はじめに
C++にとってGUI開発はお手軽ではなくGUI部をC#で開発することもよくあります。しかし、残念ながらC#とC++間のデータ交換は容易ではなく結構苦労します。
私はC++用のシリアライザTheolizerを開発してますが、これはメタ・シリアライザ機能を実験的に持っており、それを使ってC#とC++を簡単に連携できる可能性がありますのでトライしようと考えています。(Javaなどの他の言語とのお手軽連携も可能ですが、私がC#に慣れているので)
しかし、C#がC++の速度に追いついたという記事をちらほら見かけます。もし、それが多くのケースで成り立つのであれば、わざわざ連携するより最初からC#で全て開発した方が速いです。(C++erにとってC#の構文をマスターするのはそれ程難易度の高いことではないです。びっくりする程似てますので。)
そこで、実際のところどうなのか比較してみました。
結論としては、C#の方が高速な場面はありますが、多くの場面でC++の方が高速です。CPUをぶん回すようなプログラムを開発する必要がある時、C#でC++を凌駕するのは現実的ではありません。やはり適材適所で使い分けするのが妥当という、ある意味当たり前の結論となりました。
それぞれの言語の狙い通り、C#は処理速度と生産性のバランスが重要な時、C++は多少生産性を犠牲にしても処理速度が必要な時に用いると良いです。
評価に用いたソース・コードはGitHubのリポジトリCompareSpeedにてMITライセンスにて公開しています。興味のある方は御覧ください。
1. 評価環境
評価時に使用した環境は以下の通りです。
| 項目 | 種別とバージョン |
|---|---|
| OS | Windows 10 Pro バージョン 1703 OSビルド 15063.674 |
| 開発環境 | Visual Stuido Community 2017 Version 15.4.1 .NET Framework Version 4.6.02046 |
| ターゲットフレームワーク | .NET Framework 4.6.2 |
| ビルド | 64bit Releaseビルド |
| 最適化オプション | Visual Studioプロジェクト生成のデフォルト |
| CPU | Intel(R) Core(TM) i7-3820 CPU @3.60GHz |
| メモリ | 16GB |
また、計測した時間の単位は特記無き場合mSecです。
2. C#がC++より高速になった?
2-1. まずは再現確認
「C# C++ 速度」で検索するとトップの方に出て来る気づいたら、C# が C++ の速度を凌駕している!のシリーズから続) 気づいたら、C# が C++ の速度を凌駕している!を検証してみました。(メモリ獲得/解放を除いた部分を比較しているので分かりやすいです。)
リンク先の記事の評価対象のソースを引用させて頂き、C#側はStopwatch、C++はstd::chrono::system_clockを使用して処理時間を計測しました。
計測はそれぞれ100回測定し、平均値と3σ(簡単のため母分散を使用)を求めました。
| 評価対象 | リンク先記事の結果 | 当検証(平均値) | 当検証(3σ) |
|---|---|---|---|
| C++(test2) | 1673 | 1622 | 114 |
| C#マネージド(test1) | 2533 | 2371 | 20 |
| C#アンセーフ(test2) | 1675 | 1593 | 14 |
リンク先の記事とほぼ同じ結果がでてます。
この検証についてですが、他の検証記事でC#の方がそれなりに遅いという結果がでている場合もあります。一見矛盾するようにも見えますが、当記事の最後の方に記載しているようにC#の処理速度は再現性が微妙です。ソースを修正すると修正していない部分の速度が遅くなることが時々あります。
今回の記事は気がついた範囲ではC#側が高速になるよう安定する状態で計測しています。そこまで追求しなかった場合、C#側の速度が遅くなる結果になることは十分に考えられます。C#は思わぬ時に速度が低下します。
2-2. 次にちょっと修正して比較
リンク先記事は、4321 x 6789ピクセルの1ピクセル1バイトのグレイスケールの画像を想定し、アラインを取るため1行は4324バイト確保しています。合計43246789バイトのメモリを用意し、内43216789バイトへバイト書き込みしています。
このままでは、獲得するメモリ・サイズなど条件を振る際に手間がかかりそうですので少し単純化しました。4321*6789バイト確保し、その全てへバイト書き込みます。
なお、このテスト以降、各テストに「係数(sFactor)」を導入し、テストに掛かるリアル時間を100ミリ秒~1秒程度に収めるようにsFactorの値を設定しています。(テストの繰り返し数をsFactorで割り、計測した時間をsFactor倍して換算してます。)
| 評価対象 | 平均値 | 3σ |
|---|---|---|
| C++ | 1615 | 107 |
| C#マネージド1 | 1584 | 20 |
| C#マネージド2 | 2370 | 20 |
| C#マネージド3 | 1187 | 15 |
| C#アンセーフ1 | 1780 | 22 |
| C#アンセーフ2 | 1581 | 29 |
最初にトライしたものは、C#マネージド1(平均1,584mSec)とC#アンセーフ1(平均1,780mSec)でした。何故かマネージドの方が速いのです。元の評価記事とあまりに異なりますし、一般的に知られている傾向とも異なりますので少し追求しました。
2-2-1.最初のソース
最初に処理時間を計測したソースは以下の通りです。
kCountLai=4321*6789、kCountLao=100、sFactor=1です。
C++は元サイトの検証時と同等ですが、C#は随分異なります。ほぼ元サイトのパラメータと同じなのでこんなに差がでるのは変です。
C++:平均時間1,615mSec(元サイト検証プログラムの平均時間1,622mSec)
void setLargeArray()
{
std::unique_ptr<byte[]> aArray(new byte[kCountLai]);
int aCount = kCountLao/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCountLai; ++i)
{
aArray[i] = static_cast<byte>(i ^ j);
}
}
}
C#マネージド1:平均時間1,584mSec(元サイト検証プログラムの平均時間2,371mSec)
static void setLargeArrayManaged1()
{
var aArray = new byte[kCountLai];
int aCount = kCountLao/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCountLai; ++i)
{
aArray[i] = (byte)(i ^ j);
}
}
}
C#アンセーフ1:平均時間1,780mSec(元サイト検証プログラムの平均時間1,593mSec)
unsafe static void setLargeArray1Unsafe()
{
var aArray = new byte[kCountLai];
fixed (byte* aArrayFixed = aArray)
{
for (int j=0; j < kCountLao/sFactor; ++j)
{
for (int i=0; i < kCountLai; ++i)
{
aArrayFixed[i] = (byte)(i ^ j);
}
}
}
}
2-2-2.マネージドについて元サイトとの相違の解決
大きな差は、内側のループを別メソッドで処理しているかいないかのように思いました。流石に100回程度のメソッド・コールでこんな差がでるとは思えないのですが、やってみたらビンゴ!でした。
C#マネージド2:平均時間2,370mSec(元サイト検証プログラムの平均時間2,371mSec)
static void setLargeArrayManaged2()
{
var aArray = new byte[kCountLai];
int aCount = kCountLao/sFactor;
for (int j=0; j < aCount; ++j)
{
setLargeArrayManaged2Body(aArray, j);
}
}
static void setLargeArrayManaged2Body(byte[] iArray, int j)
{
for (int i=0; i < kCountLai; ++i)
{
iArray[i] = (byte)(i ^ j);
}
}
2-2-3.原因の追求
100回しか呼び出しておらずメソッド・コールがそんなに遅いとか有り得ないため、試しに設定バイト数を半分に減らしてみました。
平均時間はほぼ半減しました。ある意味当たり前ですね。
しかし、メソッド呼び出し回数はどちらも100回ですから、処理時間のほとんどがメソッド呼び出し時間ではなくメモリ書き込み時間であることが分かります。
2-2-1.と2-2-2.のマネージドの結果はメソッド呼び出しするかしないかのみの相違です。メソッド呼び出しそのものの時間はほぼ無視できるため、メソッド呼び出しを挟むことによりメモリ書き込み時間が遅くなる(1,589mSec → 2,373mSec)と結論できます。
メソッド呼び出しの有無でメモリ書き込み時間が変わる理由は分かりませんが、1回目の書き込み時に物理アドレスが割り当たっていることをチェックするので遅く、2回目以降は割り当て済みなので速く、メソッド呼び出しを挟むと常にチェックが働いて遅いのかも?と想像してます。 真の原因は掴めていません。
C#マネージド3:平均時間1,187mSec(全バイト書込時の平均時間2,370mSec)
static void setLargeArrayManaged3()
{
var aArray = new byte[kCountLai];
int aCount = kCountLao/sFactor;
for (int j=0; j < aCount; ++j)
{
setLargeArrayManaged3Body(aArray, j);
}
}
static void setLargeArrayManaged3Body(byte[] iArray, int j)
{
for (int i=0; i < kCountLai; i+=2)
{
iArray[i] = (byte)(i ^ j);
}
}
2-2-4.アンセーフについて元サイトとの相違の解決
こちらも元サイトと異なる結果になりました。差はメソッド呼び出しているかどうかですが、先の検証からメソッド呼び出し自体は原因ではない筈ですので、ポインタ渡しをシミュレート(aArrayFixed2へ設定してアクセスする)してみたところ再現しました。C++erにとっては意外なことで速度が変わります。
C#アンセーフ2:平均時間1,581mSec(元サイト検証プログラムの平均時間1,593mSec)
unsafe static void setLargeArray2Unsafe()
{
var aArray = new byte[kCountLai];
fixed (byte* aArrayFixed = aArray)
{
byte* aArrayFixed2 = aArrayFixed;
for (int j=0; j < kCountLao/sFactor; ++j)
{
for (int i=0; i < kCountLai; ++i)
{
aArrayFixed2[i] = (byte)(i ^ j);
}
}
}
}
3. メモリ獲得と設定
大きくC#にC++が負けているのが約200バイトまでのメモリ獲得と設定処理です。
10バイト~10,000,000バイトまでを10倍づつ増やして計測しました。1,000バイト以上についてsFactorを10から10倍づつ増やしてリアル時間がほど同等になるよう制御しています。(計測に多量の時間がかかると辛いので)
| タイトル | バイト数 | sFactor | C++ | C#マネージ | C#アンセーフ |
|---|---|---|---|---|---|
| get 10bytes memory & setup. | 10 | 1 | 575 | 128 | 132 |
| get 100bytes memory & setup. | 100 | 1 | 936 | 774 | 776 |
| get 1000bytes memory & setup. | 1,000 | 10 | 3,450 | 6,121 | 6,119 |
| get 10000bytes memory & setup. | 10,000 | 100 | 29,995 | 59,357 | 59,436 |
| get 100000bytes memory & setup. | 100,000 | 1,000 | 303,502 | 708,180 | 711,781 |
| get 1000000bytes memory & setup. | 1,000,000 | 10,000 | 3,088,057 | 7,009,674 | 7,011,499 |
| get 10000000bytes memory & setup. | 10,000,000 | 100,000 | 50,441,143 | 75,632,585 | 75,652,502 |
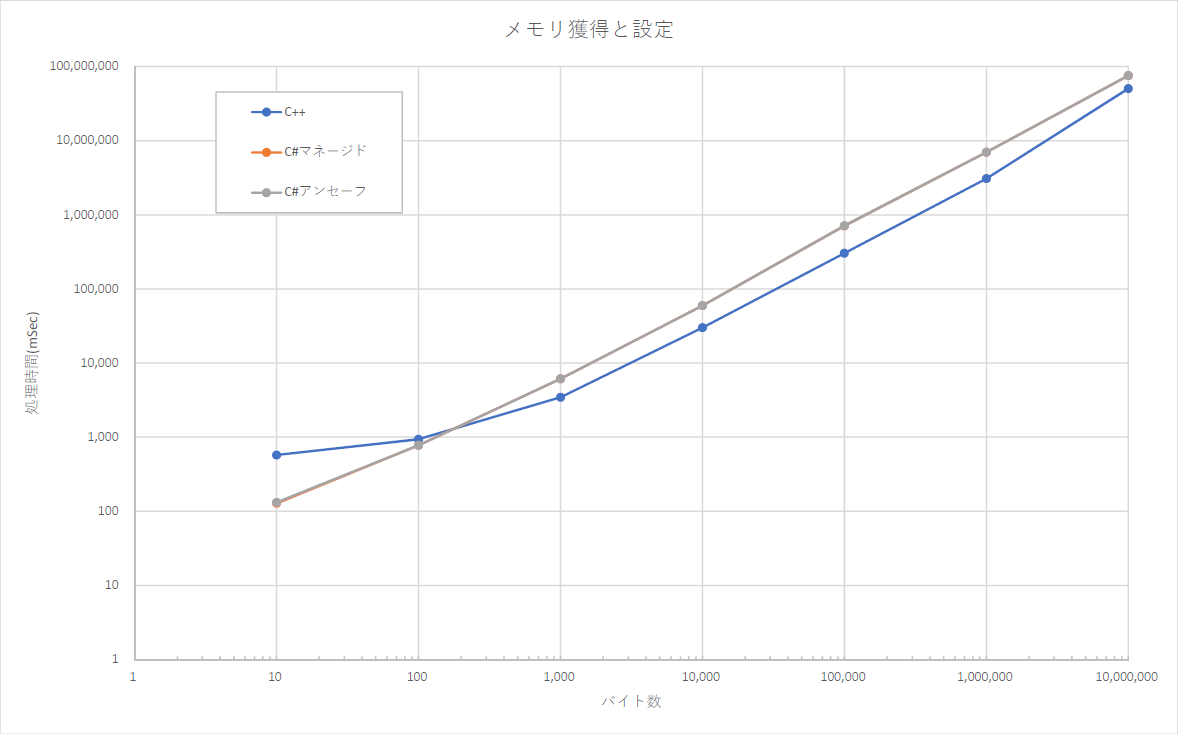
(対数目盛です。ご注意下さい。)
グラフをざっと読んで約200バイトを超えるとC++のほうが高速ですが、それ未満の場合C#の方が速く、10バイトくらいですと4~5倍の差が開いてます。
元々C++で高速処理が必要なループ内でnew/deleteすることは無いとは思いますが、もしどうしてもそれが必要な時はC#の方が高速そうです。(他にガベージコレクションの影響が有る筈ですので状況によります。)
C++のソース:
void getMemory(int iCount)
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
std::unique_ptr<byte[]> aArray(new byte[iCount]);
for (int i=0; i < iCount; ++i)
{
aArray[i] = static_cast<byte>(i);
}
}
}
C#マネージドのソース:
static void getMemoryManaged(int iCount)
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
byte[] aArray = new byte[iCount];
for (int i=0; i < iCount; ++i)
{
aArray[i] = (byte)i;
}
}
}
C#アンセーフのソース:
unsafe static void getMemoryUnsafe(int iCount)
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
byte[] aArray = new byte[iCount];
fixed (byte* aArrayFixed = aArray)
{
byte* aArrayFixed2 = aArrayFixed;
for (int i=0; i < iCount; ++i)
{
aArrayFixed2[i] = (byte)i;
}
}
}
}
4. 単純処理
単に10,000,000回のループを回して処理時間を計測しました。
-
volatile変数へ設定
最適化でループの外に追い出されるのを回避するため、Volatileメモリへ設定しています。C#の方が高速ですが微差です。 -
通常変数へ設定
ループ最適化されるかどうかを比較するため、1つだけ通常のメモリへ設定してみました。C++は最適化によりループが消えてしまいました。C#はそのような最適化はされないようです。 -
i^j計算とi%10計算
作業途中で剰余を使うとC#が遅くなることに気がついたので、元サイトで使っている排他的論理和(i^j)と剰余(i%10)の処理時間を比較してみました。
C++の方が高速です。(i^j)は微差ですが(i%10)はそこそこ差がつきました。 -
インライン展開
インライン展開はinline指定せず最適化による自動展開の有無を計測しています。残念ながらC#は最適化では展開されないようです。C++の方が大幅に高速です。 -
文字列を1文字づつ増やす(最大100文字)
文字列処理もちょっと気になったので比較してみました。1文字づつ増やして最大100文字まで増やす処理です。
C++は小メモリ獲得が遅いためC++の方が遅いと予想したのですが、意外にC++の方が大幅に高速でした。文字列処理に大幅な速度差があるのかも知れません。
| 番号 | タイトル | 概要 | C++ | C# |
|---|---|---|---|---|
| 1. | initialize volatile memory. | volatile変数へ設定 | 410 | 402 |
| 2. | initialize non-volatile memory. | 通常変数へ設定 | 0 | 402 |
| 3. | calculation(i^j). | i^j計算 | 596 | 600 |
| 3. | calculation(i%10). | i%10計算 | 1,267 | 1,651 |
| 4. | inline expansion. | インライン展開 | 406 | 5,660 |
| 5. | modify string. | 文字列を1文字づつ増やす(最大100文字) | 7,764 | 29,982 |
1.「volatile変数へ設定」のソース
// C++
void initVolatile()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i;
}
}
}
// C#
static void initVolatile()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i;
}
}
}
2.「通常変数へ設定」のソース
// C++
void initNonVolatile()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sNonVolatileInt = i;
}
}
}
// C#
static void initNonVolatile()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sNonVolatileInt = i;
}
}
}
3.「i^j計算とi%10計算」のソース
// C++
void calculate1()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i ^ j;
}
}
}
void calculate2()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i % 10;
}
}
}
// C#
static void calculate1()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i ^ j;
}
}
}
static void calculate2()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = i % 10;
}
}
}
4.「インライン展開」のソース
// C++
int sumNormal(int x)
{
int ret=0;
for (int i = 0; i < x; ++i) ret += i;
return ret;
}
void inlineExpansion()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = sumNormal(10);
}
}
}
// C#
static int sumNormal(int x)
{
int ret=0;
for (int i = 0; i < x; ++i) ret += i;
return ret;
}
static void inlineExpansion()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = sumNormal(10);
}
}
}
5.「文字列を1文字づつ増やす(最大100文字)」のソース
// C++
void modifyString()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
std::string aString = "";
for (int i=0; i < kCount0i; ++i)
{
aString += "x";
}
}
}
// C#
static void modifyString()
{
int aCount = kCount0o/sFactor;
for (int j=0; j < aCount; ++j)
{
String aString = "";
for (int i=0; i < kCount0i; ++i)
{
aString += "x";
}
}
}
5. クラス・インスタンス生成
double型メンバ2つのみ持つComplexクラスをローカル変数としてコンストラクトしメンバ変数読み出しで比較しました。
C#でスタックに獲得するにはかなり特殊なことをするしかなく一般にヒープから獲得するのでヒープを使いました。
C++は一般にスタックに獲得するのでスタック変数としています。比較のためヒープからも獲得してみていますが、予想通り非常に遅いです。
| タイトル | 言語 | 結果 |
|---|---|---|
| construct on stack & read member. | C++ | 407 |
| construct & read member. | C# | 4,633 |
| construct on heap & read member. | C++ | 54,610 |
C++のソース:
// テスト用のクラス
class Complex
{
double mReal;
double mImaginary;
public:
Complex() : mReal(1.0), mImaginary(0.1) { }
double getReal() { return mReal; }
void setReal(double value) { mReal = value; }
double getImaginary() { return mImaginary; }
void setImaginary(double value) { mImaginary = value; }
};
// コンストラクト(stack)
void constuctStack()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
Complex temp;
sVolatileInt = static_cast<int>(temp.getReal());
}
}
}
// コンストラクト(heap)
void constuctHeap()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
std::unique_ptr<Complex> temp(new Complex);
sVolatileInt = static_cast<int>(temp->getReal());
}
}
}
C#のソース:
// テスト用のクラス
class Complex
{
private double mReal;
private double mImaginary;
public Complex() { mReal = 1.0; mImaginary = 0.1; }
public double Real
{
get { return mReal; }
set { mReal = value; }
}
public double Imaginary
{
get { return mImaginary; }
set { mImaginary = value; }
}
}
// コンストラクト
static void constuct()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
var temp = new Complex();
sVolatileInt = (int)temp.Real;
}
}
}
6. ジェネリック関数、関数テンプレート処理
ジェネリック関数と関数テンプレートはC#とC++の同等な機能です。単純な2変数のmax()関数について比較してみました。比較のため非ジェネリック、非テンプレートのint型処理max()関数も測定しています。
なお、string型は最適化を防止するため、ループ変数のi, jを文字列へ変換後、辞書順比較して、結果をint型へ戻してます。ですので、ジェネリック/テンプレート処理だけでなく数値と文字列変換時間も含まれています。
| タイトル | C++ | C# |
|---|---|---|
| normal(int). | 694 | 894 |
| template(int)./generics(int). | 652 | 8,936 |
| template(double)./generics(double). | 890 | 9,446 |
| template(string)./generics(string). | 50,332 | 357,398 |
C++のソース:
// テスト用の通常関数
int maxInt(int iLhs, int iRhs)
{
return (iLhs > iRhs)?iLhs:iRhs;
}
// テスト用の関数テンプレート
template<typename tType>
tType const& max(tType const& iLhs, tType const& iRhs)
{
return (iLhs > iRhs)?iLhs:iRhs;
}
// 通常関数
void normalInt()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = maxInt(i, j);
}
}
}
// int型
void genericsInt()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = max<int>(i, j);
}
}
}
// double型
void genericsDouble()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = static_cast<int>(max<double>(i, j));
}
}
}
// string型
void genericsString()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt =
std::atoi(::max<std::string>(std::to_string(i), std::to_string(j)).c_str());
}
}
}
C#のソース:
// テスト用の通常メソッド
static int maxInt(int iLhs, int iRhs)
{
return (iLhs > iRhs)?iLhs:iRhs;
}
// テスト用のジェネリック・メソッド
static Type max<Type>(Type iLhs, Type iRhs) where Type : IComparable
{
return (iLhs.CompareTo(iRhs) > 0)?iLhs:iRhs;
}
// 通常関数
static void normalInt()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = maxInt(i, j);
}
}
}
// int型
static void genericsInt()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = max<int>(i, j);
}
}
}
// double型
static void genericsDouble()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt = (int)max<double>(i, j);
}
}
}
// string型
static void genericsString()
{
for (int j=0; j < kCount0o/sFactor; ++j)
{
for (int i=0; i < kCount0i; ++i)
{
sVolatileInt =
int.Parse(max<String>(i.ToString(), j.ToString()));
}
}
}
7. 特記事項
検証していてC#側は結果がなかなか安定せずたいへんでした。他のテストも纏めてテストしているのですが、テストを追加していくと、何も修正していない別のテストが遅くなることが時々あります。1つの関数を大きくしない方が安定する傾向があったため、現在はかなり細切れにすることでできるだけC#側で良い結果が出る状況でテストしています。
C++ではそのような不安定さには気が付きませんでした。
8. まとめ
意外にC#は検討しています。巷で言われているようにC#がC++を凌駕している部分も確かにありました。特に顕著な差があるのは小サイズのメモリ獲得(new)です。しかし、それはC++で高速処理を書く際には一般に避ける使い方です。逆にC#がC++より遅い部分をC#の世界だけで回避するのは現実的ではなさそうです。
また、C#は比較的頻繁に他の部分のソース修正の影響を受けて修正していない関数の処理時間が変わってしまうため、C#で高速に計算処理するプログラムを追求するのはかなり苦労しそうです。
更に、今回、ガベージコレクションを積極的には発生させていません。メモリ使用後、直ぐに参照を外しているため、重たいコンパクションは発生していない筈です。
マイクロソフトはGarbage Collection Notificationsにて記述していますが、サーバ側でガベージコレクションが発生すると最悪クライアントにてタイムアウトする。GCが近づいたことの通知を受け取って他のサーバへ処理をリダイレクトすることができる旨を記載しています。この影響については計測できていません。
やはりC#は処理速度よりプログラムの開発生産性を上げる方を優先した言語です。生産性を優先しているとはいえ十分高速ですから、CPUをぶん回すような処理ではなくGUI周辺や他のコンピュータとの通信処理、データベース処理等を記述するにはたいへん優れた言語と思います。
そして、CPUをぶん回す必要がある処理はC++で記述し、それ以外の部分をC#で開発することで高速性と納期のバランスを取れるのは良い選択の1つと思います。
【補足】
C++とC#の組み合わせだけに言及していますが、実際には他の組み合わせも当然有りえます。可能であれば、JavaとC++の比較もしてみたいのですが、私はJavaの使用経験がほとんどないので適切な評価を行うのはちょっと難しいのです。
9. おまけ
C++はマルチプラットフォームでビルド出来るようにしてますので、MinGW 5.4.0とgcc
5.4.0でも走らせてみました。なお、gccは上記Windows 10上のVirtualBoxにインストールしたubuntu 16.04にてテストしました。おまけなので100回ではなく3回の平均です。
また、最適化オプションはCMAKE_BUILD_TYPE=ReleaseにてCMakeにお任せし、64ビットのコンパイラにてビルドしています。
| タイトル | 概要 | VC++ | MinGW | gcc |
|---|---|---|---|---|
| set to large array[test2() of site1]. | 元サイトの再現確認 | 1622 | 523 | 619 |
| set to large array. | 上記の微修正 | 1,615 | 510 | 602 |
| get 10bytes memory & setup. | 10バイト獲得と設定 | 575 | 578 | 386 |
| get 100bytes memory & setup. | 100バイト獲得と設定 | 936 | 758 | 531 |
| get 1000bytes memory & setup. | 1,000バイト獲得と設定 | 3,450 | 2,285 | 2,229 |
| get 10000bytes memory & setup. | 10,000バイト獲得と設定 | 29,995 | 17,247 | 17,982 |
| get 100000bytes memory & setup. | 100,000バイト獲得と設定 | 303,502 | 164,666 | 175,067 |
| get 1000000bytes memory & setup. | 1,000,000バイト獲得と設定 | 3,088,057 | 1,562,627 | 1,770,650 |
| get 10000000bytes memory & setup. | 10,000,000バイト獲得と設定 | 50,441,143 | 36,461,133 | 18,817,067 |
| initialize volatile memory. | volatile変数へ設定 | 410 | 407 | 487 |
| initialize non-volatile memory. | 通常変数へ設定 | 0 | 0 | 0 |
| calculation(i^j). | i^j計算 | 596 | 661 | 812 |
| calculation(i%10). | i%10計算 | 1,267 | 1,686 | 1,878 |
| inline expansion. | インライン展開 | 406 | 396 | 460 |
| modify string. | 文字列を1文字づつ増やす(最大100文字) | 7,764 | 6,771 | 7,537 |
| construct on stack & read member. | クラスをスタックに獲得 | 407 | 406 | 477 |
| construct on heap & read member. | クラスをヒープに獲得 | 54,610 | 51,567 | 30,196 |
| normal(int). | 通常関数(int) | 694 | 707 | 916 |
| template(int). | テンプレート(int) | 652 | 669 | 891 |
| template(double). | テンプレート(double) | 890 | 875 | 1,008 |
| template(string). | テンプレート(string) | 50,332 | 146,049 | 213,358 |
MinGW/gccの大量メモリ設定が高速なようですが、恐らくこれはループのオーバーヘッドが少ないのだろうと思います。
gccはMinGWより遅いように見えますがVirtualBoxで動作している影響があるかもしれません。その中で小メモリ獲得と設定性能が優れています。C#に迫る勢いですね。
10.おまけ2
調査中にThe Computer Language Benchmarks Gameを見つけました。
様々な言語で様々なアルゴリズムの性能比較をしています。4コアのコンピュータにてマルチスレッド環境でテストしています。