はじめに
最近話題になっている「Dify」のRAG機能が気になり、実際使ってみたのでその使用経験をご紹介します。
Difyとは?
DifyはオープンソースのLLMアプリ開発プラットフォームで、プログラミングの知識がなくても、簡単にカスタムAIチャットボットを作成できるノーコードツールです。Difyは非エンジニアでも使えるように設計されており、直感的な操作で多機能なチャットボットを作成することができます。
Difyのおすすめポイントは以下の4つです!
- プログラミング不要: コーディングの知識がなくても使えます。
- カスタマイズ可能: ユーザーのニーズに合わせたチャットボットを作成可能。様々なLLMを使ってチャットボット作成できるのもポイントです。
- 多機能: 様々な機能を簡単に追加できます。その中で「知識取得」というRAG機能もあります。
- ローカル環境でも使用可能: 自分のPC上で動作させることができます。
RAGとは?
RAG(Retrieval-Augmented Generation)機能は、LLMに最新の情報や特定の知識を提供するため、外部から関連情報取得して質問に答えるための仕組みです。
Difyではその機能が「知識取得(Knowledge Retrieval)」と呼ばれ、チャットボットに参考にして欲しいデータやドキュメントをナレッジ(Knowledge・知識)としてDifyに読み込ませることができます!
ローカル環境でRAG機能を利用したチャットボットを作ってみた
ローカルでDifyを動かすメリット
クラウド版のDifyを使用すると、以下のようなコストが発生することがあります:
- 利用料金: 言語モデルやその他のサービスの使用量に応じて課金されます。特に大規模なデータ処理や頻繁な使用がある場合、これが高額になることがあります。
- データストレージ: アップロードしたデータの保存にはストレージ料金がかかります。使用するストレージ量が増えると、料金も上昇します。
- APIコール料金: 外部APIを利用する際には、コール数に応じた料金が発生します。特にAPIを頻繁に呼び出すアプリケーションでは、このコストが大きくなります
ローカルでは、3つ目の項目だけがコストになりますので、ローカルで動かした方がコスパが良いです。Difyをローカルで使う場合は、DifyのGitHub を参考に構築しましょう。
ナレッジの使用方法
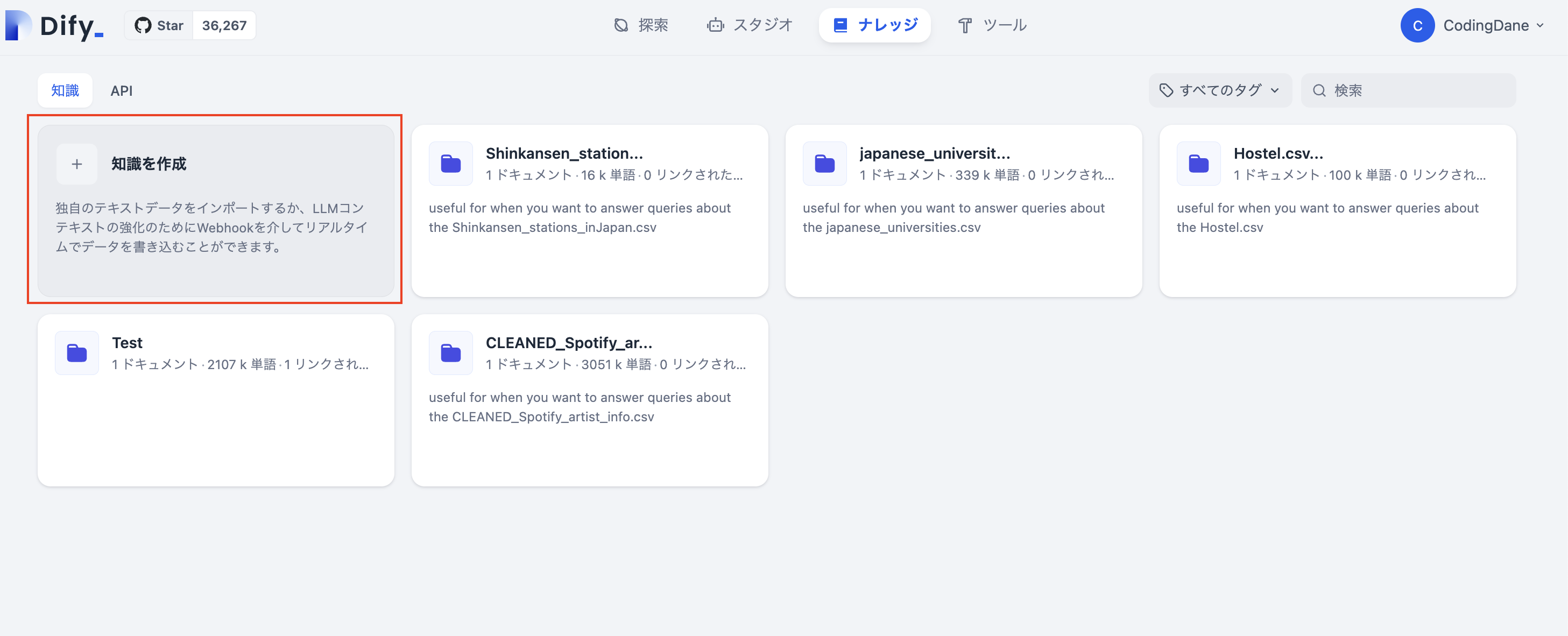
Difyのアプリでは、メニューバーの「ナレッジ」タブから新しい知識を作成することができます。
以前読み込ませたデータが知識として保存されて、ナレッジタブから管理できます。
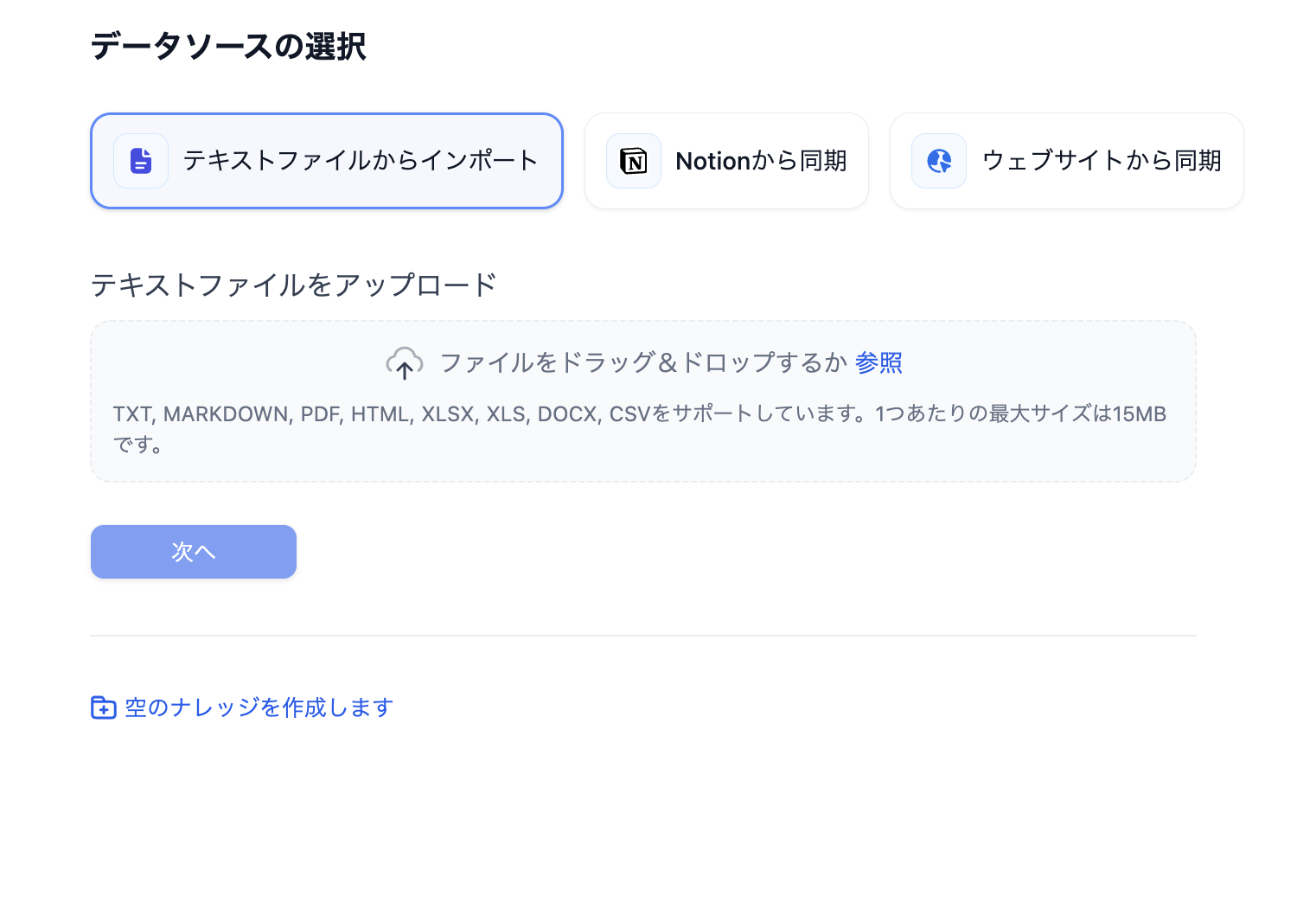
テキストファイルからインポートする場合はPDF、CSVなど、様々なフォーマットで読み込ませることができます。NotionやWebサイトからも同期する機能があり、例えば会社のNotionページから直接知識取得することも可能です。生成AIを使って社内ドキュメント検索ができれば非常に便利なのではないかなと思いました。
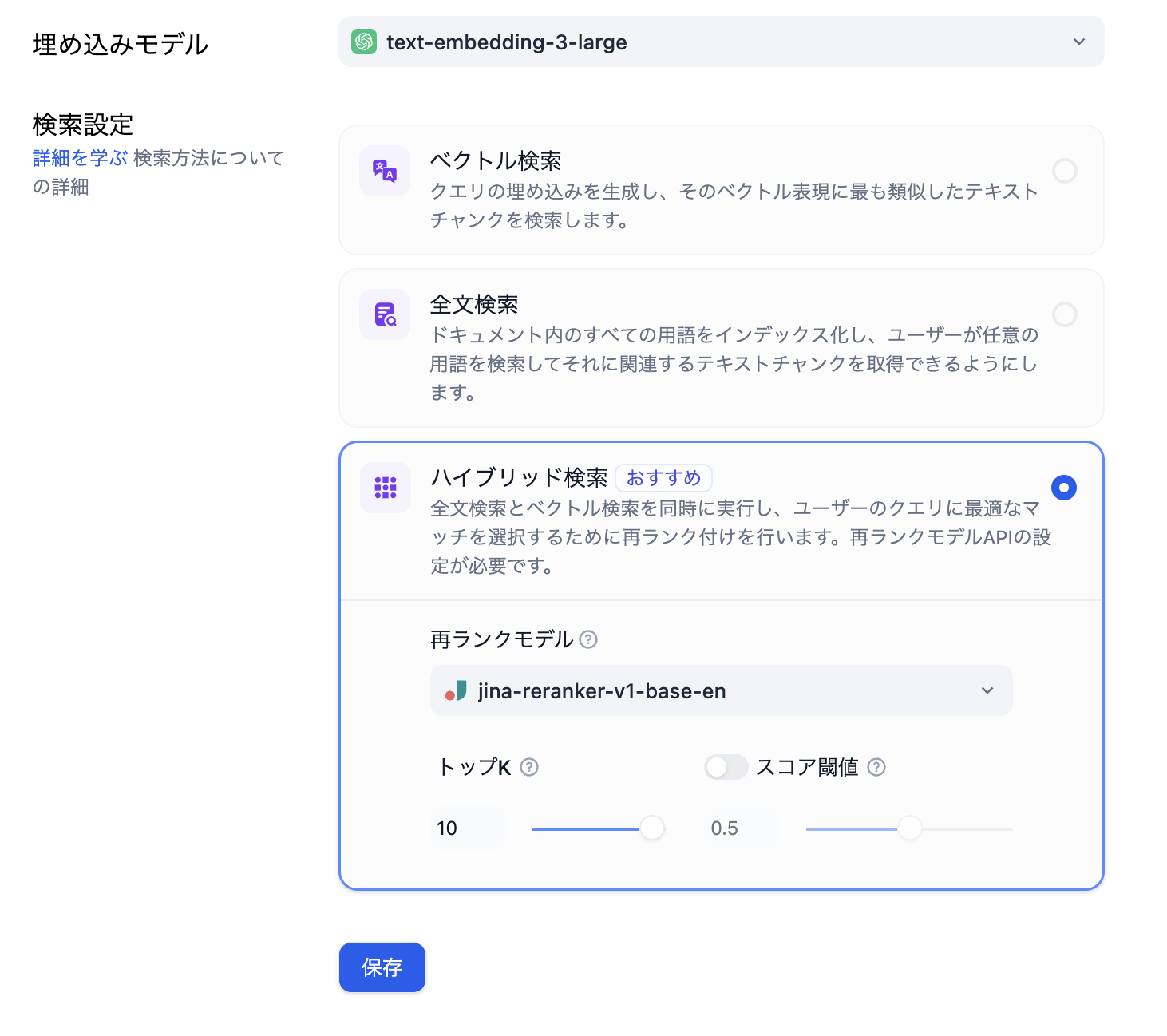
ファイルをインポートしてからは、Difyがどのように知識取得するかを選択できます。検索方法は3種類ありますが、「おすすめ」の「ハイブリッド検索」がうまく動いているので、そちらを利用しています。ハイブリッド検索はベクトル検索と全文検索が使われているので、どちらを選ぶか迷った場合には良い選択肢です。
再ランクモデルを使う場合、再ランクモデルを使う場合、Jina Ai RerankerのAPIキーを取得する必要があります(無料枠あり)。
今回はKaggle で見つけたデータを利用し、読み込ませてみました。
アプリ自体を作る
必要なデータをナレッジに読み込ませた後、アプリ自体を作成します。
Difyでは作成できるアプリの種類がいろいろありますが、いちばん簡単ですぐ使えるのが「基本」のチャットボットです。そちらを使うとすぐにチャットボットが作れます。
まずは右上のボタンで使用するLLMを選びます。非常に早くて安いので最近gpt-4oを使用しています。
ナレッジに読み込ませたデータ(知識)をコンテキストとしてチャットボットに追加することができます。手順(プロンプト)にはチャットボットの仕様を書いていきます。
今回の「Kaggle」から取ったダミーデータは日本のホステルに関するデータです。日本を旅行するなら役に立つ情報かもしれません!
右側のデバッグとプレビューでアプリを公開する前に実際に使ってみることができます。(公開するとはいえ、ローカルで動かしている場合、ローカルでしか公開されません。)
アプリの設定を行うと、チャットボットはそのまま利用できます。
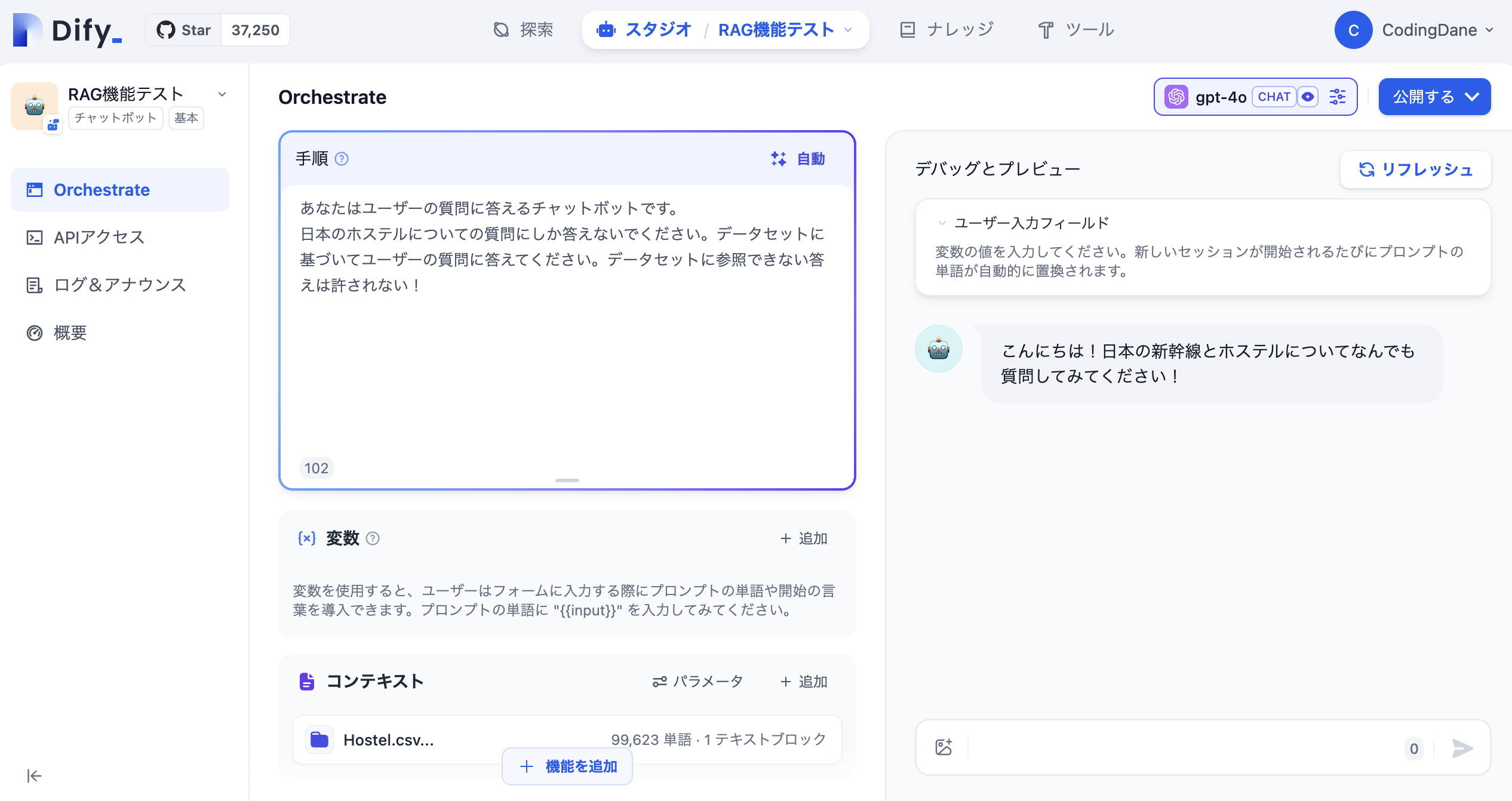
では、使ってみましょう!
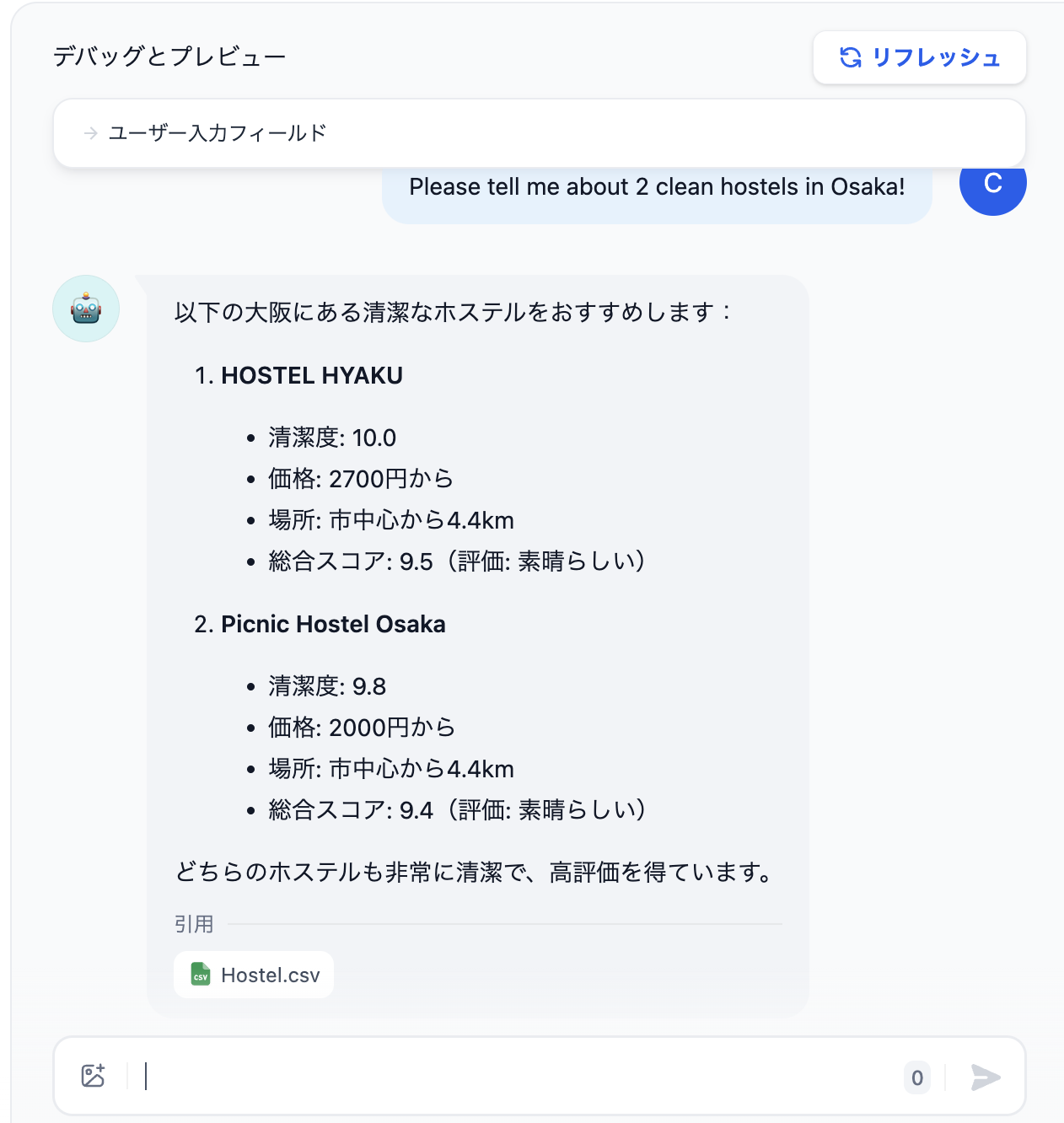
ホステルのデータに基づいて、「大阪の清潔なホステルを2つ教えてください」と聞いてみると、読み込ませたデータを参照にして、おすすめのホステルを教えてくれます。データセットが英語のため、英語のクエリにしか反応できませんでした(残念)。
しかし、非常に早いスピードでデータを取得することができ、成功して良かったです!