pythonを使ってリサンプリングによる並べ替え検定を行い、データに有意な差があるかを検証してみる
今回想定する事例
-
とある二つのwebページがありそれぞれクリック数とサイトの訪問時間を測定したデータを仮定する。この二つのwebページのどちらが売り上げに寄与しているか調べたい。
-
データはcsvファイルで、以下のような記述となっている。
Page , Time
PageA, 0.21
PageB, 2.53
:
PageA, 0.93 -
今回、ページAが21、Bが15の合計36セッションであったので、これらを
並べ替え検定
(すべての時間を一緒にまとめ繰り返しシャッフルしてA:21個、B:15個の2つのグループに分け、その時の平均値の差を算出)
によって差があるかを調べる。
データの可視化(箱ひげ図)
まずは、どのようなデータになっているかを可視化しておく
from pathlib import Path
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
#データを扱いやすい形に変換しておく
try:
import common
DATA = common.dataDirectory()
except ImportError:
DATA = Path().resolve() / 'data'
WEB_PAGE_DATA_CSV = DATA / 'web_page_data.csv'
# ファイルの読み込み
session_times = pd.read_csv(WEB_PAGE_DATA_CSV)
session_times.Time = 100 * session_times.Time
# 箱ひげ図の作成
ax = session_times.boxplot(by='Page', column='Time',
figsize=(4, 4))
ax.set_xlabel('Page')
ax.set_ylabel('Time (in seconds)')
plt.suptitle('')
plt.tight_layout()
plt.show()
実行結果
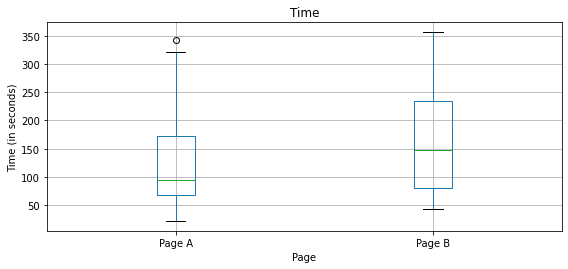
図では、Bのほうが閲覧時間が長くより良いwebページに見えるがこれだけではまだよくわからない
平均値と平均の差を算出
箱ひげ図だけでは、差が有意かどうかわからなかったので、平均値の差が偶然なものかどうかを確かめる必要性が出てきた。そこでまず平均値の差を求める。
mean_a = session_times[session_times.Page == 'Page A'].Time.mean()
mean_b = session_times[session_times.Page == 'Page B'].Time.mean()
print(mean_b - mean_a)
実行すると、平均の差が約35.6であった。
リサンプリング
次に、すべての時間を一緒にまとめ繰り返しシャッフルしてA:21個、B:15個の2つのグループに分け、その時の平均値の差を算出する関数を作成
import random
# 36の時間データをそれぞれ無作為に割り当てる関数の作成
def perm_fun(x, nA, nB):
n = nA + nB
idx_B = set(random.sample(range(n), nB)) # 15個のインデックスで示す非復元抽出した標本を割り当て
idx_A = set(range(n)) - idx_B # 残りをグループAに割り当て
return x.loc[idx_B].mean() - x.loc[idx_A].mean()
nA = session_times[session_times.Page == 'Page A'].shape[0]
nB = session_times[session_times.Page == 'Page B'].shape[0]
print(perm_fun(session_times.Time, nA, nB))
実行結果
55.78となった。シャッフルして振り分けしているので、この数値は実行するたびに変化する。
この関数を1000回繰り返し平均時間の差の分布をヒストグラムで表示してみる。
random.seed(1)
perm_diffs = [perm_fun(session_times.Time, nA, nB) for _ in range(1000)]
fig, ax = plt.subplots(figsize=(5, 5))
ax.hist(perm_diffs, bins=11, rwidth=0.9)
ax.axvline(x = mean_b - mean_a, color='black', lw=2)
ax.text(50, 190, 'Observed\ndifference', bbox={'facecolor':'white'})
ax.set_xlabel('Session time differences (in seconds)')
ax.set_ylabel('Frequency')
plt.tight_layout()
plt.show()
実行結果
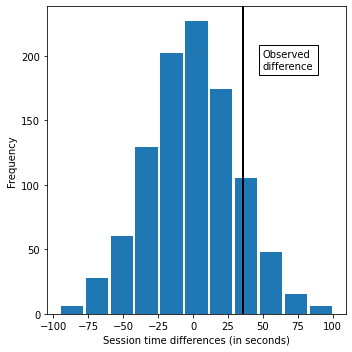
グラフから、無作為並べ替えによる平均の差が観測値(35.67)を超えている確率が12.1%であることを示す。
よって、これは統計的に有意ではないことが分かった。
まとめと感想
今回二つのwebサイトのどちらがより売り上げに寄与しているかを簡単な並べ替え検定を用いて調べてみた。リサンプリングの技術はどの検定でも用いられるような基礎的なものであるので習得しておくに越したことはないなと感じた。
結果としては有意な差が得られなかったので、例えばサイトの滞在時間ではなく商品のクリック数やどのurlを踏んでいるかなどのほかの指標を用いて検定することが必要であると考えた。
今後はt検定やχ^2検定などをpythonを使ってできるようにしていきたい。
また、今回初めての投稿で不備や見ずらい点があったので改善できればよいなと感じた。