
図書館を管理していると想像してください。ただし、整然とした本の棚ではなく、あちこちに散乱したバラバラのページだけがある状況です。必要な情報を見つけるのは悪夢のようで、他の人と共有するのはさらに困難です。これは、データの海に溺れている多くの企業にとっての現実です。Snowflake、Redshift、BigQueryのような従来のデータウェアハウスは秩序を提供しますが、しばしば高額なコストやベンダーロックインという問題を伴います。そこで登場するのが、データ界の新星であるApache Icebergです。しかし、それは単なるコスト削減だけなのでしょうか、それとももっと多くの可能性があるのでしょうか?
では、Icebergがこれほど魅力的な理由は何でしょうか?主なポイントは以下の通りです:
- データの整理整頓: 混乱したデータレイクを構造化され、クエリ可能なリソースに変換します。
- ベンダーの自由: 単一のベンダーによる価格設定や制限に縛られません。
- エンジンの柔軟性: 各データ作業に最適なツールを使用して効率性とコスト効果を最大化します。
- 将来性のあるアーキテクチャ: 技術の進化に対応し、苦痛を伴う移行を避けられます。
歴史的な分析の分野では、Snowflake、Redshift、BigQuery、最近ではClickHouseのようなプラットフォームが長い間主流でした。しかし、データエンジニアリングの世界では、Apache Icebergが注目を集めています。ユーザーはデータを直接Icebergに送信してレイクハウスを構築し、データの管理とクエリの方法を再定義しています。
Icebergの核となる機能には、ニーズに応じてデータ構造を簡単に適応できるスキーマ進化、過去のデータバージョンを振り返るタイムトラベル、多様なツールとの互換性などがあります。これらの機能は大規模データセットを管理する上でのゲームチェンジャーですが、技術的な利点を超えた意味を持っています。Icebergの採用は、コスト、ベンダー独立性、将来の拡張性について戦略的に考える必要があります。そのため、Icebergの台頭は単なる技術の進歩ではなく、企業がデータアーキテクチャをよりオープンで柔軟、かつ将来性のあるものにする方法を再考する動きを反映しています。
コスト削減を超えて: Apache Icebergの真の力
これらの課題にもかかわらず、Icebergの採用が増え続けている理由は、単なる技術的な観点だけでなく、その変革的なビジネスへの影響にもあります。
1. データレイクの整理整頓: IcebergがS3に秩序をもたらす方法
Icebergなしでは、S3上の生データファイルから特定の情報を探し出すのは干し草の中から針を探すようなものです。AWS Athenaのようなツールはファイルをクエリできますが、データの構造(スキーマ)を管理し、アクセス権を制御するには手動で設定が必要です。Icebergは、S3バケットを整然としたクエリ可能なデータセットに変換し、適切なアクセス制御を提供します。これにより、どのモダンなクエリエンジンとも互換性を持たせることができます。IcebergをS3にレイヤーとして追加することで、企業は広がるデータレイクを統一的に管理し、カオスを管理可能な状態に変えることができます。
2. ベンダーロックインの打破: 独立性の力
ベンダーロックインは、Snowflakeのようなプロプライエタリシステムを使用する組織にとって重大な懸念事項です。歴史的には、データがSnowflakeに保存されている場合、Snowflakeが料金を引き上げるときに交渉の余地がほとんどありませんでした。他のプラットフォームへのデータ移行には多大な努力を要するため、Snowflakeは強力な立場を持っていました。Icebergは、この依存関係から解放される方法を提供します。
Icebergは広範な互換性を提供することでベンダーロックインを排除します。Icebergフォーマットに保存されたデータは、多数のエンジンでクエリ可能であり、組織はベンダーを自由に切り替え、料金をより効果的に交渉できます。例えば、IcebergをAmazon EMRやDatabricksのようなクラウドネイティブの計算エンジンと組み合わせることで、データ要件の進化に応じて柔軟性を確保できます。この柔軟性により、企業はコスト効率を高めるだけでなく、将来のデータ戦略を柔軟に保ち、技術の変化に迅速に対応できるようになります。
3. 最適なツールの選択: マルチエンジン互換性
異なるデータ処理ツール(エンジン)は、それぞれ異なるタスクで優れた性能を発揮します。Icebergはマルチエンジンの使用を可能にし、タスクに最適なツールを選択できます。例えば、IcebergをSnowflakeと組み合わせて複雑な分析クエリ(OLAP)を処理し、DuckDBで軽量分析を行うことで、コストを削減しながら柔軟性を維持できます。
さらに、Trino(フェデレーションクエリ用)、RisingWave(ストリーム処理用)、LanceDB(ベクター検索用)、PuppyGraph(グラフ分析用)など、他のクエリエンジンもIcebergエコシステムを拡張しています。これらのエンジンは特定のユースケースに対して低レイテンシのクエリ機能を提供します。このマルチエンジンアプローチにより、企業はインタラクティブなダッシュボードからリアルタイムストリーミング分析まで、ロックインなしで高度な分析を探求することが可能になります。
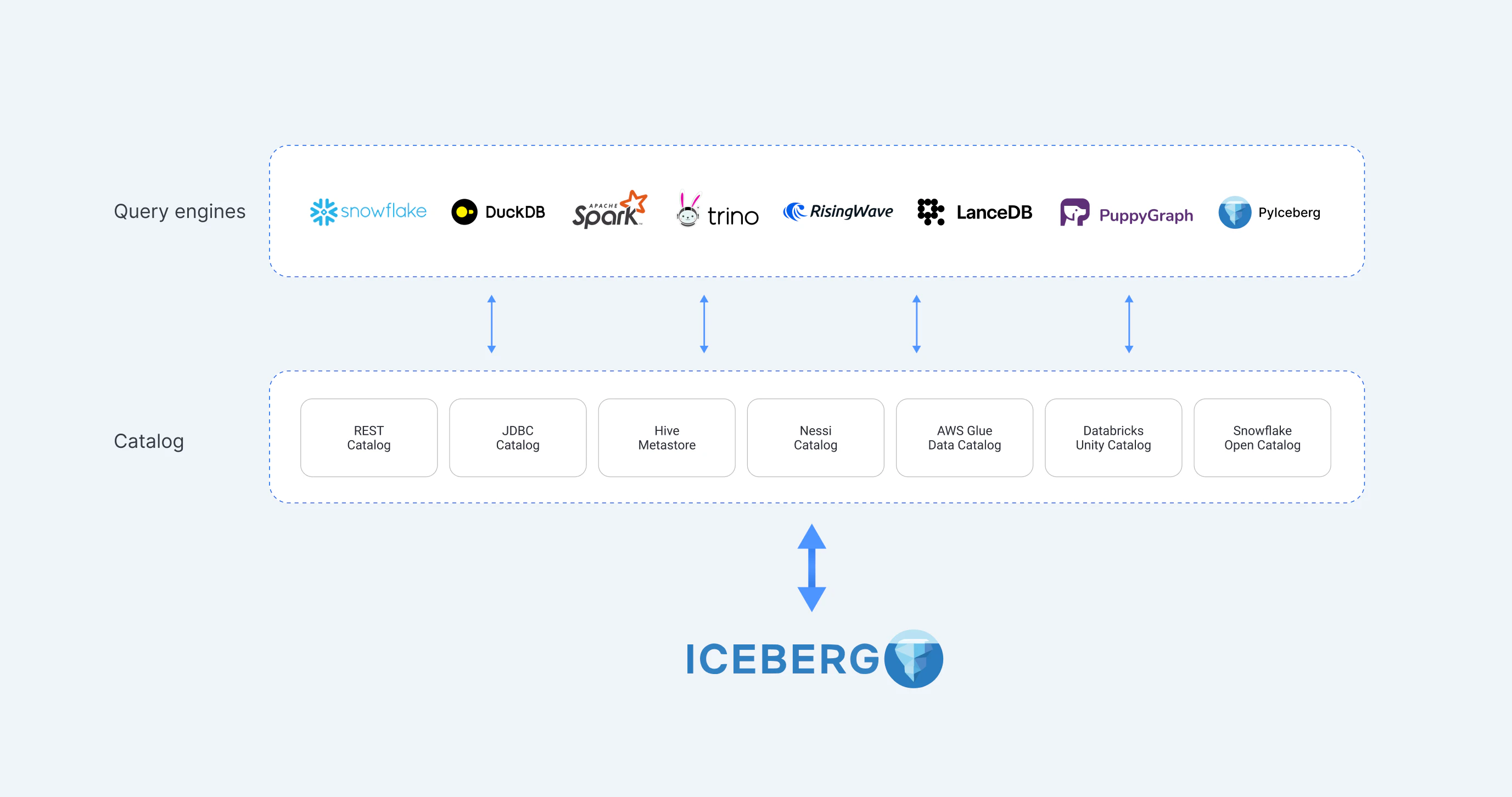
4. あらゆる言語に対応: マルチランゲージサポート
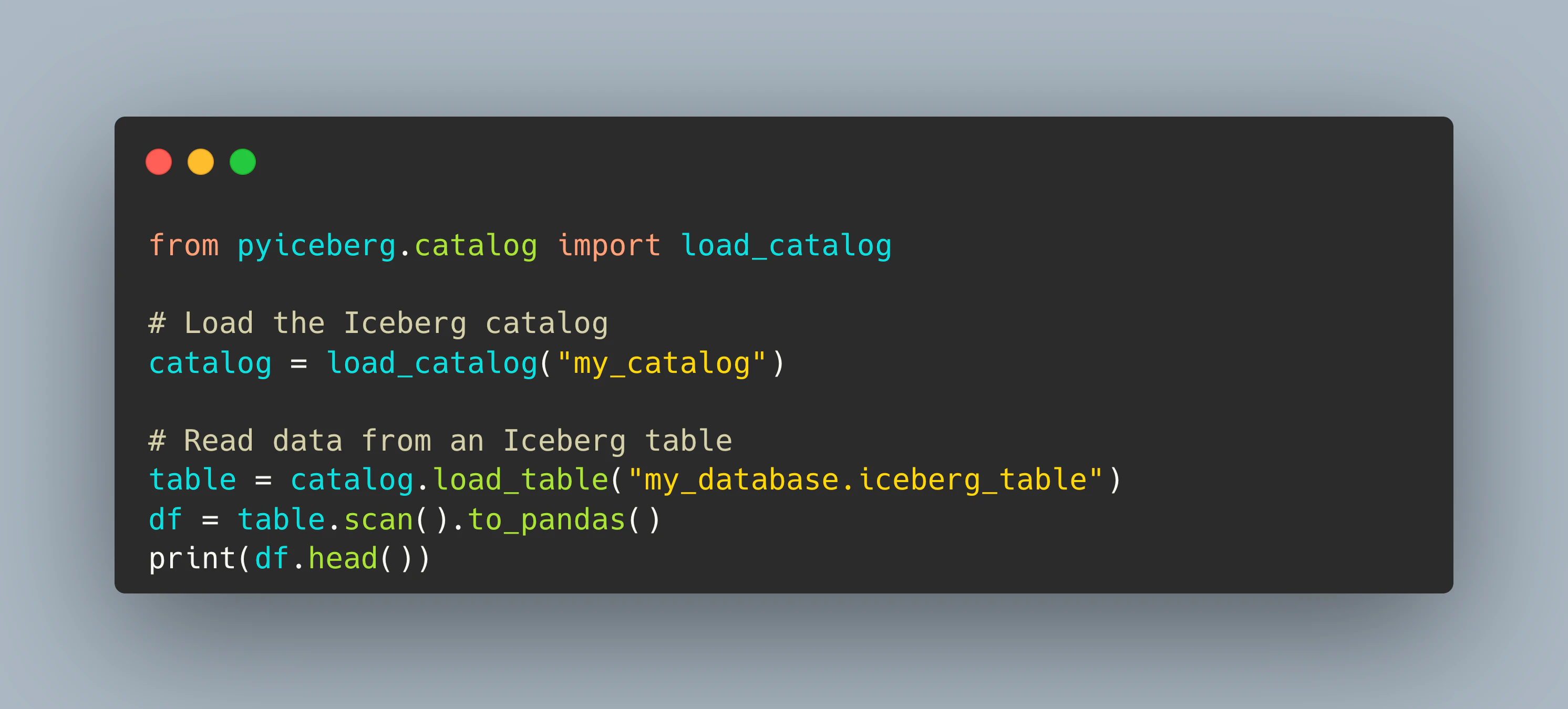
Icebergはさまざまなプログラミング言語をサポートしており、クロスファンクショナルなチームにとって魅力的です。データエンジニアはSQLを使用し、データサイエンティストはPythonを活用できます。ML/AIのワークロードでは、IcebergのPythonベースツールとの互換性がデータアクセスをシームレスにし、モデルのトレーニングや推論において革新的な利便性を提供します。さらに、PyIcebergのようなフレームワークにより、Python環境での高度なデータ操作がさらに簡単になります。また、JavaやScalaなどの言語も利用可能で、Icebergはバックエンドシステムから高度なデータサイエンスパイプラインまで、多様なエンタープライズワークフローにシームレスに適合します。
レイクハウスのビジョン: Icebergで構築するウェアハウスの未来
Apache Icebergのようなオープンテーブルフォーマットは、データ管理の未来を象徴しています。その柔軟性とエコシステムの互換性は、プロプライエタリシステムに代わる魅力的な選択肢を提供し、モダンデータアーキテクチャの新しい基準を確立します。
2025年までに、すべてのデータベースがIcebergフォーマットでデータをネイティブに保存するデータエンジンへと進化するでしょう。なぜこれが起こるのでしょうか?RisingWave Labsでは、このビジョンを完全に受け入れています。RisingWaveはクラウドネイティブなストリーミングデータベースであり、Icebergテーブルを完全にサポートすることで、Icebergフォーマットでデータをシームレスに保存およびクエリできるようにしました。
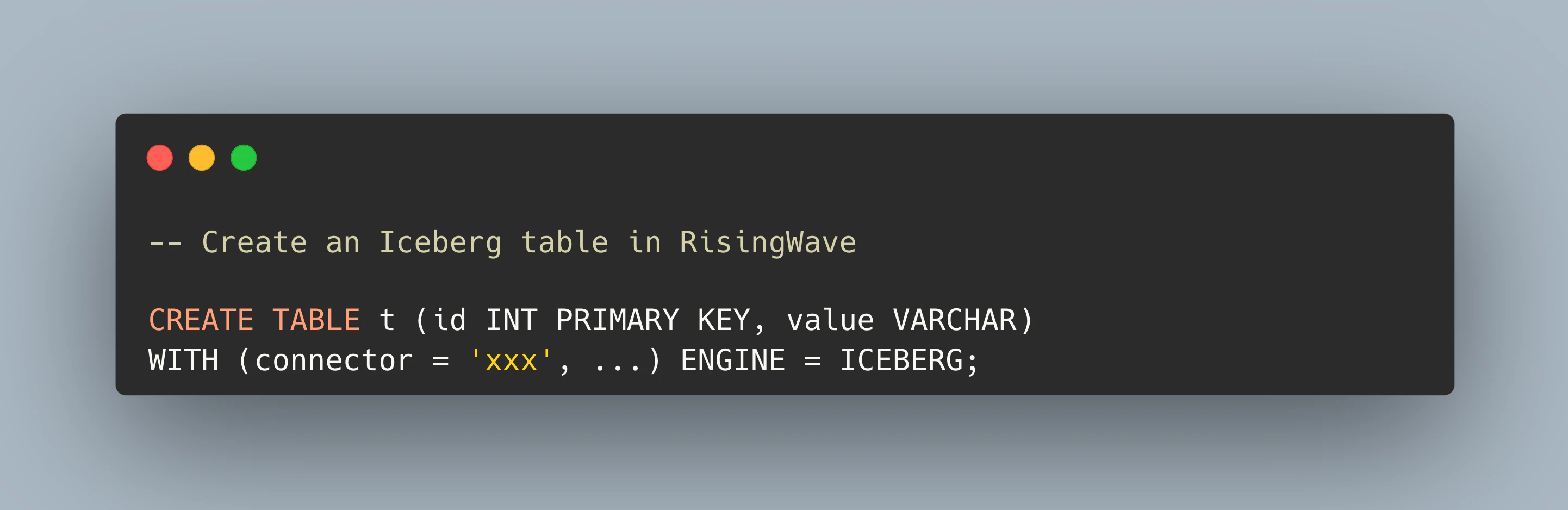
この統合により、RisingWaveユーザーはIcebergエコシステムと簡単に接続でき、そのオープンで将来性のある設計を活用できます。ユーザーは、あらゆるエンジンやプログラミング言語を使用してデータとやり取りできる柔軟性を持ち、拡大を続ける分析環境全体で互換性を確保します。これは、真にオープンで相互運用可能なデータエコシステムへの重要な一歩です。
最後に
Apache Icebergは単なる新技術ではなく、データの管理と活用方法におけるパラダイムシフトです。オープンアクセス、柔軟性、ベンダー独立性を採用することで、Icebergは企業が真に将来性のあるデータアーキテクチャを構築できるようにします。Databricks、Snowflake、AWSなどの業界大手によるサポートにより、その地位はモダンデータエンジニアリングの中核としてさらに固まっています。データの世界が進化し続ける中で、Icebergはよりオープンで柔軟、かつ強力な未来への道を提供します。準備はできていますか?