はじめに
こんばんは。
出戻りガツオ🐟です。
知人の凄い方が下記の記事をシェアされていました。
なんと LINEのNLP Foundation Devチームから日本語言語モデルが発表されたとのこと!
とりあえずどんな感じなんだろ?ということで調べてみました。
2023.08.16でわかった分の検証結果です。
japanese-large-lm(ジャパニーズ ラージ エルエム)
最大の特徴は日本語であることですよね。
下記のページに、このような記載があります。
Tokenization
We use a sentencepiece tokenizer with a unigram language model and byte-fallback. We do not apply pre-tokenization with Japanese tokenizer. Thus, a user may directly feed raw sentences into the tokenizer.
上記のブログなどでも確認しましたが、やはり日本語をAIに解釈させるうえで、
前段階で処理の手間がかかっている ということが伺えます。
日本人同士でも何言っているかわからないときがあるので仕方ないですね。
句読点の場所で意味が全く変わる文章もありますし。
品のない文章しか思い浮かばないので、言及しません。
試すためには
上記のページのコチラ↓

こちらでText Generateを試すことができます。
Power Automate推しなので、とりあえずサクっとPower Automateでもやりましょう
API Keyの取得
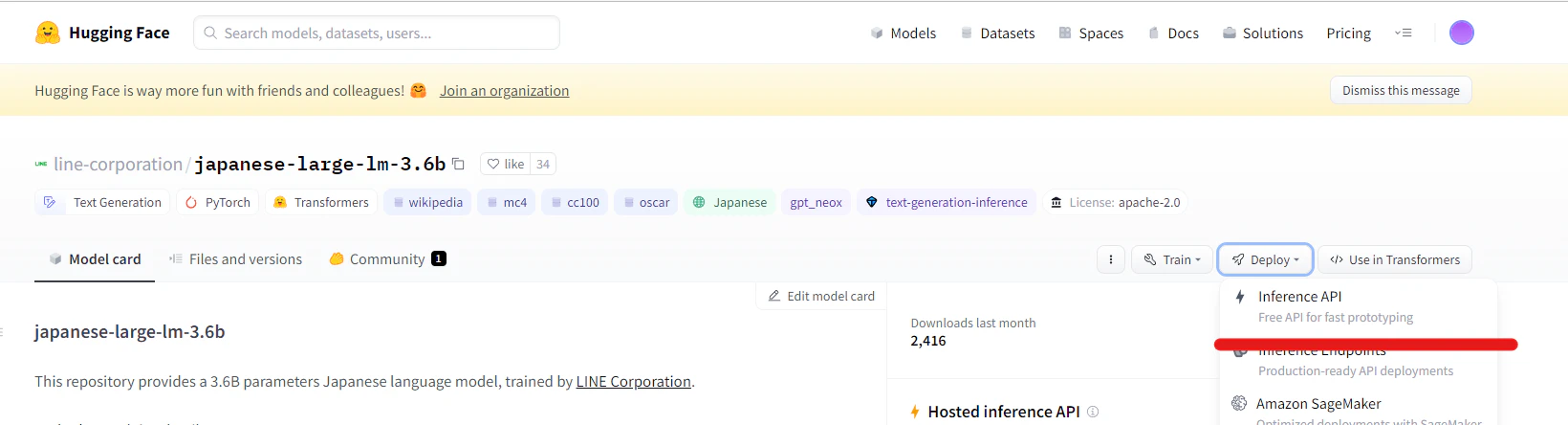
[ Deploy ] > [ Inference API ]こちらをクリックし、

赤線で伏せているボタンから、トークンを発行します。
絶対に漏らしてはいけないやつです。
そして上の画像のURL
[ https://api-inference.huggingface.co/models/line-corporation/japanese-large-lm-3.6b ]
こちらもPower Automateで使う部分ですね。
今回紹介している内容は無料のプロトタイプの方法という点にご注意ください。
Power Automateで実装する。
作成 は、戻り値を見るためだけのアクションです。

「変数を初期化する」のアクションは、API Keyを格納している文字列変数の格納です。
肝となるHTTPの部分をサクっと紹介します。

| 項目 | 値 |
|---|---|
| 方法 | POST |
| URI | https://api-inference.huggingface.co/models/line-corporation/japanese-large-lm-3.6b |
ヘッダーは下記の通りです。
| Key | Value |
|---|---|
| Authorization | Bearer {API key} |
本文
{
"inputs": "@{triggerBody()['text']}"
}
inputsのvalueが、Text Generateで使うプロンプトに該当します。
戻り値は
[
{
"generated_text": "{作成された文字列}"
}
]
となるので、面倒な方は
body('HTTP')[0]?['generated_text']
上記で文字列だけ取得できます。
パラメーターや詳細な設定は、要研究ですね🧐
さっそく実行!
入力した文字列は日本の大きい山は
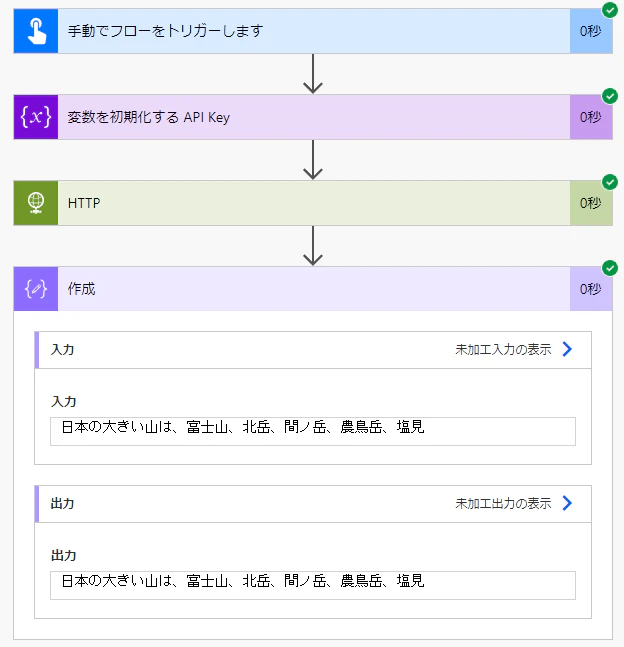
衝撃的な速さですね。
361ミリ秒
質問に対して、値を返すという部分の検証が未達ですが、事前トークン化の過程で
日本語が如何に大変か如実に表しているな...と勝手に解釈しました。
このような研究を進めてくださっている研究チームに感謝です✨