LSTMで「どのキャラクターのセリフか」を判別しました。使用データ数は少ないです。
参考文献
- Sequence Classification with LSTM Recurrent Neural Networks in Python with Keras - Machine Learning Mastery
- 数学ガール/フェルマーの最終定理 (数学ガールシリーズ 2) | 結城 浩 |本 | 通販 | Amazon
参考にした記事
以下の機械学習ブログで、「映画レビュー(=英単語の列)がポジティブなものかネガティブなものか」を判別するモデルをKerasのLSTMで構築しています。
Sequence Classification with LSTM Recurrent Neural Networks in Python with Keras - Machine Learning Mastery
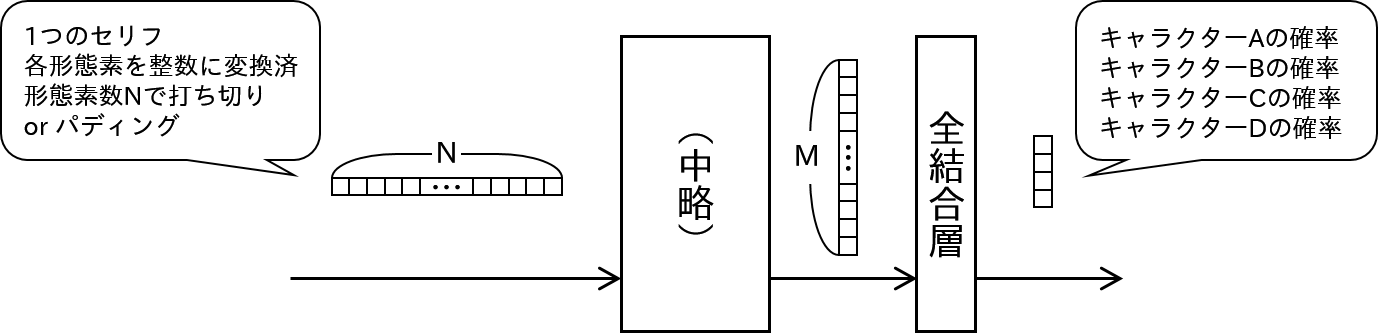
上の記事のモデルをまとめると以下の絵のようになると思います(1番最後の畳み込みありのモデル)。

今回やったこと
上のモデルの入口と出口を以下のように改造すれば、「キャラクターのセリフ(日本語)を入れるとどのキャラクターのものか判別する」モデルになりそうな気がします。
- 今回、元データとして、手元にあった本をつかうことにします(以下)。
数学ガール/フェルマーの最終定理 (数学ガールシリーズ 2) | 結城 浩 |本 | 通販 | Amazon
この本のメインキャラクターは「僕」「ミルカさん」「テトラちゃん」「ユーリ」なので、この4人のセリフを判別することにします。 - セリフは日本語なので、形態素への分解が必要です。今回は Janome パッケージを使用し、品詞と単語文字列が一致すれば同一の形態素ということにしました。
手順
以下の手順で行いました(スクリプトはこの記事の一番下)。
- キャラクターのセリフをひたすらテキストにタイプします。
- 今回は各キャラクターのセリフが100以上出てくるまでテキストに起こしました。
- カギ括弧内を1つのセリフとし、数字・記号・数式が含まれるセリフはとばしました。
- すべてのセリフを読み込んで、形態素に分解します。
- 登場したすべての形態素に、登場回数が多い順から1, 2, …と数字を振ります。
- すべてのセリフを、形態素の数字の列に変換します。同時に、列の長さをそろえます。
- 今回は、決め打ちで形態素数15にそろえました。
- 訓練用データとテスト用データを抽出します。
- 今回は、各キャラクターのセリフを100個ずつランダムサンプリングし、そのうち90個ずつを訓練用データ、10個ずつをテスト用データとしました。
- 後はモデルの訓練とテストを行います。
- 参考にした記事ではLSTM層の出力のニューロン数が100ですが、過学習になるような気がしたので20に減らしました。
- 学習時はLSTM層の入力、LSTMブロックの入力、全結合層の入力でドロップアウトしました。
- バッチサイズやエポック数は少し試行錯誤して決めました。
キャラクターのセリフは以下のようなテキストに起こしています(セリフは参考文献2からの引用です)。
先頭にキャラクターを示す記号を付けています(A:僕、B:ミルカさん、C:テトラちゃん、D:ユーリ)。
Dお兄ちゃん、きれいだねえ
Aそうだね。いくつあるのか、数え切れないね
(略)
結果
テスト用データに対して80%の精度になりました。
Epoch 28/30
360/360 [==============================] - 0s - loss: 0.1113 - acc: 0.9722
Epoch 29/30
360/360 [==============================] - 0s - loss: 0.0993 - acc: 0.9722
Epoch 30/30
360/360 [==============================] - 0s - loss: 0.0894 - acc: 0.9833
Accuracy (train): 98.89%
Accuracy (test) : 80.00%
結果の詳細や補足
今回のテスト結果は以下のようになりました(セリフは参考文献2からの引用です)。
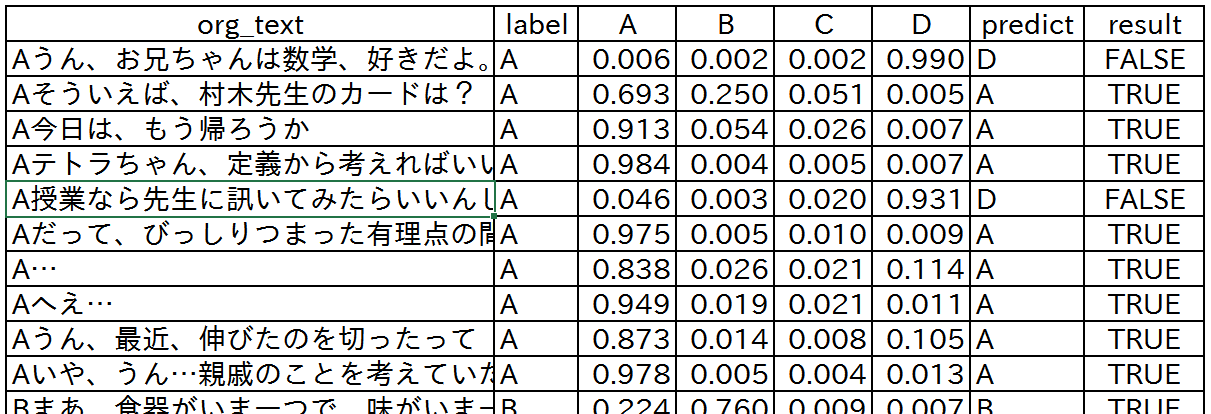
- labelは正解、A~D列はモデルが推論した確率分布、predictはモデルの推測(A~Dのmax index)です。
- 「僕」のセリフでモデルが正しく「僕」と推測している例では、確率は比較的はっきり「僕」に偏っています。
- 2行目「そういえば、村木先生のカードは?」については比較的「僕」である確率が低いですが、これは実際ミルカさんやテトラちゃんのセリフでもありえそうな気がします(そんなことが学習できているかはわかりませんが…)。
- 「僕」のセリフで判定を誤った1つ目は、「ユーリ」と誤判定されています。これはセリフに「お兄ちゃん」が含まれているからかもしれません(?)。
- 誤った2つ目も「ユーリ」と誤判定されていますが、「授業」や「先生」という言葉はユーリが発する確率が高かったのでしょうか(?)。
※ org_text の最初の記号はセリフを数字列化するときに取り除いています。
今回、訓練用データが360、テスト用データが40と少ないので、結果は多分にデータに依存していると思われます。
また、今回 Janome で形態素解析をしましたが、「屋上でテトラちゃんと食べてたんだよ…」というセリフから「ちゃんと(副詞)」が抽出されてしまうなど、分解が意図通りでない現象が確認されています。これについて意図通りに修正するなどはしていません。
スクリプト
今回実行したスクリプトは以下です。すべて1ファイルに書いてしまっていますが悪しからず。
モデル部分はほぼ参考にした記事の通りですが、ハイパーパラメータは多少異なります。
なお、私の環境のKerasはバージョンが1.2.0と古いので、関数の引数名が最新のバージョンと異なります。エラーが出たら適宜修正してください。
# -*- coding: utf-8 -*-
import codecs
import numpy
import pandas
import random
import sys
from janome.tokenizer import Tokenizer
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.embeddings import Embedding
if __name__ == "__main__":
# セリフデータを読み込みます
filename = 'data.txt'
file = codecs.open(filename, 'r', 'utf-8')
lines = file.readlines()
file.close()
# 品詞分解し全ての単語と登場回数を収集します
words = [] # 単語文字列、品詞、登場回数のリスト
t = Tokenizer()
for line in lines:
line = line.replace('\n', '')
tokens = t.tokenize(line)
for j in range(1, len(tokens)): # 1単語目は話者を示す記号なのでとばします
token = tokens[j]
is_new_word = True
for i in range(len(words)):
if words[i][0] == token.surface and words[i][1] == token.part_of_speech[:2]:
words[i][2] += 1
is_new_word = False
break
if is_new_word:
words.append([token.surface, token.part_of_speech[:2], 1])
# 単語情報をデータフレームに変換します
dic = pandas.DataFrame(words)
dic.columns = ['words', 'parts', 'freq']
dic = dic.sort_values(by=['freq'], ascending=False)
dic = dic.reset_index(drop=True)
# print(dic) # 辞書が完成
num_words = dic.shape[0] # 全単語数を確認しておきます
# 辞書ができたので全セリフデータを固定長の数字列に変換します
max_speech_length = 15
data_list = []
for line in lines:
line = line.replace('\n', '')
tokens = t.tokenize(line)
record = []
record.append(tokens[0].surface.encode('utf-8'))
# 固定長より長いセリフは打ち切り
# 固定長より短いセリフは0埋め
n = min(len(tokens), max_speech_length + 1)
for j in range(1, n):
dic_temp = dic[(dic['words'] == tokens[j].surface)
& (dic['parts'] == tokens[j].part_of_speech[:2])]
record.append(dic_temp.index[0] + 1)
if (len(record) < max_speech_length + 1):
for j in range(max_speech_length + 1 - len(record)):
record.append(0)
record.append(line) # ログ用に元文字列も付与します(数字列だとどのセリフかわからないので)
data_list.append(record)
colnames = ['label']
colnames.extend(range(0, max_speech_length))
colnames.append('org_text')
data = pandas.DataFrame(data_list, columns=colnames)
# ここからセリフ分類モデルを訓練します
random.seed(123)
numpy.random.seed(123)
# まずモデルを構築します
embedding_vecor_length = 32
model = Sequential()
model.add(Embedding(num_words, embedding_vecor_length, input_length=max_speech_length))
model.add(Conv1D(32, 3, border_mode='same', activation='relu'))
model.add(MaxPooling1D(pool_length=2))
model.add(Dropout(0.1))
model.add(LSTM(20, dropout_W=0.1, dropout_U=0.1))
model.add(Dropout(0.1))
model.add(Dense(4, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
# 訓練用データ、テスト用データを用意します
# 各キャラクターのセリフを同じ個数ずつランダムサンプリングします
x_train, y_train, x_train_org = [], [], [] # x_train_org はログ用
x_test, y_test, x_test_org = [], [], [] # x_test_org はログ用
n_eachclass_train = 90
n_eachclass_test = 10
n_eachclass = n_eachclass_train + n_eachclass_test
prob = {'A':[1,0,0,0], 'B':[0,1,0,0], 'C':[0,0,1,0], 'D':[0,0,0,1]}
for label in ['A', 'B', 'C', 'D']:
data_temp = data[data.label == label]
if (data_temp.shape[0] < n_eachclass):
print(u'データ数が足りません: ラベル' + label + u', ' + str(data_temp.shape[0]))
sys.exit()
data_temp = data_temp.loc[random.sample(data_temp.index, n_eachclass)]
org_text = data_temp.iloc[:,max_speech_length+1]
data_temp = data_temp.iloc[:,1:(max_speech_length+1)]
for i in range(n_eachclass_train):
x_train.append(data_temp.iloc[i].as_matrix())
y_train.append(prob[label])
x_train_org.append([org_text.iloc[i], label])
for i in range(n_eachclass_train, n_eachclass):
x_test.append(data_temp.iloc[i].as_matrix())
y_test.append(prob[label])
x_test_org.append([org_text.iloc[i], label])
x_train = numpy.array(x_train)
y_train = numpy.array(y_train)
x_test = numpy.array(x_test)
y_test = numpy.array(y_test)
# 訓練用とテスト用に選ばれたセリフたちをログ出力しておきます
x_train_org = pandas.DataFrame(x_train_org, columns=['org_text', 'label'])
x_train_org.to_csv('train.csv', index=False, encoding='utf-8')
x_test_org = pandas.DataFrame(x_test_org, columns=['org_text', 'label'])
x_test_org.to_csv('test.csv', index=False, encoding='utf-8')
# モデルを訓練します
model.fit(x_train, y_train, nb_epoch=30, batch_size=20)
# 訓練したモデルの性能をテストします
scores = model.evaluate(x_train, y_train, verbose=0)
print("Accuracy (train): %.2f%%" % (scores[1]*100))
scores = model.evaluate(x_test, y_test, verbose=0)
print("Accuracy (test) : %.2f%%" % (scores[1]*100))
# 具体的に個々のデータに対してどのような確率分布になったか知りたい場合はログに付与します
prob = pandas.DataFrame(model.predict(x_train), columns = ['A', 'B', 'C', 'D'])
prob['predict'] = prob.idxmax(axis=1)
x_train_org = pandas.concat([x_train_org, prob], axis=1)
x_train_org['result'] = (x_train_org['label'] == x_train_org['predict']) # 正解不正解
x_train_org.to_csv('train.csv', index=False, encoding='utf-8')
prob = pandas.DataFrame(model.predict(x_test), columns = ['A', 'B', 'C', 'D'])
prob['predict'] = prob.idxmax(axis=1)
x_test_org = pandas.concat([x_test_org, prob], axis=1)
x_test_org['result'] = (x_test_org['label'] == x_test_org['predict']) # 正解不正解
x_test_org.to_csv('test.csv', index=False, encoding='utf-8')
# モデルの構造と訓練済パラメータを保存しておきます
json_string = model.to_json()
open('model.json', 'w').write(json_string)
model.save_weights('param.hdf5')