今回はKaggle Competitionの中からテキストマイニングについての課題である、
"Bag of Words Meets Bags of Popcorn"を取り扱いたいと思います
開発環境の整備、Kaggleってなに?等の疑問に関しては下記のリンクをご参考下さい
【Beginner】【AI】【機械学習】Light GBM: Titanic: Machine Learning from Disaster
ユーザーレビューの内容からそれがネガティブなのかポジティブなのかを予測するテキストマイニング系のコンペティションとなります
文章という非構造的なデータをどのように加工することで、予測判定モデルが作成できるようになるのかを下記のステップで説明させて頂きます。
1.データの確認
2.データの綺麗化
3.テキストデータの数値化
4.数値化されたテキストデータの学習、評価判定モデルの作成
テキストマイニングの一般的な分析の流れが上記になりますので、汎用的に使えるステップとなると思います。
それでは早速分析を進めていきましょう。
1.データの確認
train001 = pd.read_csv("labeledTrainData.tsv",delimiter="\t")
Pythonでは、各データがタブで区切られた".tsv"ファイルもread_csvで読み込むことが出来ます。
この際にタブ区切りのデータを読み込む際に必要な因数、delimiter="\t"を忘れずに追記します。
アウトプットを確認したら下記の様になっております
"sentiment" 1ならポジティブ(高評価)、0ならネガティブ(低評価)といった具合です
"review" ここに実際の評価コメントが載っております。これを分析して低評価、高評価における特徴を分析します
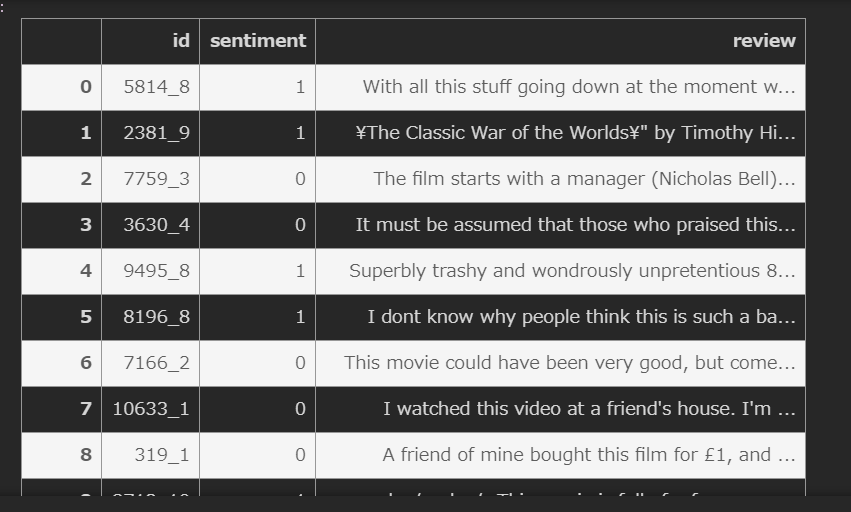
試しにreviewの中身を1行見てみましょう
train001.loc[0,"review"]
中身を見ると、htmlタグが残っている、ダブルクォーテーションが残っている等、分析のためを考えるとデータがきれいな状態ではないです。

なので、文章データの綺麗化について下で見ていきましょう。
2.データの綺麗化
データの綺麗化は下記の手順で行います。
- htmlのタグ消し
- 文字以外の(?,!等)の除去
- 全ての文字を小文字に
- ストップワードの削除
まずはhtmlのタグ消しから見ていきましょう
Beautiful Soupというライブラリを使用します
from bs4 import BeautifulSoup
soup = BeautifulSoup(train001.loc[0,"review"])
train002 = soup.get_text()
上記実行後、出力を見てみましょう
</br>といったhtmlタグが削除されていることが確認できます。

次に、2. 文字以外の(?,!等)の除去に進みます
import re
train003 = re.sub("[^a-zA-Z]"," ", train002)
これで削除完了です。
次に、3. 全ての文字を小文字にします
train004 = letters_only.lower()
こちらもこれで変換完了となります。
最後に4. ストップワードの削除を行います。
ストップワードとは、あまりにも使われる単語のため、テキストデータを扱う時によく除去される言葉です。「a」「the」「an」といった冠詞などが代表的ですね。
ストップワードは自身で設定することも可能なのですが今回は、ストップワードのパッケージを利用致します。
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
ちなみに、どういったストップワードが登録されているかは下記のプログラムで確認することが出来ます
stopwords.words("english")
文章からストップワードを削除するコードは下記です。
train005 = [w for w in train004 if not w in stopwords.words("english")]
このステップを踏むことでデータの綺麗化が行えます。
これらの処理を関数化してみましょう。
from bs4 import BeautifulSoup
import re
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
# これまでの作業の関数化
def review_to_words(raw_review):
#1.htmlのタグ消し
review_text = BeautifulSoup(raw_review).get_text()
#2.文字以外の(?,!等)の除去
letters_only = re.sub("[^a-zA-Z]", " ", review_text)
#3.全ての文字を小文字に
words = letters_only.lower().split()
#4.StopWordsリストの作成
stops = set(stopwords.words("english"))
#5.StopWords Remove
meaningful_words = [w for w in words if not w in stops]
#6.文にして結果を返す
return(" ".join( meaningful_words))
上記の関数を全てのレビューに適用しましょう
# 全てreviewのクリーニング化
# count_reviews
count_reviews = train001["review"].size
# train003:all review clean
# 配列の初期化
train003 = []
for i in range(0,count_reviews):
train003.append(review_to_words(train["review"][i]))
# reviewの内容が全て''で区切られてtrain003に格納
上記を表示すると、全てのreviewの内容が''で区切られてtrain003に結合されているのが確認できます。
3.テキストデータの数値化
以上綺麗化されたテキストデータを数値化していきます。
テキストデータの数値化の方法には大きく二つ下記が存在します。
1.CountVectorbizer
→単純に特定の単語が何回登場したかをカウントし特徴量とします
2.TfidfVectorizer
→カウントだけでは単語に偏りが発生する恐れがあるので、
TF(単語の出現頻度)とIDF(指定単語のレア度)を掛け合わせたTF * IDFの値を特徴量とします

参考リンク:機械学習 〜 テキスト特徴量(CountVectorizer, TfidfVectorizer) 〜
[TF IDF]
(https://qiita.com/AwaJ/items/5937665d5a4152cc24cf)
今回はCountVectorizerを利用します
# scikit-learnからCountVectorizerをimport
from sklearn.feature_extraction.text import CountVectorizer
# 初期化:CountVectorizerを使うよ、という宣言
vectorizer = CountVectorizer(analyzer="word",
tokenizer= None,
preprocessor= None,
stop_words= None,
max_features=5000) #特徴量の数を5000に設定
上記の関数を利用して、テキストデータの綺麗化を行ったtrain003を利用して特徴量ベクトルを作成していきます。(テキストデータを数値化していきます)
アウトプットのイメージは下記です
濃い黄色がreview番号、薄い黄色が特徴量として選ばれた単語になります、これらの単語は該当review上に何回出てきたかをカウントして数値として登録します
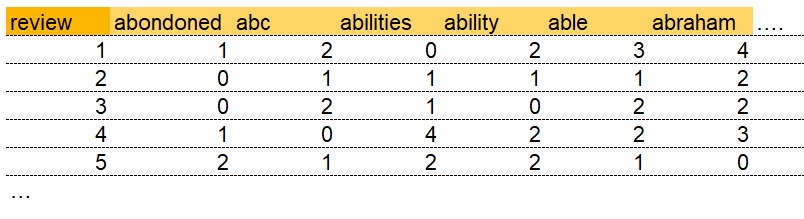
上記マトリックスを作成するコードは下記です
# 特徴量ベクトルの作成
train004 = vectorizer.fit_transform(train003)
# 25,000 x 5,000のデータセットを確認
これにより25,000人分のreviewに5,000単語を特徴量とし、その出現回数をカウントしたマトリックスが作成されます
(この際に使用する特徴量は自身で指定することもできますが、全文書の状態を確認し、カウントしやすいものを"fit_transform"実行中にプログラムが自動で選んでもくれます)
またどのような単語が特徴量として選ばれたのかは、下記のコードで見ることが可能です。
# どの単語が特徴量に選ばれたのかの確認
train005 = vectorizer.get_feature_names()
4.数値化されたテキストデータの学習、評価判定モデルの作成
次に上記までで、数値化したテキスト情報を用いて、どういった数値を記録したら"良い評価"か、"悪い評価"かをランダムフォレストを用いて学習させます。
まずランダムフォレストにこれまでの各reviewの特徴量のカウントとその場合の評価結果(sentiment)を学習させます
# Random Forestを用いた学習と予測
from sklearn.ensemble import RandomForestClassifier
# 初期化
forest = RandomForestClassifier(n_estimators=100)
# Random Forestの学習(.fit(説明変数、目的変数)
forest = forest.fit(train004, train["sentiment"])
次に判定を予測するテストデータを読み込み、訓練データと同様にテキストデータの綺麗化を行います
# テストデータの読み込み
test = pd.read_csv("testData.tsv",header=0,delimiter="\t",quoting=3)
# 配列の初期化
clean_test_reviews=[]
# 関数"review_to_words"の適用(訓練データの時と同様)
for i in range(0,count_reviews):
clean_review = review_to_words( test["review"][i] )
clean_test_reviews.append( clean_review )
次に綺麗化を行ったテキストデータをモデル適用が出来る形、つまり特徴量によってベクトル化された形に変換致します
# テストデータを単語ベクトルの形にする
test_data_feature=vectorizer.transform(clean_test_reviews)
test_data_feature=test_data_feature.toarray()
predict関数を用いて上記のinputデータから評価を予測します
# 学習したRFを用いて予測
result=forest.predict(test_data_feature)
予測した結果をkaggleにsubmit出来る形でcsvとしてアウトプットします
output = pd.DataFrame( data={"id":test["id"], "sentiment":result} )
output.to_csv( "Bag_of_Words_model.csv", index=False, quoting=3 )
以上で、テキストマイニングのすべての工程が終了致しました。
最後に
上記の予測モデルをkaggleにsubmitしたところ結果が下記でした
精度は84%。まずまずといった結果です。
特徴量をTFIDFにするまたは、Random Forestのチューニングを頑張れば更に精度向上が目指せそうです。
