- 製造業出身のデータサイエンティストがお送りする記事
- 今回は、統計的因果探索手法の一つであるLiNGAMを実装してみました。
はじめに
製造現場でデータサイエンスを行っている際、相関関係と因果関係をきちっと切り分けて分析することが重要だと思います。今回、データから因果関係を推測するための機械学習技術である統計的因果探索を勉強しましたので、その中の1つ「LiNGAM」について整理しました。
細かい理論的な部分は書籍を参照して頂ければと思います。
LiNGAMの流れ
今回、実装するLiNGAMモデルは、独立成分分析の手法を用いた方法になります。
具体的な因果関係は下記構造方程式の$\boldsymbol{B}$を推定することで実現します。
$$\boldsymbol{x} = \boldsymbol{B}\boldsymbol{x} + \boldsymbol{e}$$
$\boldsymbol{B}$はICA(独立成分分析)による混合行列を上記仮定を用いて一意に特定します。
$\boldsymbol{B}$は下記仮定より、正しい因果関係で置換すれば上三角部分が0となります。
- 未観測共通原因が存在しない
- 有向非巡回モデルである
- 各変数が連続変数である
- 各変数の誤差項は非ガウス分布に従う
- 各変数の関係は線形である
しかし、実際に得られる推定行列は、要素に0に近い値を持った$\boldsymbol{\hat{B}}$です。
ここから$\boldsymbol{B}$を推定するには、$\boldsymbol{P}$$\boldsymbol{\hat{B}}$$\boldsymbol{P}^T$の上三角部分が最小となるような置換行列$\boldsymbol{P}$を求めるという手法を取っているそうです。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いてLiNGAMを構築します。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
import graphviz
import lingam
from lingam.utils import make_dot
print([np.__version__, pd.__version__, graphviz.__version__, lingam.__version__])
np.set_printoptions(precision=3, suppress=True)
np.random.seed(100)
次にデータを読み込みます。
# データセットの読込み
boston = load_boston()
# データフレームの作成
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
# データの中身を確認
df.head()
次にグラフ構造を可視化するための関数を作成します。
def make_graph(adjacency_matrix, labels=None):
idx = np.abs(adjacency_matrix) > 0.5
dirs = np.where(idx)
d = graphviz.Digraph(format='png', engine='dot')
# フォント設定
d.attr('node', fontname="MS Gothic", fontsize="10")
names = labels if labels else [f'x{i}' for i in range(len(adjacency_matrix))]
for to, from_, coef in zip(dirs[0], dirs[1], adjacency_matrix[idx]):
d.edge(names[from_], names[to], label=f'{coef:.2f}', fontsize="10")
return d
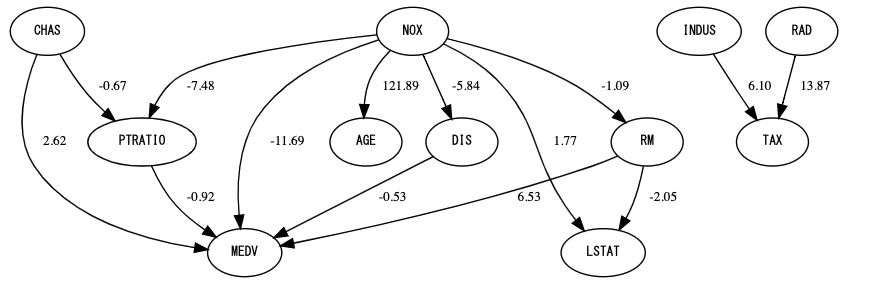
ここから、LiNGAMを用いてモデルを学習し、可視化します。
model = lingam.DirectLiNGAM()
model.fit(df)
labels = [f'{i}. {col}' for i, col in enumerate(df.columns)]
make_graph(model.adjacency_matrix_, labels)
さいごに
最後まで読んで頂き、ありがとうございました。
結構簡単に利用できることが分かりました。ノードはパラメータの設定次第で結果が変わってくるため、調整は必要ですが、これで因果関係を可視化できそうです。
訂正要望がありましたら、ご連絡頂けますと幸いです。