はじめに
つたないQiitaの投稿ですが、それなりに記事数が増えてきたので、
50回目の記事投稿のテーマとして、Power Automateを利用したQiitaの記事一覧の取得を
選定しました。
普段アウトプットに取り組まれている方のお力になれれば何よりです。
概要
今回はPower Automateにて、Qiita API v2から、記事情報の一覧を取得し、
SharePointにCSVファイルとして保存します。
記事投稿の一覧を取得するうえで、下記の記事と公式ドキュメントを参考にしました。
1. 参考にさせていただいた記事
2. 公式ドキュメント
ざっくり手順
| No | アクション | 詳細 |
|---|---|---|
| 1 | 作成 | CSVのファイル名用にyyyyMMddで本日日付を取得 |
| 2 | 作成 | QiitaのUserIDを格納 |
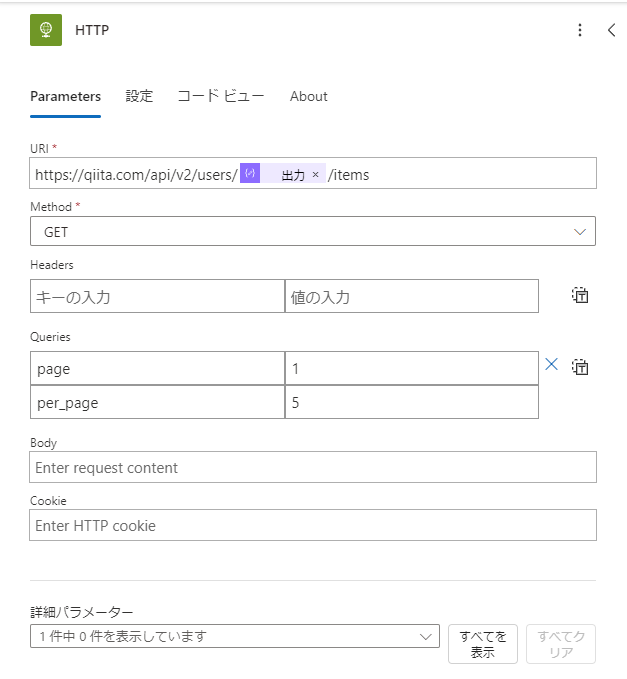
| 3 | HTTP |
Qiita API v2に要求を送信する |
| 4 | JSONの解析 | 戻り値を使いやすいように設定 |
| 5 | CSV テーブルの作成 | 必要な列のみ抽出 |
| 6 | ファイルの作成 | SharePointにCSVを作成 |
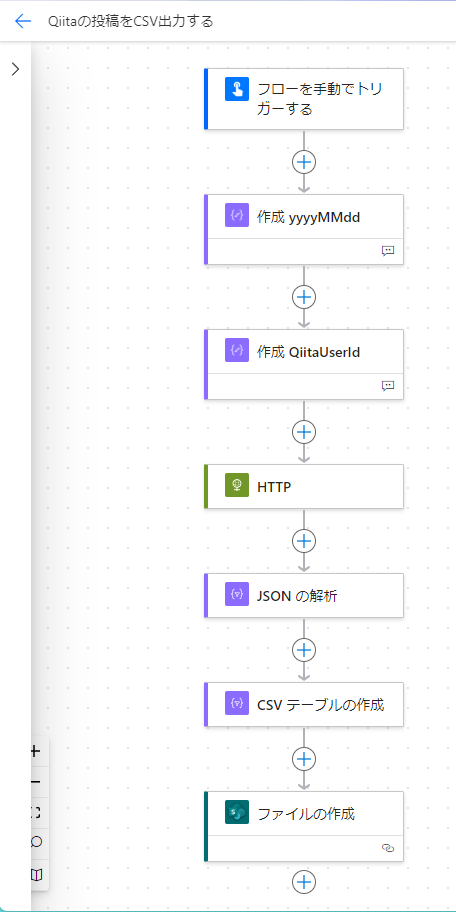
作成アクションでファイル名とUserIDを設定
今回のフローでいう定数や変数の立ち位置にくるものです。
何気にややこしいyyyyMMdd
本日日付は、utcNowをconvertTimeZoneしたうえで、日付書式文字列に変えています。
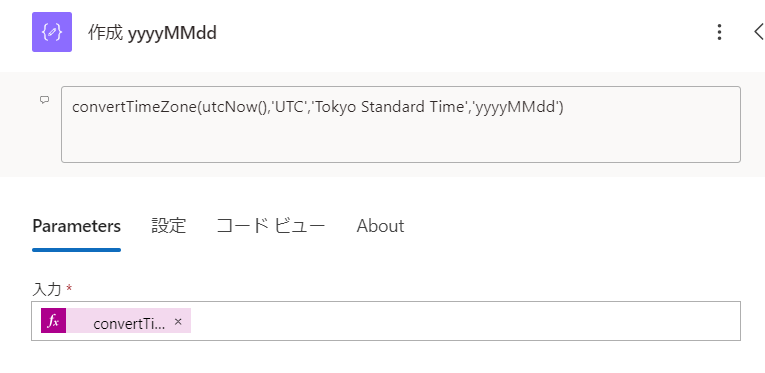
convertTimeZone(utcNow(),'UTC','Tokyo Standard Time','yyyyMMdd')
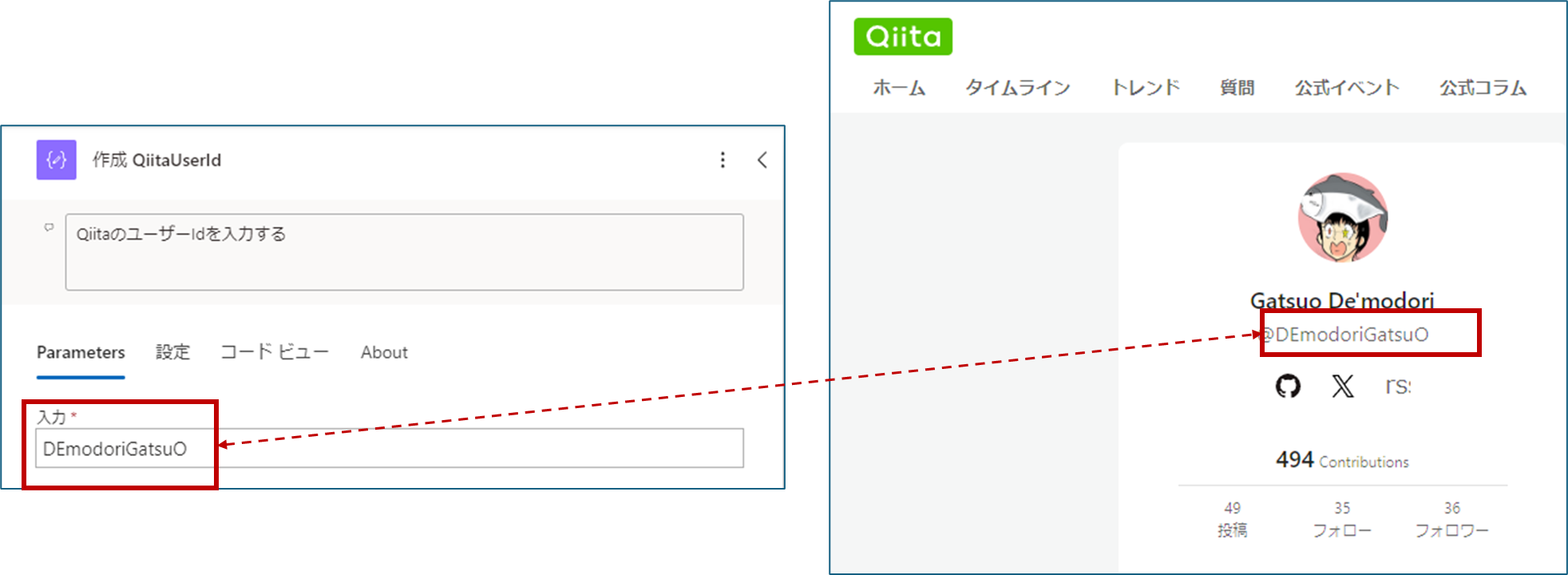
QiitaのUserID
自分の画面でいうと下記のとおりです。
肝心なHTTP要求 Qiita API v2
- Qiita APIのURI
https://qiita.com/api/v2/users/@{ユーザーID}/items
こちらに、パラメーターであるpageとper_pageを設定します。
URIに直接書くと下記のようになります。
https://qiita.com/api/v2/users/@{ユーザーID}/items?page=1&per_page=5
個人的にPower AutomateでQueriesとして別で設定できることが好みなので、画像のとおり設定しています。
| Key | Value | Memo |
|---|---|---|
Method |
GET |
|
| page | 1 | ページ番号 |
| per_page | 50 | 1ページあたりに含まれる要素数 |
記事数が多い方は上記の設定にお気を付けください。
私はまだまだ少ないので、pageは1、per_pageの設定を、Qiitaの記事数に設定します。
HTTPの戻り値
Qiita API v2を利用すると、戻り値で、ページのタイトルやURLやいいね数など
多くの値が取得できます。
JSONの解析では、私の例の場合、下記のスキーマを設定しております。
JSONの解析
{
"type": "array",
"items": {
"type": "object",
"properties": {
"rendered_body": {
"type": "string"
},
"body": {
"type": "string"
},
"coediting": {
"type": "boolean"
},
"comments_count": {
"type": "integer"
},
"created_at": {
"type": "string"
},
"group": {},
"id": {
"type": "string"
},
"likes_count": {
"type": "integer"
},
"private": {
"type": "boolean"
},
"reactions_count": {
"type": "integer"
},
"stocks_count": {
"type": "integer"
},
"tags": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"versions": {
"type": "array"
}
},
"required": [
"name",
"versions"
]
}
},
"title": {
"type": "string"
},
"updated_at": {
"type": "string"
},
"url": {
"type": "string"
},
"user": {
"type": "object",
"properties": {
"description": {
"type": "string"
},
"facebook_id": {
"type": "string"
},
"followees_count": {
"type": "integer"
},
"followers_count": {
"type": "integer"
},
"github_login_name": {
"type": "string"
},
"id": {
"type": "string"
},
"items_count": {
"type": "integer"
},
"linkedin_id": {
"type": "string"
},
"location": {
"type": "string"
},
"name": {
"type": "string"
},
"organization": {
"type": "string"
},
"permanent_id": {
"type": "integer"
},
"profile_image_url": {
"type": "string"
},
"team_only": {
"type": "boolean"
},
"twitter_screen_name": {
"type": "string"
},
"website_url": {
"type": "string"
}
}
},
"page_views_count": {},
"team_membership": {},
"organization_url_name": {},
"slide": {
"type": "boolean"
}
},
"required": [
"rendered_body",
"body",
"coediting",
"comments_count",
"created_at",
"group",
"id",
"likes_count",
"private",
"reactions_count",
"stocks_count",
"tags",
"title",
"updated_at",
"url",
"user",
"page_views_count",
"team_membership",
"organization_url_name",
"slide"
]
}
}
👆長いので折りたたみにしています
JSON の解析で表示しているスキーマは、私の記事の投稿状況で、作成した例になるので、
私の例をコピペして上手くいかない場合は、一度HTTP要求を送信して、サンプルの JSON ペイロードを入力するか、貼り付けすることをお勧めします。
CSV テーブルを作成
データ操作アクションの一つである、CSV テーブルを作成を実行します。
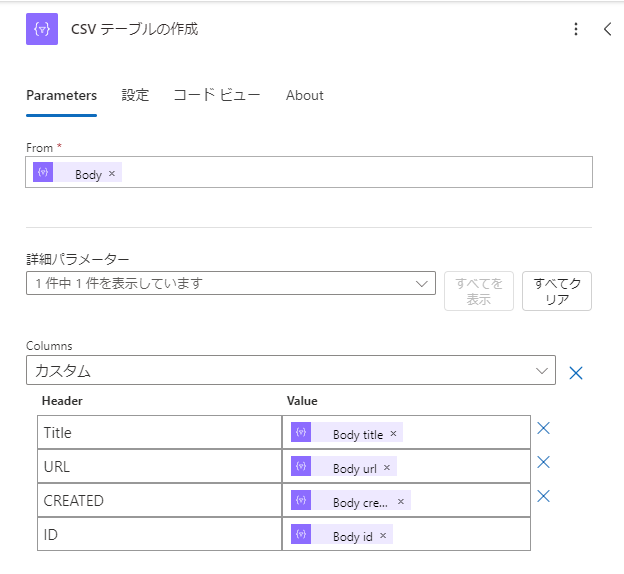
| Title | URL | CREATED | ID |
|---|---|---|---|
| 記事のタイトル | リンク | 作成日付 | ID |
| ↓ | ↓ | ↓ | ↓ |
上記のテーブルをこちらで作成します。
ファイルの作成
最後にファイルの作成で、CSVをSharePointに出力します。
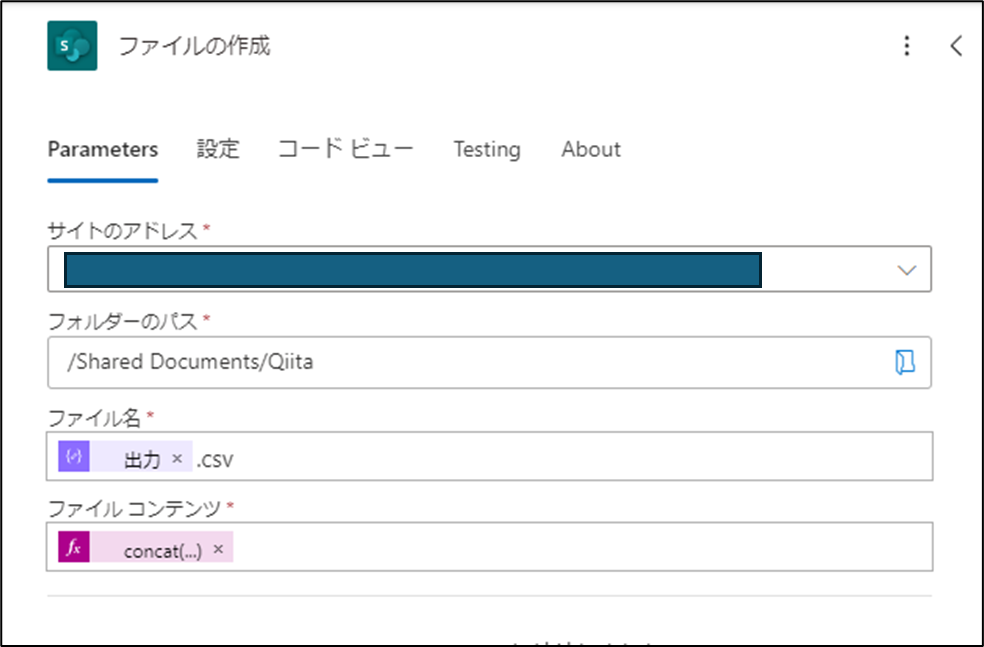
SharePointでなくても、OneDriveやOneDrive for Businessでも同様の操作が可能です。
CSVテーブルの作成ですが、そのままCSVテーブルの作成のOutputを設定してしまうと、
文字化けしてしまいます。
対策で下記の関数をファイル コンテンツに設定して、文字化け対策をします。
concat(decodeUriComponent('%EF%BB%BF'),body('CSV_テーブルの作成'))
実行結果

おわりに
つたないアウトプットですが、継続中です!
良いPower Lifeを!