【問題】処理スピードが遅いアレイのフィルター
※この記事は私の記事の中では少し難しめとなっています。
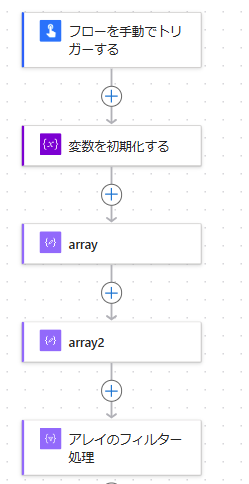
例えば下記のように、顧客から
①arrayというドメインリストがある。
②array2のメールアドレスと氏名のリストのメールアドレスにドメインが含まれているかどうかを調べたい
といわれた時、基本はアレイのフィルター処理で合致するデータを探すのが一般的だと思います。
[
{
"ID": "docomo.com",
"Type": "domain"
},
{
"ID": "satokaihatsu.com",
"Type": "domain"
},
{
"ID": "au.com",
"Type": "domain"
}
]
[
{
"ID": "AyaAkita@docomo.com",
"Name": "秋田彩"
},
{
"ID": "HarukoSuzuki@satokaihatsu.com",
"Name": "鈴木春子"
},
{
"ID": "TomokiFuyuki@au.com",
"Name": "冬木智樹"
},
{
"ID": "NatsukoMaToba@au.com",
"Name": "的場奈津子"
}
]
このぐらいのデータ数ならば処理スピードには問題ないのですが
件数が5000件、10000件となってくると話しは変わってきます。
For eachでLoopさせながらデータを吐き出すので何時間とかかるんです…![]()
そういった場合はXMLのXpathなどを利用するように言われており、
XMLの【に等しい】時のmargeの仕方は
多分下記のポールさんが一番最初に教えてくださっていたと思います。
※余談ですが彼は今も私のあこがれの存在です。I really into his solution as always!
一方で、【次の値を含む】際の
Xpathの書き方も業務では意外と必要だったのですが、
誰も記載している様子がなかったので紹介したいと思います。
上記2つのアレイを結合した結果としては下記のとおりです。
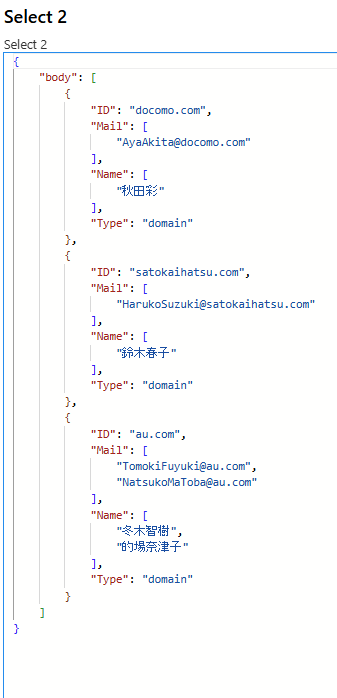
やり方
先の動画のポールさんのやり方を参考に
Array、Array2を作成し、Prepare Array、XMLという作成アクションを作ります(ここまでは全く同じです)
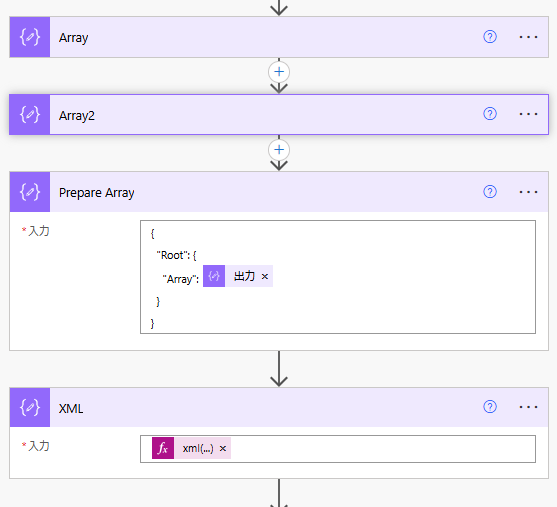
{
"Root": {
"Array": @{outputs('Array2')}
}
}
@{xml(outputs('Prepare_Array'))}
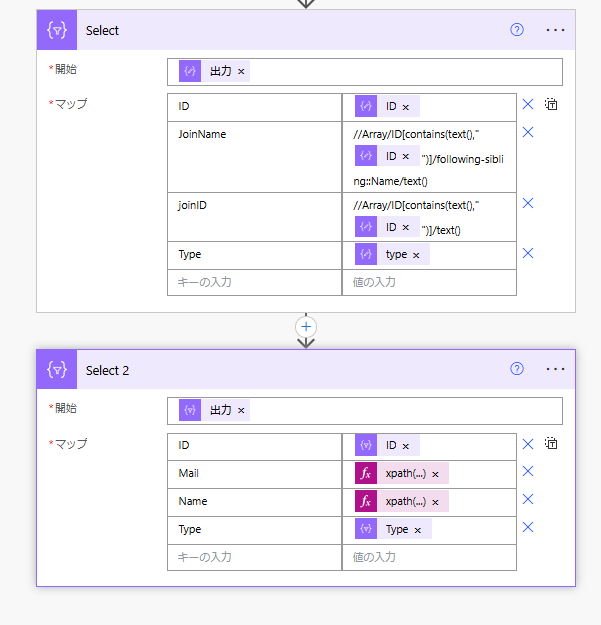
さて、ここからが皆さんが確認したいところかと思います。
上記画像を参照してください。
Select(選択)のアクションを追加し、
開始にarrayアクションを入れて、マップのKeyにJoinNameとJoinID、そしてValueにXPathコードをそれぞれ埋め込みます
//Array/ID[contains(text(),"item()?['ID']")]/following-sibling::Name/text()
//Array/ID[contains(text(),"item()?['ID']")]/text()
上記はもう一つのArray2をJoinするためのXpathコードにitem()?['ID']を埋め込んでいます。
そして最後に再度選択アクションを追加し
MailとNameのキーを作成し
それぞれ下記のように記載します。
xpath(outputs('XML'),item()?['joinID'])
xpath(outputs('XML'),item()?['joinName'])
大体Xpathのコード内容は、選択を2度使うのではなく、
Concatを使ってitem()?['ID']とXpathのコードをくっつけて一度に書いてしまうことも多いのですが
Xpathコードを流用したり直したりもするので、変更しやすいように選択に直接ベタ書きしています。
そのほうが複雑にならなくて楽なんですよね。
以上が【次の値を含む】アレイを抽出する際に使用するやり方となります。
最後に
上記の含むデータを加工して含まないデータも作成できると思います。
Xpathの使用の仕方はDesktopの方が紹介されているものが多いですが
PowerAutomateのクラウドでも利用できるので、
応用して使ってみるとスピードの大幅改善になったりもします!