こんにちは、しなもんです。
とある研究で、東京のコロナの影響について調査する課題があった際、
テレビでみた 「AI判定でマスク着用率を調べる」 やつを思い出し
簡易的に作ってみました。
こういうやつです。
※今回作るAIは精度が低く、マスク着用を判定するだけしかできません。しょうがないね。
機械学習を始めて使う初心者が、同じような人のために成功例を紹介するだけです。
専門的な解説は一切ありません。ごめんね。
環境
Python 3.10.7
# ぱいそんです
numpy 1.23.5
# 画像処理をする際に座標計算とかに使います
icrawler 0.6.6
# スクレイピングに使います。
opencv-python 4.7.0.72
# 画像処理に使います。
keras 2.12.0
# AIモデル作成に使います。
matplotlib 3.7.1
# 学習の様子を可視化するために使います。
dlib 19.24.1
# 実際に顔を検出する際に使います。
$ pip install [パッケージ名]
でインストールできます。
警告
cmakeを導入しないとinstallできないパッケージがあります。
事前に導入しておいてください。
※筆者のバージョンはcmake 3.26.3でした。
スクレイピング
画像分析用に、マスクをしている人としていない人の画像を収集します。
from icrawler.builtin import BingImageCrawler
# 画像を収集するメソッド
# 引数は画像を保存するパスpath、検索ワードkeyword、収集する枚数num
def scraping(path, keyword, num):
bing_crawler=BingImageCrawler(
downloader_threads=4,
storage={'root_dir': path}
)
#検索ワードにkeywordを入れたときに得られる画像をnum枚収集
bing_crawler.crawl(
keyword=keyword,
max_num=num
)
print(f'{keyword}: scraping completed!')
gather_path='./gather/*.jpg'
mask_people_path='./mask_people/*.jpg'
keywords=['集合写真', 'マスク 東京']
num=1000
scraping('./image/gather/', keywords[0], num)
scraping('./image/mask_people/', keywords[1], num)
bingから、検索ワードにかかった画像を片っ端から持ってきます。
ほぼこちらのコードを使わせていただきました。
なぜ「集合写真」と「マスク 東京」なのかもこちらで解説されています。
参考にしたサイトでは取得する画像は300枚ですが...
後ほど使う顔抽出がかなり使えず、結果的に使える画像が少なくなってしまうため
多めに1000枚にしてあります。各自調整してください。
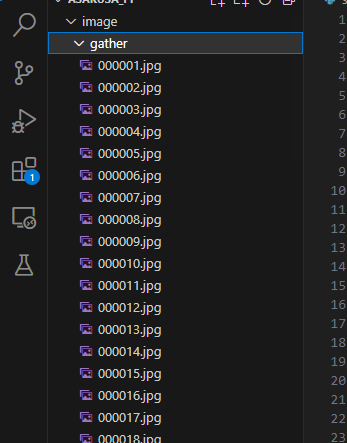
実行すると、このようにフォルダが作られて画像が収集されていきます。
顔のみを抽出する
ここが一番苦労しました。
#OpenCVのインポート
import cv2
import pathlib
import numpy as np
fid = 0
def get_face(fp):
global fid
#カスケード型分類器に使用する分類器のデータ(xmlファイル)を読み込み
HAAR_FILE = "HOGE:/haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(HAAR_FILE)
#画像ファイルの読み込み
image_picture = fp
img_np = np.fromfile(image_picture, dtype=np.uint8)
img = cv2.imdecode(img_np, cv2.IMREAD_COLOR)
#グレースケールに変換する
img_g = cv2.imread(image_picture,0)
#カスケード型分類器を使用して画像ファイルから顔部分を検出する
face = cascade.detectMultiScale(img_g)
#顔の座標を表示する
print(face)
#顔部分を切り取る
for x,y,w,h in face:
face_cut = img[y:y+h, x:x+w]
#保存する
out="image/mask_off"+"/"+str(fid)+".jpg"
print(out)
cv2.imwrite(out, face_cut)
fid+=1
input_dir = "image/gather"
input_list = list(pathlib.Path(input_dir).glob('**/*.jpg'))
for i in range(len(input_list)):
try:
get_face(str(input_list[i]))
except:
continue
詳しい解説はこちらのサイトにて詳しく書かれています...
xmlファイルについては、こちらをダウンロードし、そのファイルパスを書いてください。
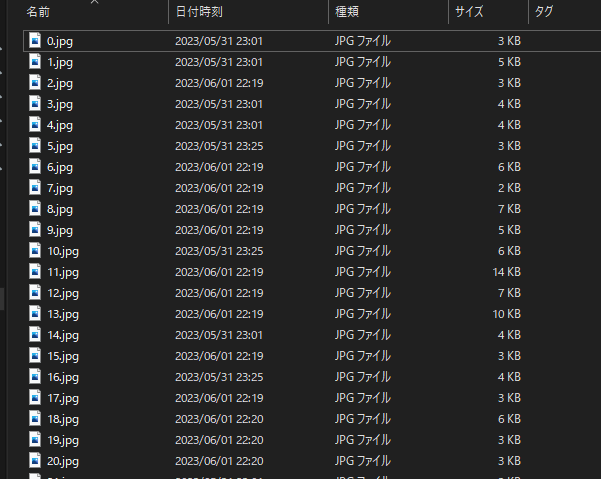
成功すると、顔の部分だけが切り抜かれた画像が連なっているはずですが、
かなりの確率で顔以外のものが検出されてしまいます。
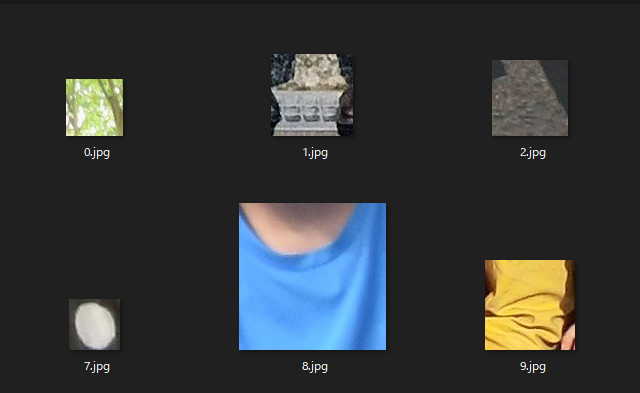
もっといい方法があるとは思うんですが、
私は初心者なので余計な画像は手作業で連番を完全に無視して消しました。
いい方法があれば教えてください...
学習させてモデルをつくる
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import cv2, glob
import numpy as np
import warnings
warnings.simplefilter('ignore')
print("modules imported!====================")
#画像形式の指定
in_shape=(50, 50, 3)
nb_classes=2
#CNNモデル構造の定義
#入力層:50x50x3ch
#畳み込み層1: 3x3のカーネルを32個使う
#畳み込み層2: 3x3のカーネルを32個使う
#プーリング層1: 2x2で区切ってその中の最大値を使う
model=Sequential()
model.add(Conv2D(32, kernel_size=(3,3), activation='relu', input_shape=in_shape))
model.add(Conv2D(32, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
#畳み込み層3: 3x3のカーネルを64個使う
#畳み込み層4: 3x3のカーネルを64個使う
#プーリング層2: 2x2で区切ってその中の最大値を使う
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
#全結合層: 512
#出力層: 2(マスクありorなしの2値)
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes, activation='softmax'))
#モデルのコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy']
)
print('model compiled!====================')
#画像データをNumpy形式に変換
x=[]
y=[]
def read_files(target_files, y_val):
files=glob.glob(target_files)
for fname in files:
# print(fname)
#画像の読み出し
img=cv2.imread(fname)
#画像サイズを50 x 50にリサイズ
img=cv2.resize(img, (50,50))
# print(img)
x.append(img)
y.append(np.array(y_val))
#ディレクトリ内の画像を集める
read_files("./image/mask_off/*.jpg", [1,0])
read_files("./image/mask_on/*.jpg", [0,1])
x_train, y_train=(np.array(x), np.array(y))
#テスト用画像をNumpy形式で得る
x,y=[[],[]]
read_files("./image/mask_off_test/*.jpg", [1,0])
read_files("./image/mask_on_test/*.jpg", [0,1])
x_test, y_test=(np.array(x), np.array(y))
#データの学習
hist=model.fit(
x_train,
y_train,
batch_size=100,
epochs=100,
validation_data=(x_test,y_test)
)
#データの評価
score=model.evaluate(x_test, y_test, verbose=1)
print("正解率 = ",score[1], 'loss = ',score[0])
#モデルの保存
model.save('mask_model.h5')
#学習の様子を可視化
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train','test'], loc='upper left')
plt.show()
こちらは完全にコピペさせてもらいました...
実行する前に、mask_off_testとmask_on_testフォルダを作り、
テスト用顔写真を数枚入れてください。
トレーニング用の画像フォルダとテスト用の画像フォルダに同じ画像が無いようにしてください。
テスト用写真は何枚でも構いません。学習のスコアを見ながらその都度調整してください。

実行すると学習が始まります。
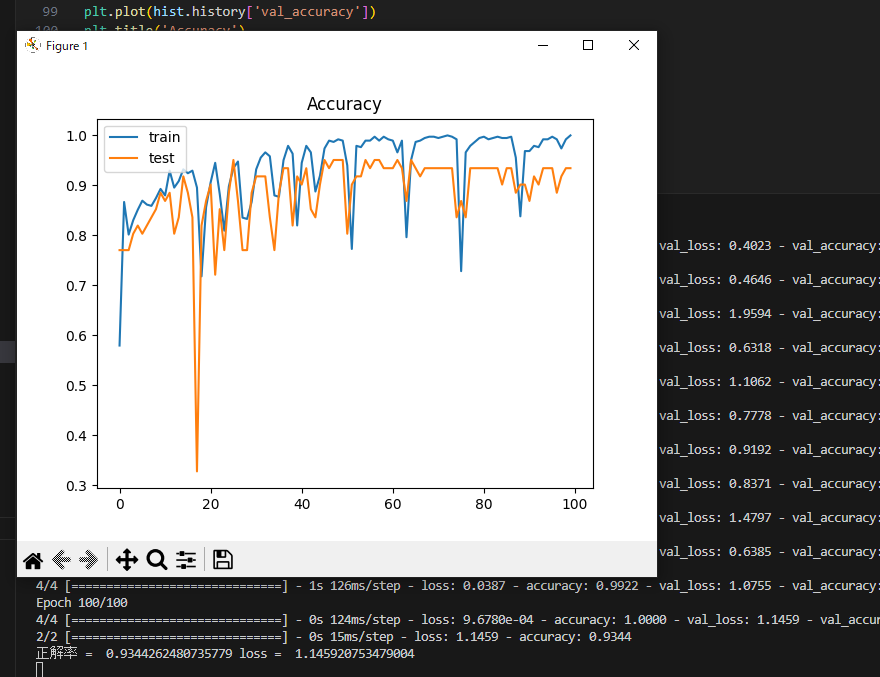
終わると、このようにウィンドウが出現します。
機械学習初心者すぎて何がどうなのかわからないですが...
グラフの青い線はトレーニング中の評価で、オレンジの線が実際に判別できるかテストした時の評価です。
ターミナルには正解率が93%、ロスが1.14とあります。
一見正解率が高く、よさそうですがロスが非常に大きく、学習できていないか過学習を抑えられていないことがわかります。初心者だからしょうがないね!
本来であればここに一番時間をかけるべき部分なのですが、
今回はあくまで簡易的な実装を目指しているので、以下の数値で妥協します。
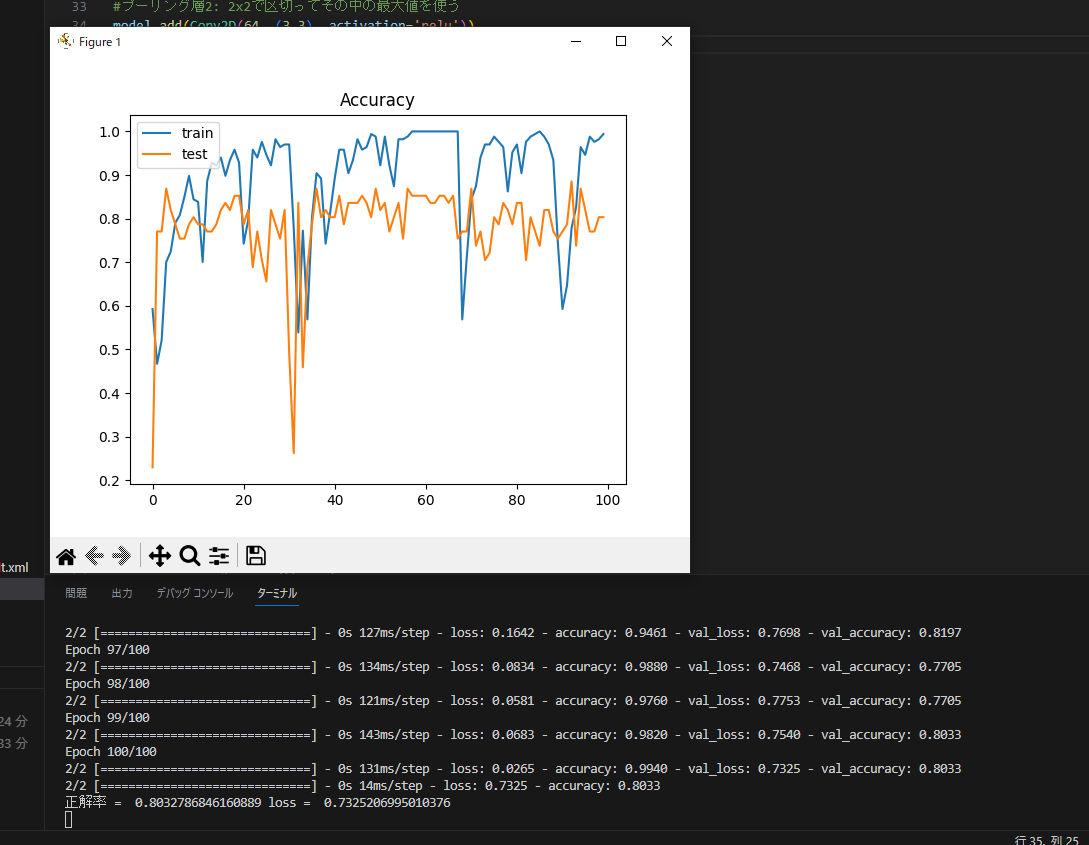
正解率が大きく下がりましたが、ロスも半分になったのでヨシ!(分かってない)
具体的には、
・マスクを着用している画像と着用していない画像の量を同程度にする。
・学習データを増やすためにスクレイピング量を増やす。
・学習に向いていないデータを削除する。
・テスト用画像の量を調整する。
でロスを下げることができました...
正しい方法なのかは知りません!
モデルを使用する
それでは完成したAIモデルを使ってみます。
Webカメラでリアルタイムで検出することもできますが、
今回は事前に用意した動画から検出することにします。
from keras.models import load_model
import cv2, dlib, pprint, os
import numpy as np
# 結果ラベル
res_labels = ['NO MASK!', 'OK']
save_dir = "./live"
# 保存した学習モデルを読み込む
model = load_model('mask_model.h5')
# dlibを始める
detector = dlib.get_frontal_face_detector()
# 動画ファイルのパス
video_path = "video.mp4"
# 動画ファイルを開く
capture = cv2.VideoCapture(video_path)
# 動画のフレームサイズを取得
frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 動画の保存用のビデオライターを作成
if save_dir and not os.path.exists(save_dir):
os.makedirs(save_dir)
output_path = os.path.join(save_dir, "output.mp4")
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
out = cv2.VideoWriter(output_path, fourcc, 30.0, (frame_width, frame_height))
while True:
# 動画からフレームを読み込む
ok, frame = capture.read()
if not ok:
break
# 画面を縮小表示する
frame = cv2.resize(frame, (1920, 1080))
try:
# 顔検出
dets = detector(frame, 1)
for k, d in enumerate(dets):
pprint.pprint(d)
x1 = int(d.left())
y1 = int(d.top())
x2 = int(d.right())
y2 = int(d.bottom())
# 顔部分を切り取る
im = frame[y1:y2, x1:x2]
im = cv2.resize(im, (50, 50))
im = im.reshape(-1, 50, 50, 3)
# 予測
res = model.predict([im])[0]
v = res.argmax()
print(res_labels[v])
# 枠を描画, マスクない時(v=0)は赤で強調する
color = (0, 0, 255) if v == 0 else (0, 255, 0)
border = 5 if v == 0 else 2
cv2.rectangle(frame, (x1, y1), (x2, y2), color, thickness=border)
# テキストを描画
cv2.putText(frame, res_labels[v], (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, thickness=1)
except:
pass
#結果を保存
out.write(frame)
#ウィンドウに画像を出力
cv2.imshow('Mask Live Check', frame)
#ESC or Enterキーでループ脱出
k=cv2.waitKey(1)
if k==13 or k==27:
break
#カメラを開放
capture.release()
out.release()
#ウィンドウを破棄
cv2.destroyAllWindows()
参考にしたサイトはこちらです。
※動画を保存するような処理が入っていますが、動きませんでした...why...
「video.mp4」をpythonファイルと同じディレクトリに置いて実行すると...

肖像権保護のためぼかしていますが、
正答率80%にしてはかなり判別することができています。
まとめ
機械学習初心者でも、テレビでよく見るアレを作ることができました!!
業務用じゃないので精度は悪いし着用率を求めることはできないですが、
データ収集から活用までできるので、機械学習をやってみよう!って人におすすめです。
それでは...
参考