ストリーム処理は新しい技術ではありません。この概念は少なくとも23年間研究されてきました!私が最初に目にした学術論文は2002年に遡り、これは有名なMapReduce論文が発表されるわずか2年前のことでした。
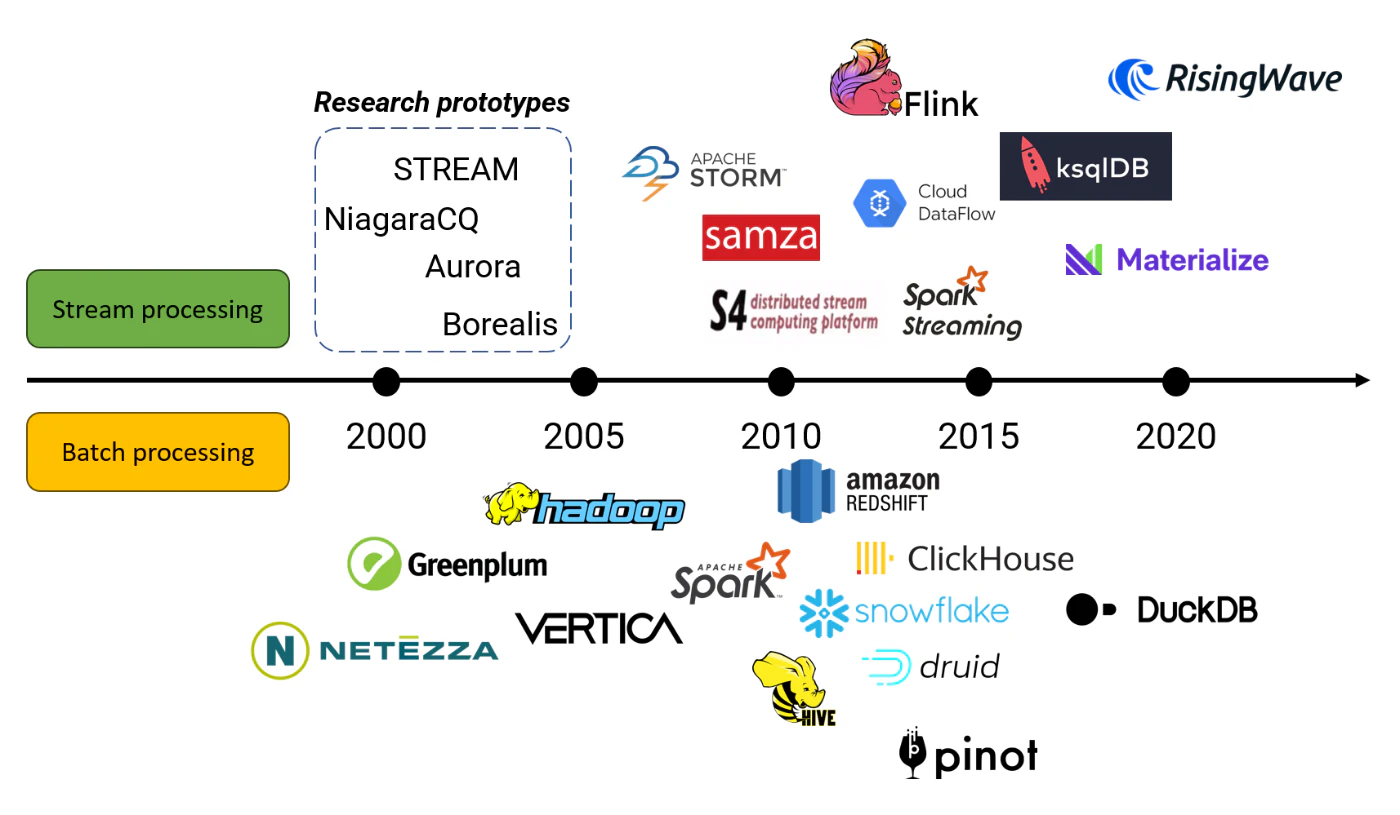
2000年代には、StreamBase(現在はTIBCOの一部)などの先駆的な企業がウォール街でこの技術の商業化を始めました。しかし、クラウド上でストリーム処理を商業化する動きが本格化したのはここ数年のことです。RisingWaveは2021年初頭に導入され、ConfluentはImmerokを買収し、2023年にApache Flinkの商業化を開始しました。Databricksもまた、データストリーミング分野で競争するためにSpark Streamingの新バージョンであるProject Lightspeedを発表しました。さらに、いくつかのスタートアップ企業が既存のオープンソースシステムをベースにした製品を開発するか、独自のソリューションを構築しています。
多くのデータベンダーがこの分野で活動する中で、ほとんどが似たような目標やアプローチに収束しているのは興味深いことです。本記事では、エンジニアの視点から見た2025年のストリーム処理システムの予測を共有します。
免責事項: 私はRisingWaveに関与していますが、できる限り中立的な立場で技術的な側面に焦点を当て、商業的な偏りを避けるよう努めています。見落としや誤った記述があれば、ぜひご連絡ください。
「S3を主要ストレージとするアーキテクチャ」の採用
AWS S3は信頼性が高くコスト効率に優れたストレージサービスとしての地位を確立し、Snowflakeの成功により、現代のデータインフラの基盤としての役割が強化されました。時間が経つにつれ、データシステムはますますS3ベースのアーキテクチャに移行し、スタートアップ企業はS3上に完全に新しいシステムを構築して革新を推し進めています。
ストリーミングシステムも同様の可能性を探求しています。私の知る限りでは、RisingWaveは、S3を主要なストレージレイヤーとして設計された初のストリーム処理システムです。2021年に開発が開始され、4年の試行錯誤を経て大きく進化しました。最近では、AlibabaがFlink 2.0でのストレージとコンピュートの分離を導入する計画を発表し、内部で培ったベストプラクティスを活用しています。
ストレージとコンピュートの分離は、分散システムにおける大きなトレンドに合致していますが、ストリーム処理での実装には独自の技術的課題があります。
バッチ処理システム(例えばSnowflake)とは異なり、ストリーム処理システムは本質的に状態を持っています。これらのシステムは、増分計算のために内部状態への継続的なアクセスを必要とします。ストレージとコンピュートの分離を採用することは、これらの状態をS3に移動することを意味します。一見すると、このアプローチは魅力的に思えます。S3はローカルメモリやディスクに比べてストレージコストが低く、そのスケーラビリティにより、ジョインのような大規模な状態操作(メモリ不足を引き起こす可能性があるもの)を処理するのに適しています。しかし、現実はそれほど簡単ではありません。
主な障害はS3の遅延です。その耐久性やスケーラビリティに優れる一方で、アクセス時間はローカルストレージよりも桁違いに遅く、低遅延を求めるストリーム処理ワークロードにとっては重要な制限となります。さらに、S3との頻繁なやり取りはアクセスコストを大幅に増加させ、ストレージレイヤーとしてのコストメリットを損なう可能性があります。問題をさらに複雑にするのは、S3によるパフォーマンス低下に対処するために高度なキャッシング戦略が必要になることです。これらの最適化なしでは、運用ワークロードが深刻な性能低下に見舞われ、コストも管理不能になるリスクがあります。
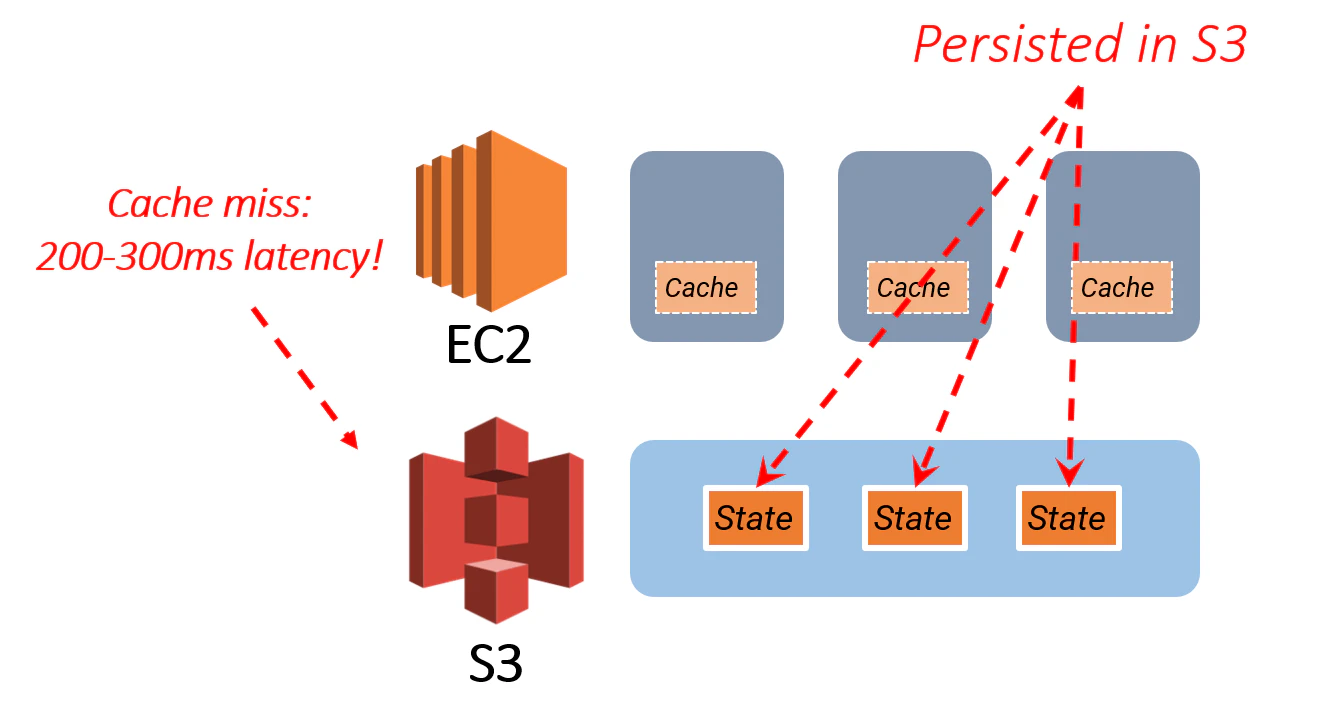
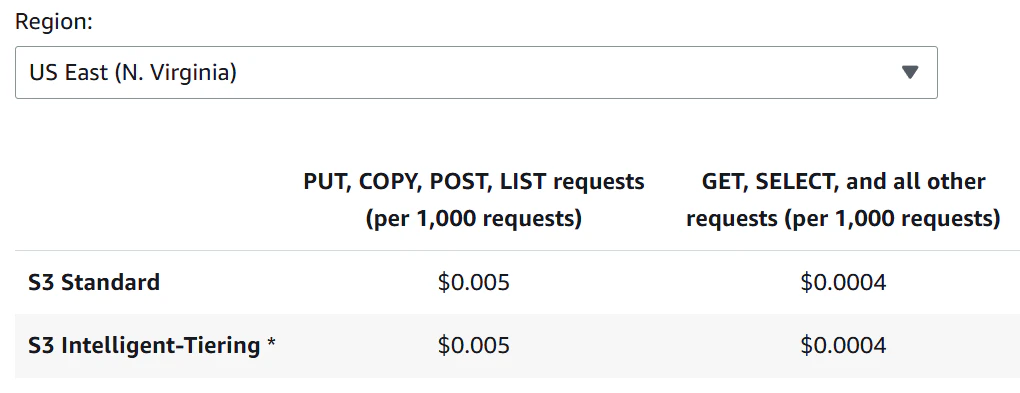
2025年までには、多くのストリーム処理システムがアーキテクチャの基盤としてS3を採用することが予想されます。しかし、S3を中心とした効率的なシステムを構築するには大規模な技術投資が必要です。頻繁にアクセスされるデータをローカルストレージやメモリに保存するハイブリッドストレージモデルや高度なキャッシングメカニズムといった手法が不可欠となるでしょう。ストレージとコンピュートの分離はストリーム処理における画期的な進展を示しますが、その可能性を実現するには性能やコストの課題を解決することが不可欠です。
Kafkaのシェアを狙う
イベントストリーミングの話題になると、Kafkaは避けて通れません。Kafkaはイベントストリーミングの事実上の標準として広く使用され、システム間でデータを移動するためのデータパイプラインとして機能しています。しかし、データ移動を可能にするツールはKafkaだけではありません。Fivetran、AirbyteといったSaaSソリューションは、データ取り込みのための使いやすいツールを提供し、エンジニアが利用できる選択肢を広げています。
Kafkaの人気にもかかわらず、その計算能力は限られています。そのため、ジョイン、集約、フィルタリング、射影など、リアルタイムデータ変換を処理するためにストリーム処理システムが必要です。しかし、ここで課題となるのは、データ取り込みとストリーム処理の2つのシステムを別々に管理する必要がある点です。この2重構成の維持はリソースを大量に消費し、開発の複雑性と運用コストを増大させます。
この非効率性に対処するため、ストリーム処理システムはデータ取り込み機能を統合しつつあります。特に、RisingWave、Apache Flink、Apache Spark Streamingなどのシステムは、Postgres、MySQL、MongoDBなどの上流ソースからのCDC(Change Data Capture)データを直接取り込む機能をサポートしています。これにより、Kafkaを中間層として使用する必要がなくなり、アーキテクチャの負担が軽減され、ワークフローが簡素化されます。
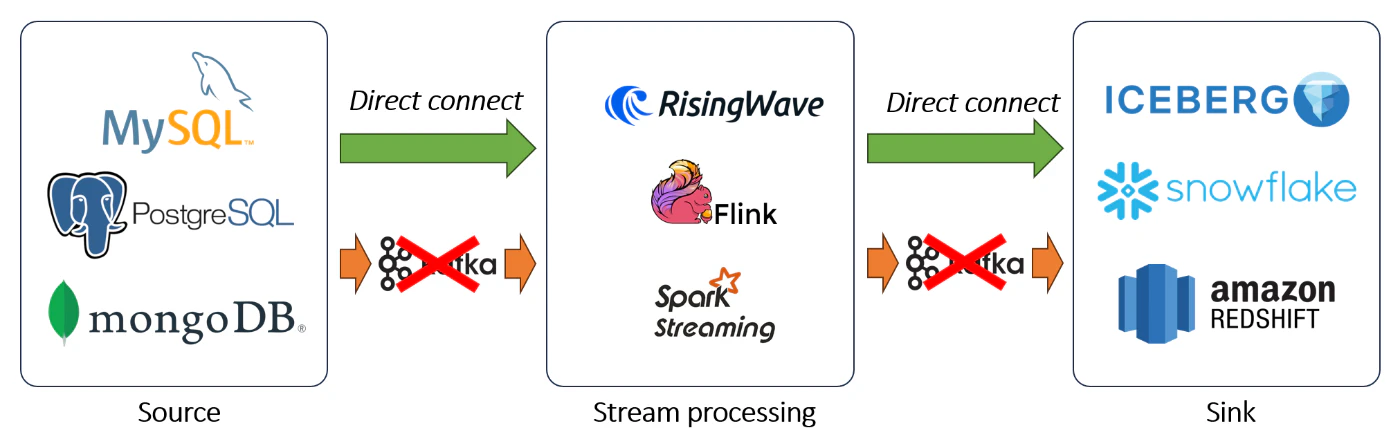
2025年を見据えたとき、ストリーム処理システムはイベントストリーミングプラットフォームであるKafkaと直接競合するでしょうか?短い答えは「完全には競合しない」です。機能の重複はあるものの、ストリーム処理システムがKafkaを完全に置き換えることはないでしょう。Kafkaは、ストリーム処理システムの設計範囲を超える広範なユースケースを持っているため、データエコシステムにおけるその重要性は引き続き維持されると考えられます。
データレイクの採用
2024年は間違いなくデータレイクの年です。Databricksは、Icebergの元開発者が設立したTabularを買収し、Icebergの可能性を大きく後押ししました。同時に、SnowflakeはPolarisというIcebergベースのカタログサービスを発表しました。StarburstやDremioといった主要なクエリエンジンベンダーもPolarisへのサポートを示し、統一基準に向けた動きが進んでいます。
モダンなデータエンジニアリングにおいて関連性を維持するために、ほぼすべてのデータストリーミングベンダーがIcebergとの統合を発表しています。例えば、Confluentは、KafkaデータをIceberg形式に直接取り込むための製品Tableflowを公開しました。同様に、Redpandaもデータレイクにデータをストリーミングする類似サービスを立ち上げました。StreamNativeのUrsa Engineもこの成長するトレンドの一例です。
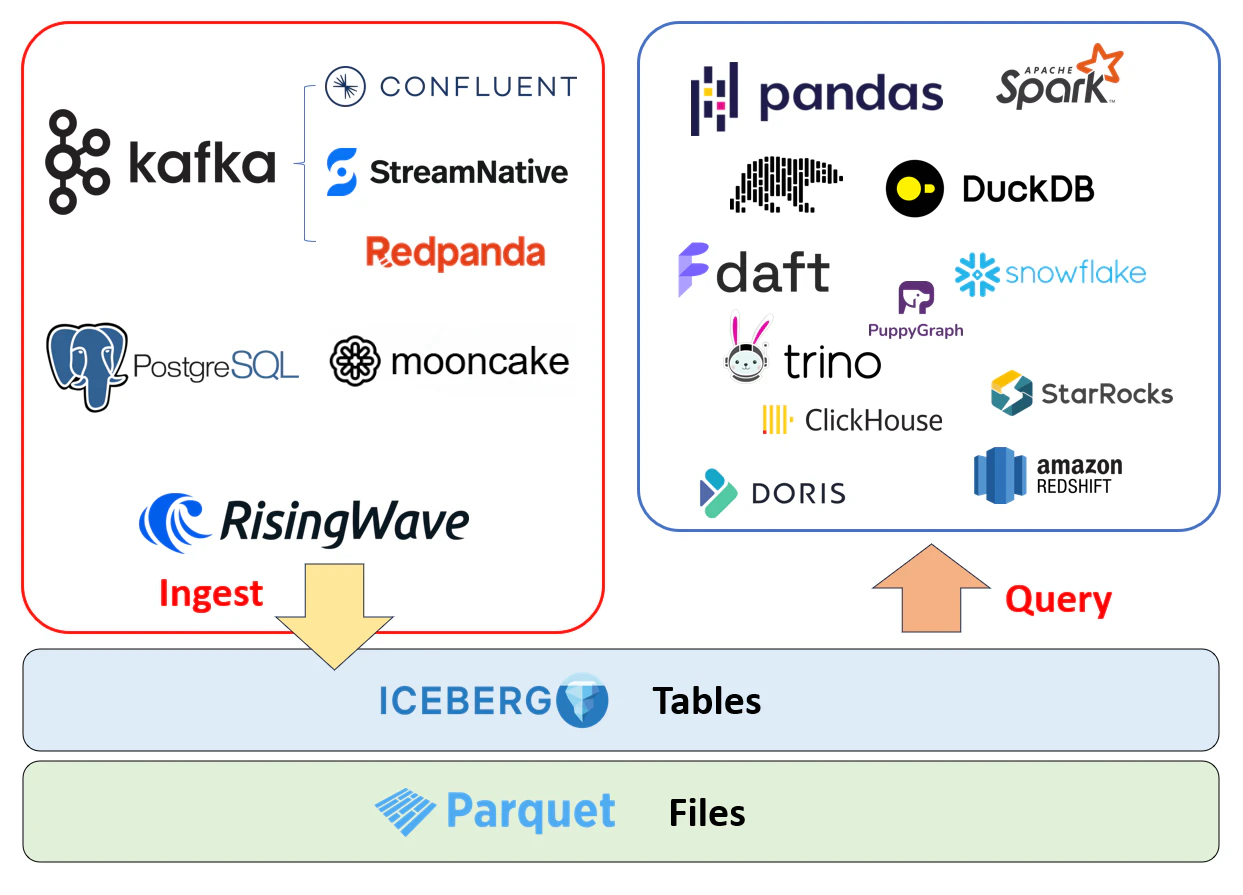
ストリーム処理システムについて言えば、Icebergのサポート状況はベンダーによって異なります。Spark Streamingを統括するDatabricksはDelta Lakeに注力しており、Alibabaの影響を強く受けるApache FlinkはIcebergの代替であるPaimonを推進しています。一方、RisingWaveはIcebergを全面的に受け入れており、AWS Glue Catalog、Polaris、Unity Catalogなど、さまざまなカタログサービスをサポートすることを目指しています。
データストリーミングとデータレイクの統合は、単なるデータ取り込みにとどまりません。DatabricksのDelta Live Tables機能に示されるように、データレイクに対する増分計算への需要が高まっています。しかし、IcebergはまだCDC(Change Data Capture)を完全にサポートしていないため、現在のところIceberg上で効率的な増分計算を提供するシステムは存在しません。このギャップはまもなく解消される可能性があり、Iceberg spec v3が間もなく登場し、この分野での競争が本格化するでしょう。
クエリ提供の最適化
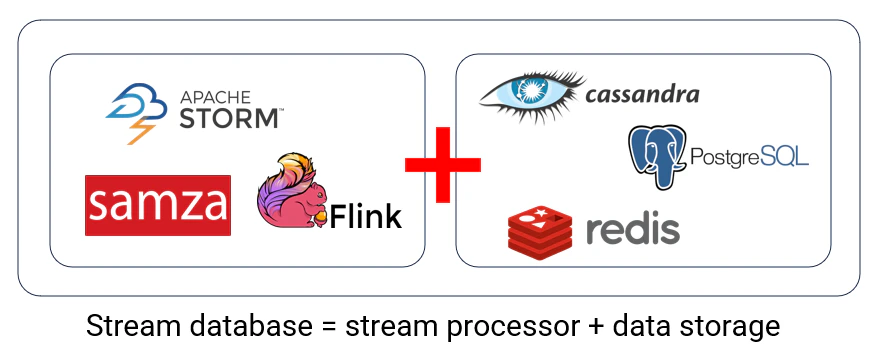
ストリーム処理の分野を長く追っている人であれば、顕著なトレンドに気づくはずです。それは、多くのストリーム処理システムが独自のストレージエンジンを構築しているということです。例えば、RisingWaveはデフォルトでデータの保存と提供機能を備えたストリーミングデータベースです。同様に、Flinkは最近FlussやPaimonを導入し、その提供能力を強化しています。DatabricksのDelta Live TablesもSpark Streamingを基盤として構築されており、データの直接提供を可能にしています。この動きは、業界全体のトレンドを反映しています。
なぜこれらのストリーム処理システムが、ストレージと提供機能を統合する方向に進んでいるのでしょうか?答えはアーキテクチャの簡素化にあります。従来、ストリーム処理システムはデータ処理のみに特化し、ストレージおよび提供レイヤーは別のシステムが管理していました。しかし、単一アプリケーションのために複数のシステムを維持することは、運用負担を大幅に増加させ、複雑性とコストを押し上げます。
データ取り込み、処理、提供レイヤーを1つのシステムに統合することで、ストリーム処理プラットフォームはデータフローをスムーズにし、保守負担を軽減し、アプリケーション開発のタイムラインを短縮します。これにより、開発者は数年ではなく数ヶ月でアプリケーションを構築して展開できるようになります。
このシフトは、システム内の可動部分が多すぎることによるコストと複雑さという重大な課題にも対処しています。単一プラットフォームでデータ取り込み、ステートフル処理、リアルタイム提供を管理できる場合、効率が向上し、遅延が低減し、コストが削減されます。その結果、現代のストリーム処理システムは、処理能力の強みを活かしつつ、堅牢なストレージと提供能力を提供する包括的なアプローチを採用しています。
将来を見据えると、この分野での継続的なイノベーションが期待されます。システムは、リアルタイムデータアプリケーションの拡張性、性能、シンプルさへの高まる要求を満たすために進化し続けるでしょう。
AIへの注目
AIは、テクノロジー分野でのほぼすべての会話の中心となっており、ストリーム処理システムも例外ではありません。多くのイベントストリーミングおよびデータシステムが、このAI主導の環境で関連性を保つための機能を開発しています。新たに浮上しているパターンの1つは、さまざまなソースからデータを直接取り込み、埋め込みサービスを利用して生データをベクトルに変換し、ベクトルデータベースを使用してベクトル検索を可能にすることです。このトレンドは大きな注目を集めており、AWSでさえこのワークフローをサポートするソリューションを提供しています。
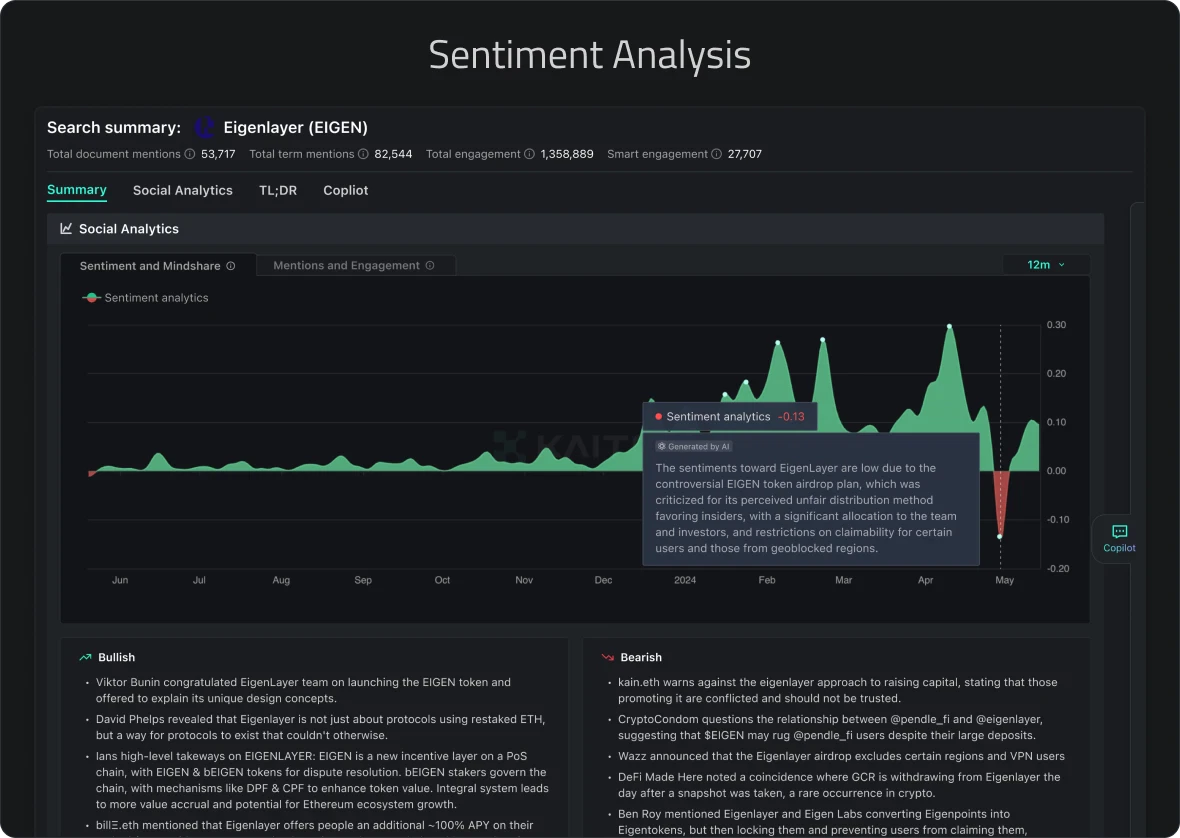
こうした機能に対する需要は明白です。例えば、急成長している暗号通貨関連の企業Kaitoは、Xからリアルタイムデータを高ボリュームで取り込み、センチメント分析を行い、RisingWaveを利用してトレーダー向けの行動可能なインサイトを生成しています。このセンチメント分析はLLM(大規模言語モデル)によって実現されています。しかし、現在のLLMには100〜200msの遅延があるため、広告ターゲティングや商品推薦のような遅延に敏感な分野には適していません。この分野では従来型の機械学習モデルが依然として主流です。
未来のリアルタイムAIはどのような姿をしているのでしょうか?LLMの進化に伴い、より多くの開発者がAI駆動型メカニズムをアプリケーションに統合する方法を模索しています。リアルタイム特徴量エンジニアリングは、これらの取り組みの中核を成し続け、アプリケーションが動的にデータを処理し、行動することを可能にします。AIとストリーム処理のシナジーはまだ初期段階にありますが、リアルタイムデータアプリケーションにおける次の革新の波を定義する可能性を秘めています。
結論
2025年のストリーム処理システムのトレンドを2つの言葉で要約するなら、「レイクハウス」と「AI」でしょう。主要なストリーム処理システムのすべてがIcebergに収束し、AI統合における役割を模索していることは明らかです。これらのトレンドに適応する企業は、競争力を維持するだけでなく、リアルタイムでデータ集約型アプリケーションが拡大する世界で成功を収めるでしょう。