この記事で助かる人
SharePoint OnlineにCSVファイルがアップロードされたことをトリガーにして何かしたい人
ポイント
- ファイルのアップロードの検知には、「ファイルが作成されたとき」または「項目が作成された時」が使える
- CSVファイルをクラウドフロー内にとりこむには「ファイルコンテンツの取得」または「パスによるファイルコンテンツの取得」が使える
- CSVファイルは、初期化したテキスト変数の値に設定すると、そのまま文字列として扱える
この記事を書いている人
お仕事でPower Automateを使っていて、この記事は備忘録も兼ねてます。ブログにて、 クラウドフローのTIPSのようなもの を作っていますので、そちらも使ってもらえると嬉しいです。
準備
ファイルのアップロードを待ち受けるために、任意のSharePointサイトのドキュメントライブラリに、適当なフォルダを作成しておきます。

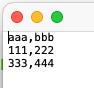
テスト用のCSVファイルも用意します。テキストエディタを使って適当なものを用意すれば良いでしょう。今回はこんなものを使いました。
aaa,bbb
111,222
333,444
方法1 「ファイルが追加されたとき」をトリガーにする
ShaerPointの項目の中で「ファイル」というキーワードで検索してみると、非推奨も含めていくつか見つかります。 まずは、「ファイルが作成されたとき(プロパティのみ)」というのがあるので、これを使ってみます。
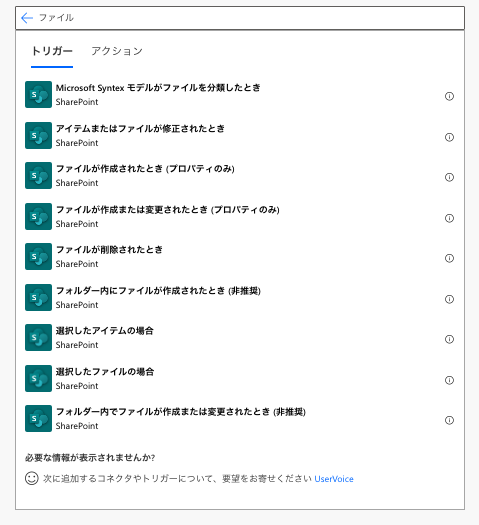
サイトアドレスとファイルを放り込むフォルダを指定します。結果を確認するために、「作成」の中にトリガーで得られた内容を入れておきます。準備ができたら、手動テストをクリック。
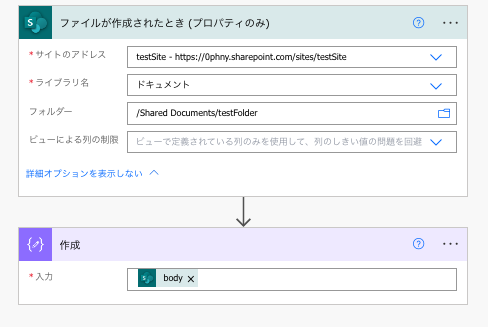
トリガーなので、実際に先ほど指定したフォルダに、用意したCSVファイルをアップロードしてみます。
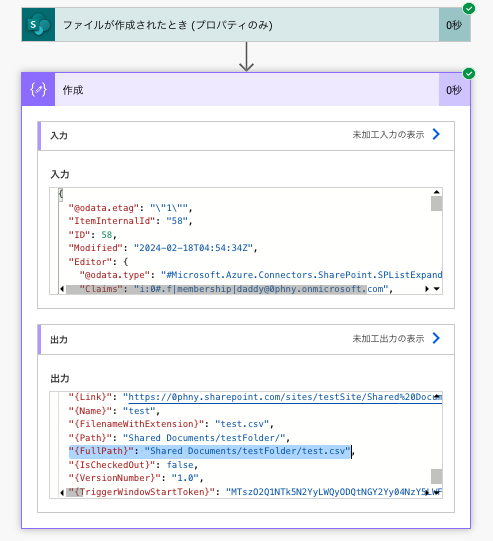
CSVファイルが指定されたフォルダに入ったことで、クラウドフローが動作しました。ファイルの場所とファイル名がFullPathの項目で取れています。
その2「項目が作成されたとき」をトリガーにする
その1のトリガーで動作すれば問題ないのですが、なぜか私が過去何回か同じようなトリガーを使った時に、うまくファイルの追加を検知してくれないという事がありました。
SharePointのフォルダ内に入っているファイルの情報というのは、内部ではSharePointリストを使って管理されています。そのため、リストに項目が追加されたことを検知する方法でも、ファイルが増えたことを検知してトリガーとして使うことができます。
SharePoint上のフォルダをリストとして扱うには、リストのIDが必要です。このIDの取得の方法は、別の記事 【SharePoint Onlineでサイトページからページ一覧を取得するために管理しているリストのIDを取得したい】 で紹介しましたので、そちらを参考にしてください。

その1と同じようにファイルのフルパスが取得できました!

アップロードされたフィイル自体を取得する
アップロードされたことを検知してトリガーを使ったクラウドフローの自動起動ができましたので、今度は実際にアップロードされたファイルの中身を利用するために、クラウドフロー内にファイルを取り込む処理を作ります。
そのためには、「ファイル コンテンツの取得」アクションを使います。トリガーで取得できた情報の中から、識別子として選択するのがポイントです。

ちなみに、別の方法として、「パスによるファイルコンテンツの取得」アクションを使うこともできます。使い方はほとんど同じですが、こちらの場合は「完全パス」を選択します。

CSVを行ごとに処理する
CSVファイルを1行ごとに処理していくには、1行をひとつの配列にしておく必要があります。配列ならばとループ処理をつかって順番に1行ずつ処理ができるようになります。
まず文字列の変数に取得したファイルコンテンツをいれてやります。

ファイルの中身がテキストとして取得できました。

CSVファイルの1行は改行を区切りとしています。区切り文字を指定してテキストファイルを配列にするにはSplit関数をつかいます。
あらかじめ、文字列変数を初期化して、値の中でいちどエンターキーを押します。こうすることで改行コードを変数として再利用ができます。
split(variables('CSVファイル'),variables('改行'))

これで実行してみると、各行を1つの配列として取得する事ができました。

ループで1行ずつ処理する
1行ごとに1要素の配列にすることができたので、あとはこれをループで回して、取り出したい部分を指定すればよいだけです。
各行は、「,」カンマ区切りで列が表現されているので、こちらもSplit関数を使って配列にしてやります。
ためしに、「作成」をつかって以下の式を実行してみます。
split(item(),',')

テスト実行すると、各行の要素がSplit関数によってさらに列として配列に分かれました。

ヘッダー行は無視する
ここで、aaa,bbb という先頭行はヘッダー(タイトル)なので無視したいです。こういう時にはカウンターと条件を加えましょう。カウンターがゼロの時には処理を行わず、カウンターがゼロ以上ならば動作をさせます。
ループの手前でカウンターを整数の変数として初期化しておきます。値は0にします。
ループのなかでは、このカウンターが0の時には何もしないことで、ヘッダー部分を無視する事ができます。

もうひとつのポイントは、CSVのなかの値を取得する部分です。Split関数でカンマ区切りで分けられた値は配列の各要素に入っていますから、1番目(1列目)には[0]、2番目(2列目)には[1]というように添え字をつけてやることで、配列から値を取り出せます。
split(item(),',')[0]
実行してみるとこんな感じになります。作成2のところには上記の関数が入っているので、ループの2回目には2行目1列目の「111」という値が取れました。配列からの値の取得の方法がわかっていれば、あとはリストやDataverse、Excelファイルなどで書き込むなり処理するなり自由に使えます。

おわりに
ファイルの取り込みは、トリガーで取得したファイルの場所を使う必要があることと、取得したファイルはそのままテキスト文字列として変数の中で扱えるのがポイントでした。
これがわかるまで、CSVを敬遠していました。さまざまなログはCSVで提供されることが多いので応用範囲は大きいのかと思います。ループは動作が遅いので、この辺りもう一工夫できそうですが、それはまた別の機会に。