機械学習のモデルのよさの指標に「ROC 曲線の AUC」というのがありますが、聞いたことがないと「?」となると思います。それで定義を確認すると、「真陽性率と偽陽性率」と出てきて難しいと思います(自分は)。あとそもそもなぜこんな指標をつかうのかとか、「AUC が0.8です」って言われたときにだから何なのかわかりにくいと思います(自分は)。
なので「なぜ AUC なの」「AUC がいくらだったらどういうことなの」について考えたことを書きました。数式やコードはないです。おかしな点がありましたら編集リクエストをください。
この記事は全体的に気持ちなので、きちんとした情報は適切な記事をご参照ください。例えば次の記事などがわかりやすいです。
【統計学】ROC曲線とは何か、アニメーションで理解する。
https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f
※ 以下、わかりやすさのために「スパムメールかどうかを判定する分類器」を例にとります。
そもそもなぜこんな指標が必要なの
例えばスパムメール分類の性能を競うコンテストなら、難しく考えなくても「1万件のテストデータに対してスパムか非スパムかを正しく当てた件数」とかの指標でちゃんと優劣がつくと思います。ROC 曲線とか AUC とか言い出す意味がわかりません。
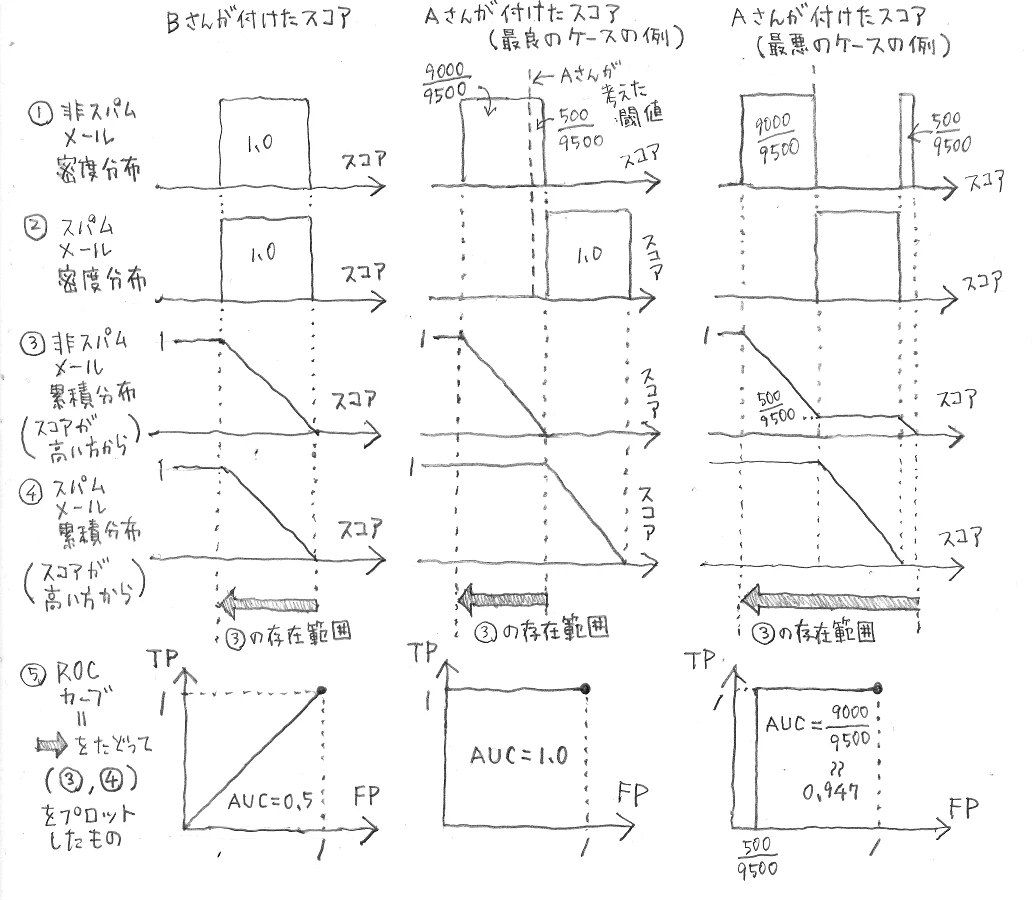
しかし、「正解数」が分類器の性能について教えてくれることは存外少ないものです。例えば1万件のテストデータに500件のスパムメールが含まれているとします(コンテスト参加者にはどのデータがスパムメールか、全部で何件のスパムメールがあるかは秘密ですが)。いま、AさんとBさんが、テストデータに対し各データがスパム(1)か非スパム(0)かを自分の分類器で判定した結果を提出しました。提出された結果を採点すると両者とも9500点でした。内訳として、Aさんは500件のスパムメールを全てスパムと正しく判定していたものの、500件の非スパムメールまでスパムと誤判定したために9500点でした。一方、Bさんは全てのデータを非スパムと判定して9500点でした。実はBさんは何も手を動かさず全部0(=非スパム)と書いて提出しただけでした。
これでAさんとBさんが同じ評価というのはちょっと引っかかる気がします。Aさんは少なくとも全てのスパムメールを特定していて頑張ったと思います。それに、Aさんは500件の非スパムメールをスパムと誤判定してしまいましたが、実はAさんの分類器の中ではこの誤判定した500件に対するスパムっぽさの中間的なスコアが真スパムメール500件に対するそれよりも小さめの値になっていて、閾値の調節次第では満点を取れていたかもしれません。正解数を指標にしてしまうと、こういうところが評価できません。
「Aさんは閾値もちゃんと調整するべきだった。やはり指標は正解数でよい」という考え方もあるかもしれませんが、実用的にはモデルのこのような閾値は後から調整することもあるかもしれませんし、「閾値で揺れ動いてしまう正解数よりは、閾値で0か1かに丸めてしまう前の、各データに付けたスパムらしさのスコアのよさを評価したい」ということもあると思います。それを評価できるのが ROC 曲線の AUC です。「このコンテストでは ROC 曲線の AUC で評価します」というときは、そういうテストデータ内のスパムらしさの大小を正しく推測することを期待されているということです。
(ここで、まだ AUC について何も説明していませんが、先にAさんとBさんの例の AUC を述べます。)では先の例のAさんとBさんを AUC で評価するとどうなるのかというと、0か1かに丸める前のスパムらしさのスコアを提出してもらわないとわかりません。ただ、何も手を動かしていないBさんの場合は、全てのテストデータに対してスパムらしさが同じと考えている=全てのテストデータが同じスコアと考えてよいでしょうから、それなら AUC は 0.5 になります。他方Aさんの AUC はスコアの付けられ方によりますが、0.947~1 になります。Aさんの AUC は最悪でもかなりよい値です。0か1に丸める前のスコアが提出されていないとしても、そのスコア順に並べて下位9000件が非スパムメールであることが確定しているからです。「スコアが低い方のデータ 90% をとればちゃんと全部非スパムメール」というのはもうこの時点でかなりよいスコアの付け方だと思います。上位1000件については、この中に500件のスパムメールと500件の非スパムメールがどのように並んでいるかわかりません。もしスコア上位500件がずばりスパムメールなら、AUC=1 が達成されます。あるスコアで仕切りを入れると完全にスパムメールと非スパムメールが分離できる状態で、とてもよいスコアの付け方です。もしその逆で、上位500件の方が非スパムメールになってしまっているとこれはよくないですが、それだとしても AUC=0.947 は達成されます。下位9000件をきちんと当てていますので。
※ AさんとBさんの例の図(「③の存在範囲」のところは「③の存在範囲」に限らなくてもいいですが限ってもいいです)
じゃあどういう指標にすればいいの
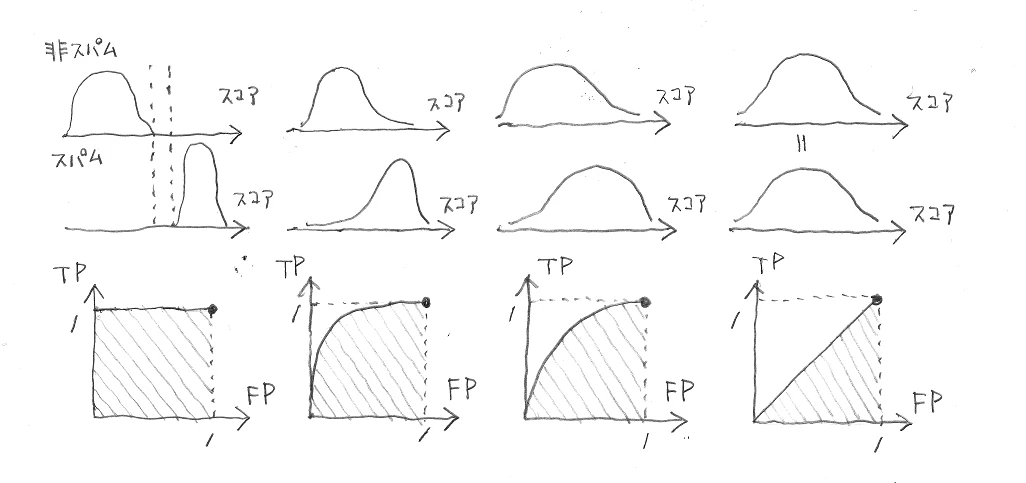
ここで、AUC が登場する前に戻ります。いま「閾値で揺れ動いてしまう正解数よりは、閾値で0か1かに丸めてしまう前の、各データに付けたスパムらしさのスコアのよさを評価したい」と考えています。といっても、どう評価すべきかは明確ではないです。例えば、あるスコアの値で閾値を入れるとスパムメールと非スパムメールを完全に分離できるようなスコアの付け方をしていたら、そのスコアの付け方は「完璧」と評価してもいいと思います(下図の一番左)。あるいは、そのスコアの付け方が対象データがスパムであろうと非スパムであろうと全く無差別なものであったら、「全然駄目(分類器としての価値なし)」と評価できそうです(下図の一番右)。しかし、実際のケースは往々にしてそれらのように極端ではなく、「スパムメールと非スパムメールを完全に分離はしていないが無差別でもない」というようになっています(下図の真ん中2つ)。この中間の状態をどう評価すればよいのでしょうか。左から3番目よりは左から2番目の方がよさそうですが。
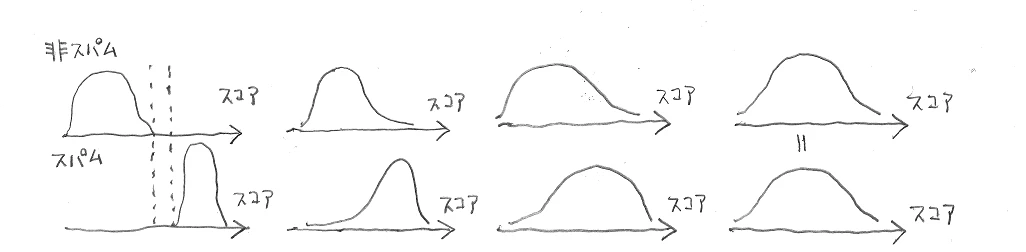
上図だけみると「分布の重なりの面積」などが指標として思い浮かびそうですが、それだと広い分布の中に狭い分布がすっぽり入っているときの、狭い分布の相対位置などが考慮されなさそうです。いきなり「分布と分布」で考えるのは難しいので、「点と分布」にして考えます。いま、テストデータ中に非スパムデータが1件しかないとします。例えば、下図の点線のところのスコアにある1件だけだったとします。この状況なら、スコア付けがよいものかどうかは幾分考えやすい気がします。つまり、下の斜線の面積が1に近いほどよいです。全てのスパムデータのスコアが非スパムデータのスコアを上回っていますから、よいスコアの付け方です。逆に、斜線の面積が0.5なら「スパムメールのスコアが非スパムメールのスコアを上回る確率が0.5で、実質スコアの付け方がスパムメールと非スパムメールを差別しておらず、全然よい付け方じゃない」となります。(斜線の面積が0.5を下回ることもあり得るかもしれませんが、スパムメールの期待スコアの方がかえって低いというバグとしか思えないスコアの付け方です。その場合でも ROC 曲線は描けますが。)
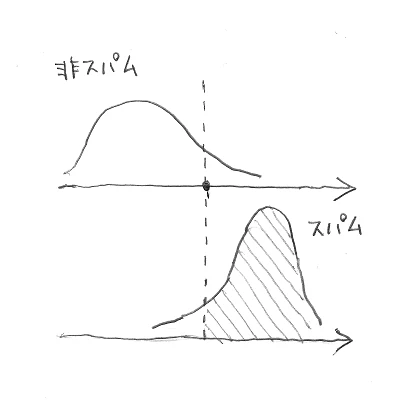
非スパムメールが1件だけだったら、上図の斜線の面積でスコア付けのよさが評価できそうです。では非スパムメールを2件に増やしたら、上図の斜線の面積が2つ得られますが、単純に平均してしまってもよいと思います。非スパムメールが何件あっても、上図の斜線の面積の平均がスコア付けのよさの指標になりそうです。実は ROC 曲線を描いて AUC (ROC 曲線の下の面積)を求めることがこの斜線の面積の平均を求めることに他なりません。「AUC=0.8 です」と言われたら、上の斜線の面積が平均的に 0.8 ということです。
この定義を踏まえると、「ROC 曲線の AUC の値とは何か」には、例えば以下のように答えられます(全て意味は同じ)。
- 「ある非スパムメールのスコアよりスコアが大きいスパムメールがスパムメール全体の何割か」の、非スパムメール全体に関する期待値。
- 「ある非スパムメールとあるスパムメールをそれぞれランダムに選んだとき、スパムメールの方がスコアが大きい確率」の、非スパムメール全体に関する期待値。
- 「ある非スパムメールのスコアに判定の閾値をおいたとき、スパムメールの内どれだけの割合をきちんとスパムと判定するか」の、非スパムメール全体に関する期待値。
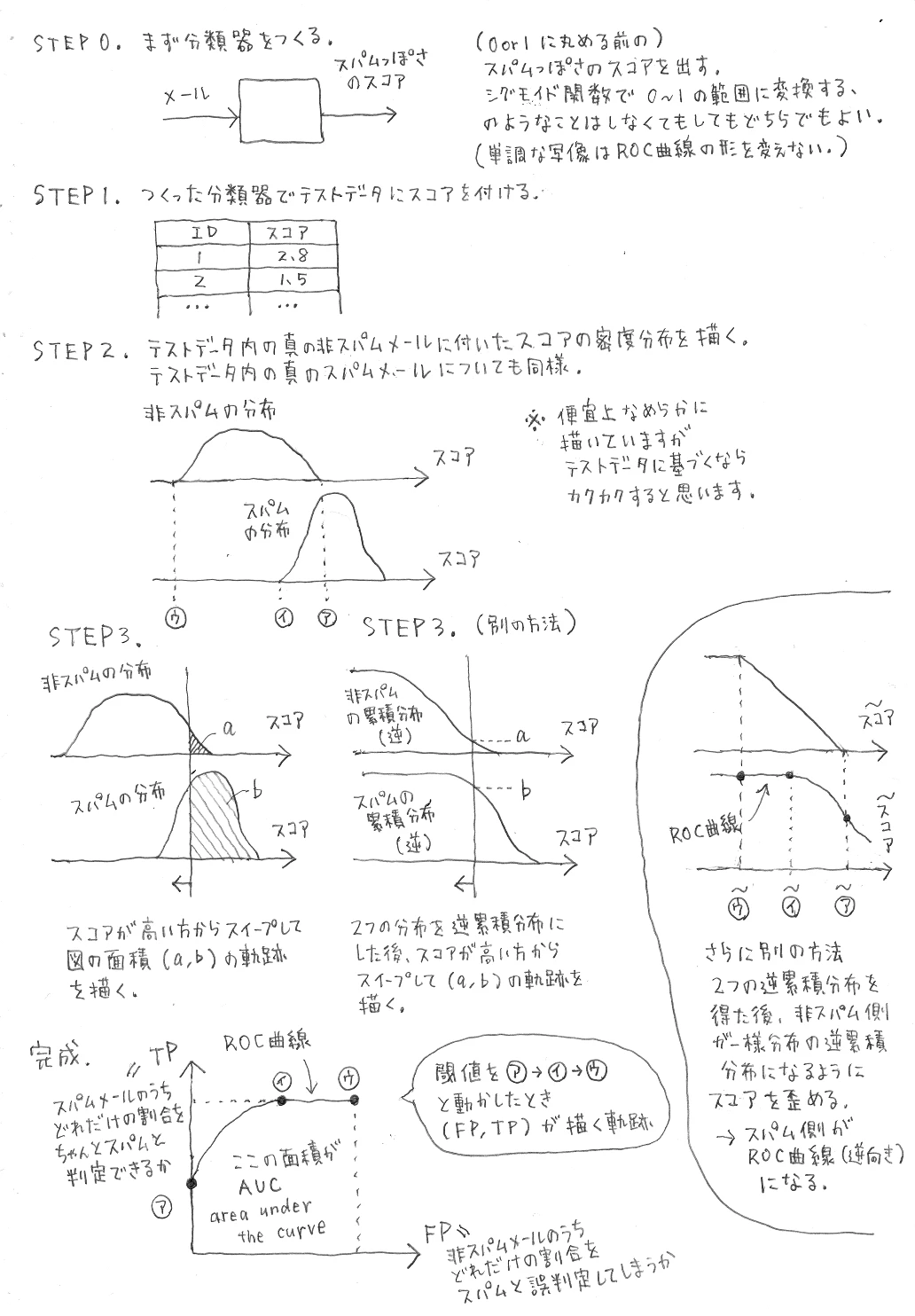
ROC 曲線の AUC の値ってどうやって計算するの(イメージ)
実際に ROC 曲線の AUC の値とはどうやってできるものなのかのイメージです。機械学習の文脈で書いています。先ほどまでの説明とリンクできていません。イメージなので正確に知りたい方はきちんとした文献を参照ください。