この記事は韓国語から翻訳したものです。不十分な部分があれば、いつでもフィードバックをいただければありがたいです! (オリジナル記事, 同じく私が作成しました。)
Grafanaを利用して室内/外の空気質ダッシュボードを構築した過程を説明したい。
ダッシュボードプラットフォーム選択 - Grafana
GrafanaはGrafana Labsが管理しているオープンソースのダッシュボード及び可視化プラットフォームである。様々なデータソースから一目で見やすいダッシュボードを作成することができ、きっかけとなった放送に出たIT開発者のパッシブハウスダッシュボードもGrafanaで作られていたので選択することになりました。
時系列データを保存する - InfluxDB
まず、収集したいデータは、時間別の室内/外空気質データです。このようなデータを保存するためには、時系列データベースが効果的である。InfluxDBは、時系列データを保存・管理するためのオープンソースデータベースである。
最初は、Grafanaとの接続が簡単でよく使われているPrometheusを使おうとしたが、インスタンスやノードを拡張する理由がない、
- インスタンスやノードを拡張する理由がない。
- データ収集がPush方式ではなくPull方式
- データ収集形式がJSONではなくOpenMetrics形式である。
などの理由でPrometheusの代わりにInfluxDBを選択しました。InfluxDBはPush方式でデータを収集し、データを簡単にPushすることができるREST APIを提供する。このREST APIを利用した様々な言語のクライアントライブラリも提供しており、データ収集スクリプトを直接作成するのに便利でした。
インフラの構築
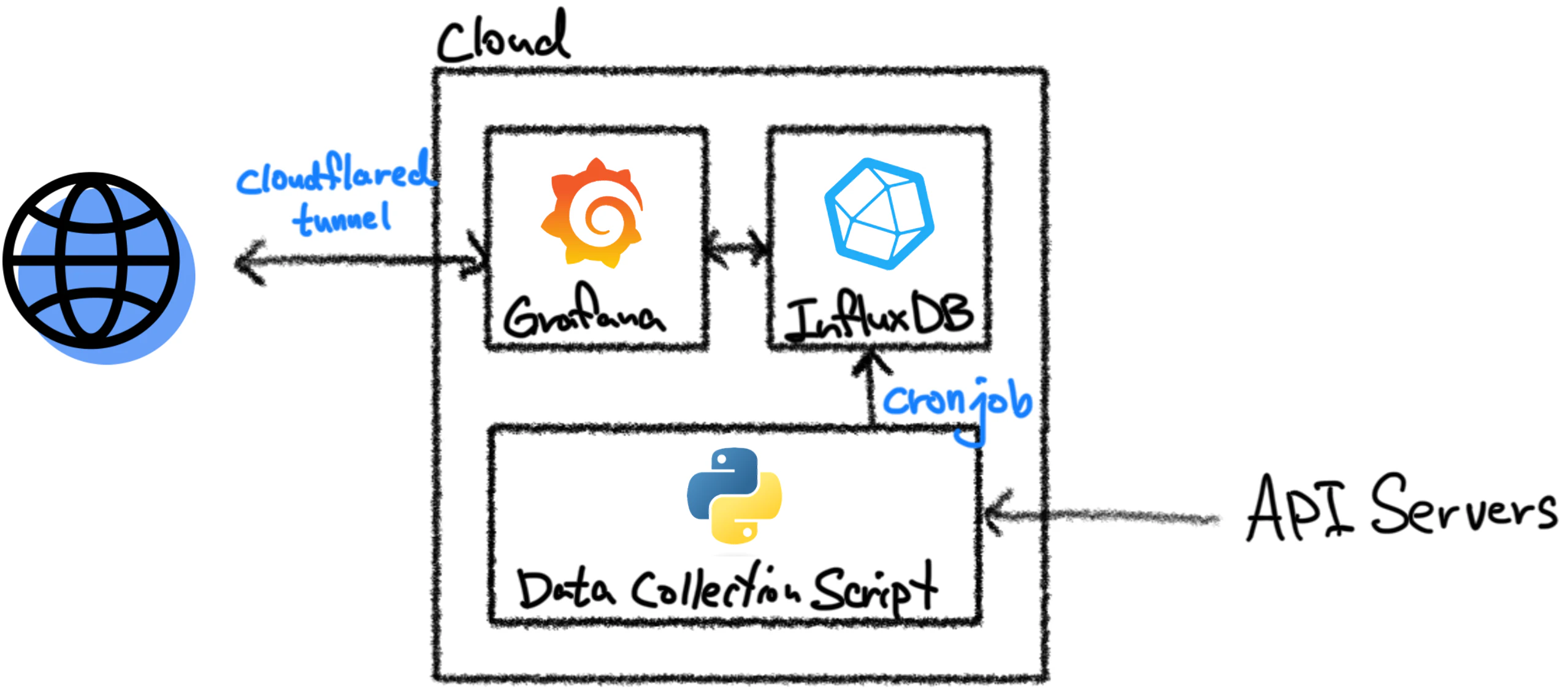
インフラは以下のように構築することにした。現在住んでいる家にサーバーとして24時間稼働できるデバイスがないので、GrafanaとInfluxDBを個人クラウドにインストールすることにしました。
まず、Grafanaの公式ドキュメントで案内された通りにGrafanaをインストールします。
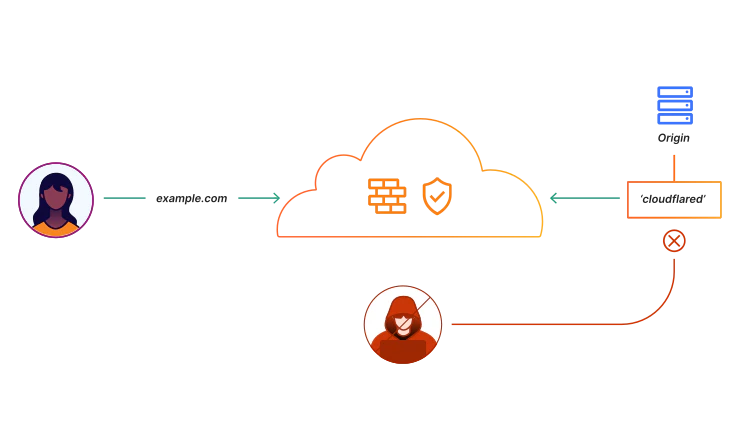
「Cloudflare Tunnel原理」
インストールとConfigファイルを修正した後、Grafanaを実行すると、基本的に3000番ポートでサービスされます。ウェブサーバーと証明書管理インフラを別途に構築するのは面倒なので、ポートを別途に変更しない予定です。代わりに、Cloudflare Tunnelを利用します。Tunnel Daemon(cloudflared)をoriginサーバーにインストールしておけば、すべてのトラフィックをCloudflareを通過させることができます。これにより、OriginサーバーのIPを隠し、ウェブサーバーを別途に構築する必要もなく、SSL証明書を別途に管理する必要もない。似たような製品にはngrokというものがある。
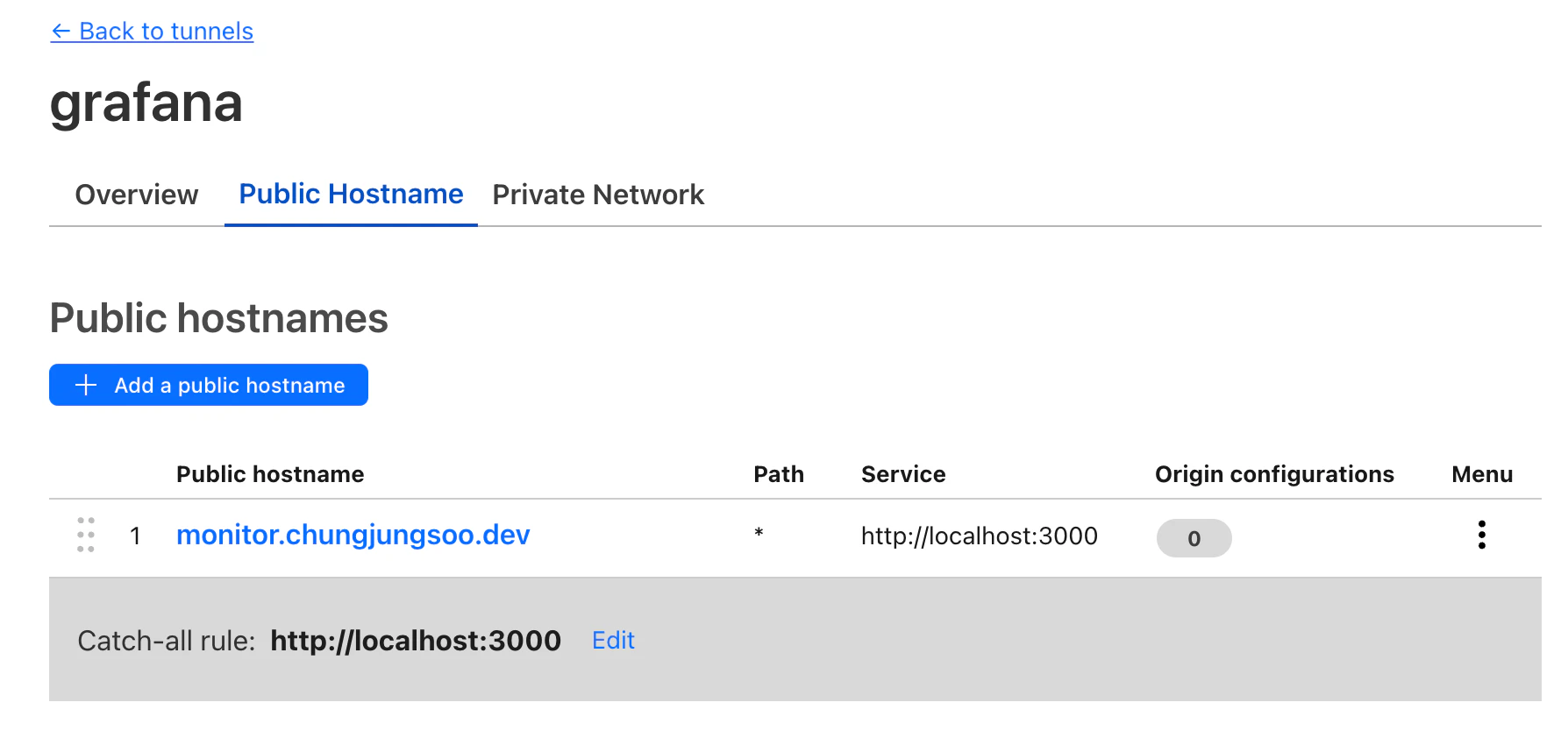
サーバーにcloudflaredをインストールし、Zero Trust Consoleでトンネルを生成してcloudflaredと接続した後、Public Hostnameで外部から接続するURLアドレスを入力する。cloudflaredはGrafanaと同じサーバーにあり、Grafanaは現在3000番ポートで提供されているので、そのhostnameをlocalhost:3000で接続すれば終わりです。
トンネル設定を完了してhostnameで接続すると、Grafanaのログインページが正常に表示されることが確認できます。
InfluxDBも公式ドキュメントに書いてある通りにインストールをします。インストールが完了したら、InfluxDB CLIを追加でインストールします。
まず、InfluxDBは一般的なRDBと少し違うので、InfluxDBのData Elementsについて説明します。
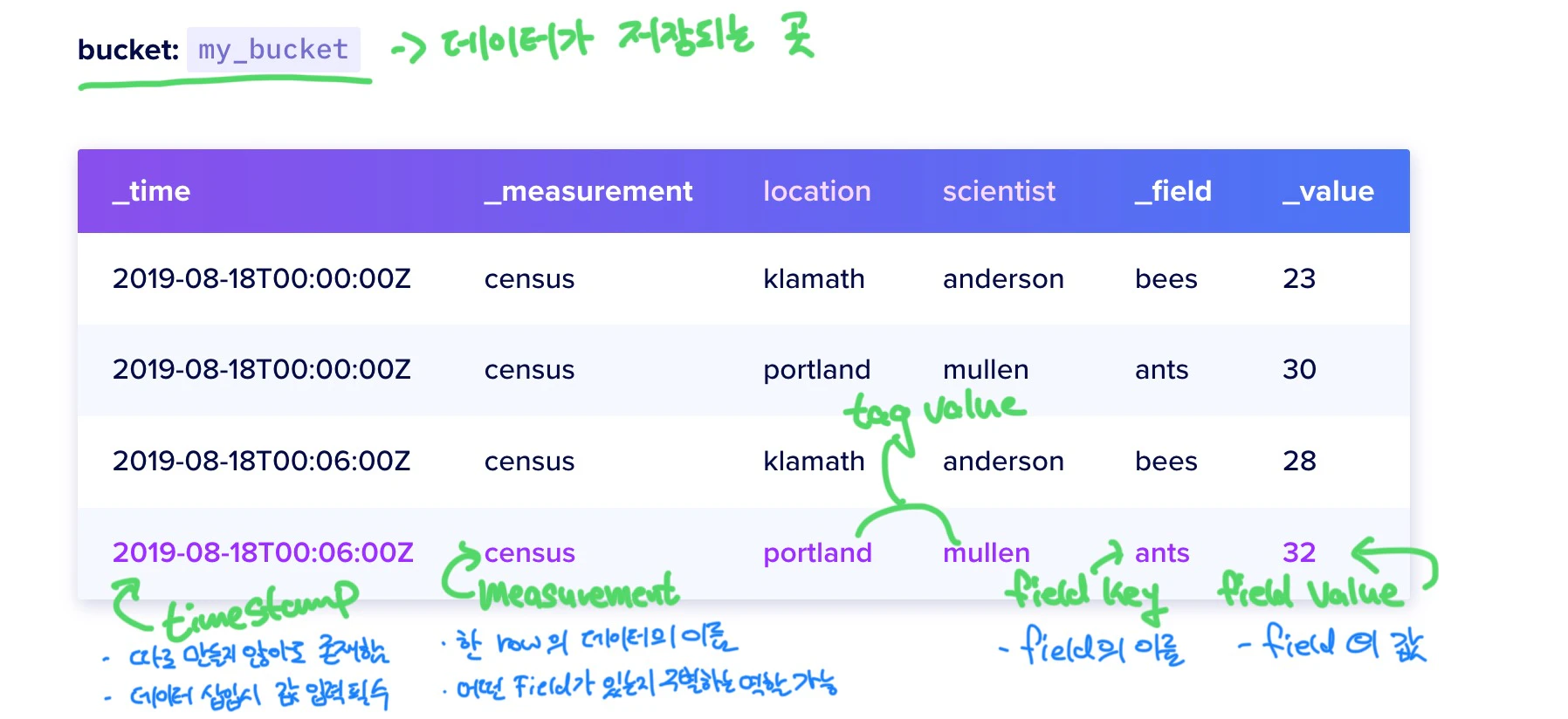
大きくBucket, Measurement, Field, Pointだけ説明します。
- Bucket: InfluxDBでデータを保存する空間です。
- Measurement: 保存されたデータの名前と考えると分かりやすいです。この名前でそのデータにどんなFieldがあるか確認することができます。
- Field: InfluxDBデータのKey-ValueペアをFieldと言う。したがって、Field key, Field valueに分かれる。
- Point: Measurement、Field、Timestampを含む単一レコードデータである。ex)
2019-08-18T00:00:00Z census ants 30 portland mullen.
インフラ構築段階ではBucketのみを生成し、データ収集段階でBucketにデータを保存する予定である。屋内測定データと屋外測定データを別々に保存するようにBucketを二つ作成しました。データを自動的に削除してくれるRetention Periodは1年に設定しました。1年前のデータは特に必要ないようで、運用するクラウドの容量が大きくないので、適当に保存する必要があります。

データ収集
データ収集は簡単に説明すると、Pythonスクリプトを作成してこれをCrontabで定期的に実行するようにしました。スクリプトにはデータを取ってきてこれを正しくDBに保存する段階まで実行します。
室内空気の質
室内空気質は、現在使っているAirGradientから直接データを取得したいと思います。AirGradientは親切にAPIを提供しているので、これを利用してデータを取り込むことができます。AirGradientのダッシュボードにアクセスしてAPI Keyを発行された後、私が所有しているセンサーのデータを取得するAPIを呼び出すと次のように値を返します。
{
"locationId": "<location_id_in_int>",
"locationName": "Home monitor",
"pm01": 3,
"pm02": 6,
"pm10": 6,
"pm003Count": 440,
"atmp": 26.04,
"rhum": 38,
"rco2": 848,
"tvoc": 140.51997,
"wifi": -31,
"timestamp": "2024-03-13T16:47:52.000Z",
"ledMode": "co2",
"ledCo2Threshold1": 1000,
"ledCo2Threshold2": 2000,
"ledCo2ThresholdEnd": 4000,
"serialno": "<serial_number_in_string>",
"firmwareVersion": null,
"tvocIndex": 146,
"noxIndex": 2
}
InfluxDBに記録したい値は全てAPIが返してくれています。この値をスクリプトが帰るサーバーから取得してInfluxDBに保存すればよいです。PythonにはInfluxDB Clientライブラリがあるので、これを利用してスクリプトを作成します。
import requests
import time
from influxdb_client import InfluxDBClient, Point
from datetime import datetime
def get_indoor_data() -> dict:
indoor_api_url = 'https://api.airgradient.com/public/api/v1/locations/<location id>/measures/current?token=<api token>'
try:
response = requests.get(indoor_api_url)
json_data = response.json()
except Exception as e:
print(e)
return {}
return json_data
def main():
indoor_data = get_indoor_data()
current_timestamp = int(time.time())
if not indoor_data:
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(current_timestamp))}] - No data written")
return
if indoor_data:
indoor_point = Point('indoor') \
.field('temp', float(indoor_data['atmp'])) \
.field('humidity', int(indoor_data['rhum'])) \
.field('pm01', int(indoor_data['pm01'])) \
.field('pm25', int(indoor_data['pm02'])) \
.field('pm10', int(indoor_data['pm10'])) \
.field('co2', int(indoor_data['rco2'])) \
.field('tvoc', int(indoor_data['tvocIndex'])) \
.field('nox', int(indoor_data['noxIndex'])) \
.time(current_timestamp * 10 ** 9, write_precision='ns')
with InfluxDBClient.from_config_file("config.toml") as client:
with client.write_api() as writer:
if indoor_data:
writer.write(bucket="indoor", record=[indoor_point])
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(current_timestamp))}] - Indoor data written")
if __name__ == '__main__':
main()
Point を作成し、indoorという measurementに各センサーの数値をFieldとしてKey-Valueペアで保存し、それをInfluxDBに記録する。config.toml ファイルにはInfluxDBの接続情報が含まれている。config.tomlにはInfluxDB接続のためのToken値が必要なので、Influx CLIでこれを生成しましょう。(参考1, 参考2)
屋外大気質
屋外の空気質は大気質関連APIを使って取得する必要があります。しかし、現在公開されているAPIの中で希望する規格のAPIがないので、直接他のAPIを呼び出して希望する規格で返すようにWrappingするAPIを別途製作しました。室内空気質と同じようにコードを作成します。API乱用防止のため、URL及びパラメータは公開しなかった。
import requests
import time
from influxdb_client import InfluxDBClient, Point
def main():
outdoor_data = get_outdoor_data() # Fetch Custom Made AirQuality API
current_timestamp = time.time_ns()
if not outdoor_data:
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(current_timestamp / 10 ** 9))}] - No data written")
return
if outdoor_data:
outdoor_point = Point('outdoor') \
.field('temp', int(outdoor_data['temp'])) \
.field('humidity', int(outdoor_data['humidity'])) \
.field('pm25', float(outdoor_data['pm25'])) \
.field('pm10', float(outdoor_data['pm10'])) \
.field('atm', float(outdoor_data['atm'])) \
.time(current_timestamp, write_precision='ns')
with InfluxDBClient.from_config_file("config.toml") as client:
with client.write_api() as writer:
if outdoor_data:
writer.write(bucket="outdoor", record=[outdoor_point])
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(current_timestamp / 10 ** 9))}] - Outdoor data written")
if __name__ == '__main__':
main()
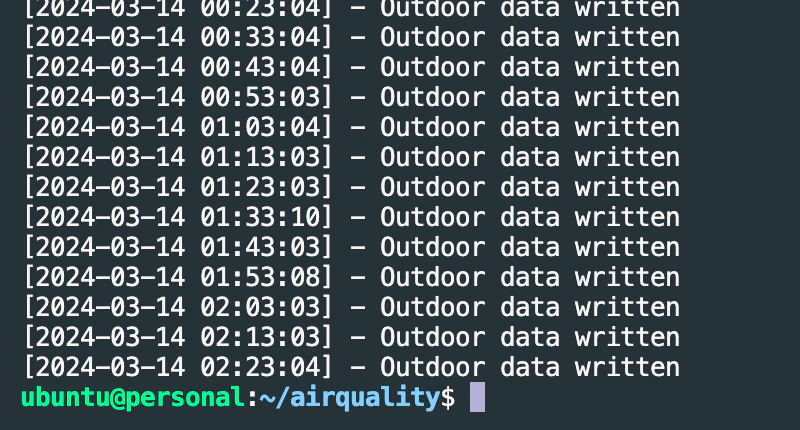
スクリプトの作成が終わったら、両方のスクリプトをCrontabに登録して定期的に実行されるようにします。Indoorは2分に1回、Outdoorは10分に1回測定するように設定しました。Crontabログを確認して正常に実行されてるか確認しましょう。
ダッシュボード生成
スクリプトが正常に実行されてるなら、DBにデータも正しく記録されてるはずです。これをダッシュボードを作りながら確認してみましょう。
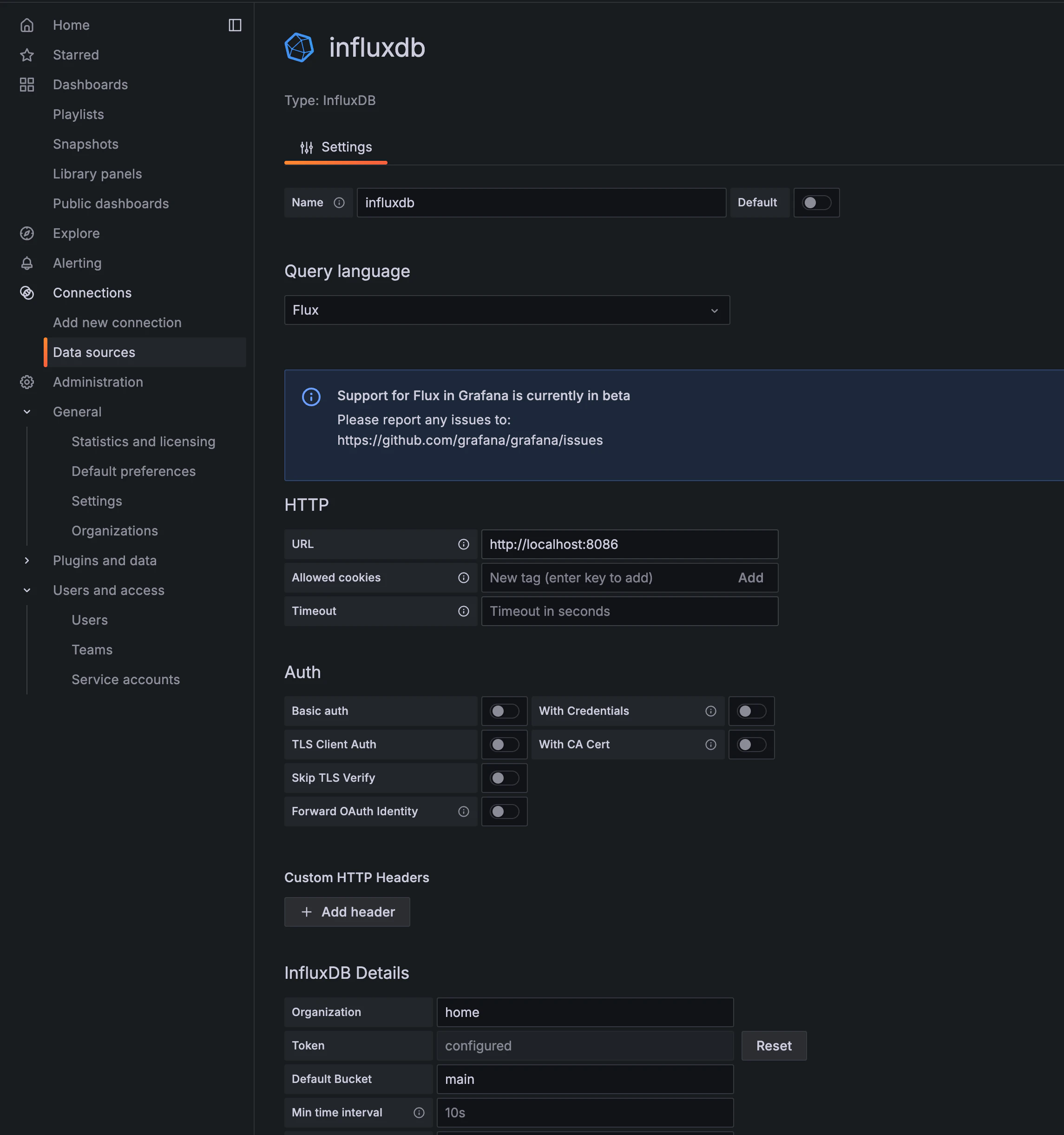
まず、ダッシュボードに綺麗にデータを表示するためにはデータソースを接続する必要があります。Grafanaメニューからデータソースを追加するを押して、InfluxDBを選択します。GrafanaとInfluxDBは同じサーバーにあるので、アドレスは http://localhost:8086 です。
DetailsセクションのTokenに先ほどのconfig.tomlで設定したTokenの値を入力するか、CLIで新しく生成してその値を入力します。下部に Save & Test ボタンがあるので、押して接続がうまくできるか確認してみましょう。
データソースを正常に追加したら、次はダッシュボードを作ってみましょう。左メニューにダッシュボードへ入って新しいダッシュボードを作成し、右上の追加ボタンを押してVisualizationを追加します。
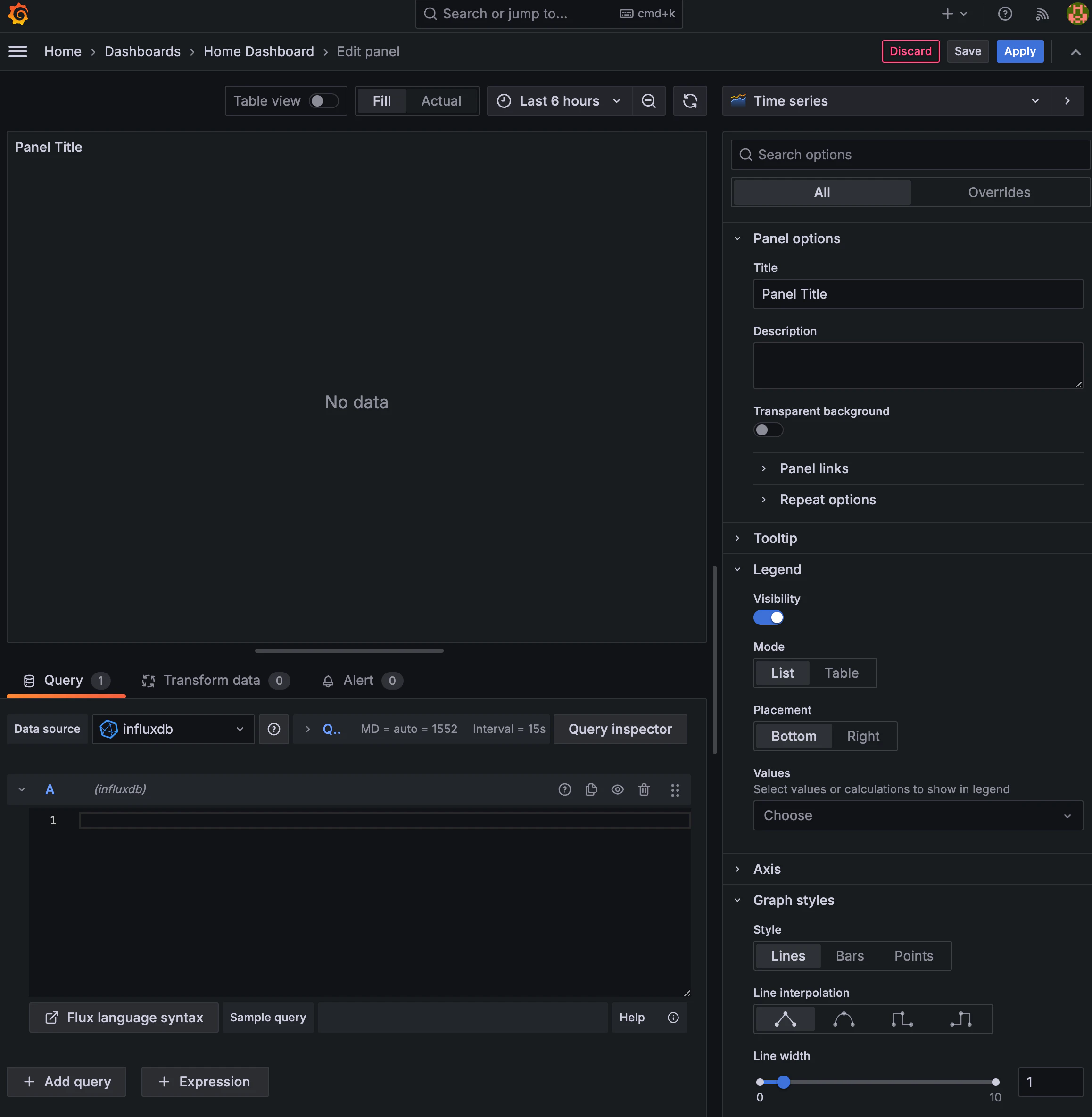
Visualizationを選択すると上のように表示されますが、ここで視覚的に表示したいデータをクエリして、そのクエリで取得したデータが視覚化される方式です。Visualizationの種類を見ると、右上側で選択することができますが、デフォルトはTime Seriesです。まず、一つのFieldに対する値をクエリしてみましょう。 例としてIndoor bucketに保存した温度値をクエリしてみましょう。
from(bucket: "indoor")
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "indoor" and
r._field == "temp"
)
このクエリは indoor bucketから temp fieldを可視化を要求した開始時刻から終了時刻まで取得するクエリです。開始時間と終了時間の設定は右上にある時間タブを使うことができます。このクエリを実行すると、下記のように可視化されたデータを見ることができます。
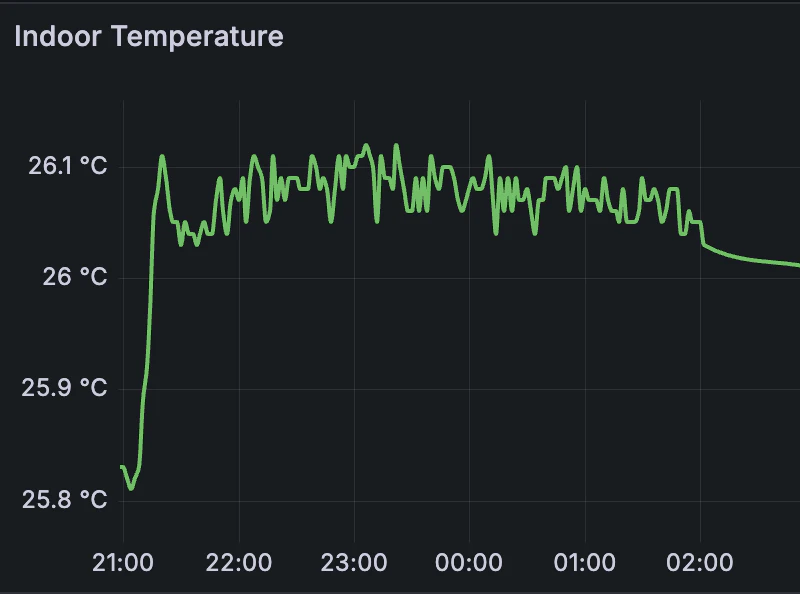
上のような方法で好みに合わせてダッシュボードをカスタマイズしてみましょう。ダッシュボードにVisualizationを追加して、サイズと配置も適切に調整して保存することを忘れないでください!
結果
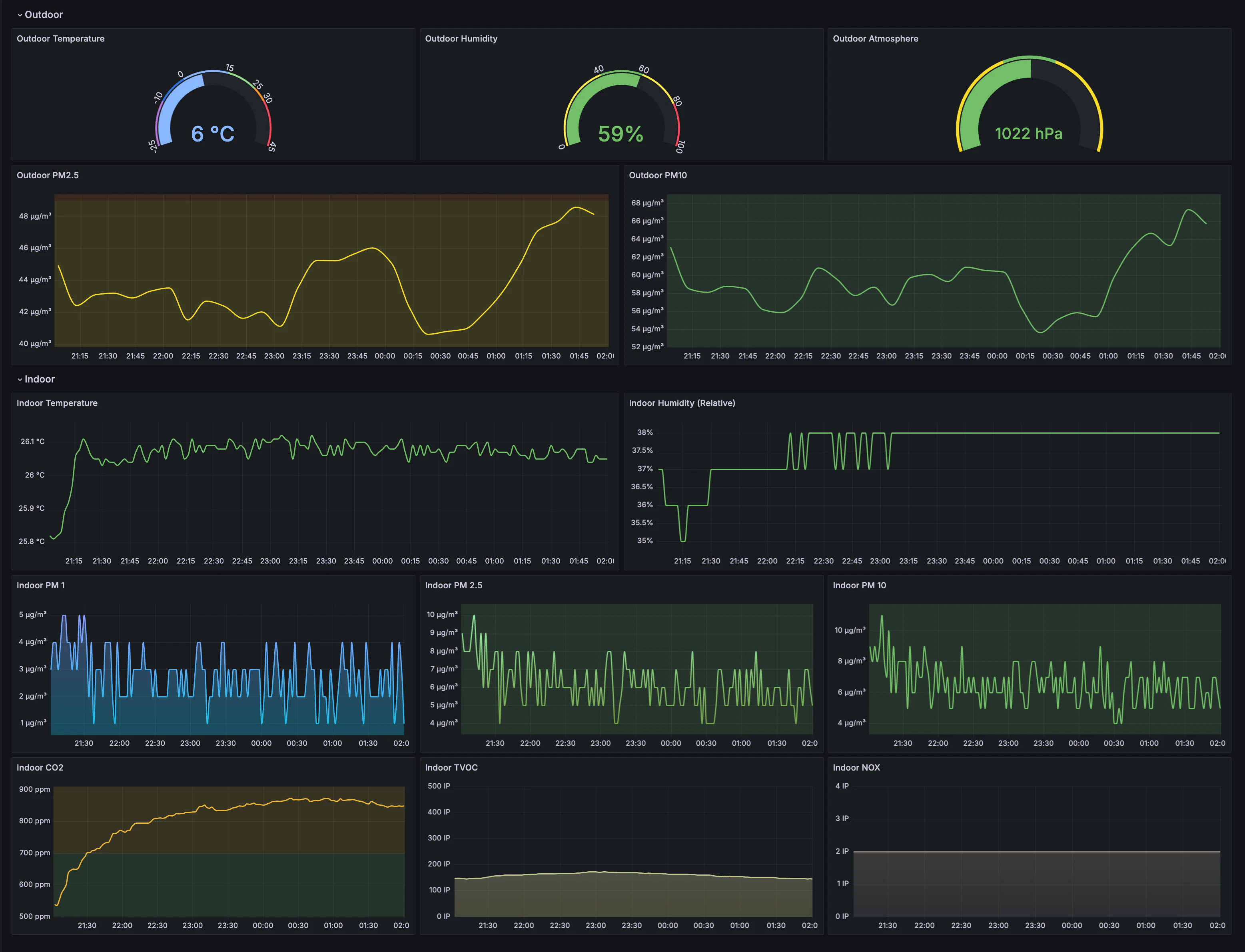
このように作られたダッシュボードはモバイルUIもサポートしているので、どこでも室内/外の空気質情報を一目で確認することができます。EBSで放映されたものと同じように作ってみましたが、Grafanaを扱うのは初めてなので、まだ未熟な部分が多かったです。ダッシュボードを今後、より視覚的に見やすく改善していきたいです。
今後、空気質に関するデータがどんどん蓄積されていくので、これを利用してより多くのインサイトを得たいと思います。 将来的には、これを利用して両親がいる実家にも導入し、Home Assistantを利用して室内環境を自動的に制御するシステムを構築してみたいと思います。