データ管理がデータレイクに移行する流れは、確かに変革的なものです。データレイクは、膨大な量の生データ、非構造化データ、および半構造化データを管理する上で基本的な役割を果たします。歴史データを単一の信頼できる情報源として保存する能力は、組織がデータの一貫性、整合性、および信頼性を異なる部門やチーム間で維持するために不可欠です。
Apache Spark、Trino、またはClickHouseのような計算エンジンを統合することで、データレイクは「データレイクハウス」に変わります。これにより、大量のデータを保存するだけでなく、効率的に処理することが可能になります。

Apache Kafkaは、広く使用されているイベントストリーミングプラットフォームであり、多くのデータ駆動型企業の技術スタックに組み込まれています。Kafkaは、現代のデータスタックにおいて「最近のデータのリポジトリ」として長い間認識されてきました。多くのデータエンジニアは、通常7日から1ヶ月の期間、新しく取り込まれたデータを保存するためにKafkaを使用し、その後、このデータをデータレイクに転送します。
「イベントストリーミングプラットフォームは一時的なデータ用であり、データレイクは歴史データ用である」という認識があります。しかし、Kafkaが新しい形態のデータレイクに進化しつつあることを示す証拠が増えています。
この記事では、この進化がなぜ起こっているのかを説明します。
データレイクとは?
データレイクは、あらゆる規模の構造化データおよび非構造化データを保存できる集中型リポジトリです。データウェアハウスとは異なり、データレイクはデータをそのままの形式(通常はフラットな構造)で保持します。
データレイクを管理するためのフレームワークとして、Apache Iceberg、Apache Hudi、Delta Lakeの3つがよく知られています。これらのシステムはそれぞれ独自の特徴と利点を持っていますが、いずれも大規模な歴史データの保存と管理に広く採用されています。その設計と機能により、膨大な量のデータを扱いやすくするとともに、Apache Sparkなどの一般的な計算エンジンとの統合が容易になるため、多様なビッグデータアプリケーションおよび分析ユースケースに適しています。
Kafka にはデータレイクのすべての特性がある
Kafkaは、データレイクとしての特性を本質的に備えています。Kafkaが新しいデータレイクとして利用できるかを議論する前に、まずKafkaがデータレイクになるために必要なすべての特性を持っているかを確認しましょう。
Kafkaは確かにそのすべての重要な特性を備えています。
-
データベースのようなACID特性。 Martin KleppmannがKafka Summit San Francisco 2018で行った基調講演「Is Kafka a Database?」で強調されているように、Kafkaは原子性、一貫性、分離性、耐久性(ACID)といったデータベースのような特性を含むよう進化しました。多くの人々は最近のデータを保存するためだけにKafkaを使用していますが、Kafkaは実際には現代のデータレイクと同様に無限の保存期間を持っています。この機能により、Kafkaは膨大な量のデータを保存するための魅力的な選択肢となります。
-
コスト効率の良い階層型ストレージ。 多くの人々がKafkaを長期データの保存に使用することを躊躇する主な理由は、Kafkaが高コストであるという認識です。かつては確かにそうでした。従来のKafkaの設計では、データをAWS EC2のような計算インスタンスに保存する必要があり、AWS S3などのオブジェクトストレージよりもはるかに高価でした。しかし、これは変わりつつあります。Confluentが構築した最新のKafkaバージョンや、Redpanda、Apache Pulsarのような他の人気のあるイベントストリーミングプラットフォームは、コールドデータを安価なオブジェクトストアに保存する階層型ストレージを採用しています。これにより、コストを削減し、長期データの永続化が実現可能になりました。この新しい設計により、Kafkaはスケーラビリティを心配することなく、膨大なデータを低コストで保存できるようになりました。
-
さまざまなタイプのデータの保存。 Kafkaは、リレーショナルデータのような構造化データから、JSONやAvroのような半構造化データ、さらには(稀ではありますが)テキストドキュメントや画像、動画のような非構造化データまで、幅広いデータタイプを扱うことができます。この多様性は、今日の多様なデータ環境において非常に重要であり、Kafkaを組織全体のデータを一元的に保存するリポジトリとして利用することができます。これにより、複数のストレージソリューションを管理する際の複雑さやオーバーヘッドが削減されます。
-
リアルタイムデータの保存。 多くの人がデータレイクを歴史データの保存に使用していますが、現代のデータレイクは進化を遂げ、リアルタイム性をますます備えるようになっています。これは自然な流れであり、現代のアプリケーションやデバイスは膨大なデータを継続的に生成しています。そのため、データレイクはリアルタイムデータを取り込むための最適化を進めています。一方、イベントストリーミングプラットフォームとしてのKafkaは、リアルタイムデータの取り込みを本質的にサポートしています。そのアーキテクチャは、高速で移動するリアルタイムデータとゆっくり移動する歴史データの両方を保存するのに適しています。
Kafka は新しいデータレイクとして適しているのか?
Kafkaはデータレイクのすべての特性を備えています。しかし、Kafkaは実際に本番環境で新しいデータレイクとして利用可能なのでしょうか?この視点を支持するいくつかの説得力のある理由があります。
-
データソースとしての役割。 多くの組織は、データをデータウェアハウスや他のストレージシステムに転送する前に、まずKafkaに直接取り込みます。もしKafkaがデータを永久保存するデータレイクとして使用されれば、異なるシステム間でデータを移動させる必要がなくなります。データ移動を排除することで、コスト削減だけでなく、データの不整合や損失のリスクも最小化されます。
-
単一の信頼できる情報源(Single Source of Truth)。 Kafkaをデータレイクとして活用すれば、組織全体の単一の信頼できる情報源として機能します。データの不整合は、データを変換する際に発生します。しかし、データソースをデータの行き先として使用すれば、不整合問題に直面することはありません。このアプローチは、システムの数を減らし、それらを同期および統合する必要性を低減することで、データアーキテクチャを大幅に簡素化します。その結果、インフラストラクチャは管理が容易になり、エラーが発生しにくくなり、コスト効率も向上します。
-
豊富なエコシステム。 Kafkaは、さまざまなデータソースからデータを取り込むための非常に豊富で堅牢なエコシステムを備えています。また、ほとんどの計算エンジンがKafkaからデータを簡単に消費できます。この柔軟性により、Kafkaを既存のシステムやワークフローに統合するプロセスが大幅に簡素化されます。さらに、Kafkaの機能はデータの取り込みと保存だけにとどまりません。Kafka Streamsを通じて軽量なストリーム処理機能をネイティブに提供します。これにより、データが取り込まれると同時にリアルタイムで処理できるため、リアルタイム分析や意思決定が必要な組織にとって大きな利点となります。
Kafka は既存のデータレイク管理フレームワークを置き換えるのか?
結論はシンプルで、少なくとも直近では「いいえ」です。Kafkaがリアルタイムデータと歴史データの両方を保存できる能力を持っているにもかかわらず、Apache Iceberg、Apache Hudi、Delta Lakeのような広く使用されているデータレイク管理フレームワークを完全に取って代わることはありません。
これらのデータレイク管理フレームワークは、大規模なデータストレージを最適化しつつ、ACID特性を維持するよう設計されています。一方で、Kafkaはデータ型認識による圧縮、クエリプッシュダウンのサポート、更新および削除のサポートといった重要な機能をまだ統合していません。このため、歴史データを管理する用途では、依然としてこれらのフレームワークの方が優れています。
将来的に採用される可能性があるアーキテクチャの1つは、Kafkaを読み書きの統一されたインターフェースとして活用し、ホットデータとウォームデータをKafkaに保存する方法です。その後、コールドデータを透明な形で、ユーザーに意識させることなくIceberg/Hudi/Deltaに移行するという仕組みです。このアプローチでは、Kafkaと既存のデータレイクの利点を組み合わせることができます。ユーザーはKafka APIを直接呼び出すことで引き続きデータを読み書きでき、基盤構造やデータ形式の複雑さは抽象化されるため、システムとのインタラクションが簡素化されます。
Kafka を使ったストリーミングデータレイクハウスの構築
データレイクハウスは、データレイクとデータウェアハウスのベストな機能を融合させた強力なデータプラットフォームです。これにより、構造化データおよび非構造化データの膨大な量を扱うことができ、高度な分析や機械学習をサポートします。Kafkaが新しいデータレイクへと進化することで、リアルタイムデータと歴史データの両方を保存・処理できる「ストリーミングデータレイクハウス」を構築することが可能になります。以下の2つの主要コンポーネントが、このアーキテクチャの構築に必要です:
-
ストリーム処理システム。 最初に必要なコンポーネントは、RisingWave、Apache Flink、またはKsqlDBのようなストリーム処理システムです。これらのシステムは、Kafkaに保存されたリアルタイムデータストリームを処理するよう設計されており、データ生成と同時に分析を行うことで、より迅速かつ情報に基づいた意思決定を可能にします。
-
リアルタイム分析エンジン。 次に必要なコンポーネントは、Apache Spark、Trino、またはClickHouseのようなリアルタイム分析エンジンです。これらのエンジンは、処理されたデータを分析し、洞察を提供し、意思決定を支援します。これらは、低遅延で大量のデータを扱う能力を持ち、Kafkaを基盤としたストリーミングデータレイクハウスアーキテクチャに最適です。
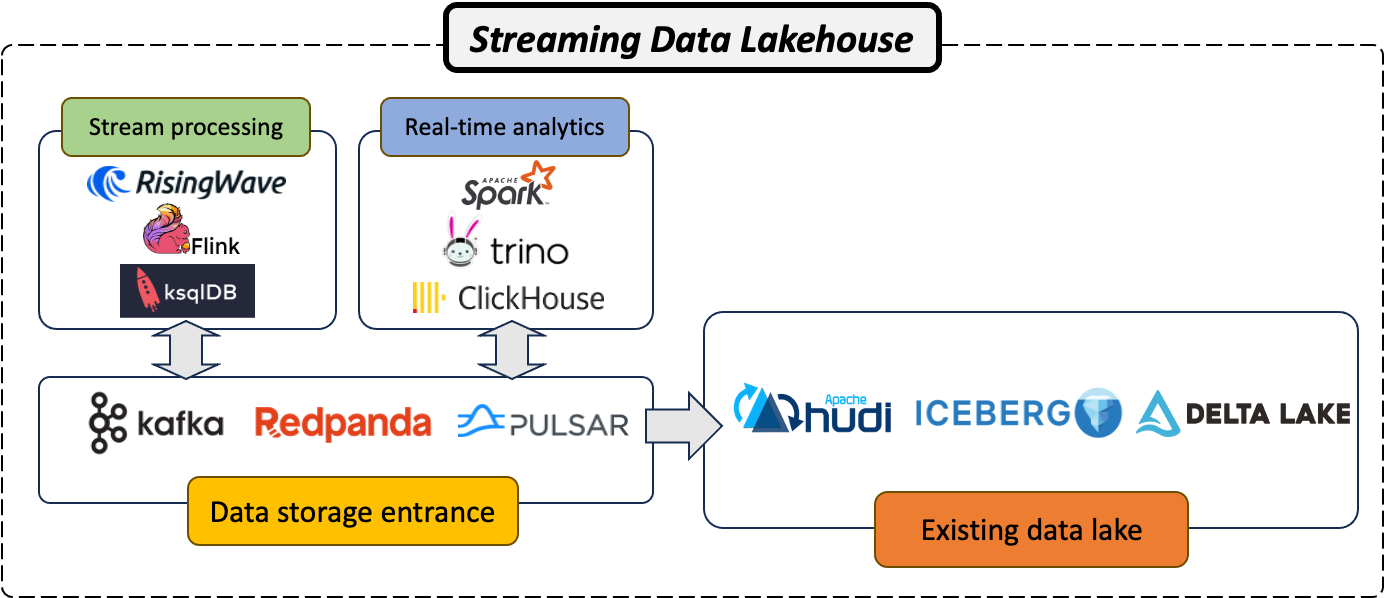
Kafkaを堅牢なストリーム処理システムおよび強力なリアルタイム分析エンジンと組み合わせることで、現代のデータ処理および分析のニーズに対応できるストリーミングデータレイクハウスアーキテクチャを構築することが可能になります。このアーキテクチャは、リアルタイムの洞察を提供し、より優れた意思決定を促進し、競争力を高めることで、企業がデータの価値を最大化するのに役立ちます。
Kafkaへの期待
Kafkaは非常に強力で多用途ですが、Kafkaが真のデータレイクに進化するには改善が必要な分野があります。以下は、Kafkaへのいくつかの期待リストです:
-
データ型認識による圧縮。 現在、Kafkaはデータをバイト配列として扱い、データの実際の構造や型を認識していません。この認識の欠如により、Kafkaが実行する圧縮は汎用的であり、データの構造を理解している場合よりも効率的ではありません。Kafkaが処理しているデータ型を認識できれば、より効果的にデータ圧縮を実行することが可能になります。この改善により、ストレージ要件が削減され、データ転送と処理の負担が最小化されることで、分析クエリのパフォーマンスが最適化されます。
-
クエリプッシュダウンのサポート。 クエリプッシュダウンとは、クエリの一部(例:フィルター処理)をストレージレイヤーにプッシュすることで、データの取得と処理をより効率化する技術です。現在、Kafkaはクエリプッシュダウンをサポートしておらず、必要なデータが少量であっても、すべてのデータをメモリにロードして処理する必要があります。Kafkaがクエリプッシュダウンをサポートすれば、メモリにロードして処理する必要のあるデータ量が削減され、分析クエリのパフォーマンスが向上します。
-
更新と削除のサポート。 現在のKafkaは追記専用ログとして設計されており、更新や削除を処理するための回避策はあるものの、それらは従来のデータベースほど簡単で効率的ではありません。Kafkaがネイティブに更新および削除操作をサポートすれば、データメンテナンスが容易かつ効率的になります。また、Kafkaはより完全で多用途なデータストレージソリューションとなり、データレイクとしての適性が向上します。この追加機能は、多くの組織にとって大きな変革となり、データアーキテクチャを簡素化し、データメンテナンスに関連する負担を軽減します。
結論
Kafkaを新しいデータレイクとして受け入れることは、データ管理と分析における基本的な変化を示しています。その高度な機能に加え、ストリーム処理システムとリアルタイム分析エンジンを組み合わせることで、レイクハウスアーキテクチャの強固な基盤となります。さらに、データの永続性、単一の信頼できる情報源としての能力、そして豊富なエコシステムにより、Kafkaはデータレイクの有力な選択肢としての地位を確立しています。今後、Kafkaや他のイベントストリーミングプラットフォームがどのように進化するか、注目していきましょう。