当記事ではBEVFormerの論文の解説についてまとめました。
先に確認しておくと良い論文
Deformable Convolution
Deformable Convolutionは一般的にはgridなどで表される近傍の位置(ピクセルなど)に基づいて行われる畳み込み演算の参照位置を動的に変化させる手法です。
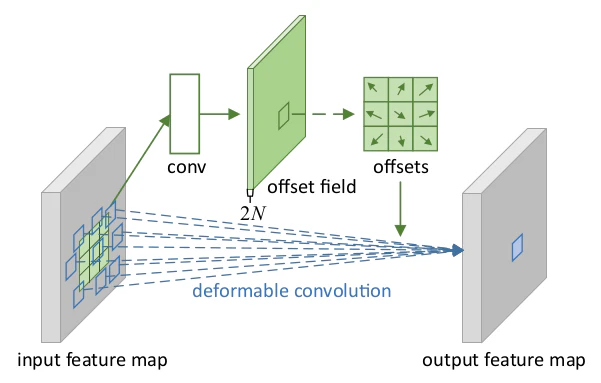
Deformable Convolution論文 Figure.2
Deformable Convolutionの処理の概要は上図を元に確認すると良いと思います。以下、論文の数式を元に計算の詳細を確認します。
まず、gridの$\mathcal{R}$を下記のように定義します。
\begin{align}
\mathcal{R} = \{ (-1,-1), (-1, 0), (-1, 1), (0, -1), (0, 0), (0, 1), (1, -1), (1, 0), (1, 1) \}
\end{align}
上記は一般的な$3 \times 3$の畳み込みに対応します。次にlocation$\mathbf{p}_{0} \in \mathbb{R}^{2}$における畳み込み演算を下記のように定義します。
\begin{align}
\mathbf{y}(\mathbf{p}_{0}) = \sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}(\mathbf{p}_{0}) \cdot \mathbf{x}(\mathbf{p}_{0} + \mathbf{p}_{n})
\end{align}
このときオフセット項の$\Delta \mathbf{p}_{n} \in \mathbb{R}^{2}$を元にDeformable Convolutionは下記のように定義されます。
\begin{align}
\mathbf{y}(\mathbf{p}_{0}) = \sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}(\mathbf{p}_{0}) \cdot \mathbf{x}(\mathbf{p}_{0} + \mathbf{p}_{n} + \Delta \mathbf{p}_{n})
\end{align}
ここで用いられるオフセット項の$\Delta \mathbf{p}_{n}$は下図の(b)〜(d)のように畳み込み演算を行う際に参照する位置を変化させると大まかに理解しておくと良いと思います。
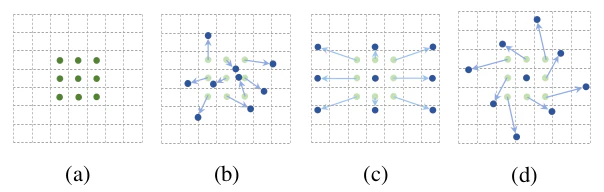
Deformable Convolution論文 Figure.1
Deformable DETR
DeformableDETRはDETRの計算量の改善にあたってDeformable Convolutionを参考にAttention処理を構築した研究です。
\begin{align}
\mathrm{MultiHeadAttention}(\mathbf{z}_{q}, \mathbf{x}) &= \sum_{m=1}^{M} \mathbf{W}_{m} \left[ \sum_{k \in \Omega_{k}} A_{mqk} \cdot \mathbf{W}_{m}' \mathbf{x}_{k} \right] \\
A_{mqk} & \propto \exp{ \left[ \frac{\mathbf{z}_{q}^{\mathrm{T}} \mathbf{U}_{m}^{\mathrm{T}} \mathbf{V}_{m} \mathbf{x}_{k}}{\sqrt{C_{v}}} \right] } \\
\sum_{k \in \Omega_{k}} A_{mqk} &= 1 \\
\mathbf{W}_{m}' & \in \mathbb{R}^{C_v \times C}, \, \mathbf{W}_{m} \in \mathbb{R}^{C \times C_v} \\
\mathbf{U}_{m}, \mathbf{V}_{m} & \in \mathbb{R}^{C_v \times C} \\
C_{v} &= \frac{C}{M}
\end{align}
Deformable Attentionの処理は上記のMultiHeadAttentionの処理の記法に基づいて下記のように定義されます。
\begin{align}
\mathrm{DeformAttention}(\mathbf{z}_{q}, \mathbf{p}_{q}, \mathbf{x}) &= \sum_{m=1}^{M} \mathbf{W}_{m} \left[ \sum_{k=1}^{K} A_{mqk} \cdot \mathbf{W}_{m}' \mathbf{x} (\mathbf{p}_{q} + \Delta \mathbf{p}_{mqk}) \right] \\
\mathbf{x} & \in \mathbb{R}^{C \times H \times W}
\end{align}
ここで上記の$K$を$K << HW$となるように定めることでDeformable DETRではDETRの処理から計算量を削減することができます。
BEVFormerの論文の確認
BEVFormerの処理の概要
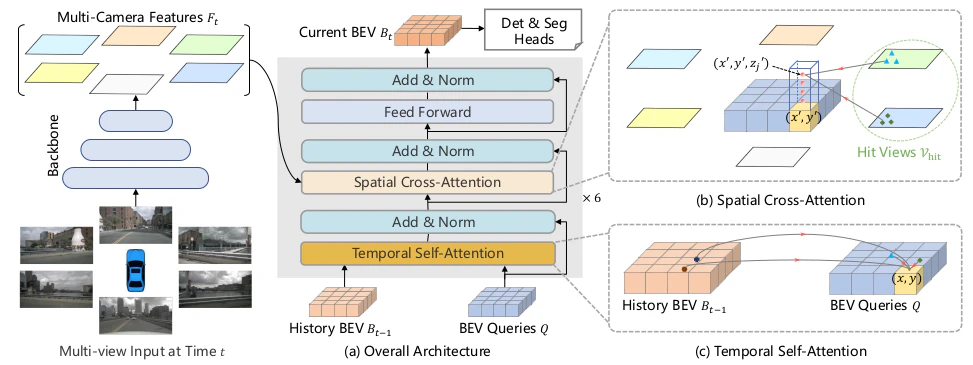
BEVFormer論文 Figure.2
BEVQueriesとSpatial Cross-Attention
Spatial Cross-Attention(SCA)の処理は下記のような数式で定義されます。
\begin{align}
\mathrm{SCA}(Q_{p}, F_{t}) &= \frac{1}{|\mathcal{V}_{\mathrm{hit}}|} \sum_{i \in \mathcal{V}_{\mathrm{hit}}} \sum_{j=1}^{N_{\mathrm{ref}}} \mathrm{DeformAttention} \left( Q_{p}, \mathcal{P}(p, i, j), F_{t}^{i} \right) \\
\mathrm{DeformAttention}(q, p, x) &= \sum_{i=1}^{N_{\mathrm{head}}} \mathcal{W}_{i} \sum_{j=1}^{N_{\mathrm{key}}} A_{ij} \cdot \mathcal{W}_{i}' x(p + \Delta p_{ij})
\end{align}
Spatial Cross-Attentionには前節で取り扱ったDeformable Attentionの処理が用いられています。一般的なTransformerにおけるMulti Head Attentionの処理とやや異なる表記が用いられていますが、「$A_{ij}$がQueryとKeyから作られるAttention Matrixの要素であること」と「$x(p + \Delta p_{ij})$がValueに対応すること」に着目することでオーソドックスなTransformerにおける数式と対応付けることができます。Spatial Cross-AttentionではこのDeformable Attentionをhit views(計算に用いる特徴マップ)とreference points(確認する点)の数だけ計算しそれぞれの和を計算します。
| 文字 | 解釈 |
|---|---|
| $Q_{p} \in \mathbb{R}^{1 \times C}$ | 点$p$におけるBEV queriesの$Q \in \mathbb{R}^{H \times W \times C}$のベクトル(SCA) |
| $F_{t}$ | 時点$t$における特徴量マップ(SCA) |
| $F_{t}^{i}$ | 時点$t$における$i$番目の特徴マップ(SCA) |
| $\mathcal{V}_{\mathrm{hit}}$ | 用いる特徴マップのインデックスの集合(SCA) |
| $N_{\mathrm{ref}}$ | reference points(Attention処理を行うにあたって計算に用いる点)の数(SCA) |
| $\mathcal{P}(p, i, j)$ | 位置$p$のSCAの計算にあたって用いる$i$番目の画像(view image)の$j$番目の参照点(reference points)(SCA) |
出てくる文字が多いのでそれぞれの文字の解釈については上記にまとめました。Deformableの処理ではreference pointsの$\mathcal{P}(p, i, j)$の取得にあたってオーソドックスなgridによる処理とは異なる処理が用いられるので以下ではreference pointsに関する処理について詳しく確認します。
\begin{align}
x' &= \left( x - \frac{W}{2} \right) \times s \\
y' &= \left( y - \frac{H}{2} \right) \times s \\
p &= (x, y)
\end{align}
まず位置$p=(x,y)$に対し、上記のように$x', y'$を計算します。この$x', y'$に$z$の値を与えるアンカー(anchor heights)の$z_{j}'$を用意し、下記のような計算でBird's Eye Viewにおける3Dの位置の$(x', y', z_{j}')$をそれぞれの画像に投影します。
\begin{align}
\mathcal{P}(p, i, j) &= (x_{ij}, y_{ij}) \\
z_{ij} \cdot \left(\begin{array}{c} x_{ij} \\ y_{ij} \\ 1 \end{array} \right) &= T_{i} \cdot \left(\begin{array}{c} x' \\ y' \\ z_{j}' \\ 1 \end{array} \right)
\end{align}
このような処理を行うことで鳥瞰図(Bird's Eye View)からそれぞれの画像を参照し、特徴量についてAttention処理を行うことが可能になります。
Temporal Self-Attention
\begin{align}
\mathrm{TSA}(Q_{p}, \{ Q, B_{t-1}' \}) = \sum_{V \in \{ Q, B_{t-1}' \}} \mathrm{DeformAttention}(Q_{p}, p, V)
\end{align}
Temporal Self-Attentionは上記のようにBEV Queriesの$Q$とhistory BEV featuresの$B_{t-1}$について行う処理です。この処理を入れることで直前の状態も参考に鳥瞰図を作成することができます。
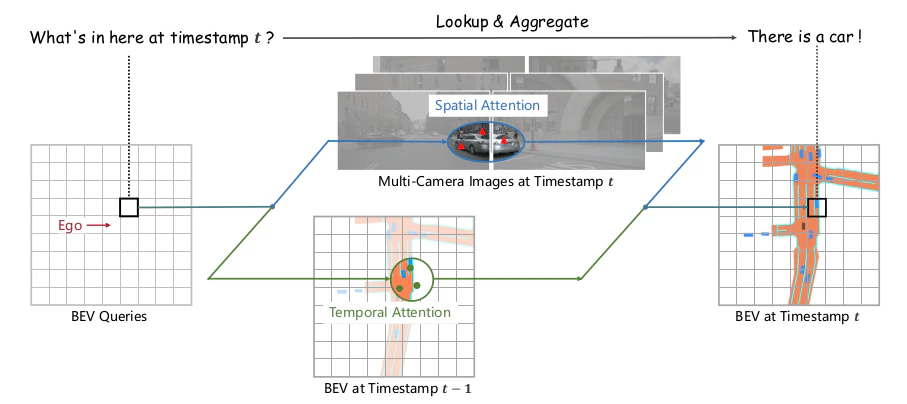
BEVFormer論文 Figure.1