超シンプルシリーズ今回は階層クラスタリングを超シンプルに記述してみます。
前処理フェーズのノウハウがあるので、今回もkaggle Titanicのデータを使用します。
前処理については下記をご参照ください(今回はデータ処理も本ブログで記載はしてます)
【Beginner】【AI】【機械学習】Light GBM: Titanic: Machine Learning from Disaster
マーケティング系の業務を行う際にユーザーを任意のクラスタに分けて、
それをベースにそれぞれに分析を重ねていくというケースが殆どだともいます。
たいていK-meansとかを良く使うと思いますが、そんなにビックデータでもなければ実は階層クラスタリングの方が簡単なチューニングも聞きますので実用性に富む場合があります。
なので今回は階層クラスタリングを実行するところまでを超シンプルに紹介します。
1.事前準備
まずは例のごとく良く使うライブラリをインポートしておきましょう。
import numpy as np
import numpy.random as random
import scipy as sp
from pandas import Series,DataFrame
import pandas as pd
import csv
import math
import string
import gensim
from gensim import corpora, models, similarities
import os
# 下記が階層クラスタリングのライブラリ
from scipy.cluster.hierarchy import linkage,dendrogram
上記にリンクもありますが簡単に前処理のコードも記載致します。
df000 = pd.read_csv("train.csv",encoding="CP932")
# 欠損値状況を確認(アウトプットは省略しますので実行してみてください)
df000.isnull().sum()
# まずは年齢の欠損値を平均値で補完
df001 = df000
df001["Age"] = df000["Age"].fillna(df000["Age"].describe()["mean"])
# すいません何故がこのタイミングで説明変数を精査(必要なものをdrop)
df003 = df002.drop(["PassengerId","Name","Ticket","Cabin","Embarked"],axis=1)
# カテゴリ変数のダミー化(性別をダミー化します)
df004 = pd.get_dummies(df003["Sex"])
# ダミー化した性別情報を元のデータフレームに結合し、カテゴリ"Sex"を削除します
df005 = pd.concat([df003,df004],axis=1)
df006 = df005.drop("Sex",axis=1)
はい。ここまでが簡単なデータ前処理となります。
もちろん他にも多くの効率的な方法がありますが、ご容赦ください。
2.階層クラスタリングの実行
次に階層クラスタリングを実行しますが一行で終了致します。
下記です。
# 階層クラスタリングの実行
df007 = linkage(df006,metric = 'euclidean',method="ward")
これでデータフレームの階層化が終了しました。(早い)
この部分は"metric"と"method"の部分でチューニングが可能です。
各変数一覧については本ブログの最後に掲載いたします。
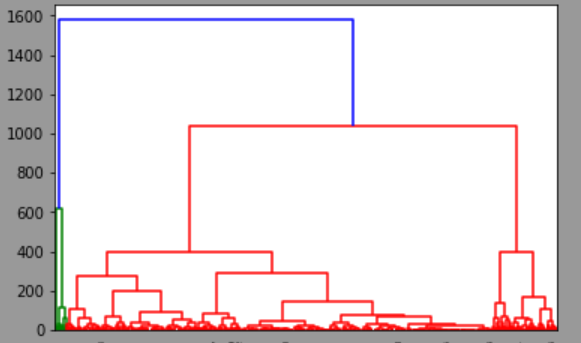
ちなみに階層結果をビジュアライズすることも可能です。
良く言うデンドログラムというやつです。
余り実業務で使うこと無いですけど、クラスタリングやった感はでます。
# 階層結果のビジュアライズ
plt = dendrogram(df007)
output:
次に自身が分けたい任意の数でクラスタを分けたいときののコードを紹介します。
K-meanと違い階層クラスタリングは分けたい数でクラスタリングを分けることが出来るため使いやすいなと感じます。
# cut_treeファンクションでクラスタを任意のクラスタに分けれるようにします
cuttree = cut_tree(df007)
# 下記の例では3つのクラスタに分けます
df008 = cuttree[:,-3]
# 元のファイルにクラスタ数を結合(
df006["cluster"] =df008
3に分けるときに"-3"と書くところは少し注意ですね。
最後に結合したファイルをcsvで吐き出して、レーダーチャートなりグラフなりでEDA(Exploratory Data Analysis)してみて、最適なクラスタを探してみてください。
「最適なクラスタを探すってどうやるの?」といった場合、
主に行うのは3つです。
1.linkage()の際のmetricとmethodのパターンを変えてみる
2.最後cuttree()のクラスタ数を変えてみる
3.そもそもインプットデータの特徴量を変えてみる
上記行ってみてクラスタの特徴がはっきりと分かれるクラスタを見つけてみてください。
Ref.linkage()のチューニング要素
linkage()関数のチューニング要素metricとmethodの一覧は下記です。
metric
euclidean:ユークリッド距離
minkowski:ミンコフスキー距離
cityblock:マンハッタン距離
seuclidean:標準化されたユークリッド距離
sqeuclidean:乗ユークリッド距離
cosine:コサイン距離 (1からベクトルの余弦を引いたもの)
correlation:層間距離(1から標本相関を引いたもの)
hamming:異なる座標の比率を示すハミング距離
jaccard:1からジャカード係数を引いた値
chebychev:チェビシェフ距離(最大座標差)
canbella:キャンベラ距離
braycurtis:ブレイ・カーティス距離
mahalanobis:マハラノビス距離
method
single
complete
average
weighted
centroid
median
ward
参考にしたのは下記のリンクです。
metric
https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.linkage.html
method
https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.linkage.html
組合せは任意ですが、データが密集していてあまりうまく分けれない場合は
metric=euclidean
method=ward
の組合せだとうまく分けれるケースが多いです。
あとがき
現状下記の2点が良く分からなくて調査中です
・なぜかcuttreeが効かなくなる時がある...
・method = wardを使用するときmetricはeuclideanしか使えない。。
→他にも組合せあるのか、それとも使うようにする方法があるのか。。
分かる人いればコメ頂きますと助かります。