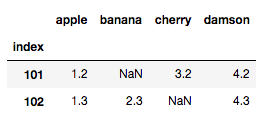
たとえば5万行のデータがあって、その中のNaNが入っている行を全て表示したいです。
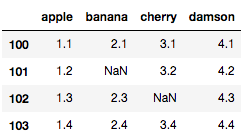
下のデータの場合 index 101のbananaと index 102のcherryにNaNが入っているので、その2行を表示したいです。
df = pd.DataFrame(
{
'apple' : [1.1, 1.2, 1.3, 1.4]
,'banana' : [2.1, np.nan, 2.3, 2.4]
,'cherry': [3.1, 3.2, np.nan, 3.4]
, 'damson': [4.1, 4.2, 4.3, 4.4]
},
index=[100, 101, 102, 103]
)
各カラムに何個の NaNが入っているかをチェックします。
df.isnull().sum()
結果:
apple 0
banana 1
cherry 1
damson 0
dtype: int64
type(df.isnull().sum())自体はpandasのSeriesデータタイプであることを確認
type(df.isnull().sum())
結果: pandas.core.series.Series
Seriesデータは iteritem()メソッド持っているため、NaNの個数0より大きいカラムを抽出します。
l = []
for index, value in df.isnull().sum().iteritems():
if value > 0:
l.append(index)
l
結果: ['banana', 'cherry']

上の図は別々で表示していますが、この複数行を連結して表示します(重複のindexを除いて表示する)。
result = []
for i in l:
result.append(df.loc[df[i].isnull() == True, :])
df_nan = pd.concat(result)
df_final = df_nan.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')
df_final