
古いレコメンデーションの提供を停止:リアルタイム化!
パーソナライズされた製品レコメンデーションは、もはやeコマースサイトにとって「必須」となっています。顧客は、今すぐにでもパーソナライズされた提案を期待しており、それがないと不満を抱くことになります。従来のバッチ処理によるレコメンデーションシステムはもはや追いつけません。これらは定期的な更新に依存しており、しばしば顧客には現在の興味に合わない、古くて不正確な提案を提供します。たとえば、ランニングシューズを探しているのに、昨日のデータに基づいて冬用コートのレコメンデーションが表示されることを想像してください!それは機会を逃したことになり、顧客も失望するでしょう。
この記事では、RisingWave、Kafka、Redisを使って、ユーザーのアクションに即座に反応するリアルタイムのレコメンデーションエンジンを構築する方法を紹介します。このシステムは、ショッピング体験を向上させ、コンバージョンを促進する関連性の高い提案を即座に提供します。
アーキテクチャ:リアルタイムレコメンデーションパイプライン
システムの構成は次のようになります:
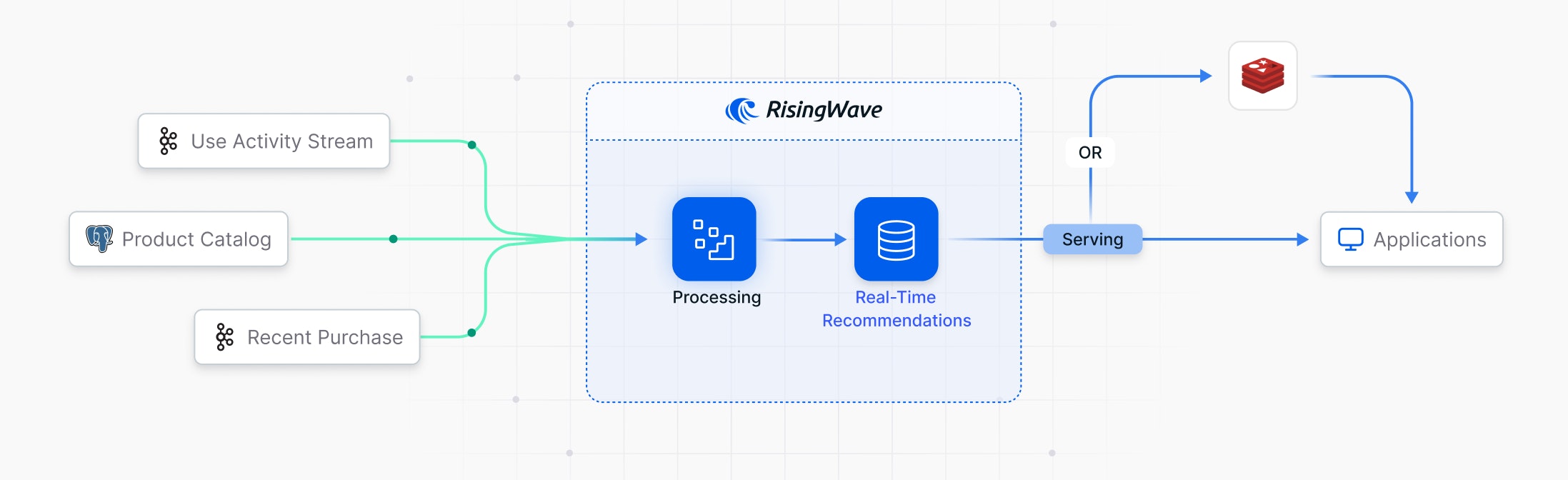
データフローの概要
-
データの取り込み:
- ユーザーアクティビティ(ページビュー、クリック、検索、カート追加イベントなど)がリアルタイムでKafkaトピックにストリーミングされます。
- 製品カタログデータ(ID、名前、カテゴリ、価格など)はPostgreSQLのようなデータベースに保存され、変更データキャプチャ(CDC)を通じて更新がキャプチャされ、RisingWaveにストリームされます。データが頻繁に更新されない場合は、製品カタログデータを直接RisingWaveに保存することもできます。
- オプションとして、購入ストリームを使って協調フィルタリングを行うこともできます。
-
ストリーム処理(RisingWave):
RisingWaveは、Kafkaトピックにリンクされたソースを定義することでこれらのストリームを取り込みます。SQLベースのマテリアライズドビューがレコメンデーションロジックを処理し、新しいデータが到着するたびに継続的に更新されます。
-
レコメンデーションストレージ(Redis):
RisingWaveのマテリアライズドビューから事前計算されたレコメンデーションがRedisに保存され、これは高速なデータ取得のために最適化されたインメモリキャッシュです。
注: 低トラフィックのセットアップやプロトタイプの場合、直接RisingWaveをクエリすることもできますが、パフォーマンスの観点から、本番環境ではRedisが推奨されます(現時点では)。
-
レコメンデーション提供:
eコマースアプリケーションは、ユーザーIDを使ってRedisからレコメンデーションを取得し、迅速でシームレスな体験を提供します。
サンプルデータ(JSON):
-
ユーザーアクティビティ(Kafka):
// ページビューイベント { "event_type": "page_view", "user_id": 123, "product_id": "product_abc", "timestamp": "2024-07-27T10:00:00Z" } // 検索イベント { "event_type": "search", "user_id": 456, "query": "running shoes", "timestamp": "2024-07-27T10:03:00Z" } -
製品カタログ(Kafka - CDC経由):
{ "product_id": "product_abc", "name": "Awesome Running Shoes", "category": "shoes/running", "price": 99.99, "description": "...", "image_url": "..." }
RisingWaveでのパイプライン構築
RisingWaveのSQLインターフェースを使用して、レコメンデーションエンジンの主要コンポーネントを構築していきましょう。
前提条件
まず、これらのシステムが稼働していることを確認してください。
- RisingWaveクラスター。クラスターの起動方法については、RisingWaveのクイックスタートを参照してください。
- ユーザーアクティビティストリームをトピックに保存するKafkaインスタンス。
-
product_catalogテーブルを保存し、変更データキャプチャ(CDC)が有効になっているPostgreSQLインスタンス。詳細な設定については、PostgreSQL CDCからのデータ取り込みを参照してください。 - レコメンデーションをキャッシュするためのRedisインスタンス。
ステップ1: ソースの定義
Kafkaトピックに接続するためのソース定義を作成します:
-- ユーザーアクティビティストリーム
CREATE SOURCE user_activity_stream (
event_type VARCHAR,
user_id INT,
product_id VARCHAR,
timestamp TIMESTAMP
) WITH (
connector = 'kafka',
topic = 'user_activity',
brokers = 'kafka-broker1:9092,kafka-broker2:9092',
scan.startup.mode = 'earliest',
format = 'json'
);
-- 製品カタログストリーム
CREATE SOURCE product_catalog (
product_id VARCHAR,
name VARCHAR,
category VARCHAR,
price DOUBLE PRECISION,
description VARCHAR,
image_url VARCHAR
) WITH (
connector = 'kafka',
topic = 'product_catalog',
brokers = 'kafka-broker1:9092,kafka-broker2:9092',
scan.startup.mode = 'earliest',
format = 'json'
);
ステップ2: トレンド製品用のマテリアライズドビュー
1時間ごとのウィンドウで、最も閲覧された製品トップ10を追跡します:
CREATE MATERIALIZED VIEW trending_products AS
WITH windowed_views AS (
SELECT
window_start,
product_id,
COUNT(*) AS view_count
FROM
TUMBLE(user_activity_stream, timestamp, INTERVAL '1 hour')
WHERE event_type = 'page_view'
GROUP BY window_start, product_id
),
ranked_products AS (
SELECT
window_start,
product_id,
view_count,
RANK() OVER (PARTITION BY window_start ORDER BY view_count DESC) AS rank
FROM windowed_views
)
SELECT
window_start,
product_id,
view_count
FROM ranked_products
WHERE rank <= 10; -- トップ10のトレンド製品
このビューは次のことを行います:
- ページビューを1時間ごとのウィンドウにグループ化。
- 各ウィンドウ内で、製品の閲覧数によってランキング。
- 新しいイベントがストリームされるたびにインクリメンタルに更新。
ステップ3: ユーザー固有のレコメンデーション用マテリアライズドビュー
最近のカテゴリビューに基づいて、パーソナライズされた提案を生成します:
CREATE MATERIALIZED VIEW user_recommendations AS
WITH recent_user_activity AS (
SELECT user_id, product_id, timestamp
FROM user_activity_stream
WHERE event_type = 'page_view'
AND timestamp > NOW() - INTERVAL '24 hours'
),
user_category_views AS (
SELECT
r.user_id,
p.category,
COUNT(*) AS category_views
FROM recent_user_activity r
JOIN product_catalog p ON r.product_id = p.product_id
GROUP BY r.user_id, p.category
),
ranked_categories AS (
SELECT
user_id,
category,
category_views,
RANK() OVER (PARTITION BY user_id ORDER BY category_views DESC) AS rank
FROM user_category_views
),
recommendations AS (
SELECT
rc.user_id,
p.product_id AS recommended_product_id
FROM ranked_categories rc
JOIN product_catalog p ON rc.category = p.category
WHERE rc.rank <= 3
AND p.product_id NOT IN (
SELECT product_id FROM recent_user_activity WHERE user_id = rc.user_id
)
)
SELECT
user_id,
array_agg(recommended_product_id) AS recommended_products
FROM recommendations
GROUP BY user_id;
このビューは次のことを行います:
- 過去24時間のアクティビティを分析。
- ユーザーのトップ3カテゴリを閲覧数でランク付け。
- これらのカテゴリから、まだ閲覧していない製品を提案。
ステップ4: Redisへのデータ出力
レコメンデーションをRedisにエクスポートします:
-- ユーザー固有のレコメンデーション用Sink
CREATE SINK user_recommendations_sink
FROM user_recommendations WITH (
connector = 'redis',
primary_key = 'user_id',
redis.url = 'redis://127.0.0.1:6379/'
) FORMAT PLAIN ENCODE JSON (
force_append_only = 'true'
);
-- トレンド製品用Sink
CREATE SINK trending_products_sink
FROM trending_products WITH (
connector = 'redis',
primary_key = 'window_start,product_id',
redis.url = 'redis://127.0.0.1:6379/'
) FORMAT PLAIN ENCODE TEMPLATE (
force_append_only = 'true',
key_format = 'trending:{window_start}',
value_format = '{product_id}:{view_count}'
);
-
Redis構造:
- ユーザーのレコメンデーション:
user_id → {"user_id": 123, "recommended_products": ["prod1", "prod2"]} - トレンド製品:
trending:2024-03-21T10:00:00 → product_abc:42
- ユーザーのレコメンデーション:
レコメンデーションの提供(アプリケーション側)
Redisからレコメンデーションを取得するためのシンプルなPythonスクリプト:
import redis
import json
# Redisに接続
redis_client = redis.Redis(host='127.0.0.1', port=6379, decode_responses=True)
def get_user_recommendations(user_id):
data = redis_client.get(str(user_id))
return json.loads(data)['recommended_products'] if data else []
def get_trending_products(window_start):
key = f"trending:{window_start}"
return redis_client.hgetall(key)
# 使用例
print(get_user_recommendations(123))
print(get_trending_products('2025-02-25T10:00:00'))
低トラフィックシナリオの場合の直接RisingWaveクエリ
前述の通り、低トラフィックのシナリオやプロトタイピング中であれば、直接RisingWaveにクエリを送ることも可能です。以下はその例です:
from risingwave import RisingWave, RisingWaveConnOptions, OutputFormat
import pandas as pd
# RisingWave SDKを使ってRisingWaveに接続
rw = RisingWave(
RisingWaveConnOptions.from_connection_info(
host='localhost',
port=4566, # デフォルトのRisingWaveポート
user='root',
password='root',
database='dev'
)
)
def get_recommendations_direct(user_id: int) -> list:
"""RisingWaveから直接レコメンデーションを取得"""
query = f"""
SELECT recommended_products
FROM user_recommendations
WHERE user_id = {user_id}
"""
# fetchを使用してDataFrameとして結果を取得
result: pd.DataFrame = rw.fetch(
query,
format=OutputFormat.DATAFRAME
)
if not result.empty:
return result['recommended_products'].iloc[0]
return []
# 使用例
def example_usage():
user_recs = get_recommendations_direct(123)
print(f"ユーザー123のレコメンデーション(直接): {user_recs}")
# 結果を生のタプルとして取得することも可能
raw_results = rw.fetch(
"SELECT * FROM trending_products LIMIT 5",
format=OutputFormat.RAW
)
print(f"トレンド製品(生データ): {raw_results}")
# 注:直接クエリを使うことは簡単ですが、
# 頻繁にリクエストがある本番環境では、Redisをキャッシュレイヤーとして使用することが推奨されます。
このアーキテクチャの利点とスケーラビリティ
このセットアップは次のような利点を提供します:
- リアルタイム更新: ユーザーアクションに即座に反応します。
- 低レイテンシ: Redisが迅速なデータ取得を確保し、RisingWaveはそれ以外の処理を効率的に処理します。
- スケーラビリティ: RisingWaveとRedisはどちらもトラフィックに応じて水平スケーリング可能です。
- 使いやすさ: SQLを使用することで開発が簡単です。
- 信頼性: 分散設計により耐障害性が向上します。
さらに進める方法:将来の拡張
この記事は堅実な基盤を提供しますが、システムを強化するためのいくつかの方法を紹介します:
- レコメンデーション戦略のA/Bテストを実装。
- より深い洞察を得るために機械学習モデルを統合。
- ユーザーのデモグラフィックに合わせたセグメント化されたトレンドの追加。
- 高度なパーソナライゼーションのために、特徴量ストアを使ってデータを豊かにする。
今すぐ始めよう!
RisingWaveを使うことで、リアルタイムレコメンデーションシステムの構築は驚くほど簡単です。ストリーミングデータ処理の力とRedisのスピードを組み合わせることで、顧客を引き寄せるダイナミックで魅力的なeコマース体験を作り出せます。まずはRisingWaveのドキュメントを参照して始めてみましょう!