統計的因果探索の LiNGAM 法で、「外生ノイズがガウス分布だと因果構造を特定できないです」「ガウス分布でなければ何でもいいです」といわれると思うんですが、「何がしたくて、何をしようとして、どこで『ガウス分布だめだこれ』となるのか」が自分にわかりやすいように少し整理しました。「文章と絵による説明」と「数式をまじえた説明」を書いたので、イメージ先行が嫌な人は後者を先にみてください。
参考文献
以下の書籍の111~115ページを参考にしていますが私の誤りは私に帰属します。お気付きの点があればご指摘いただけますと幸いです。
統計的因果探索 (機械学習プロフェッショナルシリーズ)
文章と絵による説明
※ 以下の説明では、因果効果は線形で、一方の変数から他方の変数へ一方通行であることを仮定します。また、外生ノイズの分散は正とし、外生ノイズどうしは独立とします。
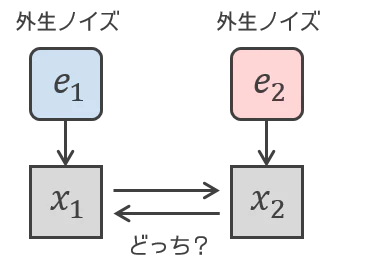
あなたは2つの変数の因果的順序を特定したいとします。こちらであちらを説明できるか、あちらでこちらを説明できるか調べようとするのは自然なことでしょう。ところで図をよくみると、説明できてしまってはいけないこともあります。もしこちらが原因であったら、あちらの外生ノイズを知らないはずなので、あちらの外生ノイズを説明できてはいけません(あちらの外生ノイズからこちらに矢印は伸びていないですから)。
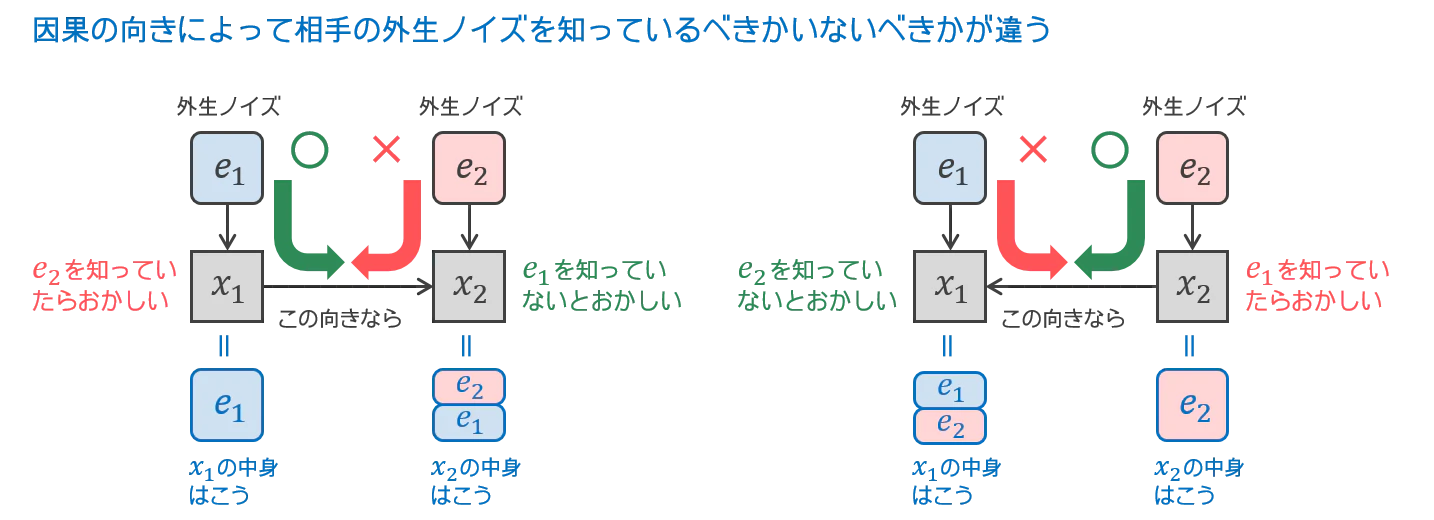
もし説明変数から被説明変数への向きが正しい因果の向きと逆だと(「結果」で「原因」を説明しようとすると)、正しい因果の向きならば起きないこと―説明変数が知らないはずの被説明変数の外生ノイズを知っていたり、被説明変数が知っているはずの説明変数の外生ノイズを知らなかったりすること―が起きます。線形回帰(=線形に説明できる部分は説明する活動)をすると、残差にこのほころびが出てきます。つまり、説明変数と残差がどちらも共通に説明変数の外生ノイズと被説明変数の外生ノイズを含むことになります(正しい因果の向きの線形回帰なら、説明変数が前者のノイズのみを、残差が後者のノイズのみを含みます)。このほころびをとらえたいです。
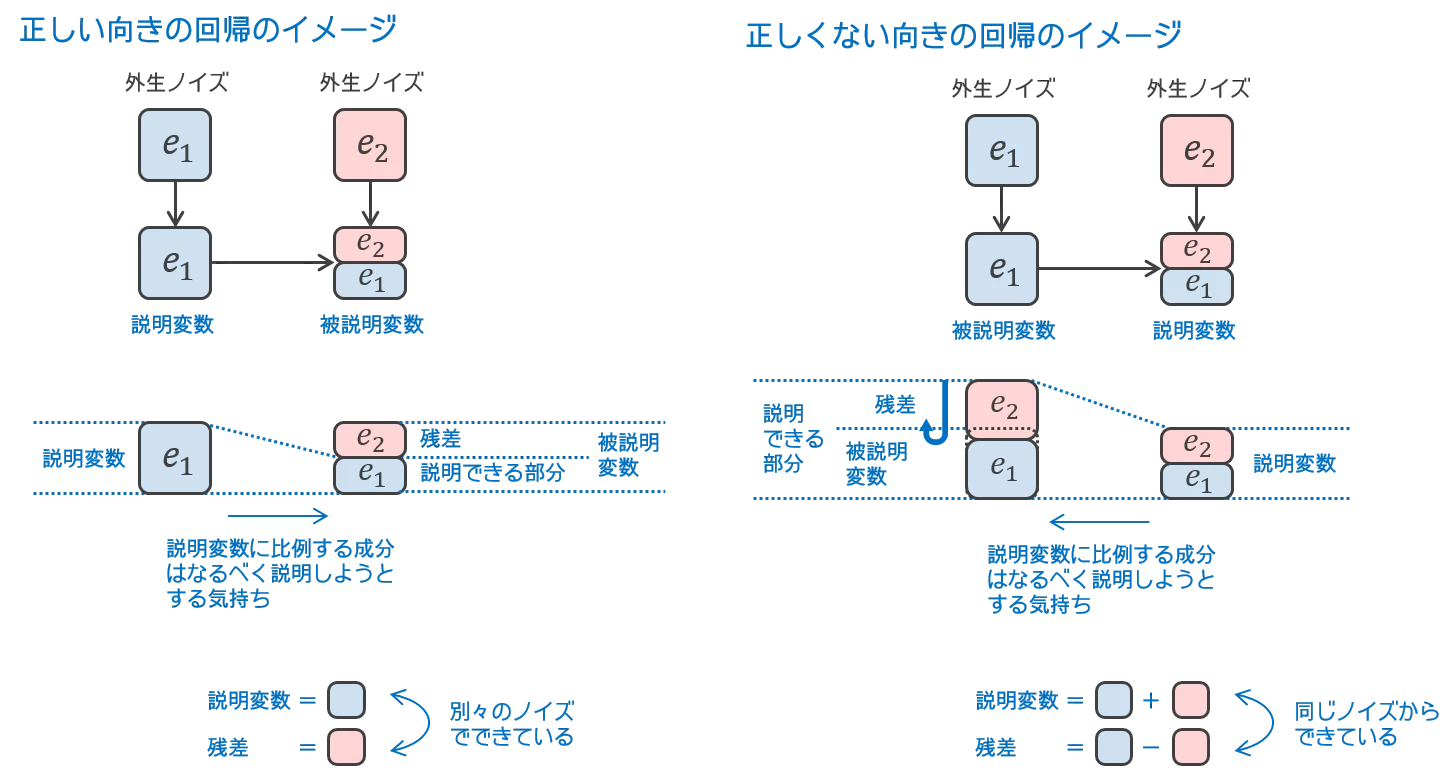
ところで、説明変数と残差が共通のノイズを含んでいようといまいと、「残差が説明変数と無相関になるまでしぼりとる」のが線形回帰です。ここで、もし2つの外生ノイズが「無相関になるまでしぼりとったら独立になってしまう」ような分布だったら、説明変数と残差が同じノイズを含んでいることのしっぽをつかめず(だって独立ですから)、ほころびをとらえられません。悲しいことにそんな分布がガウス分布です。なのでノイズがガウス分布だと因果的順序を特定できないのです。逆にガウス分布でなければ無相関にしても独立にはならないのでほころびをとらえられます(※)。
※ 後述するダルモア・スキットビッチの定理により保証されます。本当にガウス分布でなければ何でもいいのかというと、[私が見つけたダルモア・スキットビッチの定理の証明(PDF)](http://ee.sharif.edu/~bss/DarmoisTheorem.pdf)では「第2キュムラント母関数が何回でも微分可能なら」という条件が付いているようにみえます。なのでコーシー分布などについては何もいえていないようにみえます。私の誤りかより一般的な証明があるかもしれません。ご存知の方はご教示いただけますと幸いです。
[余談]ガウス分布とそれ以外の分布、どこで差がついたのか
ガウス分布の敗因(?)(の一つの説明の仕方)は、第2キュムラント母関数(特性関数の対数)に3次以上の項をもたなかったことです。線形回帰(「無相関になるまでしぼりとる」)は説明変数と残差の第2キュムラント母関数の2次のクロスターム(共分散に他なりません)をゼロにすることに相当します(※)。3次以上の項がないと2次のクロスタームをゼロにしただけで独立になってしまいます。他方、ガウス分布でない分布にしたがう確率変数は第2キュムラント母関数が多項式にならず(※※)、高次の項がずっと続いていきます(解析的ならば)。ので一般に2次のクロスタームをゼロにしただけで独立にはできないのです。
そもそもガウス分布は「独立に同一の分布にしたがうたくさんの確率変数の和」の分布収束先の分布でした(中心極限定理)。この極限では元の確率変数の2次までのキュムラントのみが生き残り3次以上のキュムラントが生き残らずゼロになります(※※※)。私たちは普段「とてもたくさんのノイズの和だと考えてガウス分布を仮定します」などといってこの余分な情報のそぎ落とされたガウス分布を安易に選ぶものですが、こと因果探索するときには余分な情報が生き残っていないことがあだになります。「こちらであちらを説明しようとして残差にほころびが出ないかみてやろう」としても、ガウス分布は線形回帰がしぼりとるよりも複雑な情報をもっていなくて、ほころびが出ないのです。
※ なお、この説明ではノイズの第2キュムラント母関数がそもそも解析的である(テイラー展開できる)ことを仮定しています(テイラー展開できないと2次の項とかがないので)。 ※※ [さっきのPDF](http://ee.sharif.edu/~bss/DarmoisTheorem.pdf)の定理2です。原論文は[これ](https://gdz.sub.uni-goettingen.de/id/PPN266833020_0044?tify=%7B%22pages%22:[616],%22panX%22:0.521,%22panY%22:0.456,%22view%22:%22info%22,%22zoom%22:0.661%7D)ですが私はフランス語が読めませんでした。他の文献をご存知の方はご教示いただけますと幸いです。 ※※※ [ウィキペディアの中心極限定理の証明](https://ja.wikipedia.org/wiki/%E4%B8%AD%E5%BF%83%E6%A5%B5%E9%99%90%E5%AE%9A%E7%90%86#%E8%A8%BC%E6%98%8E)を眺めてください。
数式をまじえた説明
まずガウス分布でなければ因果的順序を特定できる仕組みを説明してから、ガウス分布だと特定できない仕組み(仕組み?)を説明します。
ガウス分布でなければ因果的順序が特定できる仕組み
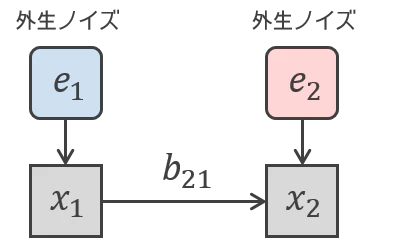
以下の線形構造方程式で、${\rm var}(e_1) > 0, , {\rm var}(e_2) > 0$ として、かつ $b_{21} \neq 0$ を仮定します。つまり、$x_1$ が $x_2$ の原因になっている状況です。
\begin{cases}
x_1 &= e_1 \\
x_2 &= b_{21} x_1 + e_2
\end{cases}
絵で描くとこうです。
-
正しい因果の向きに、$x_2$ を $x_1$ で(最小2乗法で)回帰したときには残差に $e_1$ の項は残りません。$x_2$ の $x_1$ で説明できる成分はすべて説明し切るような回帰係数 $\widehat{b_{21}}$ を求めるのが最小2乗法なのですから、$x_1 = e_1$ で説明できる成分は残差に残りません。
- 一般に $y$ を $x$ で線形回帰したときの回帰係数はサンプル上の分散・共分散で ${\rm cov}(x,y)/{\rm var}(x)$ とかけます(2乗誤差を回帰係数で偏微分してゼロとおいて解いてください)。ここでは残差の理論的な性質を議論するため、真の分散・共分散によって $\widehat{b_{21}}={\rm cov}(x_2,x_1)/{\rm var}(x_1)$ とします。
- いま ${\rm cov}(x_2,x_1) = b_{21} {\rm var}(x_1)$ なので結局 $\widehat{b_{21}} = b_{21}$ です。そうなると、$x_2$ の $x_1$ で説明できない残差 $r_2^{(1)}$ は $r_2^{(1)} = x_2 - \widehat{b_{21}} x_1 = e_2$ です。$e_1$ の項は残りません。
- いま説明変数が $x_1 = e_1$ で、残差が $r_2^{(1)} = e_2$ なので、説明変数と残差は独立です。
- 一般の線形回帰の説明変数と残差は独立ではありません。「上の線形構造方程式で、サンプルサイズがとても大きい状況で、因果が正しい向きに回帰したとき」に独立になるということです。
- 一般に(サンプルサイズがとても大きい)線形回帰の説明変数の残差は無相関にはなります(積の期待値が期待値の積に等しくなることを確認してください)。
-
他方、正しい因果の向きとは逆に、$x_1$ を $x_2$ で回帰すると残差に $e_2$ の項が残ります。というのも、$x_1$ を $x_2$ の式で表すと $e_2$ が直接出てきてしまうからです。本当は $x_1$ は $x_2$ より因果的に先に生まれていて $e_2$ を知らないので、$x_1$ を $x_2$ の式で表すなら $x_1$ が知らないはずの $e_2$ を明示的に差し引く必要があります。
- 具体的にこのときの回帰係数は $\widehat{b_{12}} = {\rm cov}(x_1,x_2)/{\rm var}(x_2) = b_{21} {\rm var}(x_1)/{\rm var}(x_2)$ です。仮定よりこれはゼロではないです。残差は $r_1^{(2)} = x_1 - \widehat{b_{12}} x_2 = x_1 - \widehat{b_{12}} (b_{21} x_1 + e_2)$ です。$e_2$ の係数 $\widehat{b_{12}}$ はゼロではないです。
- なお、$x_1 = e_1$ の係数は $1 - b_{21} \widehat{b_{12}}$ ですが、相関係数の性質および ${\rm var}(e_2) > 0$ より ${\rm cov}(x_1,x_2)^2/\bigl({\rm var}(x_1){\rm var}(x_2)\bigr) < 1$ なので、$b_{21} \widehat{b_{12}} < 1$ であり、$1 - b_{21} \widehat{b_{12}} > 0$ です。$e_1$ の係数もゼロではないです。
- じゃあ残差に $e_2$ の項が残ったら何なのかというと、もし $e_2$ のしたがう分布がガウス分布でないならば、ダルモア・スキットビッチの定理(参考文献114ページ)より説明変数 $x_2$ と残差 $r_1^{(2)}$ が独立になりません。
- ダルモア・スキットビッチの定理をここで必要な形にかなり加工してかくと、「独立な確率変数 $X_1, X_2$ を用いて以下のように確率変数 $Y_1, Y_2$ を定義したとき( $a_1, a_2, b_1, b_2$ はいずれもゼロでないとする)、$Y_1, Y_2$ が独立ならば、$X_1, X_2$ はいずれもガウス分布にしたがう」というものです。$X_1, X_2$ を $e_1, e_2$ に、$Y_1$ を $x_2$ に、$Y_2$ を $r_1^{(2)}$ に見立てて、この定理の対偶をいえば、「 $e_1, e_2$ の少なくとも一方のしたがう分布がガウス分布でないならば、$x_2, r_1^{(2)}$ は独立ではない」です。
- 具体的にこのときの回帰係数は $\widehat{b_{12}} = {\rm cov}(x_1,x_2)/{\rm var}(x_2) = b_{21} {\rm var}(x_1)/{\rm var}(x_2)$ です。仮定よりこれはゼロではないです。残差は $r_1^{(2)} = x_1 - \widehat{b_{12}} x_2 = x_1 - \widehat{b_{12}} (b_{21} x_1 + e_2)$ です。$e_2$ の係数 $\widehat{b_{12}}$ はゼロではないです。
\begin{cases} Y_1 &= a_1 X_1 + a_2 X_2 \\ Y_2 &= b_1 X_1 + b_2 X_2 \end{cases}
- 以上より、一方の向きの回帰では説明変数と残差が独立になり、もう一方の向きの回帰では説明変数と残差が独立にならないので、両パターンでの説明変数と残差の相互情報量などを手掛かりに独立でありそうかを判断すれば因果的順序を特定できます。
ガウス分布だと因果的順序が特定できない仕組み(?)
ガウス分布でなければ因果的順序が特定できるのはわかりました。しかし、上の説明はガウス分布だと因果的順序を特定できないことの説明にはなっていません。ダルモア・スキットビッチの定理は「独立ならばガウス分布にしたがう」というものですが、「ガウス分布にしたがうならば独立である」というものではありません。実際、$a_1 = b_1, a_2 = b_2$ であれば $Y_1, Y_2$ は独立ではありません。$Y_1 = Y_2$ ですから。
逆に$X_1, X_2$ がガウス分布にしたがうときに上の $Y_1, Y_2$ が独立になる条件を出してみます。$X_1, X_2$ が以下のような第2キュムラント母関数(特性関数の対数)をもつとします。
\Psi_{X_1}(t) = i \mu_1 t - \frac{\sigma_1^2 t^2}{2} \\
\Psi_{X_2}(t) = i \mu_2 t - \frac{\sigma_2^2 t^2}{2}
このとき、$(Y_1, Y_2)$ の第2キュムラント母関数は以下になります。
\displaystyle \begin{split} \Psi_{Y_1, Y_2}(t_1, t_2) &= \log E \bigl[ e^{i (t_1 Y_1 + t_2 Y_2)} \bigr] \\ &= \log E \bigl[ e^{i (t_1 a_1 X_1 + t_2 b_1 X_1 + t_1 a_2 X_2 + t_2 b_2 X_2 )} \bigr] \\ &= \log E \bigl[ e^{i (t_1 a_1 X_1 + t_2 b_1 X_1)} \bigr] \cdot E \bigl[ e^{i (t_1 a_2 X_2 + t_2 b_2 X_2 )} \bigr] \\ &= \Psi_{X_1}( a_1 t_1 + b_1 t_2) + \Psi_{X_2}( a_2 t_1 + b_2 t_2) \\ &= i (a_1 \mu_1 + a_2 \mu_2) t_1 - \frac{(a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2) t_1^2}{2} + i (b_1 \mu_1 + b_2 \mu_2) t_2 - \frac{(b_1^2 \sigma_1^2 + b_2^2 \sigma_2^2) t_2^2}{2} - (a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2) t_1 t_2
\\ &= i \left( \begin{array}{cc} t_1 & t_2 \end{array} \right) \left( \begin{array}{c} a_1 \mu_1 + a_2 \mu_2 \\ b_1 \mu_1 + b_2 \mu_2 \end{array} \right)
- \frac{1}{2} \left( \begin{array}{cc} t_1 & t_2 \end{array} \right)
\left( \begin{array}{cc}
a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2 & a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 \\
a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 & b_1^2 \sigma_1^2 + b_2^2 \sigma_2^2
\end{array} \right)
\left( \begin{array}{c} t_1 \\ t_2 \end{array} \right)
\end{split}
これは2変量ガウス分布の第2キュムラント母関数です。であれば、$Y_1$ と $Y_2$ が独立であることは共分散がゼロ、つまり、$a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 = 0$ と同値です。2変量正規分布では独立 ⇔ 無相関であるからです。
じゃあここで、$Y_1 = a_1 X_1 + a_2 X_2$ を $X_1$ が $Y_1$ の原因になっている構造方程式に見立てて( $X_2$ は外生ノイズ)、誤った向きの回帰をしてみましょう。つまり、$X_1$ を $Y_1$ で回帰してみましょう。回帰係数 $\hat{b}$ は、
\hat{b} = \frac{{\rm cov}(X_1, Y_1)}{{\rm var}(Y_1)} = \frac{{\rm cov}(X_1, a_1 X_1 + a_2 X_2)}{{\rm var}(a_1 X_1 + a_2 X_2)}
= \frac{a_1 \sigma_1^2}{a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2}
なので、残差 $r$ は以下です。
r = X_1 - \hat{b} Y_1 = X_1 - \hat{b} ( a_1 X_1 + a_2 X_2 ) = (1 - a_1 \hat{b}) X_1 - a_2 \hat{b} X_2
したがって、このとき $Y_2 = b_1 X_1 + b_2 X_2 $ を残差とみなせるための条件は、
\begin{split}
b_1 &= 1 - a_1 \hat{b} = 1 - a_1 \frac{a_1 \sigma_1^2}{a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2} = \frac{a_2^2 \sigma_2^2}{a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2} \\
b_2 &= -a_2 \hat{b} = -\frac{a_1 a_2 \sigma_1^2}{a_1^2 \sigma_1^2 + a_2^2 \sigma_2^2}
\end{split}
です。これを $a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2$ に代入してみます。すると、$a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 = 0$ となります。
以上をまとめるとこうなります。
- $X_1, X_2$ を独立な確率変数とし、$X_1, X_2$ の分散(2次のキュムラント)を $\sigma_1^2,\sigma_2^2$ とし、$Y_1 = a_1 X_1 + a_2 X_2,$ $Y_2 = b_1 X_1 + b_2 X_2$ とする。
- $Y_1$ で $X_1$ を回帰したときの残差が $Y_2$ であるならば、$a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 = 0$ である(これはガウス分布でなくてもそう)。
- $X_1, X_2$ のしたがう分布がガウス分布であるとき、$a_1 b_1 \sigma_1^2 + a_2 b_2 \sigma_2^2 = 0$ であることと $Y_1, Y_2$ が独立であることは同値である。
要するに、このページの絵の因果的構造モデルで2つの外生ノイズがガウス分布ならば、誤った向きの回帰の説明変数と残差は必ず独立になります(サンプルサイズが理想的に大きければ)。これでは正しい向きの回帰と区別が付きません。外生ノイズがガウス分布ならば因果の向きは常に特定できなかったのです。
線形回帰がいつも説明変数 $Y_1$ と残差 $Y_2$ を無相関にすることをふまえれば、$(Y_1, Y_2)$ が2変量ガウス分布にしたがうことがわかった時点で $Y_1, Y_2$ が独立であることはわかります。