Controlled-Channel Attacks解説
Intel SGXに対する攻撃手法として最もメジャーなものの1つに、Controlled-Channel Attacks[1](絶妙に和訳しにくいので以下Controlled-Channel攻撃と表記します)というサイドチャネル攻撃があります。
論文中では、HAVEN[2]というSGXを利用したシステムとしてパイオニア的なシステムに対する攻撃も実際に実験しています。
本来、この攻撃はSGXあるいはTEEに限らず、信頼不可能なOSから保護された実行環境を提供するシステム(論文中ではShielding Systemと表現されています;以下、「シールドシステム」とします)というより広い括りの様々なシステムに対して有効とされるのですが、かの有名なIntel SGX Explained[3]というホワイトペーパーでも言及されており、その事実からも特にSGX黎明期における代表的な攻撃手法の1つである事が窺えます。
ただし、本攻撃はレガシーアプリケーション(SGX向けに記述されておらず、かつサイドチャネル攻撃対策もしていない、文字通り従来型のアプリケーション)をSGXの保護機能のもとで動かすことを可能にするシールドシステム(HAVEN以外に似たような有名なシステムですとGraphene-SGX[8]があります)を想定しています。
つまり、攻撃対象としてはそういった支援システムで動くレガシーアプリケーションであるという事になります。
後述のオフライン解析の都合上、SGXSDKを用いてビルドした素のEnclaveアプリケーションに対しては、攻撃の精度や幅が有意に下がると考えられます。
SGX然りこの手の研究・開発をしている人間は、学会等でほぼ確実に攻撃に対する安全の証明を求められるのもあり、Controlled-Channel攻撃のようにメジャーな攻撃とあらばまず目を通して出来れば自分の開発しているシステムに対策を盛り込む必要があります。
これに関しては、Intelもサイドチャネル攻撃対策はSGXを利用してアプリケーションを作る開発者が各自で行うように言及しており[4]、そういったスタンスを想定している事が窺えます。
本エントリでは、英語の論文を読まずともControlled-Channel攻撃のエッセンスが理解できるように、筆者が過去にサーベイした結果に基づいて図を交えながら解説していきます。なお、私自身SGXの研究をしていたのもありますので、本エントリでは基本的に攻撃対象はSGXを利用したシステムであるものとします。
おことわり
本記事の筆者は、SGXというOSSベースの技術をメインで取り上げている関係もあり、通常は原則として所属組織とは無関係の立場で記事を書いていますが、今回の記事は現在所属している株式会社AcompanyのAcompany Advent Calendar 2022の8日目の場を借りてもおります。
自己紹介についても、Controlled-Channel攻撃を知りたい方にとってはノイズにしかならないと思いますので、ここではいたしません。万一興味がある方は、筆者のQiitaアカウントのユーザページをご覧ください。
内容については他の記事と同様、所属組織とは一切関係ありません。
Controlled-Channel攻撃の概要
Controlled-Channel攻撃は、条件分岐とページフォールトを悪用する攻撃です。詳しい説明は後の項に譲りますが、直接の攻撃対象となる秘密情報は、この条件分岐の分岐条件となる変数の値となります。
条件分岐先にある変数操作や関数呼び出しの載っているページのアドレスを予め解析で特定した上でページフォールトを誘発し、ページフォールト時にページフォールトハンドラへ渡されるページアドレスを盗み見る事で、どちらの分岐に飛んだのか、ひいては分岐条件変数である秘密情報の値が何であったかを推測する事が出来てしまうのです。
ちなみに、攻撃名に入っている「Controlled-Channel」は、敢えて和訳するのであれば「制御されたチャネル(情報源)」となりますが、これは従来のサイドチャネル攻撃との対比で命名されています。
例えば、従来のキャッシュサイドチャネル攻撃や、ネットワークトラフィックを悪用したサイドチャネル攻撃は、少なからずノイズの入っているチャネル(情報源)を用いておりました。
しかし、Controlled-Channel攻撃で利用しているチャネル、つまりページフォールト関連の情報は、決定論的でノイズが入っていません。この事から、ノイズに左右されず攻撃者の意のままに情報を取れるという意味で、「制御された」チャネル、という表現を取っているようです。
前提知識
SGXに携わっているのであればご存知であるものも多いとは思いますが、Controlled-Channel攻撃を説明する上で必要となる知識についてまず説明を行います。読む必要のない箇所に関しては適宜読み飛ばしてください。
サイドチャネル攻撃
Controlled-Channel攻撃はサイドチャネル攻撃という種類の攻撃の1つです。サイドチャネル攻撃とは、暗号を直接解読したりする代わりに、周辺の現象や状況を観測・悪用して、攻撃対象のデータを推測し盗み出そうとする攻撃です。
簡単なものであれば入力データの違いにより発生する実行時間の差異から推測する攻撃から、電磁波を観測する攻撃、キャッシュヒット/ミス率を悪用する攻撃、そしてページフォルトを悪用する攻撃など、その攻撃手法は多岐に渡ります。
この中で、今回取り扱うControlled-Channel攻撃は、ページフォルトを悪用するサイドチャネル攻撃に分類する事が出来ます。
ページフォールト
仮想メモリを実現するアルゴリズムとして主流なものに、ページングというものがあります。これは、物理アドレス空間(メインメモリを始めとするハードウェアにて割り振られている実際のアドレス)及び仮想アドレス空間(後述の通り、物理的制約を大きく軽減できる、プロセスごとの論理的なメモリ領域)をページと呼ばれるブロックに分割し、このブロック単位で管理を行います。ページの大きさ(ページサイズ)としては、現在では4kBが主流になっています。
データの大きさがページサイズと完全一致しているという極めて極端な例ですが、ページングについての図を以下に示します。
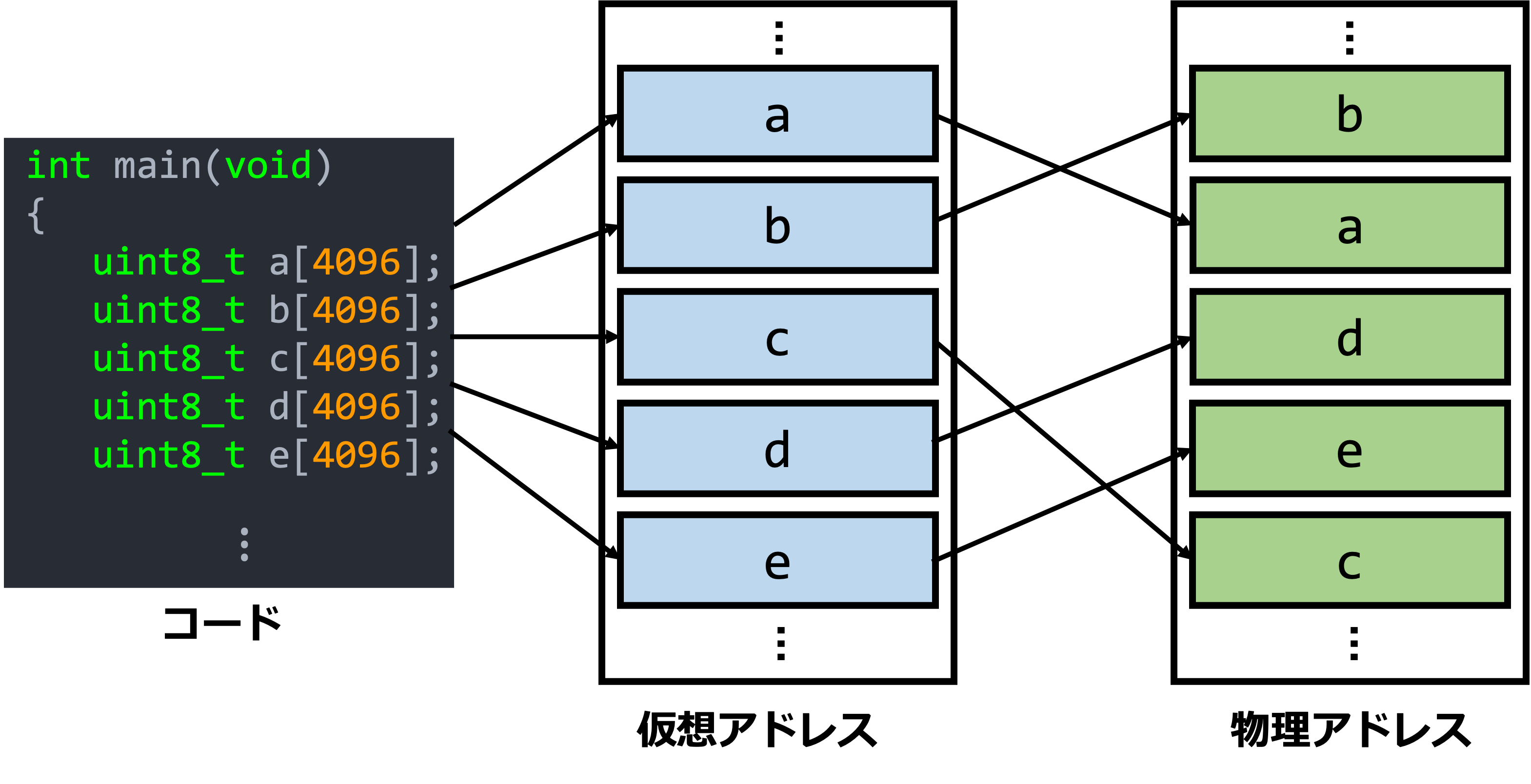
このように、仮想メモリ技術を取り入れる事によって、物理アドレス空間上の制約による影響を劇的に軽減する事が出来ます。上の図の例では、5つの連続しているページ間で順序が違っているだけなのであまり旨味がありませんが、例えば物理メモリ上で空いているページが飛び飛びであったとしても、仮想アドレス空間では連続にマッピングでき、物理アドレス空間上の制約を上手くいなせるわけです。何なら、仮想アドレス空間上のページは、RAMが枯渇しているようであれば補助記憶装置に移動して保持する事も出来るわけです(ページアウト)。
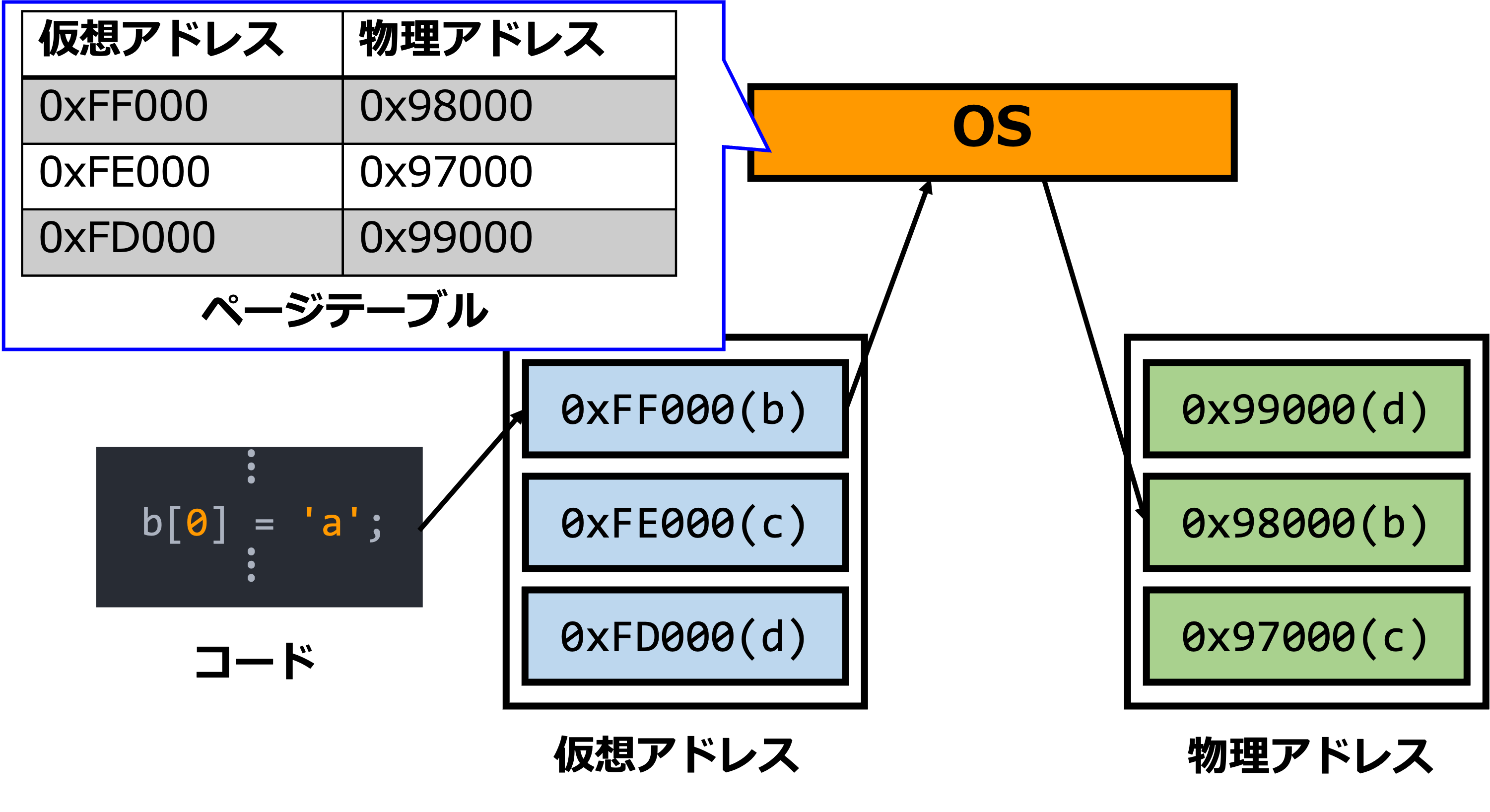
ここで、仮想アドレス空間と物理アドレス空間のページを紐付ける存在というものが当然存在します。この役割はページテーブルと呼ばれるデータ構造が担い、実際に対応付けを行っている実体をページテーブルエントリと言います(ページテーブルは格納場所、ページテーブルエントリはそこに格納される対応表、というイメージです)。文字通りページテーブルは各ページの仮想アドレスと物理アドレスの対応を保持しており、その実体はRAM上に展開されています。
しかし、RAMは比較的アクセスにコストのかかるデバイスなので、MMU(メモリ管理ユニット)内のTLB(Translation Lookaside Buffer)と呼ばれるCPU内のキャッシュメモリがページテーブルエントリのキャッシュを保持します。もちろん、キャッシュメモリであるTLBには全てのページテーブルエントリは入り切らないので、TLBに無いエントリの参照が試みられた場合はTLBミスとなり、RAM上のページテーブル本体が参照されます。また、仮想アドレスと物理アドレス間の解決(変換)は、MMUによって行われます。
以上の内容を図に示すと以下のようになります。
さて、MMUが仮想アドレスを物理アドレスへと解決しようと試みた際に、対応する物理ページがRAM上に存在しないケースがあります。これをページフォールトと呼び、そのページフォールトが発生した仮想アドレスをページフォールトアドレスと言います。最も分かりやすい例は、前述のように補助記憶装置へとページアウトされているようなケースです。
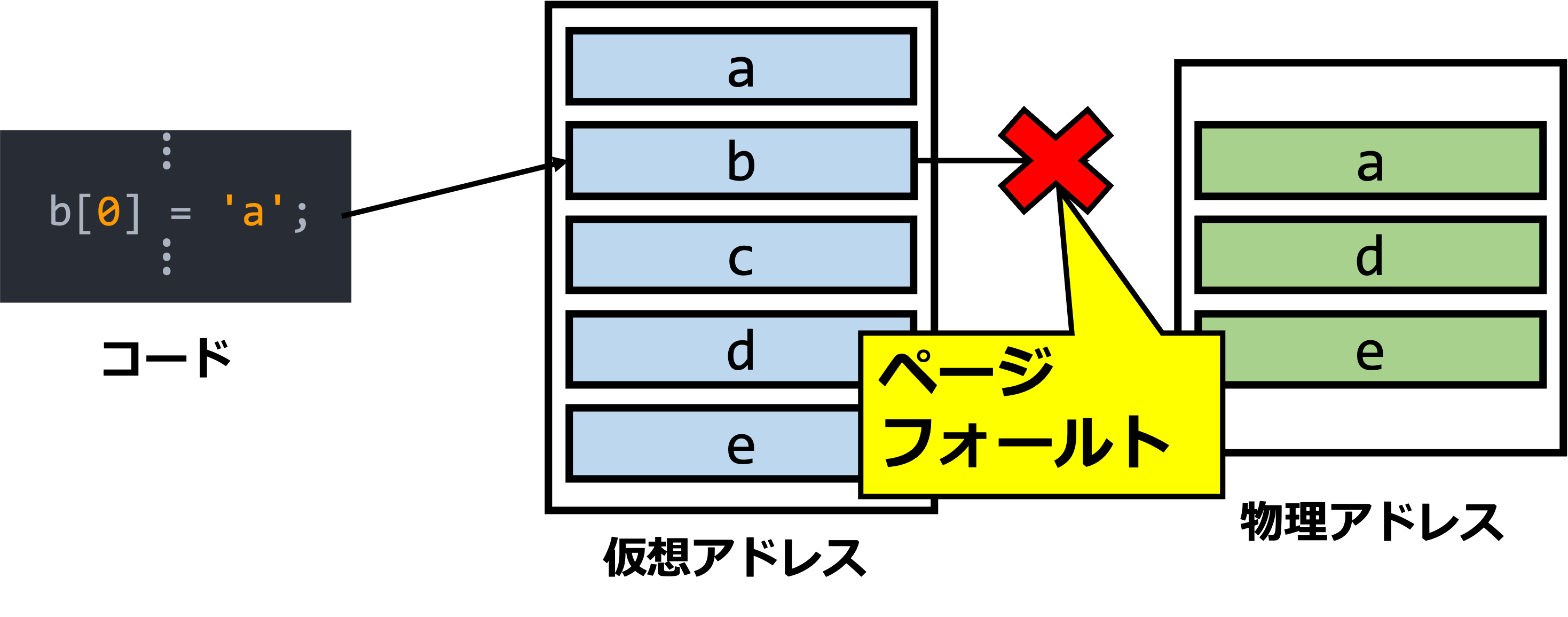
この場合、MMUではこれ以上の解決は行えませんから、どうにかして物理ページを利用可能な形でRAM上に引きずり出せとOSに命令します。OSは、ページフォールトハンドラと呼ばれるプログラムにこれを任せる事で、最終的にページフォールトを解決します。
もちろん、RAMが故障しているなどの致命的な原因があると、ページフォールトハンドラをもってしてもページフォールトを解決できない事もあるのですが(その場合は状況によってはBSoDやカーネルパニックになる事もあります)、基本的には上記の通り解決が可能ですので、ページフォールトは致命的ではないエラーに分類され、プログラムが強制終了する事はまずありません。
ページフォールトハンドラ周りについては、Controlled-Channel攻撃の説明部分でもう少し詳細に議論します。
入力依存処理
こちらは[1]の論文中での造語のようなものですので、語彙としては知らない事が多いかと思われます。
入力依存処理とは、ある入力となる変数の内容によって、その処理が実行されるか否かが決定されるような処理を言います。更に、入力依存処理には、入力依存制御転送(Input-dependent control transfer)と入力依存データアクセス(Input-dependent data access)が存在します。
…と書くと何だか堅苦しいですが、要は条件分岐先で行われる関数呼び出しや変数操作の事です。関数呼び出しの方が入力依存制御転送、変数操作の方が入力依存データアクセスとなります。
入力依存制御転送
では、入力依存制御転送の例をコード具体例を交えて見ていきます。
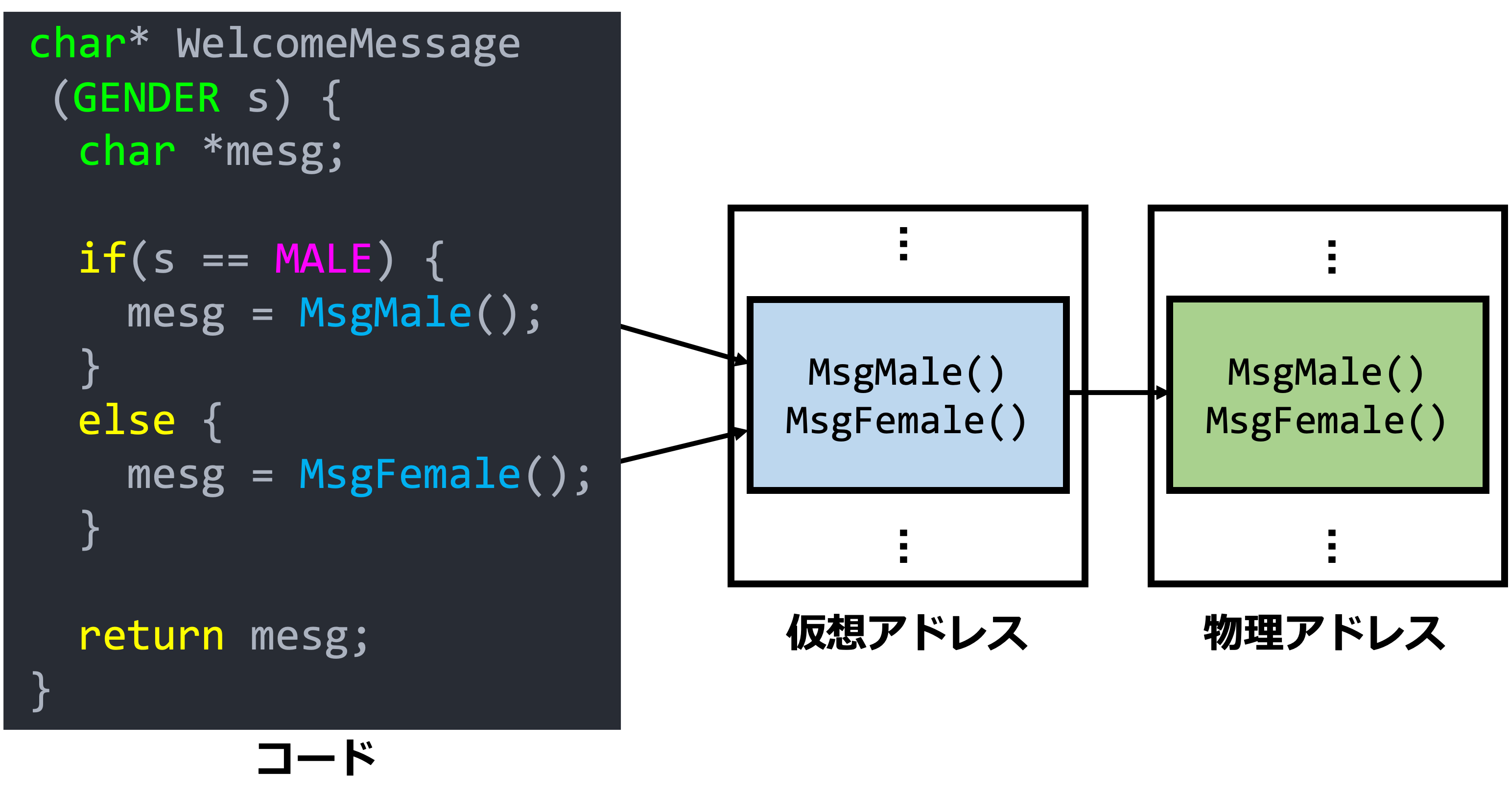
char* WelcomeMessage(GENDER s) {
char *mesg;
//GENDER is an enum of MALE and FEMALE
if(s == MALE) {
mesg = WelcomeMessageForMale();
}
else {
mesg = WelcomeMessageForFemale();
}
return mesg;
}
上記のコードの内、mesg = WelcomeMessageForMale();とmesg = WelcomeMessageForFemale();は変数s(性別)の内容によって分岐先が決定される条件分岐ブロックの中の関数呼び出しですから、これら2つが入力依存制御転送であるという事になります。
入力依存データアクセス
こちらもコード具体例を交えて見てみます。
void* CountLogin(GENDER s) {
if(s == MALE) {
gMaleCount++;
}
else {
gFemaleCount++;
}
return;
}
こちらの場合、gMaleCount++;とgFemaleCount++;が変数sの内容によって分岐先が決定される条件分岐ブロック中の変数操作ですので、これら2つが入力依存データアクセスであるという事になります。
些か唐突な話題とはなりましたが、この入力依存処理こそがControlled-Channel攻撃の成功の要となってきます。概要の項でも記述しましたが、上記の例で言えば変数sこそが本攻撃の攻撃対象になります。
Controlled-Channel攻撃の手順
さて、前提知識の説明が長くなってしまいましたが、いよいよControlled-Channel攻撃の説明に入っていきます。
攻撃の前提条件
攻撃者の能力
Controlled-Channel攻撃を仕掛ける対象のシステムが載っているOSは、同攻撃を行う攻撃者によって完全に制御権が掌握されているものとします。
普通こんな世紀末な状況はまず無いのですが、SGXなんかは「信頼可能領域はEnclaveと(Intel製)CPUのみとする」という設計思想のもとに開発されているわけですので、当然ユースケース内であればこういった苛烈な条件にも耐えられる必要が出てきます。
同時に、攻撃対象とするアプリケーション(HAVENであればHAVEN上で動作するアプリケーション)のソースコードについても攻撃者は入手しており、その内容を把握可能であるものとします。
一方で、Trusted領域(主にEnclave)の中で実際に動作中のコードについては、攻撃者は直接触れる事は出来ません。
攻撃対象のアプリケーション
先にも少し触れましたが、本攻撃のターゲットとしては、メモリアクセスパターンの撹乱などを行っていない(=有効なサイドチャネル攻撃対策を行っていない)、非SGX対応の従来型のアプリケーション(レガシーアプリケーション)をHAVEN等のシールドシステムで動かす場合が想定されています。
また、攻撃者の能力の項でも記載した通り、攻撃者がアプリケーションの動作を正確に知っている必要がありますので、アプリケーションのソースコード(あるいは解析に手間はかかりますがバイナリでも可)は公開されているものとします。特に攻撃対象がOSSであれば、この制約が障壁になる事はまずありません。
理想的な条件下でのControlled-Channel攻撃
Controlled-Channel攻撃は、大まかに言ってしまえば
- 攻撃対象の秘密情報に依存する入力依存処理及びアドレスの特定
- ページフォールトの誘発
- 観測結果からの秘密情報の推測・特定
という手順で進められます。
後述の通り、特にSGX等ではControlled-Channel攻撃を行う上で障壁となる問題が存在し、実際にはそれを回避する形の手順で攻撃を行いますが、本セクションでは基本部分をわかりやすくするため、まずは理想的な条件下(攻撃者が不自由なくページフォールトアドレスを取得可能な状況)での手順を説明します。
ちなみに、論文中ではオフライン解析とオンライン攻撃という語彙が出てきますが、オフライン解析は攻撃者の手元での解析、オンライン解析は攻撃対象システムでの攻撃本番、といったニュアンスで使われています。本記事でも、以降必要に応じてこの表現を使用します。
入力依存処理及びアドレスの特定
まずは、オフライン解析による下調べを行います。
手始めに、まず攻撃対象のアプリケーションのソースコードを見て、攻撃対象とする秘密情報を選定します。入力依存処理の項目で説明した通り、この秘密情報は条件分岐の分岐条件でなければなりません。当然ですが、条件分岐が発生すれば良い、即ち制御フローが1本で無くなれば良いので、条件分岐構文として必ずしもif文である必要はありません。
攻撃対象を選定したら、次はその秘密情報に依存する入力依存処理を特定します。要するに、攻撃対象の秘密情報を分岐条件として条件分岐先に存在する入力依存制御転送及び入力依存データアクセスを見つけるという作業です。
その後、実際にそのアプリケーションを手元(念の為記載しますが、実行はシールドシステム外で行う必要があります)で動作させ、関連する全ページへのアクセスを制限します。
ページへのアクセスを制限する方法として、論文中では、当該ページに対応するページテーブルエントリの予約ビット(例:x86-64アーキテクチャの場合、0オリジンでの51ビット目)をセット(1にする)手法を取っています。
これは、予約ビットを1にし、その状態でそのページテーブルエントリに対応するページへのアクセスが発生すると、強制的にページフォールトとなるという仕様を利用したものです。
この時、ページフォールトハンドラにページフォールトアドレスが渡され、OSからページフォールトアドレスが観測可能な状態になります。
その後、ページフォールトの発生したページへのアクセスを許可し、次の処理ステップに進んだら許可したそのページへのアクセスは再度禁止します。
再度禁止にする理由は、同じページ上の処理を再度行うというケースは当たり前にあるので、全処理に対するページフォールトアドレスを取得するには、アクセス禁止状態を保つ必要があるから、というものです。
このアクセス禁止→アドレス観測→許可・再禁止を繰り返す事で、お目当ての入力依存処理まで辿り着き、アクセス時のページフォールトアドレスを取得します。
この入力依存処理実行時のページフォールトアドレスは、言うまでもなくその入力依存処理の載っている場所(アドレス)そのものですから、これによって入力依存処理の場所を特定できるわけです。
また、実行の度に全く同じアドレスにロードされるわけは無いのですので、各アドレスはモジュール内でのオフセット(論文中での原文: module offsets)に変換しておきます。
ページフォールトの誘発・秘密情報の観測と推定
オフライン解析が完了したら、いよいよオンライン攻撃に入ります。
とは言っても、オフライン解析の時のように攻撃対象のマシンでページアクセス制限を行ってページフォールトを誘発させ、オフライン解析の結果に基づいてお目当ての入力依存処理に対応するページへのアクセスを観測するだけです。
ページフォールトが発生したら、そのページフォールトアドレスを確認し、どの入力依存処理が実行されたのかを確認します。実行された入力依存処理が分かれば、その分岐条件となった秘密情報がどういう値であるのかも推測できます(前の例で言えば性別の内訳)。
このようにして、Controlled-Channel攻撃により、入力依存処理の分岐条件となっている秘密情報を推測し、実際にかなりの精度でシールドシステム内の情報を取得できてしまうのです。
現実において直面する問題
さて、ここまでは理想的な条件下、つまり不自由なくページフォールトアドレスを攻撃者が取得できるケースでの攻撃方法を説明しましたが、わざわざ理想的な条件と断るだけあり、実際にはそう上手くは行きません。
今までの図では、各入力依存処理が律儀に別々のページに載せられているケースの描写をしていましたが、実際にはそのようなケースはかなり稀でしょう。
以下の図のように、複数の入力依存処理が同一のページに載るケースも、現実には当たり前のように発生します。
次に、SGXにおけるEnclaveのページング周りのセキュリティ境界を見てみます。
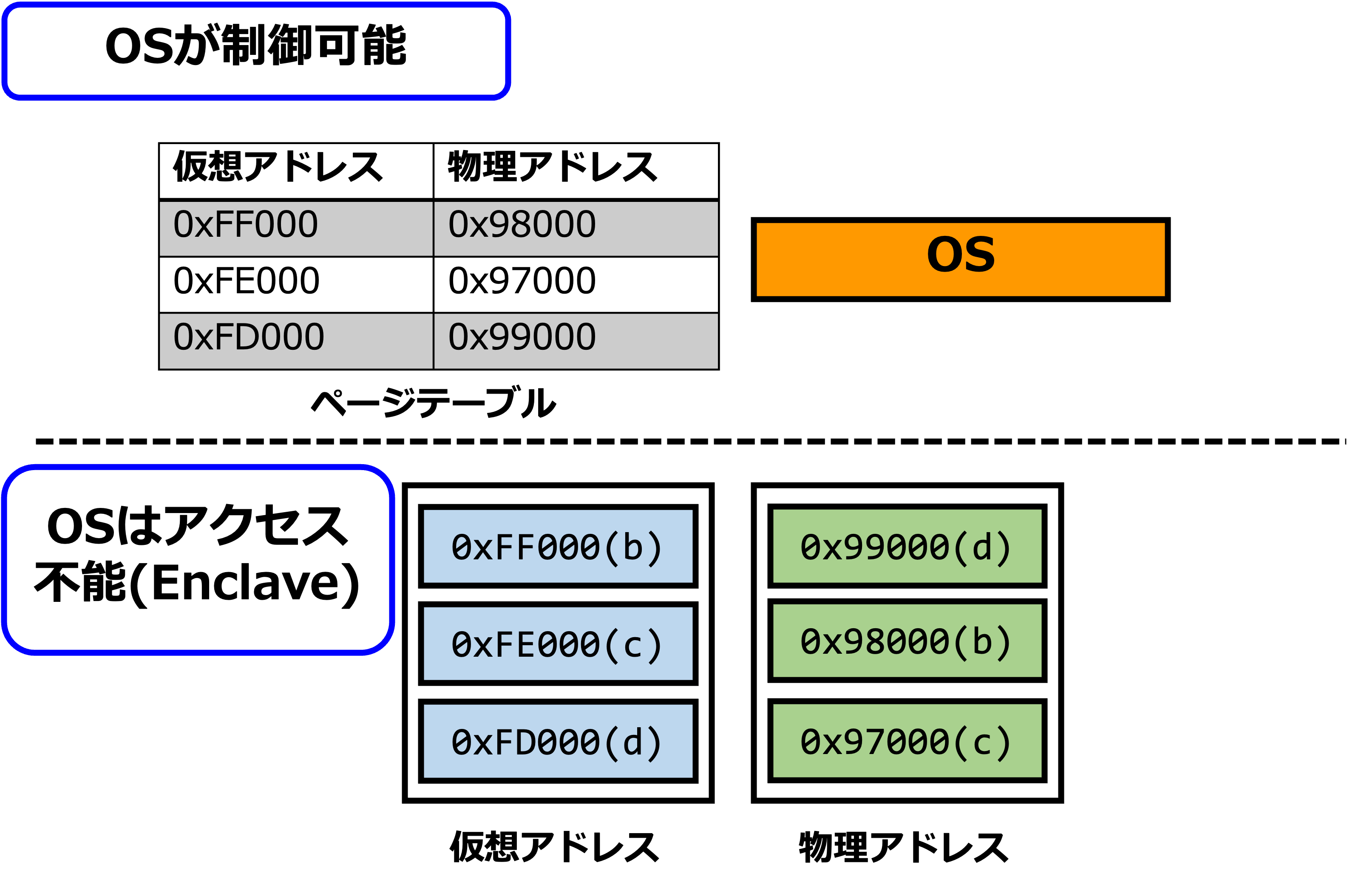
当然、Enclaveはその中のデータを保護するものですので、OSがこれにアクセスする事は出来ません。
一方で、実はEnclaveのページテーブルはEnclave外、即ちOSの制御下に存在しており、ページフォールトハンドラもOS側で実行されます。
つまり、Enclave側からページフォールトアドレスがOS上のページフォールトハンドラに通知されるわけですので、Enclave上のページフォールトに関しても、攻撃者はそのアドレスを見ることが出来てしまうのです。
また、Enclaveのページの操作は専用のスーパーバイザー命令(例:ECREATE、EADD)、つまりOS命令で行われますので、よりOSに知られるEnclaveページの配置マップの精度は高くなります。
と、ここまでの話だけでは、「それならSGXでも問題なく攻撃が通るのではないか?」となると思いますが、問題はそのSGXにおけるページフォールトアドレスの通知の仕様に存在します。
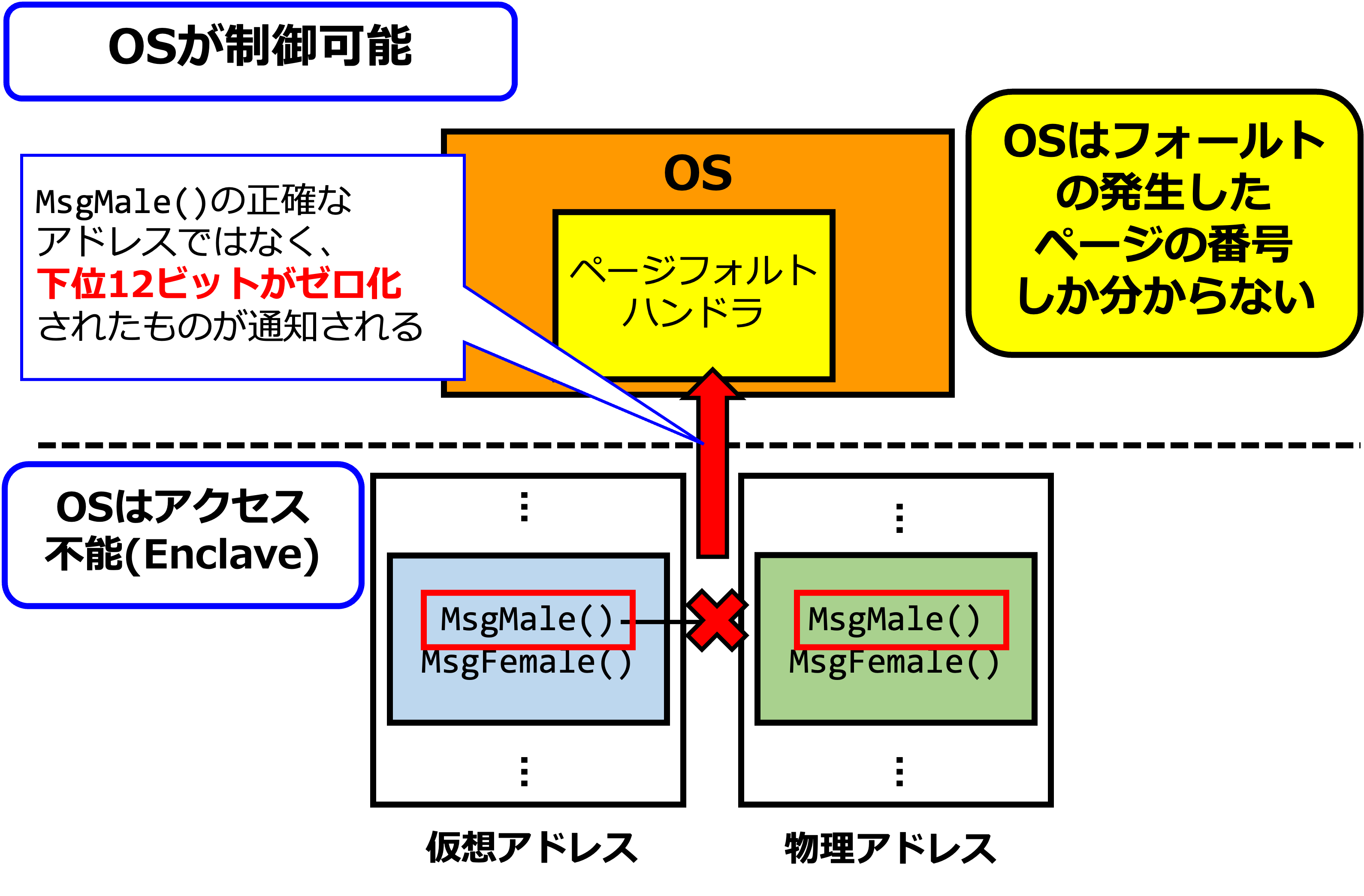
安全上の問題から、SGXはページフォルトアドレスの下位12ビット、即ち丁度一般的なページサイズである4kB分をゼロ化してページフォルトハンドラに通知する、という仕様を採用しています。
これはつまり、HAVENのようなSGXベースのシールドシステムにおいては、対象の複数の入力依存処理が同一のページに載っている場合、理想的な条件下でのやり方では識別する事が出来ない(ページフォルトアドレスがページ単位の粒度でしか返ってこないため)、という事になります。
実際の条件下でのControlled-Channel攻撃
この「SGXがページ単位の粒度でしかページフォールトアドレスを返さない」問題は、攻撃者からしてもどうしようもありませんので、ページ単位の粒度でも同一ページ内の入力依存処理を識別出来る方法を用いるアプローチを取っていきます。
そのために、「ページフォールトシーケンス」という概念を導入します。
概念、というと小難しそうに聞こえますが、要はその入力依存処理に到達するまでに発生した、一連のページ単位の粒度のページフォールトアドレスの事です。
この内、入力依存制御転送についてのページフォールトシーケンスを「コードページフォールトシーケンス」、入力依存データアクセスについてのものを「データページフォールトシーケンス」と論文中では呼んでいます。
下の図では、ページDに存在する2つの関数の呼び出し(制御転送)を識別するケースの例を示しています。
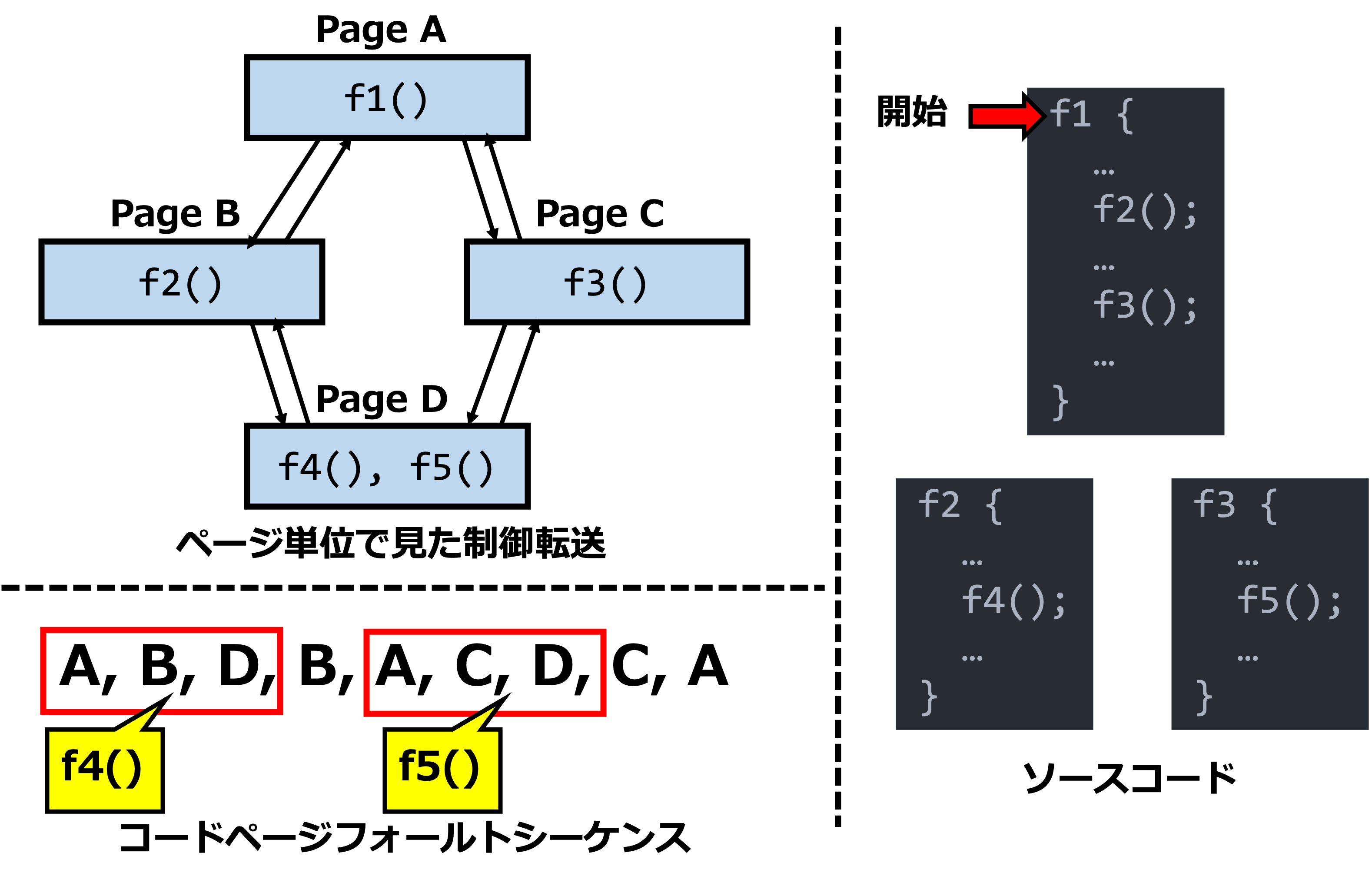
関数f4とf5は、確かに配置されているページ自体は同じページD上ですが、エントリポイントである関数f1からの関数呼び出しの経路までは同じではありません。実際、関数f4はf1→f2→f4の順であり、関数f5はf1→f3→f5の順番となっています。
つまり、ページDだけでは判別できなくても、途中経路となるページでのページフォールトも含めて観測してしまえば、同じページ上に複数の入力依存処理が存在していても識別できるというわけです。
ページフォールトシーケンスを採用した所で、工作・観測対象のページが単純に増えるだけなので、ページアクセス禁止→ページフォールトアドレス観測→ページアクセス許可・再禁止の繰り返し、という攻撃のエッセンスは、理想的な条件下の場合の攻撃と同じです。
入力依存制御転送の場合
こちらはほぼ直前の説明の通りです(というより、直前の説明が制御転送の場合の概要です)。
論文中では、オフライン解析にて一度バイトレベルの粒度でページフォールトアドレスを取得後、それをページ単位の粒度に変換(そのページフォールトアドレスの発生したページのベースアドレスに変換)しています。
もしオフライン解析でページ単位の粒度でしか取れないと、そもそも同じページ内のどの関数が呼ばれたのかを識別出来なくなるケースが存在するので、オフライン解析の時点ではバイトレベルの粒度で観測する必要があります。
勿論、その場合でもコードと照合して入力を操作したり、乱数的に生成される要素であってもメモリを覗けば特定できなくは無いとは思いますが、実際の入力となる秘密情報は前の例のように男女の比較一回で終わり、のように単純ではありませんから、現実的にはバイトレベルでの観測が好ましいでしょう。
その後も理想的な条件下の場合と同様に、オフライン解析で得られたアドレスはモジュール内でのオフセットに変換し、実際にオンライン攻撃を仕掛け、オフライン解析で得たページフォールトシーケンスとオンライン攻撃でのそれを比較して秘密情報を推定します。
偶然にも運悪く全く同じページフォールトシーケンスを通る可能性も無くはないですが、実際に観測してみると、論文中に示されている攻撃で制御転送それぞれについて少なくとも通常長さ2〜3の単一の他と識別可能なページフォールトシーケンスが取得できると記されています。
入力依存データアクセスの場合
データアクセスの場合、制御転送と違って変数から別の変数の場所に制御転送される、みたいな事は発生しないので、一工夫入れてあげる必要があります。
まず、オフライン解析において、対象のデータアクセスにより発生するページフォールトを観測を全て観測します。
次に、そのデータアクセスによるページフォールトそれぞれについて、そのデータページフォールトが発生するまでの一連の関数呼び出しのページフォールト(関数呼び出し→関数エントリ→関数内でデータアクセスの順で処理が進むので、一連の最後の関数呼び出しに対応するページフォールトは、データアクセスのページフォールトのわずかに前に発生します)の流れ、つまりコードページフォールトシーケンスを導出します。
その後、オンライン攻撃ではそのコードページフォールトシーケンスを用いて照合する事で秘密情報を推測する、という流れになります。
簡単に言ってしまえば、データアクセスだけで追うのは厳しいので、データアクセスに関連する関数呼び出しのページフォールトシーケンスを頼りにしてしまおう、という考え方です。
制御転送の場合と同様、それぞれについて少なくとも通常長さ2〜3の単一の他と識別可能なページフォールトシーケンスが取得できるようです。
入力依存データアクセスの場合も、制御転送の場合と同様、オフライン解析での観測の時点では、バイトレベルの粒度での観測が現実的には必要になり、論文中でも実際そうしていると記載されています。
ASLRに対する攻撃
ここまでとは若干雰囲気が変わりますが、このセクションではASLRに対する攻撃を見ていきます。
ASLR(Address Space Layout Randomization)とは、日本語にすると「アドレス空間配置のランダム化」となり、あるプロセスにおいてその元となる実行バイナリ・ライブラリ・スタック・ヒープといったものを、実行の度に無作為に配置するというものです。
Controlled-Channel攻撃の文脈では、この中でもプロセス内での(複数の)実行バイナリの配置撹乱が主に論点となります。
これまで説明した手法はあくまで配置が固定されている場合に通用するものですので(ちなみに論文時点ではHAVENではASLRは使用されていないようです)、ASLRが使用されているとそのままでは攻撃が通りませんが、ここでローダに目をつけます。
ローダとは、文字通りプログラムを補助記憶装置等からメモリにロードしてくるようなプログラムですが、実はこのローダに関しては、ASLRを使おうが開始地点が常に一定となります。かつ、その開始地点のコードは、プロセス全体で見ても最初に実行される部分となります(論文中では、例としてntdll.dllのLdrInitializeThunkという関数をあげています)。
よって、ページアクセスを制限した状態でプロセスを起動すれば、最初に発生するページフォールトはローダのものである事が確定し、ローダのベースアドレスを特定する事が出来ます。
その後は、ローダのベースアドレスを頼りにし、ローダの他の部分やローダによってロードされる実行バイナリが配置される場所に至るまで、自在にアクセス出来るようになります。
後は、複数の実行バイナリの内どれが読み込まれ実行されているかを探れば完全にASLRの影響を無視できます。この識別方法は簡単で、オフライン解析において各実行バイナリの最初の数個のページフォールトのパターンを記録し、オンライン攻撃時に照合してあげるだけです。
場合によっては実行バイナリの遅延読み込みが行われるかも知れませんが、この場合は新しくマッピングされたメモリ領域(つまり、実行バイナリがロードされる予定の場所)のアクセスを制限し、その領域上の最初の数個のページフォールトを追跡する事で、実行バイナリの特定に至るまで問題なく対応できます。
ページフォールトの取り扱いについて
前のセクションまでで、Controlled-Channel攻撃の基本部分は一通り説明しました。ここでは、攻撃中のページフォールトの取り扱いに関する少し細かめな説明を行います。
トラッキングページと誤検出
理想的には、オンライン攻撃時は全てのページに対し工作・観測できれば嬉しいですが、現実的にはそれはなかなか難しい所があります。
そこで、実際にはオフライン解析で得られたページフォールトシーケンスに含まれる全てのページを「トラッキングページ」として扱い、オンライン攻撃時はこのトラッキングページを対象とします。
しかし、このトラッキングページを使用する方法を取ると、誤検出(False Positive)を誘発してしまう可能性があります。
例として、検知したいシーケンスが「ページA→C」であるとします。この場合、例えば「ページA→B→C」は、本来検知対象のシーケンスではありません。
しかし、オフライン解析時点でページBがトラッキングページに加わっていない(ページフォールトシーケンスにBが入るパターンが無かった)可能性もあります。
こうなると、観測対象のページはAとCだけで、Bは観測しませんので、検知対象でない「A→B→C」のシーケンスを「A→C」であると誤検出してしまうリスクがあるのです。
この誤検出を避けるには、
- オフライン解析で得た一連のページフォールトの観測結果の内、誤検出シーケンスが発生しそうな部分を抜き出す(この時点では厳密に誤検出シーケンスと一致している必要はない)
- 抜き出した部分の内、完全に観測不要なページを削ったり、その結果生まれた重複(例:A→D→A→B→CからDを削った結果出来たA→A)を結合して整形する。
- 誤検出シーケンス候補を見つけ出す(本来A→Cが正しいが、A→B→Cとかは誤検出に繋がりそうなので検出する)
- 上の候補に含まれているページBは、トラッキングページには含まれていない。よって、トラッキングページにBを追加し、誤検出が起こらないようにする(Bが加わる事により、A→B→Cをちゃんと認識できるようになる)
といった手段を取れば良い、と論文中で示されています。
2つのページを跨ぐ制御転送
ある関数呼び出しが2つのページを跨いでしまうと、今までの処理ではページ1つずつしか制限・許可の操作を行わないため、前半許可→前半禁止→後半許可→後半禁止を繰り返す事により、無限ループに陥ってしまう可能性があります。
関数呼び出し命令を見る際は当然その命令の全体を一度に見るので、前後半の値をそれぞれ一時的に控えておく、みたいな芸当は出来ません。
これを防ぐ方法は至って単純で、このように連続する2つのトラッキングページを跨ぐ命令があるかを確認し、そこでページフォールトが発生した際には両方アクセス可能にしてあげるだけです(その後の再制限も同様)。
データアクセスの場合の処理
かなり細かい話ですが、データアクセスのページフォールトを検出する場合、コードページフォールトシーケンスを頼りに探りますので、そのデータの載るページ自体は必ずしもページアクセス許可後再度制限にする必要はありません。
単純にデータアクセスが発生したかを確かめたいだけの場合(前述の性別の例など)は、一度検知できれば問題ないので、ページアクセスを再制限する必要はなく、手間が省けます。
何らかの理由やケースで、データアクセスの回数までカウントしたい場合のみ、制御転送の場合と同じく再制限をする必要があります。
実際の攻撃結果
論文では、実際にHAVENを含むシールドシステムに対してControlled-Channel攻撃を行い、かなりの精度で中身を抽出できている事が示されています。
中でも視覚的にわかりやすいのが、シールドシステム内で動作するlibjpegの逆離散コサイン変換の処理を狙い、秘密情報である画像を抽出した攻撃例です。その攻撃結果の画像を論文より引用します:
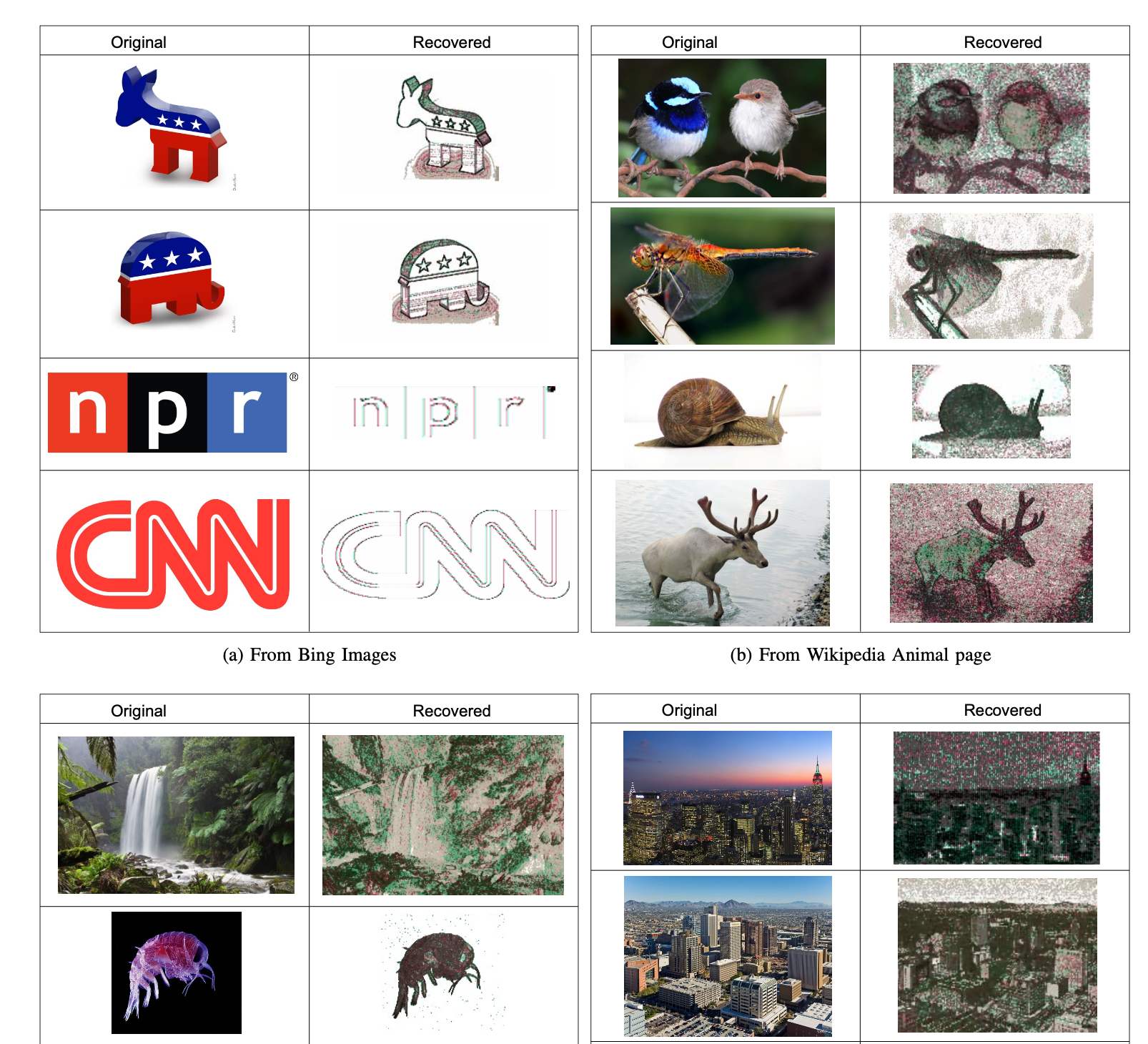
(cited from "Controlled-Channel Attacks: Deterministic Side Channels for Untrusted Operating Systems", by Yuanzhong Xu, Weidong Cui and Marcus Peinado. 2015 IEEE Symposium on Security and Privacy, [https://ieeexplore.ieee.org/document/7163052], page 656)
このように、直接データを盗まず、あくまでも周辺の事象から推測するサイドチャネル攻撃であるにも関わらず、被写体の輪郭や色の濃度などがかなりの精度で抜き出せており、相当強力な攻撃である事がわかります。
その他にも、シールドシステム内で動作するスペルチェッカを標的とし、秘密情報である文字列を抽出する攻撃の結果も記載されていますが、同様にかなりの精度で抽出する事に成功しています。
対策
論文中では、Controlled-Channel攻撃に対する軽減・対応策もいくつか上げています。
例えば、HAVENのようなシールドシステムであれば(SGXSDKで開発した素のEnclaveアプリケーションで無ければ)、OSがページング(ページフォールト関連処理を含む)できるのはアプリケーション全体の割り当てまでに制限し、それ以上の粒度の処理はシールドシステムが担当するようにすれば、Controlled-Channel攻撃は一切通用しなくなります。
何故ならば、OSにアプリケーション自体の配置の粒度以上の事を出来なくしてあげれば、極論OSはアプリケーション全体の始端と終端のアドレスしか分かりませんので、例えば内部の制御転送やデータアクセスでのページフォールトの解決は全てシールドシステムが処理し、OSにそれが漏れる事は無いからです。
その他の例として、適切なノイズ注入、Oblivious RAM、更には配置ランダム化の粒度をより上げたバージョンのASLRなどが論文中では挙げられています(本記事ではこれらの説明は省略します)。
論文中に記載されていない対策例としては、以下のものが挙げられます。
専用の対策技術を使用する
前述のlibjpegの攻撃例の精度を見ても分かる通り、このControlled-Channel攻撃はかなりのインパクトを界隈に与え、結果としてこの攻撃を無効化する専門の技術も開発されています。
有名な例としては、SGX-LAPD[5]やT-SGX[6]が挙げられます。
分岐を消す
非常に力技な方法ですが、あくまでControlled-Channel攻撃は条件分岐先から分岐条件の中身を推測し、秘密情報を抽出する攻撃ですので、そもそも条件分岐を使わなければ、根本的にこの攻撃は通りません。
この方法は論文中にもある通り、レガシーアプリケーションのコードから条件分岐を消し去るには大幅な改修が必要になるため、HAVENのようなレガシーアプリケーションをそのままSGX保護下で動かせることを売りにしているシステムの場合は、売りの部分を完全に損なってしまう方法となります。
この方法を採用しているシステムの例として、SGX-BigMatrix[7]があります。
SGX-BigMatrixは、大規模行列演算を秘密計算で行うために開発されたシステムで、独自開発のコンパイラにより、一切の条件分岐を徹底的に排するというアプローチを取っています。
コード暗号化
Controlled-Channel攻撃は、あくまで攻撃対象のアプリケーションのコードが公開されている場合のみ有効、と論文中では書かれています。
しかし、通常のEnclaveアプリケーションではそもそもコードは保護されませんし(実際、Enclave内での実行定義を詰めた共有ライブラリはUntrustedな領域、つまり通常のファイルシステムに配置され起動されるため、外から実行定義は見放題です)、シールドシステムでもUntrusted領域上に配置するものも多いでしょう(少なくとも、2017年時点でのGraphene-SGX[8]はその方式でした)。
また、UHD BDのDRM処理のユースケースのように、コードを公開しなくても問題がなく、その上実際に非公開にしているケースでも、内部の人間の手違いやサイバー攻撃によって流出してしまう可能性も否めません。
ここで、コード非公開のまま運用しても問題のないユースケースである場合に限り、Untrusted領域への配置や、意図せぬ流出からコードを守るための拡張機能として、SGX-PCL[9](Protected Code Loader)というものがIntelから公開されています(本記事執筆時点で既に開発・運用管理が放棄されているみたいですが…)。
SGX-PCLとは、ごく簡単に説明すると、Enclaveの共有ライブラリの内保護したい部分(初期処理や復号のための暗号処理部分等、後続のPCLの動作に必須の処理は当然対象外です)だけ暗号化した状態でデプロイし、後からAES鍵をTLS通信路を通して送り込み、暗号化部分を復号して処理を始める、というものです。
これを使用すれば、非公開で済むユースケースである場合に限り、より流出やバイナリの盗聴に対する防御の確実性を上げる事が出来るでしょう。
反対に、SGXを秘密計算利用するケースのように、コードが悪さをしていないかを確認した上でRemote Attestationで正当性を確かめる必要がある場合は、SGX-PCLは完全に不向きであると言えます。一応、マシン上のUntrusted領域に配置された共有ライブラリを覗いての解析は阻止できますが、その効果は限定的です。
Intel以外から公開されている似たような技術としては、SGXElide[10]というものがあります。こちらは、コードの隠したい部分を抜き取って信頼可能な第三者サーバに送り、ランタイム時にその第三者サーバから抜き取った部分をくっつけて実行する、というアプローチを取っています。
抽出可能な秘密情報の粒度を下げる
また違った見方をすると、Controlled-Channel攻撃を仕掛けて抽出できた情報が、秘密を特定できないレベルの粒度の無意味なものであれば、攻撃は結果的に失敗に終わる事になるでしょう。
一見何を言っているんだ、と思われるかも知れませんが、これを実際に可能とするアプローチが存在します。それは、「Enclave内でインタプリタを動かし、そのインタプリタ専用のスクリプトコードをTLSチャネルでEnclaveに直接送り込んで実行する」、という方法です。
この方法を使用しているシステムとしては、手前味噌ながら筆者の開発したBI-SGX[11]があります。また、TrustJS[12]というシステムも、BI-SGXとはユースケースは別であるものの、JavaScriptのインタプリタをEnclave内で動かす構成を取っているようです。
筆者が自前で開発した手前、説明に使用しやすいのでBI-SGXのケースを取りますが、インタプリタをEnclave内に載せてそこにスクリプトコードを送り込んで動かすアプローチの場合、以下の図のようにスクリプトコードは完全に保護され、一方でインタプリタ本体のコードがパブリックになります。
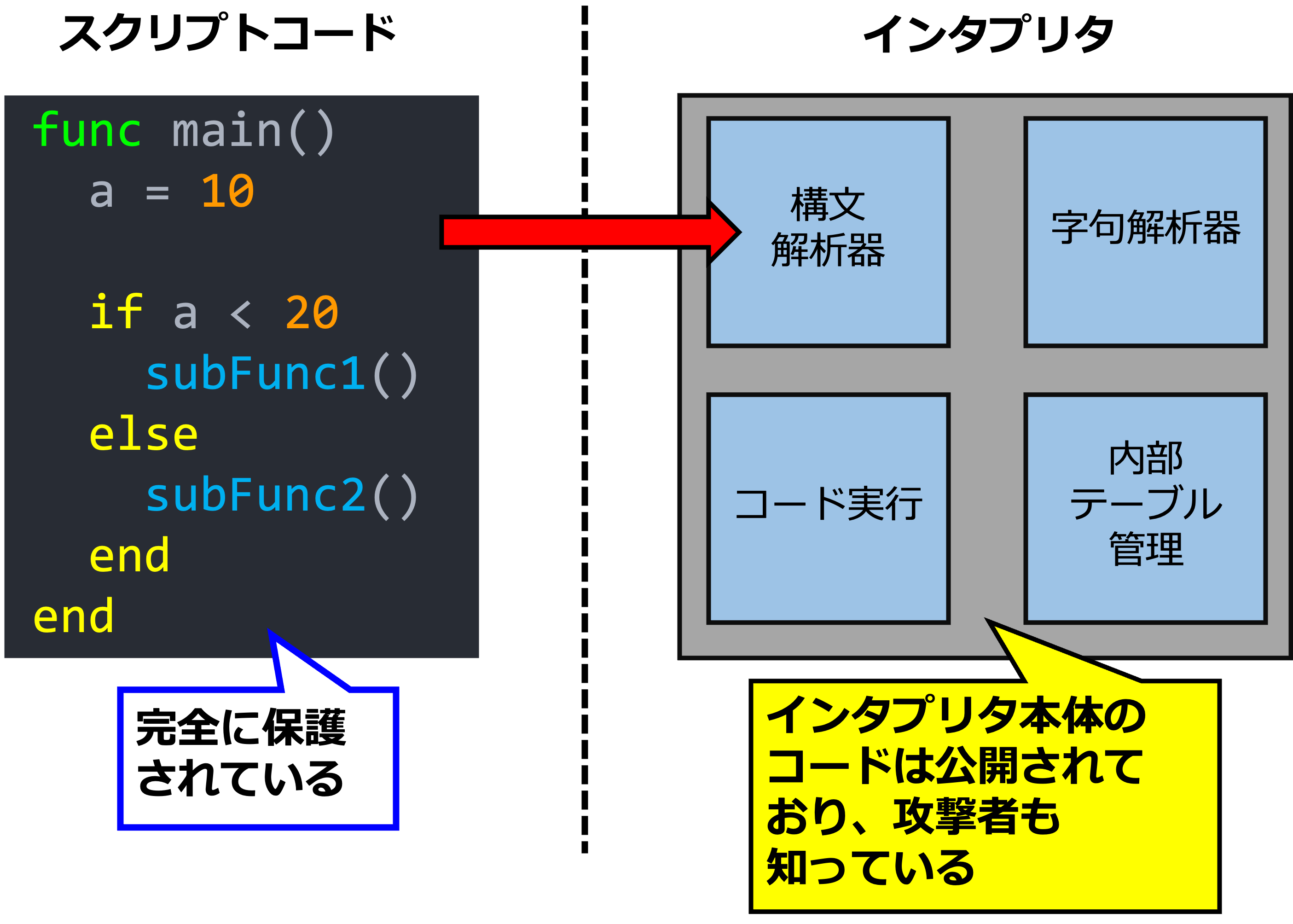
必然的に、攻撃者はインタプリタ本体のコードに対してControlled-Channel攻撃を仕掛ける事になるわけですが、この時、攻撃者は以下の情報を抽出する事が出来ます:
- トークン単位の粒度のスクリプトコード
- トークン単位の粒度の、構文解析後に生成された内部コード
- トークン単位の粒度の、変数及び関数に関する内部テーブル
- どの組み込み関数が実行されたか(少なくともBI-SGXでは、組み込み関数には専用のトークンが割り当てられるので判別可能です)
ここで、トークンとは、コード内の各要素の種別をベースとした処理単位のようなものであり、変数、関数、if、値(Value)、のようなかなり大雑把な粒度となります。
反対に、以下の情報はどうやっても抽出できません:
- 変数や関数の名称
- 変数の値
要するに、インタプリタでは全体を通してトークン単位の粒度で処理が進み、必然的に分岐条件となるものもトークンなので、攻撃者はトークンというぼやけた粒度の情報より詳しい情報を抜き出せない、という事です。
例えば、スクリプトコード内の変数の値が5以上だったら、その変数はこっちの分岐に飛ばす、みたいな条件分岐はインタプリタ本体のコードでは絶対に発生せず、一律で「値」の粒度でしか扱われません。
(これ以上は言語処理の話になってしまい、脱線してしまうので詳細は省きます)
こうなると、直前の図の左側のコードをインタプリタに送った場合、攻撃者から見えるのは、以下のような情報になります。

このように、攻撃者からすれば「何らかの変数を何らかの値と比較し、分岐先で何らかの関数が呼ばれた」より詳しいことが分からないので、結果としてControlled-Channel攻撃を対策できている、という事になります。
Controlled-Channel攻撃を検知する
こちらは今までとは打って変わり、ある種対症療法的な手段ですが、Controlled-Channel攻撃の可能性や痕跡を検知した瞬間に、その場で処理を中断する等の緊急対応を取る方法です。
Controlled-Channel攻撃では多数のページフォールトを誘発させますから、まずページフォールト回数は有力な判断材料になります。
同時に、ページフォールトは決してコストの低い処理ではありませんから、必然的に実行時間も増大し、そこからも検知する事が出来るでしょう。
ただしこの方法を取ると、誤検知により意図せず処理が停止してしまう可能性があり、また、この緊急対応を悪用しDoSを図る(処理を妨害する目的で、意図的にページフォールトを乱発させる)攻撃者が出てくるかも知れませんので、思考放棄で採用できる対応策でない事は確かです。
SGXSDKで開発した「素のEnclaveアプリケーション」の場合
最後に、通常のSGXプログラミングで開発したコードからSGXSDKでEnclaveの共有ライブラリをビルドして動作させる、言わば「素のEnclaveアプリケーション」に対して攻撃する場合について考えてみます。
前述の通り、論文中では一貫してレガシーアプリケーションをシールドシステム内で動作させる場合を攻撃対象として想定しています。
では、シールドシステムの場合と素のEnclaveアプリケーションの場合の最大の差は何であるかというと、オフライン解析において得られるページフォールトアドレスの粒度となります。
シールドシステムの場合、オフライン解析ではシールドシステム外で動作させ、バイトレベルの粒度でページフォールトアドレスを観測していました。
しかし、素のEnclaveアプリケーションでは、オフライン解析でもEnclave上で動作させる必要がありますから、SGXの仕様により、得られるページフォールトアドレスはページ単位の粒度になります。
これまた前述の通り、オフライン解析の時点でページ単位の粒度でしかアドレスを得られないと、同じページ内のどの関数や変数が呼ばれたのかを非常に識別しにくくなるので、攻撃の手間や難易度は有意に上がるでしょう。
それでも、異常に気合の入った攻撃者から攻撃を通されてしまう可能性は否定しきれないので、論文中にも記されている通り、開発者はTCB(Enclave内)のコードを可能な限り小さくし、攻撃の餌食になりえる要素を減らす事を心がけた方が良いかも知れません。
まとめ
大分長い記事になりましたが、SGXに対するサイドチャネル攻撃でも特に強力な攻撃の1つであるControlled-Channel Attacksについて説明しました。
SGXを利用したプロダクトを開発する上では無視できない存在でもありますので、本記事が少しでもお役に立てばと思います。
参考文献
[1] "Controlled-Channel Attacks: Deterministic Side Channels for Untrusted Operating Systems", by Yuanzhong Xu, Weidong Cui and Marcus Peinado. 2015 IEEE Symposium on Security and Privacy, https://ieeexplore.ieee.org/document/7163052
[2] "Shielding applications from an untrusted cloud with Haven", by Andrew Baumann, Marcus Peinado, and Galen Hunt. 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf
[3] Intel SGX Explained", by Costan and Devadas. Cryptology ePrint Archive: Report 2016/086, https://eprint.iacr.org/2016/086.pdf
[4] Intel® SGX and Side-Channels, https://software.intel.com/content/www/us/en/develop/articles/intel-sgx-and-side-channels.html
[5] Fu, Yangchun et al. “Sgx-Lapd: Thwarting Controlled Side Channel Attacks via Enclave Verifiable Page Faults.” RAID (2017).
[6] Shih, Ming-Wei & Lee, Sangho & Kim, Taesoo & Peinado, Marcus. (2017). T-SGX: Eradicating Controlled-Channel Attacks Against Enclave Programs. 10.14722/ndss.2017.23193.
[7] Fahad Shaon, Murat Kantarcioglu, Zhiqiang Lin, and Latifur Khan. 2017. SGX-BigMatrix: A Practical Encrypted Data Analytic Framework With Trusted Processors. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS '17). Association for Computing Machinery, New York, NY, USA, 1211–1228. https://doi.org/10.1145/3133956.3134095
[8] Chia-Che Tsai, Donald E. Porter, and Mona Vij. 2017. Graphene-SGX: a practical library OS for unmodified applications on SGX. In Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC '17). USENIX Association, USA, 645–658.
[9] Intel(R) Software Guard Extensions (SGX) Protected Code Loader (PCL) for Linux* OS, https://github.com/intel/linux-sgx-pcl
[10] Erick Bauman, Huibo Wang, Mingwei Zhang, and Zhiqiang Lin. 2018. SGXElide: enabling enclave code secrecy via self-modification. In Proceedings of the 2018 International Symposium on Code Generation and Optimization (CGO 2018). Association for Computing Machinery, New York, NY, USA, 75–86. https://doi.org/10.1145/3168833
[11] BI-SGX: Bioinformatic Interpreter on SGX-based Secure Computing Cloud, https://bi-sgx.net/
[12] David Goltzsche, Colin Wulf, Divya Muthukumaran, Konrad Rieck, Peter Pietzuch, and Rüdiger Kapitza. 2017. TrustJS: Trusted Client-side Execution of JavaScript. In Proceedings of the 10th European Workshop on Systems Security (EuroSec'17). Association for Computing Machinery, New York, NY, USA, Article 7, 1–6. https://doi.org/10.1145/3065913.3065917