- 製造業出身のデータサイエンティストがお送りする記事
- 今回はLazypredictを使ってみました。
Lazypredictとは
Lazypredictは、AutoMLではないですが複数行のコードで数十のモデルを構築して比較する事が可能なライブラリーです。回帰問題と分類問題に使用する事ができます。
細かい内容はGithubリポジトリを参照して頂けますと幸いです。
Lazypredictの実装
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
最初にライブラリーをインストールしますが、pipで簡単にインストール可能です。
pip install lazypredict
ここから、普通にライブラリーをインポートして行きます。
# ライブラリーのインポート
import os
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# ボストンの住宅価格データ
from sklearn.datasets import load_boston
# 前処理
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Lazypredict Regressor
from lazypredict.Supervised import LazyRegressor
import lazypredict
# データセットの読込み
boston = load_boston()
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
# データの中身を確認
df.head()
次にデータセットを分割します(train, valid, test)。
# ランダムシード値
RANDOM_STATE = 10
# 学習データと評価データの割合
TEST_SIZE = 0.2
# 学習データと評価データを作成
x_train, x_test, y_train, y_test = train_test_split(
df.iloc[:, 0 : df.shape[1] - 1],
df.iloc[:, df.shape[1] - 1],
test_size=TEST_SIZE,
random_state=RANDOM_STATE,
)
次にモデルの学習を行います。
# Lazy Predict(回帰)の設定と実行
reg = LazyRegressor(
verbose=0,
ignore_warnings=False,
custom_metric=None,
predictions=True,
random_state=RANDOM_STATE,
)
models, predictions = reg.fit(x_train, x_test, y_train, y_test)
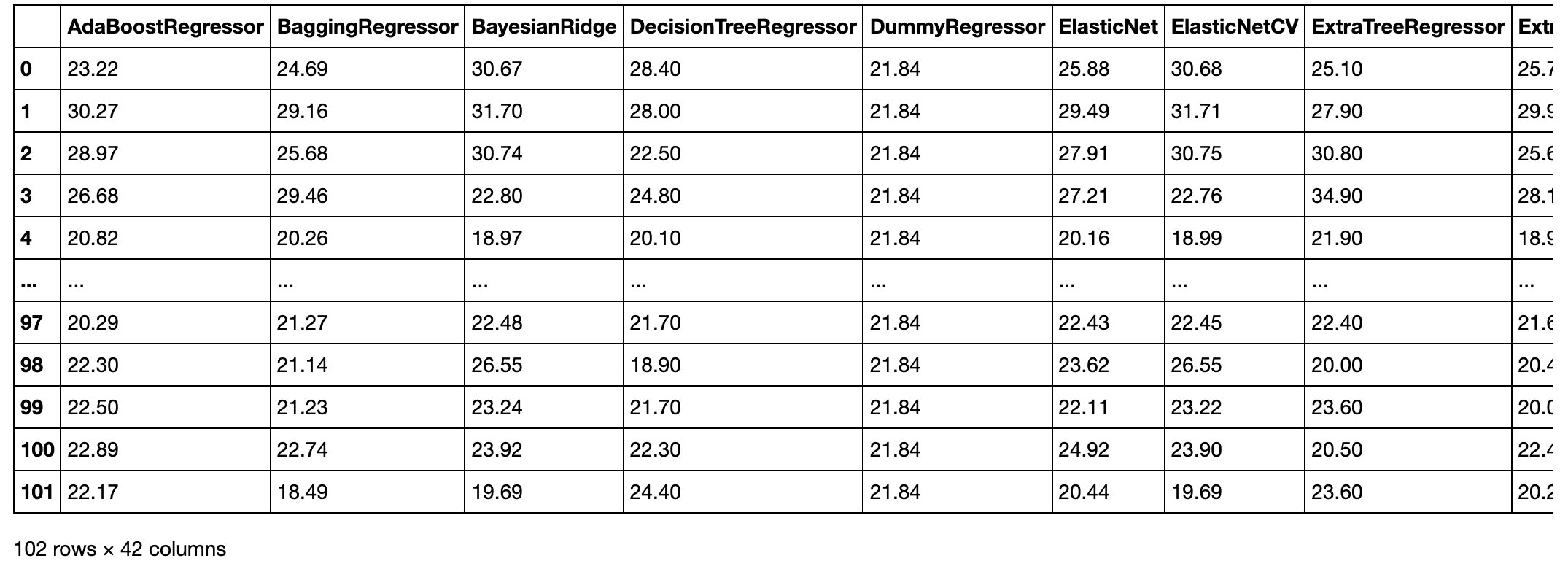
構築したモデルのtestデータに対する評価指標一覧はmodelsに格納されております。
# 検証結果
models
一部だけをアップしますが、下記のようにDataFrame形式で格納されております。

各モデルの予測結果も簡単に確認することができます。
# 予測値
predictions
さいごに
最後まで読んで頂き、ありがとうございました。
今回はLazypredictを使ってみました。
機能的には他のAutoMLライブラリーの方が良いですが、簡単に実装する上では数行で済むため良いなと思いました。
訂正要望がありましたら、ご連絡頂けますと幸いです。