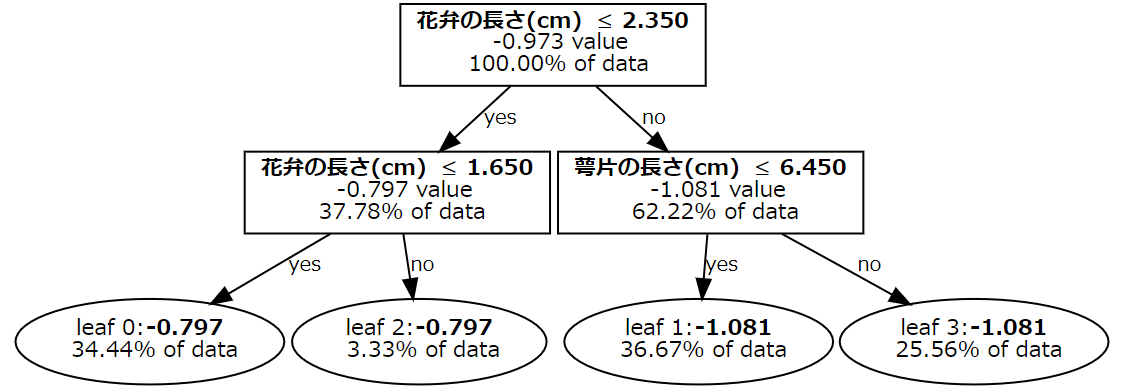
lightgbm.create_tree_digraph に以下のようにパラメータを渡すと好きなフォントに変更できます。
※ matplotlib でその日本語フォントを利用できるようにしてあることが前提です。
※ 環境設定として日本語フォントを設定しておく方法もあると思います。
import warnings
warnings.simplefilter('ignore', UserWarning)
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 6)
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = datasets.load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
# あえて特徴の名前を日本語にする
iris.feature_names = ['萼片の長さ(cm)', '萼片の幅(cm)', '花弁の長さ(cm)', '花弁の幅(cm)']
lgb_train = lgb.Dataset(X_train, y_train, feature_name=iris.feature_names)
lgb_eval = lgb.Dataset(X_test, y_test, feature_name=iris.feature_names, reference=lgb_train)
params = {'seed': 0, 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'multiclass',
'metric': {'multi_logloss'}, 'num_class': 3, 'learning_rate': 0.1,
'num_leaves': 20, 'min_data_in_leaf': 3, 'num_iteration': 10, 'verbose': -1}
model = lgb.train(params, lgb_train, valid_sets=lgb_eval,
early_stopping_rounds=20, verbose_eval=False)
model.save_model('model.txt', num_iteration=model.best_iteration)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
accuracy = accuracy_score(y_pred_max, y_test)
print(f'accuracy score: {accuracy:0.4f}')
# 以下で可視化すると日本語が表示できず豆腐がもたらされる (※ 環境設定による)
# lgb.plot_tree(
# model, tree_index=0, show_info=['internal_value', 'data_percentage'],
# orientation='vertical')
# plt.show()
# create_tree_digraph には graphviz.Digraph のコンストラクタに渡すパラメータを指定できる
graph = lgb.create_tree_digraph(
model, show_info=['internal_value', 'data_percentage'],
orientation='vertical',
node_attr={'fontname': 'M PLUS 1', 'fontsize': '11'}, # 日本語フォント
edge_attr={'fontname': 'M PLUS 1', 'fontsize': '10'}, # 日本語フォント
)
graph.format = 'png'
graph