※ソース記事はこちら
自分のアカウントの下で要求を実行し、自分のパスワードと提供されたトークンを使う、開発者GitHub APIを使っていく。
GitHubへのHTTPリクエストを行うため、Retrofitを使っていく。それにより、与えられたオーガニゼーションの配下のリポジトリの一覧と、それぞれのリポジトリのコントリビューターの一覧を要求することができる。
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}
src/tasks/Request1Blocking.ktで定義されている、loadContributorsBlockingは、与えられたオーガニゼーションのためのコントリビューターをフェッチするためにこのAPIを使っている。実装をみてみよう。
fun loadContributorsBlocking(service: GitHubService, req: RequestData) : List<User> {
val repos = service
.getOrgReposCall(req.org) // #1
.execute() // #2
.also { logRepos(req, it) } // #3
.body() ?: listOf() // #4
return repos.flatMap { repo ->
service
.getRepoContributorsCall(req.org, repo.name) // #1
.execute() // #2
.also { logUsers(repo, it) } // #3
.bodyList() // #4
}.aggregate()
}
まず、与えられたオーガニゼーション配下のリポジトリの一覧を取得し、reposリストに格納する。その後、それぞれのリポジトリに対してコントリビューターの一覧を要求し、そのすべてのリストを一つの最終的なコントリビューターのリストにマージする。
それぞれのgetOrgReposCallとgetRepoContributorsCallはCallクラスのインスタンスを返却する(#!)。この時点で、要求は送られていない。要求を実行するためにCall.executeを呼び出す(#2)。executeは配下のスレッドをブロックする同期呼び出しである。
応答が得られたら、特定のlogRepos()とlogUsers()関数を呼び出すことで、結果をログ出力する(#3)。もしHTTP応答がエラーを含んでいる場合、エラーはここでログ出力される。
最後に望ましいデータを含む応答本体を取得する必要がある。このチュートリアルでは簡単にするために、エラーがある場合は、結果として空のリストを使う(#4)。.body() ?: listOf()を何度も繰り返すのを避けるため、bodyList拡張関数を宣言する。
fun <T> Response<List<T>>.bodyList(): List<T> {
return body() ?: listOf()
}
logReposとlogUsersは受け取った情報を直ちにログする。コードが実行している間、システム出力を見ると、このようなものが見られるだろう。
1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos
2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors
2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors
...
各行の最初の項目は、プログラムが開始してから経過したミリ秒で、その後、大括弧の中にスレッド名が続く。ロード要求が呼び出されているスレッドを見ることができる。各行の最後の項目は、実際のメッセージである。つまり、ロードされたリポジトリとコントリビューターの数である。
このログは、すべての結果はメインスレッドからログされていることを示している。ブロッキング要求の下でコードを実行するとき、ウィンドウはフリーズし、ロードが完了するまで入力に反応できないことに気づくだろう。すべての要求はloadContributorsBlocking から呼び出された同一のスレッドから実行されており、これはメインUIスレッドである。(SwingではAWTイベントディスパッチスレッドである)。このためメインスレッドがブロックされ、UIがフリーズする説明である。

コントリビューターの一覧がロードされた後、結果が更新される。もし、loadContributorsBlockingがどのように呼び出されているかを見ると、updateResultsはloadContributorsBlockingの直後に進んでいる。
val users = loadContributorsBlocking(service, req)
updateResults(users, startTime)
このコードは、src/contributors/Contributors.ktにある。loadContributors関数は、コントリビューターをロードする方法を決める責務を負っている。updateResultsは、UIを更新する関数である。結果として、それは常にUIスレッドから呼び出さなければならない。
課題の分野(この後で必要になる)に習熟してもらうため、次の簡単な課題を経験していただきたい。現在は、コードを実行する場合、コントリビューターが一度参加したすべてのプロジェクトに対して、それぞれのコントリビューターの名前が何度か繰り返し表示される。この課題では、いったん追加されている各コントリビューターを連結するaggregate関数を実装する。User.contributionsプロパティはプロジェクトのすべてに対して、ユーザーに与えられた全体の貢献数が含まれている。結果の一覧は、貢献の件数に関して降順にソートされなければならない。
課題
src/tasks/Aggregation.ktを開き、List<User>.aggregate()関数を実装すること。対応するテストファイルは、test/tasks/AggregationKtTest.ktで、期待する結果の例が記載されている。intelliJ IDEAのショートカットを使って、ソースコードとテストクラスを自動的にジャンプすることができる。
この課題の実装後、kotlinオーガニゼーションの結果一覧は次のようになる。
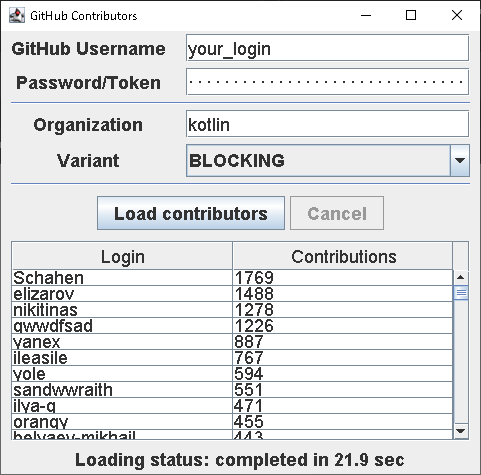
留意すべきは、ユーザーはその貢献数でどのようにソートされているかである。
解答
考えられる解答。
fun List<User>.aggregate(): List<User> =
groupBy { it.login }
.map { (login, group) -> User(login, group.sumBy { it.contributions }) }
.sortedByDescending { it.contributions }
最初に、ユーザーをログインでグルーピングする。groupByはログインに対して、異なるリポジトリ内に出現するすべてのユーザーのmapを返却する。その後、それぞれのmapエントリのために、ユーザーごとの全貢献数をカウントし、与えられた名前と貢献数の合計で、Userクラスの新しいインスタンスを作る。最後に、結果の一覧を降順にソートする。
もう一つの解答はgroupByの代わりにgroupingByを使うことである。
※参考
fun List<User>.aggregate(): List<User> =
groupingBy { it.login }
.reduce { login, acc, elem ->
User(login, acc.contributions + elem.contributions)
}.values.sortedByDescending { it.contributions }