ソース記事はこちら
Kotlinのコルーチンはスレッドと比較して非常に安価である。新しく計算を非同期で始めたいときは常に、新しいコルーチンを作ることができる。
新しいコルーチンを開始するためには、主な「コルーチンビルダー」、つまりlaunchかasyncかrunBlockingのいずれか一つを使う。
asyncは新しいコルーチンを開始し、Deferredオブジェクトを返却する。DeferredはFutureやPromiseのような他の名前で知られる概念を表す。つまり、計算を格納するが、最終的な結果を得る時は遅延する。それはいつか 将来に結果を約束する。
asyncとlaunchの主な違いは、launchが特定の結果を戻すことを期待していない計算を開始するために使うということである。launchはJobを返却し、それはコルーチンを表す。Job.join()を呼び出すことによって、完了するまで待つことが可能である。
DeferredはJobを拡張するジェネリック型である。async呼び出しはDeferred<Int>やDeferred<CustomType>を返却し、それはラムダが返却するもの(ラムダの内側の最後の式が結果である)に依存する。
コルーチンの結果を得るためには、Deferredインスタンスのawait()を呼び出す。結果を待つ間、awaitの呼び出し元のコルーチンは一時中断する。、
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
// ※以下の順で表示される
// waiting...
// loading...
// loaded!
// 42
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}
runBlockingは、通常とsuspend関数の間、つまりブロッキングと非ブロッキングの世界の間の架け橋として使われる。
それはトップレベルのメインコルーチンを開始するためのアダプタとして動作し、主にmain関数とテスト内で使われることを目的としている。
この例がどのように動くかをより理解するためには、次のビデオを見ること。
もし、deferredオブジェクトのリストがある場合、それらすべての結果を待つにはawaitAllを呼び出すことができる。
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
// ※以下の順で表示される
// Loading 1
// Loading 2
// Loading 3
// 6
}
それぞれの「コントリビューター」要求が新しいコルーチンで開始されると、すべての要求は非同期で開始する。新しい要求は、直前の要求の結果が受け取られる前に送信することができる。
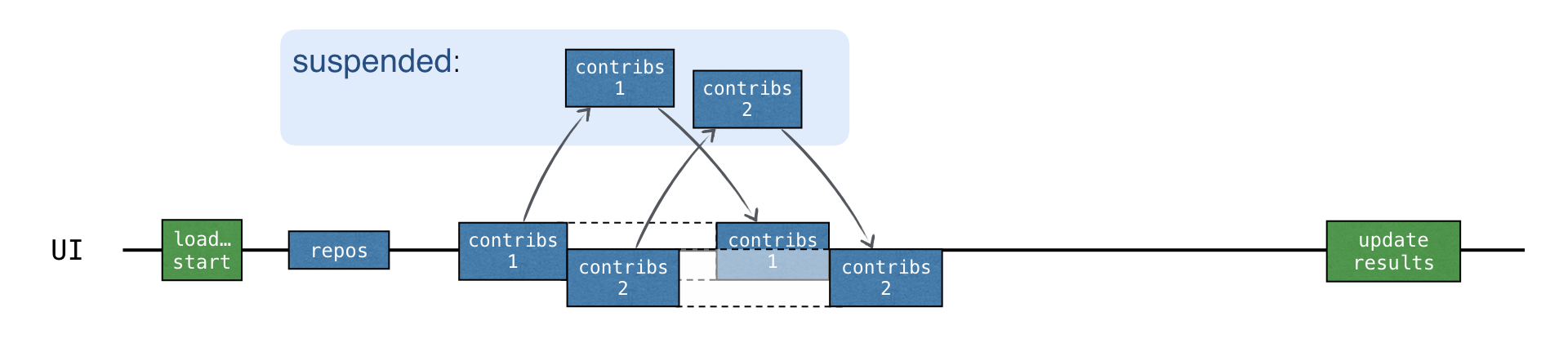
これにより、以前のCALLBACKバージョンとほぼ同じ全体のロード時間がもたらされる。ただし、一つもコールバックは不要である。されに、asyncにより、並列で実行される部分がコードの中で明確に強調される。
課題
Request5Concurrent.ktファイルにある、loadContributorsConcurrent関数を実装すること。前回のloadContributorsSuspend関数を使うこと。
Tips
下で説明する予定だが、コルーチンスコープの内側でのみ、新しいコルーチンを解することができる。そのため、loadContributorsSuspendから、中身をcoroutineScope呼び出しにコピーする。そうすればそこで、async関数を呼び出すことができる。
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// ...
}
解法は次の仕組みに基づくこと。
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// それぞれのrepoに対するコントリビューターのロード
}
}
deferreds.awaitAll() // List<List<User>>
解法
それぞれの「コントリビューター」要求をasyncでラップする。これにより、持っているリポジトリの数だけ、多くのコルーチンが生成されるだろう。しかし、新しいコルーチンを作るのは本当に安価なので、問題ではない。必要なだけ作ることができる。
asyncはDeferred<List<User>>を返却する。もはやflatMapを使うことはできない。というのは、mapの結果は、今ではDeferredオブジェクトのリストであり、リストのリストではないからである。そのため、結果を得るには、単純にflatten().aggregate()を呼ぶ必要がある。
suspend fun loadContributorsConcurrent(service: GitHubService, req: RequestData): List<User> = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
}
deferreds.awaitAll().flatten().aggregate()
}
コードを実行し、ログを確認する。すべてのコルーチンはまだ、メインUIスレッドで動作しているのがわかる。
まだどうにも、マルチスレッドを使っていないが、すでにコルーチンを並列で実行するメリットを得ている!
このコードをいつものスレッドプールとは異なるスレッドで、「コントリビューター」のコルーチンを動かすことは非常に簡単である。async関数のcontext引数として、Dispatchers.Defaultを指定することである。
async(Dispatchers.Default) { ... }
CoroutineDispatcherは対応するコルーチンが、どのスレッドあるはスレッド群で実行すべきかを決める。もし引数として指定しない場合、asyncは外側のスコープからディスパッチャーを使うだろう。
Dispatchers.Defaultは、JVM上の共有スレッドプールを表す。このプールは、並列実行の手段を提供する。それは利用可能なCPUコア数と同じ数のスレッドから構成されるが、1コアしかない場合は、それでも2スレッドを持っている。
loadContributorsConcurrent関数内のコードを変更し、新しいコルーチンがいつものスレッドプールとは異なるスレッドで開始するようにすること。さらに要求を送る前にログ出力を追加する。
async(Dispatchers.Default) {
log("starting loading for ${repo.name}")
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
この変更を取り入れた後、ログにそれぞれのコルーチンが、あるスレッドで開始し、他のスレッドで復旧するのが観察できる。
1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka
1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt
...
2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors
2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors
例えば、このログの抜粋内で、coruotine#4は、worker-2スレッドで開始し、worker-1上で継続している。
コルーチンをメインUIスレッドで実行するには、引数としてDispatcher.Mainを指定するべきでる。
launch(Dispatchers.Main) {
updateResults()
}
もし新しいコルーチンを開始するときにメインスレッドが忙しい場合、コルーチンは中断状態になり、そのスレッドで実行するためにスケジュールされる。コルーチンはスレッドが自由になるときのみ再開する。
留意すべきは、ディスパッチャーをそれぞれの末端で明示的に指定するよりも、外側のスコープから使うことが良いプラクティスとみなされている。このケースでは、loadContributorsConcurrentを引数としてDispatchers.Defaultを渡さずに定義すると、この関数をどのようにでも呼び出すことができる。つまり。Defaultディスパッチャーを持つコンテキスト、あるいはメインUIスレッドのディスパッチャーを持つコンテキスト、あるいはカスタムディスパッチャーとを持つコンテキストといったように。あとで見ていくが、テストコードかからloadContributorsConcurrentを呼び出すとき、テストを簡単にする、TestCoroutineDispatcherを持つコンテキストで呼び出すことができる。したがってこの解法は、よりフレキシブルになる。
こちらが、呼び出し側でディスパッチャーを指定する方法である。
launch(Dispatchers.Default) {
val users = loadContributorsConcurrent(service, req)
withContext(Dispatchers.Main) {
updateResults(users, startTime)
}
}
loadContributorsConcurrentに継承されたコンテキストでコルーチンを開始させる一方で、この変更をプロジェクトに適用すること。
コードを実行し、コルーチンがスレッドプールからのスレッドで実行されることを確認すること。
updateResultsは、メインUIスレッドで呼び出されるべきでる。そのためDispatchers.Mainのコンテキストで呼び出す。withContextは、指定したコルーチンコンテキストで、与えられたコードを呼び、完了するまで中断し、結果を返却する。これを表現する、もう一つのより冗長な方法は、新しいコルーチンを開始し、完了するまで明示的に(中断することで)待つこと、つまりlaunch(context) { ... }.join()である。
「外側のスコープからディスパッチャーを使うこと」は、具体的にどう動作するのか?これをより正しい方法でいうと、「外側のスコープのコンテキストからディスパッチャーを使うこと」である。コルーチンスコープとは何か、それはコルーチンコンテキストとどう異なるのか?(これら二つは混乱するかもしれない)なぜ、新しいasync「コントリビューター」のコルーチンをcoroutineScope呼び出しの内側で開始する必要があるのか?このことは次で説明しよう。