前提の確認
PyTorch Geometricのインストール
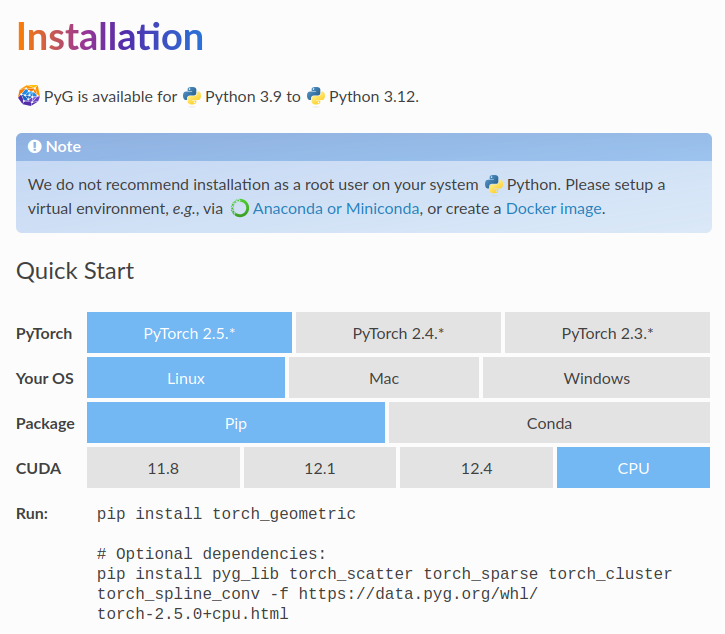
PyTorch Geometricのインストールにあたっては上記に基づいて行えば良いです。OSやCUDAのバージョンなどによってコマンドが変わるので、注意して確認した上でインストールを行うと良いと思います。
CSVファイルの入手と表示
当記事では上記に基づいてPyTorch Geometricの用法の確認を行うにあたって、MovieLens datasetを用います。MovieLens datasetは下記を実行することで入手と表示が可能です。
from torch_geometric.data import download_url, extract_zip
import pandas as pd
url = 'https://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
extract_zip(download_url(url, '.'), '.')
movie_path = './ml-latest-small/movies.csv'
rating_path = './ml-latest-small/ratings.csv'
df_movie = pd.read_csv(movie_path)
df_rating = pd.read_csv(rating_path)
print(df_movie.head())
print(df_rating.head())
・実行結果
| movieId | title | genres |
|---|---|---|
| 1 | Toy Story (1995) | Adventure |
| 2 | Jumanji (1995) | Adventure |
| 3 | Grumpier Old Men (1995) | Comedy |
| 4 | Waiting to Exhale (1995) | Comedy |
| 5 | Father of the Bride Part II (1995) | Comedy |
| userId | movieId | rating | timestamp |
|---|---|---|---|
| 1 | 1 | 1 | 964982703 |
| 2 | 1 | 3 | 964981247 |
| 3 | 1 | 6 | 964982224 |
| 4 | 1 | 47 | 964983815 |
| 5 | 1 | 50 | 964982931 |
CSVファイルからのグラフの構築
SequenceEncoderクラスとGenresEncoderクラスの実装
import torch
from sentence_transformers import SentenceTransformer
class SequenceEncoder:
def __init__(self, model_name='all-MiniLM-L6-v2', device=None):
self.device = device
self.model = SentenceTransformer(model_name, device=device)
@torch.no_grad()
def __call__(self, df):
x = self.model.encode(df.values, show_progress_bar=True,
convert_to_tensor=True, device=self.device)
return x.cpu()
class GenresEncoder:
def __init__(self, sep='|'):
self.sep = sep
def __call__(self, df):
genres = set(g for col in df.values for g in col.split(self.sep))
mapping = {genre: i for i, genre in enumerate(genres)}
x = torch.zeros(len(df), len(mapping))
for i, col in enumerate(df.values):
for genre in col.split(self.sep):
x[i, mapping[genre]] = 1
return x
ノードの読み込み(load_node_csv)
ノードの読み込みにあたっては下記のようにload_node_csv関数を実装すれば良いです。
import torch
def load_node_csv(path, index_col, encoders=None, **kwargs):
df = pd.read_csv(path, index_col=index_col, **kwargs)
mapping = {index: i for i, index in enumerate(df.index.unique())}
x = None
if encoders is not None:
xs = [encoder(df[col]) for col, encoder in encoders.items()]
x = torch.cat(xs, dim=-1)
return x, mapping
movie_path = './ml-latest-small/movies.csv'
rating_path = './ml-latest-small/ratings.csv'
movie_x, movie_mapping = load_node_csv(
movie_path, index_col='movieId', encoders={
'title': SequenceEncoder(),
'genres': GenresEncoder()
})
_, user_mapping = load_node_csv(rating_path, index_col='userId')
print(type(movie_x))
print(movie_x.shape)
print(type(movie_mapping))
print(len(movie_mapping))
print(type(user_mapping))
print(len(user_mapping))
・実行結果
<class 'torch.Tensor'>
torch.Size([9742, 404])
<class 'dict'>
9742
<class 'dict'>
610
上記の実行結果は「movie.csvのmovieIdが1〜9742、ratings.csvのuserIdが1〜610であること」と対応させながら確認すると良いと思います。
エッジの読み込み(load_edge_csv)
エッジの読み込みにあたっては下記のようにload_edge_csv関数を実装すれば良いです。
from torch_geometric.data import HeteroData
def load_edge_csv(path, src_index_col, src_mapping, dst_index_col, dst_mapping,
encoders=None, **kwargs):
df = pd.read_csv(path, **kwargs)
src = [src_mapping[index] for index in df[src_index_col]]
dst = [dst_mapping[index] for index in df[dst_index_col]]
edge_index = torch.tensor([src, dst])
edge_attr = None
if encoders is not None:
edge_attrs = [encoder(df[col]) for col, encoder in encoders.items()]
edge_attr = torch.cat(edge_attrs, dim=-1)
return edge_index, edge_attr
data = HeteroData()
data['user'].num_nodes = len(user_mapping) # Users do not have any features.
data['movie'].x = movie_x
print(data)
edge_index, edge_label = load_edge_csv(
rating_path,
src_index_col='userId',
src_mapping=user_mapping,
dst_index_col='movieId',
dst_mapping=movie_mapping,
encoders={'rating': IdentityEncoder(dtype=torch.long)},
)
data['user', 'rates', 'movie'].edge_index = edge_index
data['user', 'rates', 'movie'].edge_label = edge_label
print(data)
・実行結果
HeteroData(
user={ num_nodes=610 },
movie={ x=[9742, 404] }
)
HeteroData(
user={ num_nodes=610 },
movie={ x=[9742, 404] },
(user, rates, movie)={
edge_index=[2, 100836],
edge_label=[100836, 1],
}
)
上記の実行結果のedge_index=[2, 100836]はratings.csvのレコードの数が100,836であることと対応させながら理解すると良いです。