セ・リーグ編に続きパ・リーグ編も分析してみようと思う。
以下手順
1.プロ野球パリーグチーム別の直近3年間の得点数と失点数の平均を取得する。
2.x軸に得点数、y軸に失点数*(-1)の2次元グラフを作成する。
3.その散らばりを偏差値 - 50 の値で球団同士の無向グラフとして描画する。
実行環境:Google Colaratory
使用テキストファイル1:network2.txt(各球団の標準偏差)
使用テキストファイル2:coord2.txt(各球団の[得点数偏差値,失点数偏差値]の座標)
上記2種類のテキストファイル
以下コード
データフレーム作成
import pandas as pd
''' データフレームを制作(順に2020,2021,2022)
list1= [[オリックス得点],[ソフトバンク得点],[西武得点],[楽天得点],[ロッテ得点],[日本ハム得点],
[オリックス失点],[ソフトバンク失点],[西武失点],[楽天失点],[ロッテ失点],[日本ハム失点]]'''
list1=[[442,551,490], [531,564,555], [479,521,464], [557,532,533], [461,584,501], [493,454,463],
[502,500,458], [389,493,471], [543,589,448], [522,507,522], [479,570,536], [528,515,534]]
columns1 = ["2020", "2021", "2022"]
index1 = ["オリックス得点", "ソフトバンク得点", "西武得点","楽天得点","ロッテ得点","日本ハム得点","オリックス失点","ソフトバンク失点","西武失点","楽天失点","ロッテ失点","日本ハム失点"]
base = pd.DataFrame(data=list1, index=index1, columns=columns1)
base["平均"] = round((base["2020"] + base["2021"] + base["2022"]) / 3, 0)
# 攻撃平均と守備平均
Kougeki = base[:6]
Syubi = base[6:]
team = ['オリックス', 'ソフトバンク', '西武', '楽天', 'ロッテ', '日本ハム']
Kougekilist = []
Syubilist = []
# 攻撃・守備別にリストを定義
print(' 球団 得点平均 失点平均')
for x in range(6):
print(team[x], Kougeki['平均'][x], ',' , Syubi['平均'][x])
Kougekilist.append(Kougeki['平均'][x])
Syubilist.append(Syubi['平均'][x])
base
〜〜出力結果〜〜
球団 得点平均 失点平均
オリックス 494.0 , 487.0
ソフトバンク 550.0 , 451.0
西武 488.0 , 527.0
楽天 541.0 , 517.0
ロッテ 515.0 , 528.0
日本ハム 470.0 , 526.0
得点数の偏差値換算
import pandas as pd
''' データフレームを制作(順に2020,2021,2022)
list1= [[オリックス得点],[ソフトバンク得点],[西武得点],[楽天得点],[ロッテ得点],[日本ハム得点],
[オリックス失点],[ソフトバンク失点],[西武失点],[楽天失点],[ロッテ失点],[日本ハム失点]]'''
list1=[[442,551,490], [531,564,555], [479,521,464], [557,532,533], [461,584,501], [493,454,463],
[502,500,458], [389,493,471], [543,589,448], [522,507,522], [479,570,536], [528,515,534]]
columns1 = ["2020", "2021", "2022"]
index1 = ["オリックス得点", "ソフトバンク得点", "西武得点","楽天得点","ロッテ得点","日本ハム得点","オリックス失点","ソフトバンク失点","西武失点","楽天失点","ロッテ失点","日本ハム失点"]
base = pd.DataFrame(data=list1, index=index1, columns=columns1)
base["平均"] = round((base["2020"] + base["2021"] + base["2022"]) / 3, 0)
# 攻撃平均と守備平均
Kougeki = base[:6]
Syubi = base[6:]
team = ['オリックス', 'ソフトバンク', '西武', '楽天', 'ロッテ', '日本ハム']
Kougekilist = []
Syubilist = []
# 攻撃・守備別にリストを定義
print(' 球団 得点平均 失点平均')
for x in range(6):
print(team[x], Kougeki['平均'][x], ',' , Syubi['平均'][x])
Kougekilist.append(Kougeki['平均'][x])
Syubilist.append(Syubi['平均'][x])
base
〜〜出力結果〜〜
球団 得点平均 失点平均
オリックス 494.0 , 487.0
ソフトバンク 550.0 , 451.0
西武 488.0 , 527.0
楽天 541.0 , 517.0
ロッテ 515.0 , 528.0
日本ハム 470.0 , 526.0
失点数の偏差値換算
# 得点数の偏差値
import numpy as np
team = ['オリックス', 'ソフトバンク', '西武', '楽天', 'ロッテ', '日本ハム']
scores = Kougekilist
np_scores = np.array(scores)
#numpy.mean 算術平均
mean = np.mean(np_scores)
#numpy.std 標準偏差
std = np.std(np_scores)
K = []
print('得点数偏差値換算')
for x in range(6):
score_a = Kougekilist[x]
#(得点 - 平均点) / 標準偏差
deviation = (score_a - mean) / std
#今回は偏差値 - 50をする
deviation_value = 0 + deviation * 10
K.append(round(deviation_value))
print(team[x],"偏差値:"+str(round(deviation_value)))
〜〜出力結果〜〜
オリックス 偏差値:-5
ソフトバンク 偏差値:14
西武 偏差値:-8
楽天 偏差値:11
ロッテ 偏差値:2
日本ハム 偏差値:-14
得点数、失点数の偏差値座標
team = ['オリックス', 'ソフトバンク', '西武', '楽天', 'ロッテ', '日本ハム']
for v in range(6):
print(team[v],'の座標は',str(K[v]),',',str(-S[v]))
〜〜出力結果〜〜
オリックス の座標は -5 , 7
ソフトバンク の座標は 14 , 19
西武 の座標は -8 , -7
楽天 の座標は 11 , -4
ロッテ の座標は 2 , -8
日本ハム の座標は -14 , -7
座標同士の距離
import numpy as np
# 各ノード間の距離を求める
for x in range(6):
# 被り排除
for n in range(x+1,6,1):
a=np.array([K[x],S[x]])
b=np.array([K[n],S[n]])
distance=np.linalg.norm(b-a)
if team[x] == team[n]:
pass
else:
print(team[x],'と',team[n],'の座標距離は',round(distance))
〜〜出力結果〜〜
オリックス と ソフトバンク の座標距離は 22
オリックス と 西武 の座標距離は 14
オリックス と 楽天 の座標距離は 19
オリックス と ロッテ の座標距離は 17
オリックス と 日本ハム の座標距離は 17
ソフトバンク と 西武 の座標距離は 34
ソフトバンク と 楽天 の座標距離は 23
ソフトバンク と ロッテ の座標距離は 30
ソフトバンク と 日本ハム の座標距離は 38
西武 と 楽天 の座標距離は 19
西武 と ロッテ の座標距離は 10
西武 と 日本ハム の座標距離は 6
楽天 と ロッテ の座標距離は 10
楽天 と 日本ハム の座標距離は 25
ロッテ と 日本ハム の座標距離は 16
ライブラリのインストール
!pip install japanize_matplotlib
# 実行後にランタイム再起動する
# 「IPA」フォントをインストール
!apt-get -y install fonts-ipafont-gothic
# matplotlibのキャッシュをクリア
!rm /root/.cache/matplotlib/fontlist-v300.json
ネットワーク環境と2つのテキストファイルの読み込み
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
# colabratory上でgoogle driveとマウント
from google.colab import drive
drive.mount('/content/drive')
# 無向グラフの作成
G = nx.Graph()
G = nx.read_weighted_edgelist('/content/drive/MyDrive/Colab Notebooks/DataMining/Assignment/network2.txt', nodetype=str)
pos_array=np.loadtxt('/content/drive/MyDrive/Colab Notebooks/DataMining/Assignment/coord2.txt', dtype='int32')
pos = {}
# ndarrayの情報を「(x,y)」という値に変換する
for n, c in zip(list(G.nodes), pos_array):
pos[n] = (c[0], c[1])
グラフ描画
import matplotlib.pyplot as plt
import japanize_matplotlib
fig = plt.figure(dpi=120)
edge_labels = {(i, j): w['weight'] for i, j, w in G.edges(data=True)}
nx.draw_networkx_nodes(G, pos, node_size=400) #ノードを描画
nx.draw_networkx_edges(G, pos, width=2) #エッジを描画
nx.draw_networkx_labels(G, pos, font_family='IPAexGothic') #(ノードの)ラベルを描画
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels) #エッジのラベルを描画
plt.xlabel("← 少ない 得点数 多い →")
plt.ylabel("← 多い 失点数 少ない →")
plt.title("チーム別直近3年間の得点数と失点数")
plt.show()
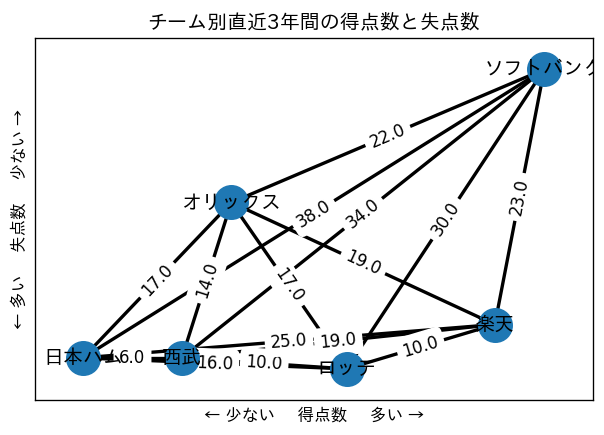
結果と分析
- ソフトバンクが得点数、失点数共に圧倒的である。
- ロッテは2020年,2021年と2位なのにも関わらず失点数がワーストという結果であり、得点数もそこまで多くないことからロッテの負け試合は大量得点差で負けることが多いのではないか
- 日本ハムはまずそう
- セ・リーグのグラフと比較して右上がりグラフの傾向にあることから得点数の多いチームは失点数が少ない傾向にあり、ばらつきが大きい。