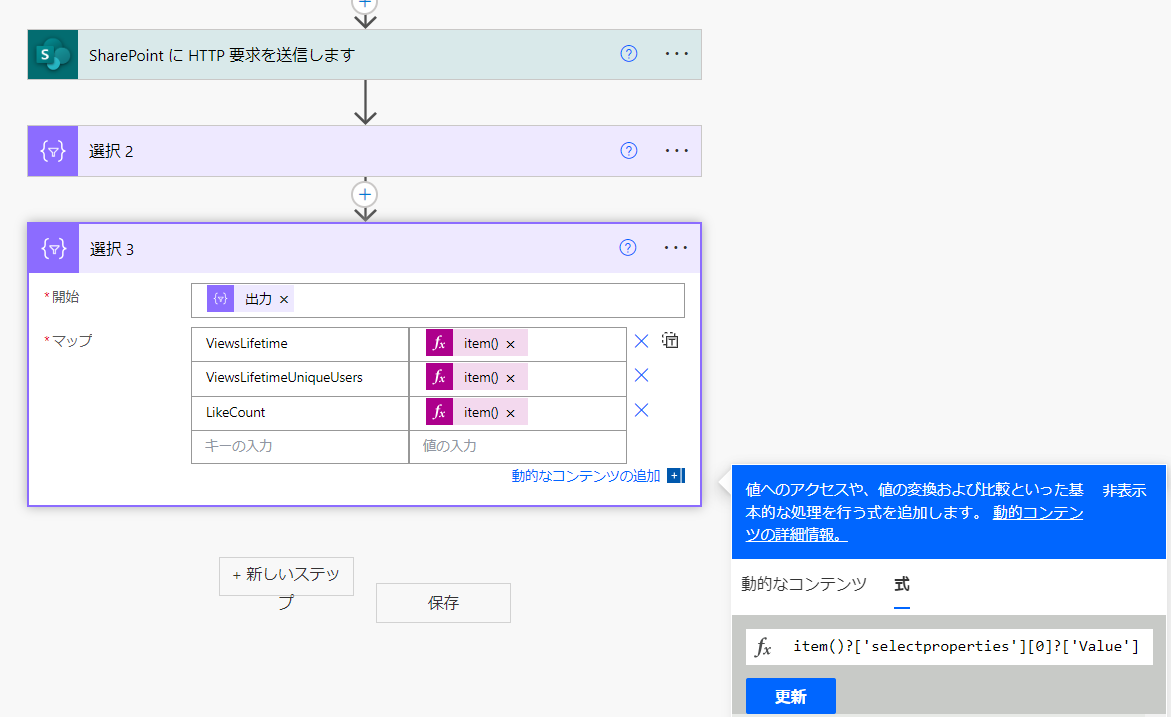
結果はこのとおり。シンプルに選択した数値のみが取得できました。

Apply to eachで回す
ページのURLを使ってHTTP要求で欲しい情報を取得できることがわかりましたので、こんどは複数のページについて順番に同じ処理を繰り返します。
先ほど作った処理の上にApply to each を配置して、選択の出力(ここには、ID、拡張子付きのページファイル名、ページファイルのURLが入っています)を選択します。

下の3つをループの中に入れたいのですが、そのままだと依存関係があってドラッグ&ドロップできなかったので、一旦スコープの中にまとめてやります。
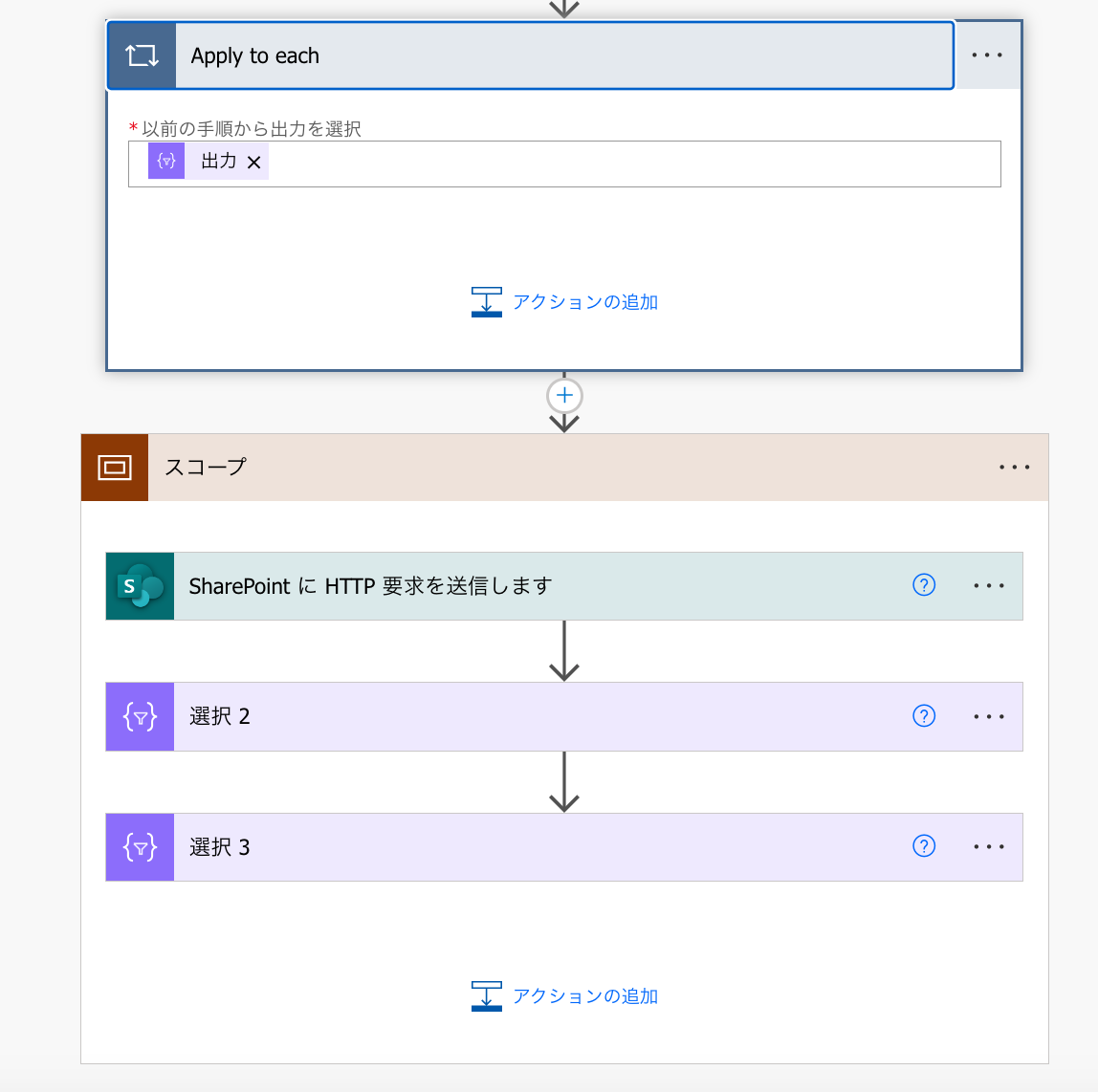
スコープごとApply to eachの中に放り込みました。

HTTP要求のページURLの部分をページごとに差し替える式を加えます。URLの前後にあるコロンやクオーテーションを消してしまわないように注意してください。
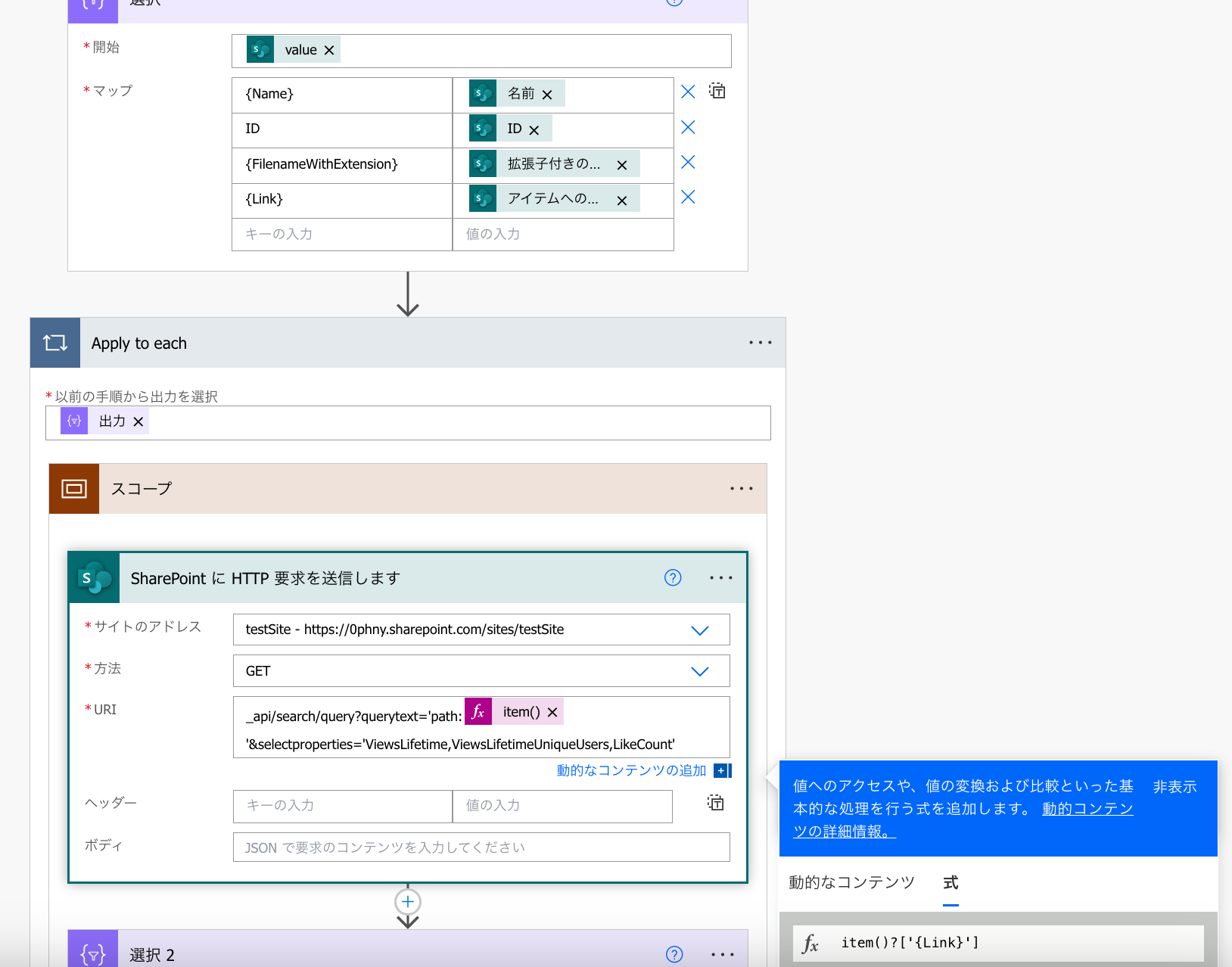
エラーになるページとならないページがあった
HTTP要求は成功して、先ほどの通り選択で必要な項目の取得に成功したページもあれば・・・

選択に失敗しているページがありました。

失敗している項目の中身を確認してみると、 Table>Rows>Results の中身が空っぽでした。

Resutsが空っぽっだったページのURLを見てみると、ニュース投稿したページではなくて、もともとシステムが作成している「Home.aspx」でした。 URLを開いてみると、たしかにこのページは記事ではないし、ページ閲覧数やいいねも表示されていませんでした。そういうものなのかな?

エラーが出っぱなしなのも気持ちが悪いので、以下が空っぽの場合は取得処理を飛ばすように条件付けしてみます。
item()?['d']?['query']?['PrimaryQueryResult']?['RelevantResults']?['Table']?['Rows']?['results']
まずは、結果の中身がわかりやすいように、「作成」を用意して、以下の式を埋めこみます。
body('SharePoint_に_HTTP_要求を送信します')?['d']?['query']?['PrimaryQueryResult']?['RelevantResults']?['Table']?['Rows']?['results']

失敗しているループについて、作成の中身を見てみると、空っぽの配列である [] になっていることがわかります。これを条件にします。
前準備として、Apply to eachの前に「変数を初期化する」を使ってからのアレイを設定しておきます。
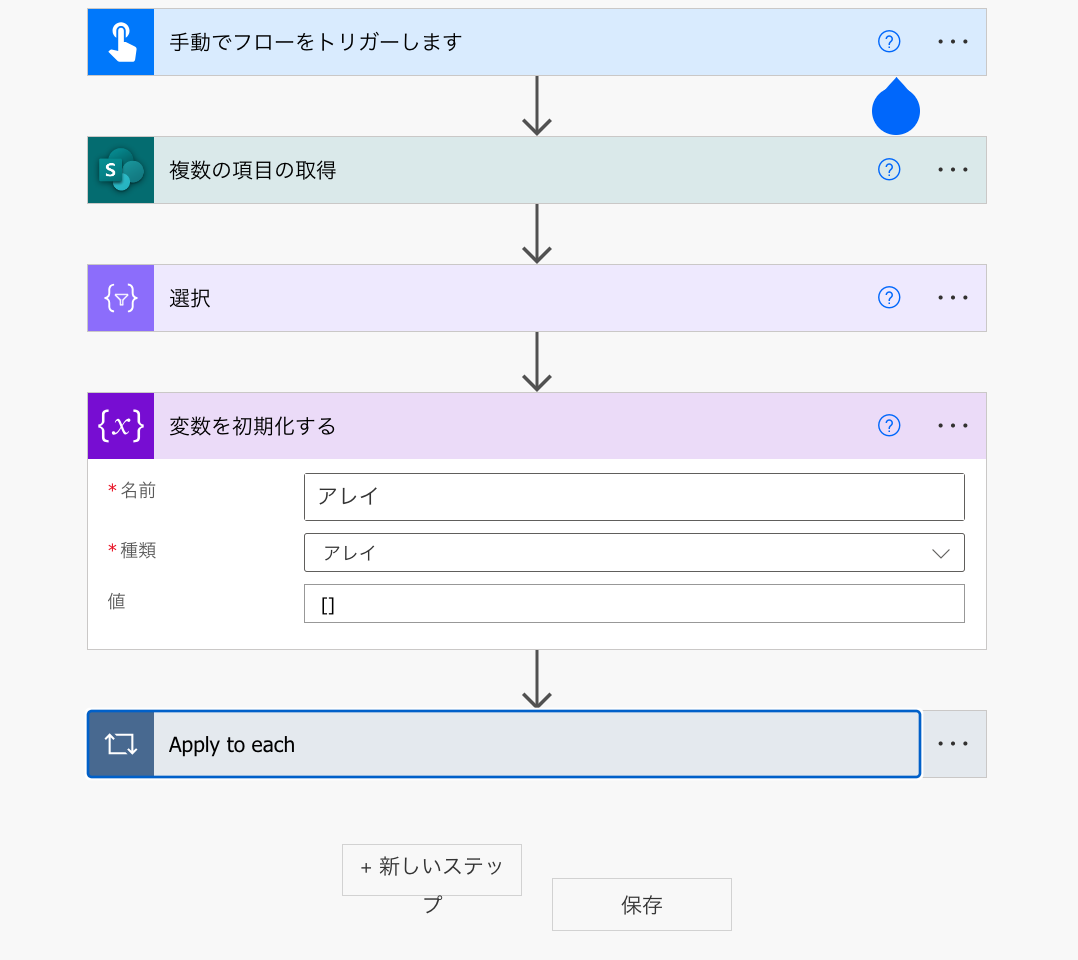
これで、アレイが空っぽではない場合にのみ、選択の処理が動作するようになりました。

複数の項目で取得できていた情報もJSONに合体
HTTP要求ができて喜んでいましたが、もともと「複数の項目の取得」でとれていた項目も盛り込みましょう。選択3に「選択」から存在していた4項目を追加しました。
注意するべきは、選択3の入力からではなく、Apply to eachの外側ループの値をとること。そのために、上の3つとは異なって、item()ではなくitems('Apply_to_each')を使っています。
items('Apply_to_each')?['{Name}']
items('Apply_to_each')?['ID']
items('Apply_to_each')?['{FilenameWithExtension}']
items('Apply_to_each')?['{Link}']
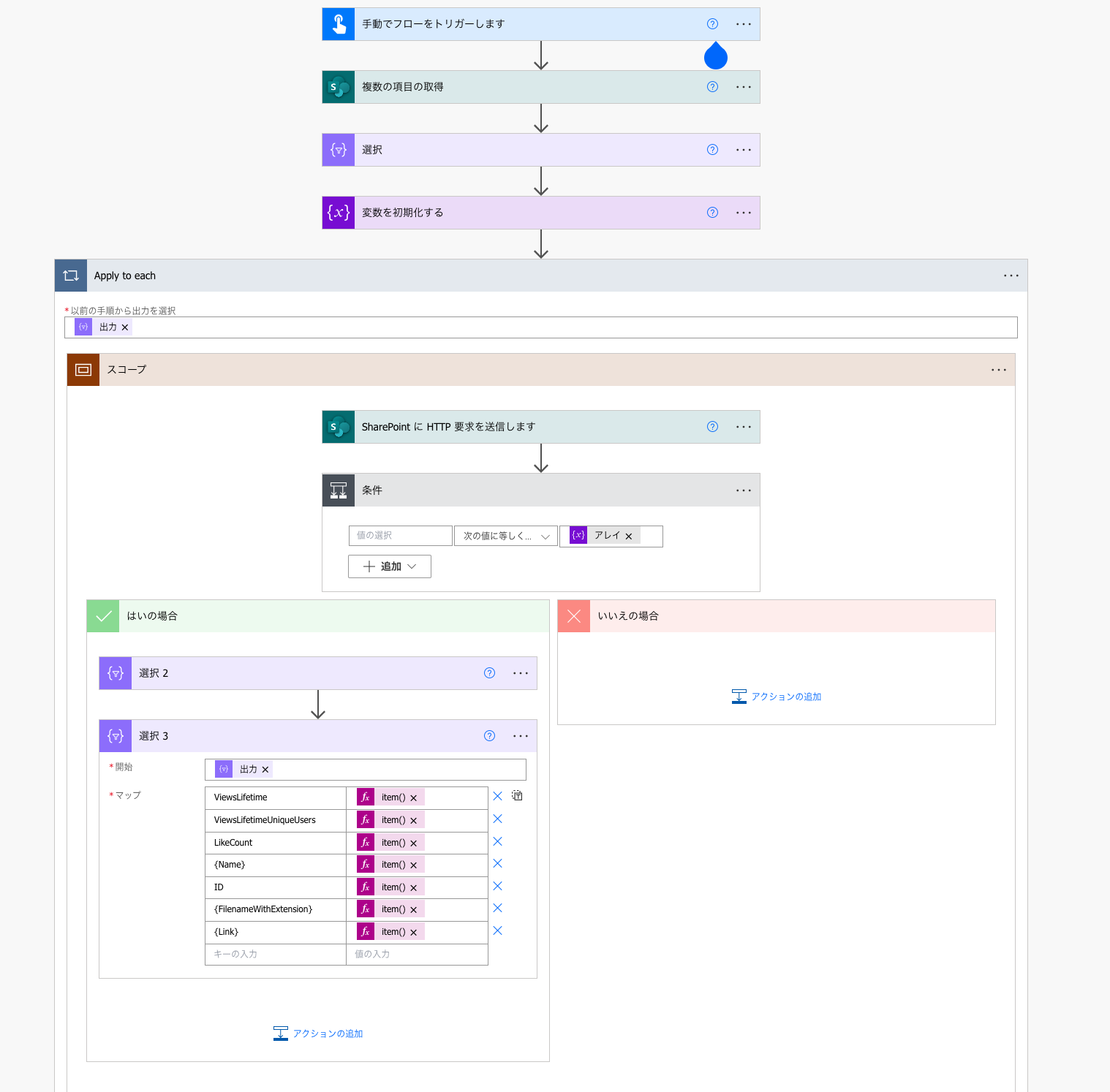
よしよし。取れてる取れてる。

ループで取得した情報をひとつのJSONに
CSVを作るには、先にJSON化していくことが肝要です。今のところ、Apply to eachのループは一回一回が独立していて、ループの後にその結果を吐き出せていません。
ループの後に結果を残すには、アレイ変数を利用して、ループ一回ずつの結果を追加していく必要があります。
まずは、Apply to eachよりも前で、変数を初期化します。
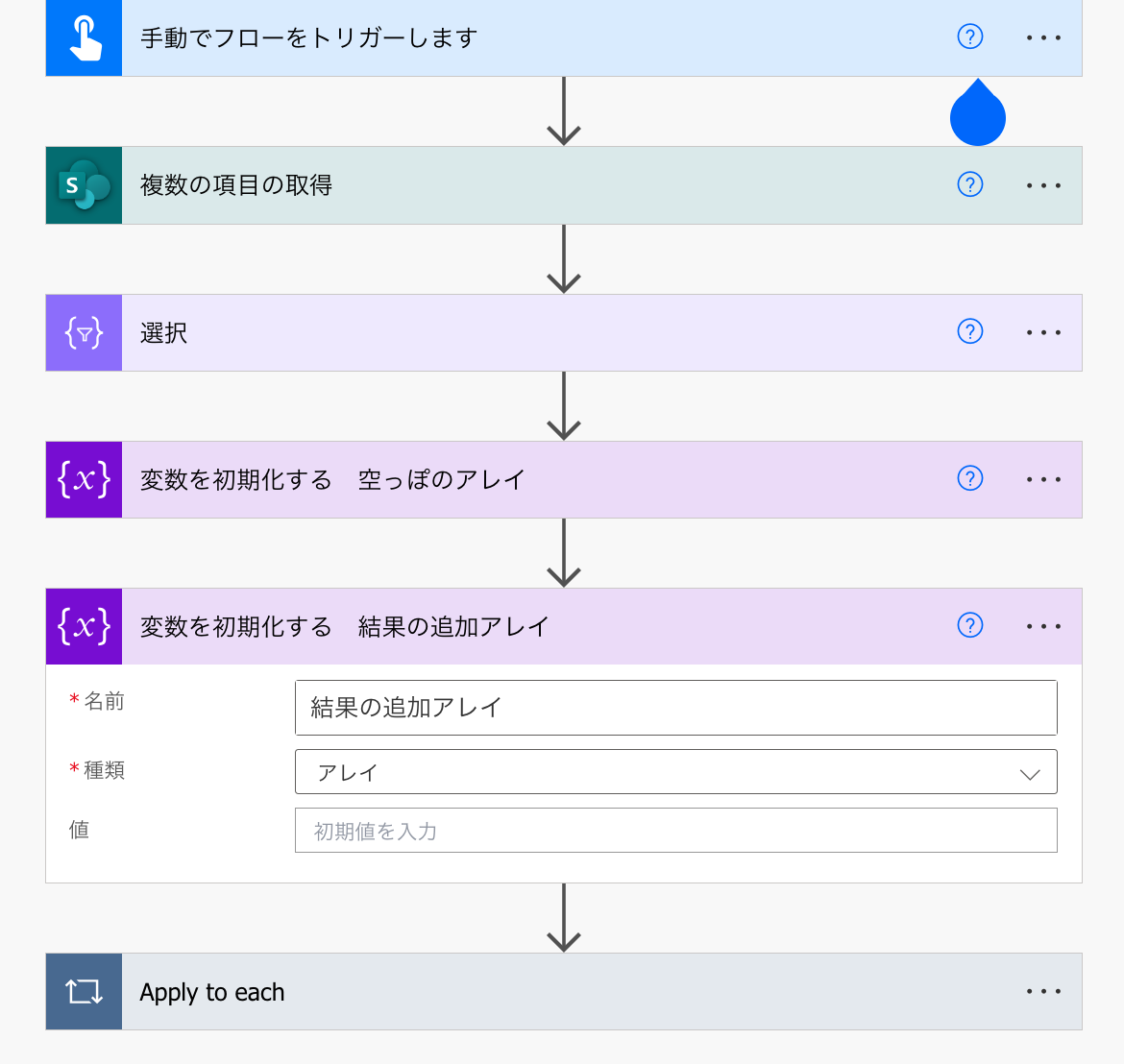
選択3の結果をアレイに追加してやります。

本当なら、これで配列に追加ができるはずなのですが、なぜかエラーが出てうまくいかず。
仕方がないので奥の手「作成」を使った方法で変数に追加をしてみました。
選択3の後ろに「作成2」を作り、union関数を使って既存の変数の内容と、新しく追加する内容を合体させます。
合体させた結果を変数に追加します。
union(body('選択_3'),variables('結果の追加アレイ'))

目的の結果をアレイ変数の中にいれられたら、Apply to eachの後ろ側で、変数に登録されたJSONの配列から、CSVテーブルへ変換させます。ファイル名には日付を表示する関数を加えます。
convertFromUtc(utcNow(),'Tokyo Standard Time','yyyyMMdd')

ファイル名に日付を入れるには、関数をつかうと便利ですが、以前にこの件について記事を書いたことがありますので、参考にしてください。
SPOのドキュメントライブラリに書き出されました。

CSVを開いてみると・・・・ おっと。文字化けしてました。

こちらも以前ブログに取り上げましたので参考にしてください。
「ファイルコンテンツ」の前に式で以下を追加します。
decodeUriComponent('%EF%BB%BF')

ふう。なんとかCSVファイルを出力することができました。お疲れ様でした。

ちなみに、結果のスクショでカウントが取得できていない「testFolder」というのは、SPOのページに作成したフォルダです。
フォルダの作り方もこちらで紹介していますので、試してみてください。
まとめ
ちょっと苦労しましたが、ページの閲覧総数、ユニークユーザー数、いいね数を取得することができました。クラウドフローを指定した期間で自動実行させれば、決まったフォルダに日付付きファイル名でCSVファイルとして保存できます。
決まったフォルダに決まったフォーマットでCSVファイルが置かれるので、あとはExcelのPower QueryやPower BI で分析ができます。
このあたりもそのうち記事にしようと思います。よかったら活用してください。