はじめに
こんにちは!出戻りガツオ🐟です。
AI時代が到来し、ワクワクしますね♬
AIをもっと楽しみたい!という方向けに、
推しのAzure AI Serviceを紹介させてください!
learnやBing AIでも調査できる時代かもしれませんが、
とりあえずやりたい!という人向けに 「こうやればいいのか!」 ということに繋がれば何よりです!
Azure Applied AI Services
Azure Applied AI Servicesは多様です。
- Azure Bot Service
- Azure Form Recognizer
- Azure Cognitive Search
- Azure Metrics Advisor
- Azure Video Indexer
- Azure Immersive Reader
- Azure Cognitive Services
- Azure Machine Learning
今回ご紹介するのは 「Azure Cognitive Services」
現在進行形でPower Appsを作成しており、
- Text to speech
- Speech to text
- Azure OpenAI
これを組み合わせた作品にしようと思っています!
作りながら同時に アウトプット! ということで経験をシェアしていこうかと!
今回のテーマはText to speech!
文字から音声を生成するAI Serviceになります。
Azure Cognitive Service
Azureのサービスの一つとしてC#やPythonを使った連携も出来ますし、
APIを使った連携も可能。

Power AppsでもAI Builderが使えますが、
さらに多くのサービスに拡張することができます。
Azure + Power Platformで可能性は∞!!
Power Apps + Power Automateで楽しんでいこうと思います!
必要なもの
- Azure サブスクリプション
- Power Platform 開発環境
- Azure OpenAIが使える状態になっていること(申請が必要です)
- ワクワクした気持ち
Text to speech
今回は「Text to speech」を使って、
Power AppsでLabelのテキストを読み上げするアプリを
作っていきます。
ちょうど今日完成したものがこちら!
上記の動画に限らず、音声の設定も色々な種類に変えられます。
例を見るにはCognitive ServiceのSpeech Studioが最適です!
どんな音声なのか、などサンプルが聞けたりみれますよ♪
Azureでリソースを作成する
まずはCognitive Servicesのリソースを作成します。

上記のようなマークです。
※Azureのリソースの作成方法などは今回割愛します。
この中で使うサービスは 「音声サービス」(Speech Service) です。
このリソースを作成することにより、独自のAPIを作成して、
自分好みのAI活用が実現できます。
詳しくは「AI-900: Microsoft Azure AI Fundamentals」のラーニングパスをオススメします。
Text to speechをPower Automateで使うには
音声サービスがアクティブなので、やることは単純です。
POSTでURIにHTTP要求を発信します。
ヘッダーは
| key | value |
|---|---|
| Ocp-Apim-Subscription-Key | 自分のサブスクリプションキー |
| Content-Type | application/ssml+xml |
| X-Microsoft-OutputFormat | audio-16khz-128kbitrate-mono-mp3 |
上記を設定します。
SSMLとは
Speech Synthesis Markup Languageというマークアップ言語です。
XMLベースマークアップ言語になります。
この言語によって
- 言葉
- 性別
- スピーカーのモデル
を設定することができます。
今回は下記の設定です。
| param | value |
|---|---|
| language | English US |
| Gender | Male |
| Model | ChristopherNeural |
Modelは 事前構築済みのニューラル音声 です。
驚くほど自然な読み上げを実現することが出来ます。
今回使用しているのは事前構築済みの音声ですが、カスタムモデルも作成ができますので
物凄い技術だなと圧巻です。
ちなみに上記の情報は、Speech Studioの他のモデルにも変えることができます。
詳しくは下記をご参照ください。
エスケープ文字があり、若干わかりづらいですが、
lang gender nameを設定すれば、モデルを変えることがわかります。
Power Appsの設定
今回はボタンコントロールで、Label1のTextを引数にして、コンテキスト変数に音声データを格納します。
戻り値はbase64形式なので、オーディオ要素のMediaプロパティは、
数式の先頭にdata:audio/mpeg;base64,を追加すれば上手く機能します。
data:audio/mpeg;base64,(戻り値のテキスト)
Power Automateの設定
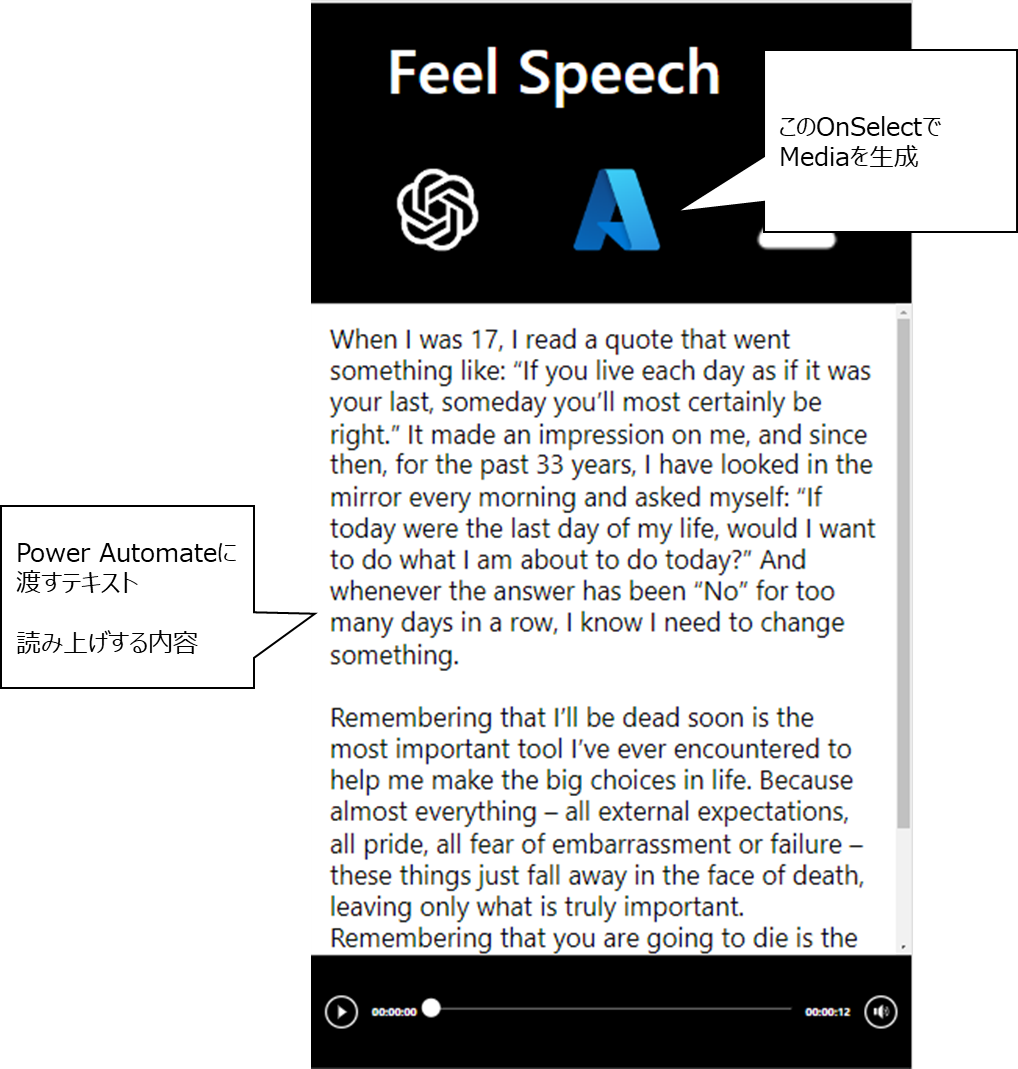
ボタンのOnSelectプロパティにPower Automateを設定します。
Label1のTextをフローに渡します。
Power Automate

HTTPの設定
| config | Value |
|---|---|
| 方法 | POST |
| URI | https://{Cognitive ServiceのRegion}.tts.speech.microsoft.com/cognitiveservices/v1 |
Body
<speak version='1.0' xml:lang='en-US'><voice xml:lang='en-US' xml:gender='Male'
name='en-US-ChristopherNeural'>
@{triggerBody()['text']}
</voice></speak>
HTTP要求が成功するとオブジェクト値が返ってくるのでbodyの中の$contentを抽出します。
Power Automateの戻り値は下記の通りとなります。
@{body('HTTP')?['$content']}
実行することによってbase64形式の文字列が返ってきます。
私の環境ではフローの完了までとても速いです。
👆に掲載したTwitterの動画で、試しにSteve Jobsの名演説を流してみてください。
凄くクリアに聞こえます。ニューラル音声恐るべしです。
今後の展望
今回はText to speechを紹介しましたが、
- Azure OpenAI
- Speech to text
にも触れていきます。
検証しているのは、English Reading Appsなので、
AIを叩いて英語学習を楽しんでみる予定です!
今後のQiitaにもご注目ください!
いつかこのネタで登壇するつもりです🐟✨
お読みいただきありがとうございました!