要約
FX のバックテストを Python でやりたい!
backtesting.py が使いやすそう!
でも、1つの為替ペアと1つの売買戦略:ストラテジーしかバックテストできない……。
多数の為替ペアとストラテジーを一度にバックテストしたい……。
自作のクラスを作ってみよう!
/* 初投稿なので色々ご容赦ください */
使用したモジュール
numpy
pandas
seaborn
matplotlib
talib
datetime
pytz
mplfinance
dask
tqdm
backtesting
read_hst
以上のモジュールを pip なり、conda などでインストールしておいてください。
ちなみに、read_hst の中身は下にあります。
ヒストリカルデータの準備
下記のURLを参考に準備してください。
自分は外付けHDDの I:\FX\Alpari-Demo に保存しております。
Alpari社からヒストリカルデータをダウンロードする方法
https://www.hungarianbest.com/mt4backtest/alpari_download/
出来ること
こんな感じに .hst を DataFrame にまとめて……

スプレッドを csv ファイルから読み込んで……
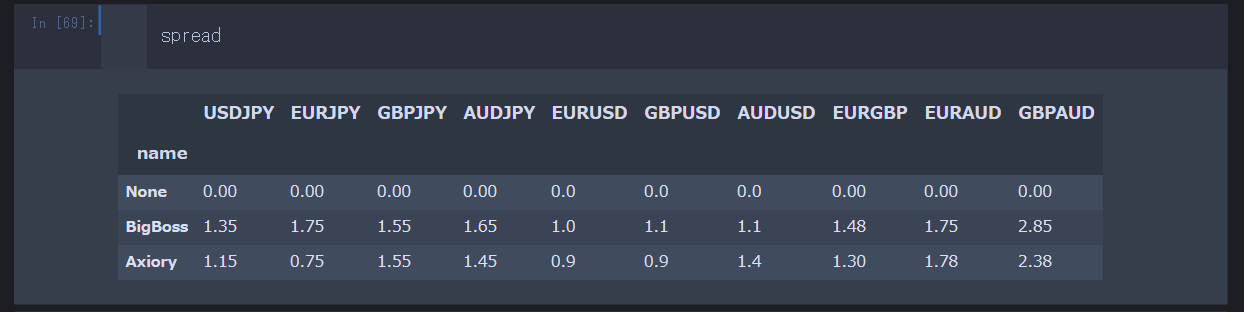
実行して……

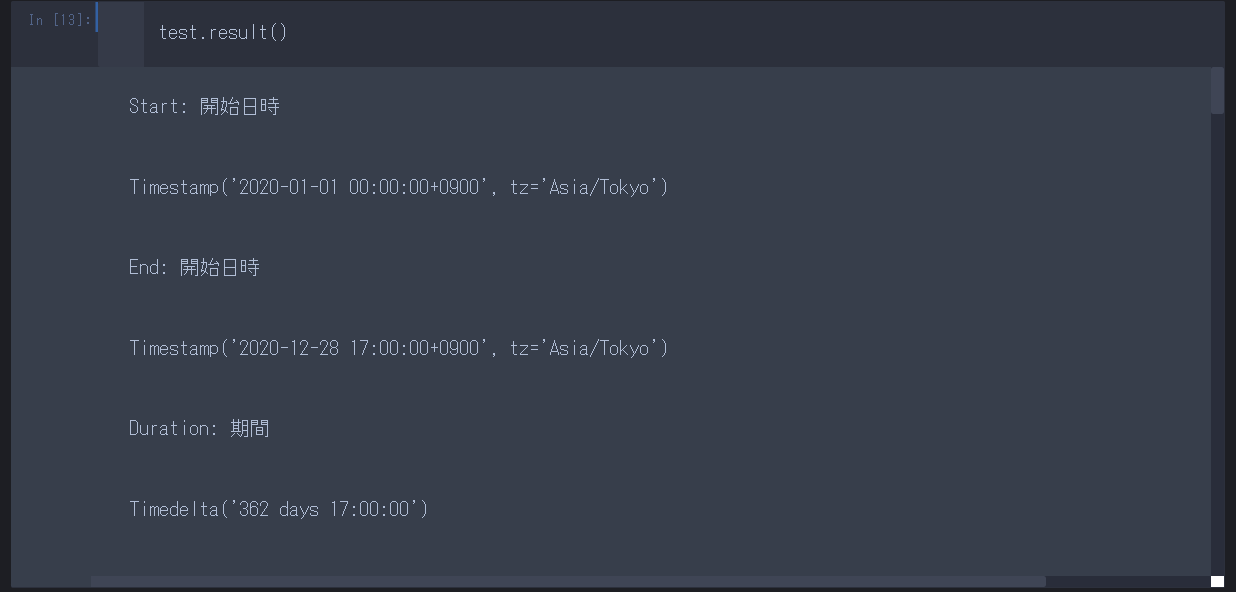
.result()で結果を確認して
.result_plot()で結果を視覚化して……
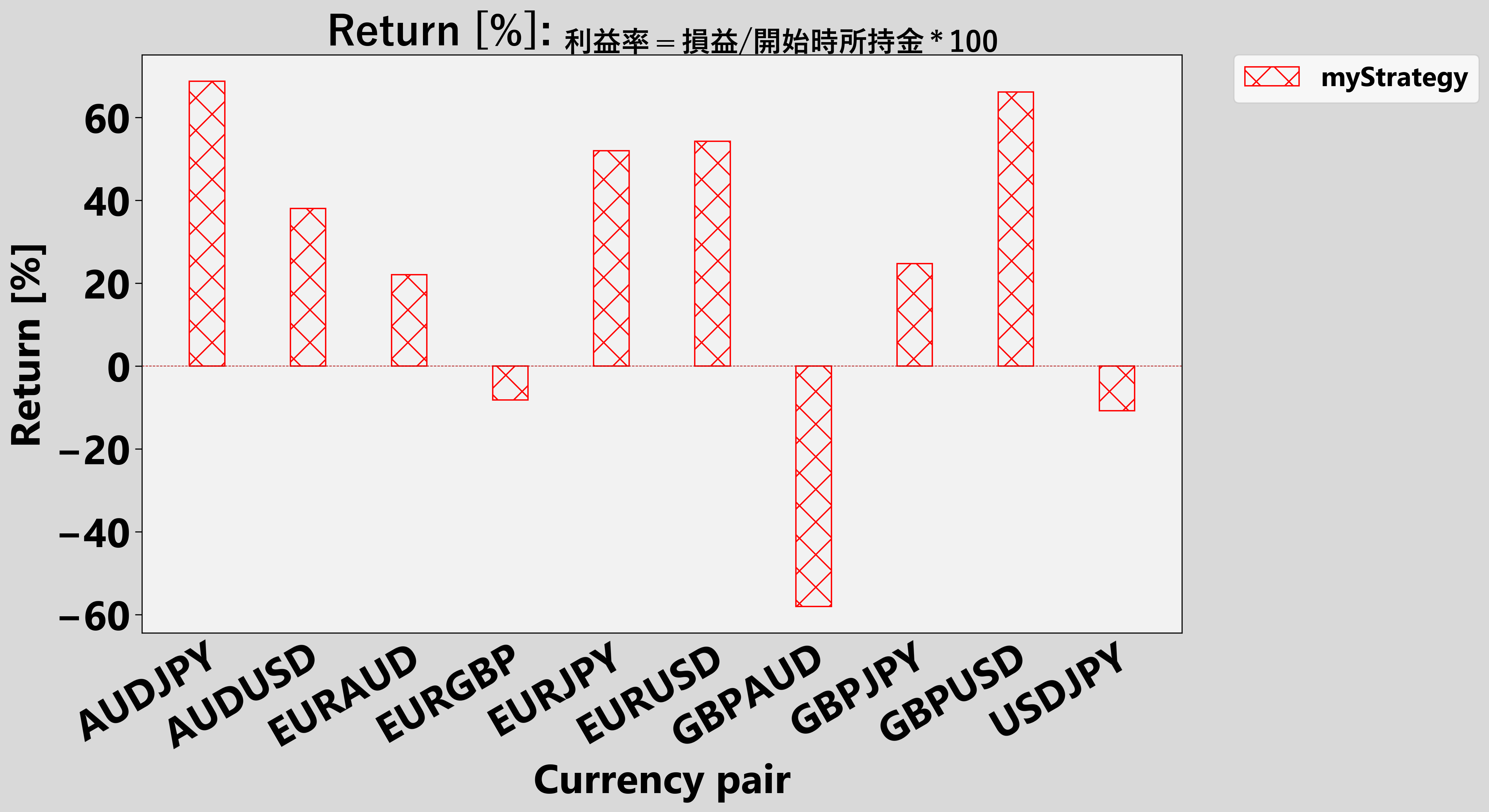
.all_bt_plot()で backtesting.py の .plot() を全回し……

やりたいことができたから満足(≧▽≦)
作成した.ipynbの中身
下記のURLにアップロードしたので、ほしい方はどうぞ(≧▽≦)
……というか、説明が面倒くさいので、各自ソースコードを確認して理解してください(´・ω・`)
まぁ、Python でバックテストしたいなんて変態は私くらいのものだと思いますが……。
https://ux.getuploader.com/hage_fx/download/50
read_hst.py の中身
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import zipfile
import pandas as pd
import os
import numpy as np
def zip2hst(fullpath):
"""Extract zip file.
Usage:
zip2hst('~/Data/USDJPY.zip')
> ~/Data/USDJPY.hst
zip2hst('USDJPY.zip')
> USDJPY.hst
args:
fullpath: Zip filename or path
return:
Extract filename or path
"""
if zipfile.is_zipfile(fullpath):
with zipfile.ZipFile(fullpath, 'r') as zf:
zf.extractall() # zip展開
ziplist = zf.namelist()
if not len(ziplist) == 1:
print('There are {} files in zipfile. Try again.'.format(len(ziplist)))
raise IOError
hstfile = ziplist[0]
return hstfile # フルパスかファイルネームだけを返す
else: # zipファイルでなければそのまま返す
return fullpath
def tickdata(filepath):
"""binary to pandas DataFrame using numpy.
参考: (´・ω・`;)ヒィィッ すいません - pythonでMT4のヒストリファイルを読み込む
http://fatbald.seesaa.net/article/447016624.html
(16) 【MT4】 ヒストリカルデータ(hstファイル)フォーマット
https://www.dogrow.net/fx/blog16/
"""
with open(filepath, 'rb') as f:
ver = np.frombuffer(f.read(148)[:4], 'i4')
if ver == 400:
dtype = [('time', 'u4'), ('open', 'f8'), ('low', 'f8'), \
('high', 'f8'), ('close', 'f8'), ('volume', 'f8')]
df = pd.DataFrame(np.frombuffer(f.read(), dtype=dtype))
df = df['time open high low close volume'.split()]
elif ver == 401:
dtype = [('time', 'u8'), ('open', 'f8'), ('high', 'f8'), ('low', 'f8'), \
('close', 'f8'), ('volume', 'i8'), ('spread','i4'), ('real_volume','i8')]
df = pd.DataFrame( np.frombuffer(f.read(), dtype=dtype) )
df = df.set_index(pd.to_datetime(df['time'], unit='s', utc=True)).drop('time', axis=1)
return df
def read_hst(fullpath):
"""Extracting hst file from zip file.
Usage:
import hst_extract as h
df = h.read_hst('~/Data/USDJPY.zip')
args:
fullpath: zip / hst file path
return:
pandas DataFrame
"""
hstfile = zip2hst(fullpath) # Extract zip in current directory.
print('Extracting {}...'.format(hstfile))
df = tickdata(hstfile) # Convert binary to pandas DataFrame.
# fullpathにhstファイル以外が与えられた場合、ファイルを消す
if not os.path.splitext(fullpath)[1] == '.hst':
os.remove(hstfile)
return df
def main():
"""Arg parser
usage: bin/read_hst.py [-h] [-c] [-p] filenames [filenames ...]
Convering historical file (.hst) to csv or pickle file.
positional arguments:
filenames
optional arguments:
-h, --help show this help message and exit
-c, --csv Convert to csv file
-p, --pickle Convert to pickle file
`stockplot/bin/read_hst.py -cp ~/Data/USDJPY.zip ~/Data/EURUSD.zip`
Extracting '~/Data/USDJPY.zip' and '~/Data/EURUSD.zip' then save to
* '~/Data/USDJPY.csv' and '~/Data/EURUSD.csv' as csv file.
* '~/Data/USDJPY.pkl' and '~/Data/EURUSD.pkl' as pickle file.
"""
description = 'Convering historical file (.hst) to csv or pickle file.'
parser = argparse.ArgumentParser(prog=__file__, description=description)
parser.add_argument('filenames', nargs='+') # 1個以上のファイルネーム
parser.add_argument('-c', '--csv', action='store_true', help='Convert to csv file')
parser.add_argument('-p', '--pickle', action='store_true', help='Convert to pickle file')
args = parser.parse_args()
filenames = args.filenames
csv = args.csv
pickle = args.pickle
if not filenames:
raise KeyError("Enter a valid filenames")
elif not (csv or pickle):
raise KeyError("Enter a valid output - filetype '-c'(--csv) or '-p'(--pickle).")
else:
for filename in filenames:
df = read_hst(filename) # convert historical to pandas Dataframe
basename = os.path.splitext(filename)[0]
if csv:
outfile = basename + '.csv'
df.to_csv(outfile)
yield outfile
if pickle:
outfile = basename + '.pkl'
df.to_pickle(outfile)
yield outfile
if __name__ == '__main__':
for convert_filename in main():
print(convert_filename)
参考URL
圧倒的感謝!(≧▽≦)
『Backtesting.py』でFXのバックテストをする!:Python
https://mmorley.hatenablog.com/entry/fx_backtesting01
(´・ω・`;)ヒィィッ すいません「バックテストを試してみました」
http://fatbald.seesaa.net/category/25188000-26.html
Module backtesting.backtesting
https://kernc.github.io/backtesting.py/doc/backtesting/backtesting.html#backtesting.backtesting.Backtest&gsc.tab=0
MT4ヒストリカルデータをpython上で扱えるようにしたりcsvに保存する
https://qiita.com/u1and0/items/6a690f6b0080b8efc2c7
Qiitaアカウント作成方法、記事の書き方、投稿手順
https://qiita.com/predora005/items/342b50859e2aeafc39b6