LAPRAS アウトプットリレー1日目の記事です!
こんにちは!LAPRAS クローラーエンジニアの @Chanmoro です!
この度LAPRAS アウトプットリレーと題しまして、3月末まで毎日 LAPRAS のメンバーが日替わりで記事をアウトプットしていきます!
昨今のコロナショックの影響で勉強会やカンファレンスが中止になってしまっていますが、今回の LAPRAS アウトプットリレーを通して少しでもエンジニアの皆さんのインプットやアウトプットするモチベーションのお役に立てればと思っています。
この記事の内容
さて、僕は普段クローラー開発者として仕事をしているのですが、新規にクローラーを開発する時にどういう流れで開発を進めているのかというのを今回記事にしてみようと思います。
ここではサンプルとして、 LAPRAS が運営している自社メディアである LAPRAS NOTE に公開されている記事の情報を取得して JSON 形式のファイルに出力するクローラーの実装例を紹介していきたいと思います。
※LAPRAS NOTE はエンジニアの方向けに、LAPRAS に関連したニュースやインタビュー記事を発信しているサイトです。
クローラー開発の手順
クローラーを実装する時にはざっくりと以下のような手順で調査と設計・実装を進めていきます。
- サイトのリンク構造と各ページの導線を調査する
- クロールするページの HTML 構造を調査する
- クローラーを実装する
それぞれ詳細を説明していきます。
1. サイトのリンク構造と各ページの導線を調査する
LAPRAS NOTE のページをざっと見てみると、トップページには記事の一覧が表示されていて、一覧にある記事へのリンクから各記事のページに移動するという導線になっています。
ざっくりと 2 種類のページで構成されていることがわかります。
- 記事一覧ページ
- 記事詳細ページ
これらのページの作りについてもう少し詳しく見ていきましょう。
記事一覧ページを調べる
記事一覧ページではこのように記事タイトル、カテゴリー、公開日、本文のダイジェストの情報と、各記事の詳細ページへのリンクが掲載されていることがわかります。
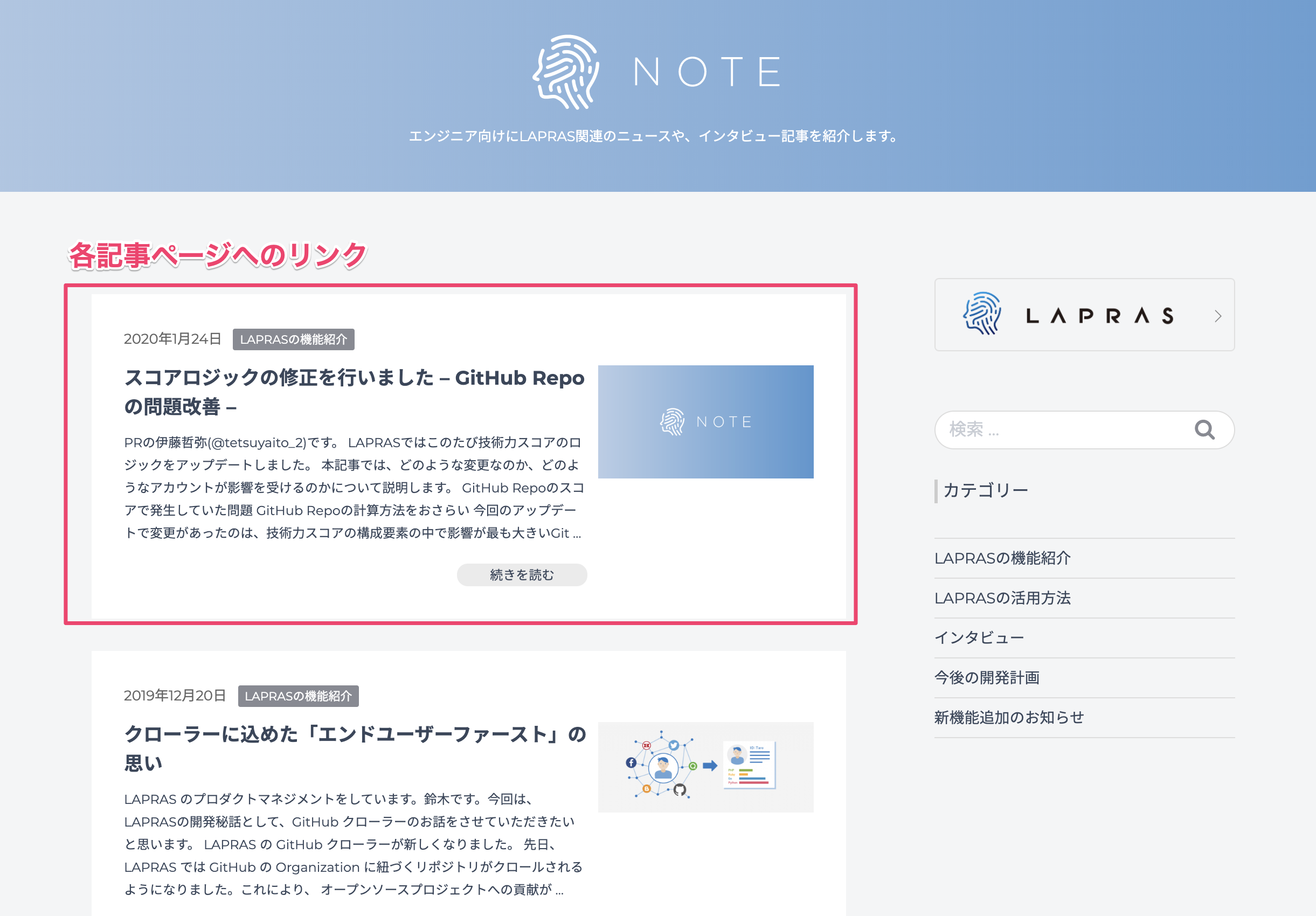
またページの下の方には次ページへのページングのリンクが表示されているとわかります。

現時点での最終ページである 2 ページ目へ移動すると、ここでは次ページへのリンクが表示されていないことがわかります。
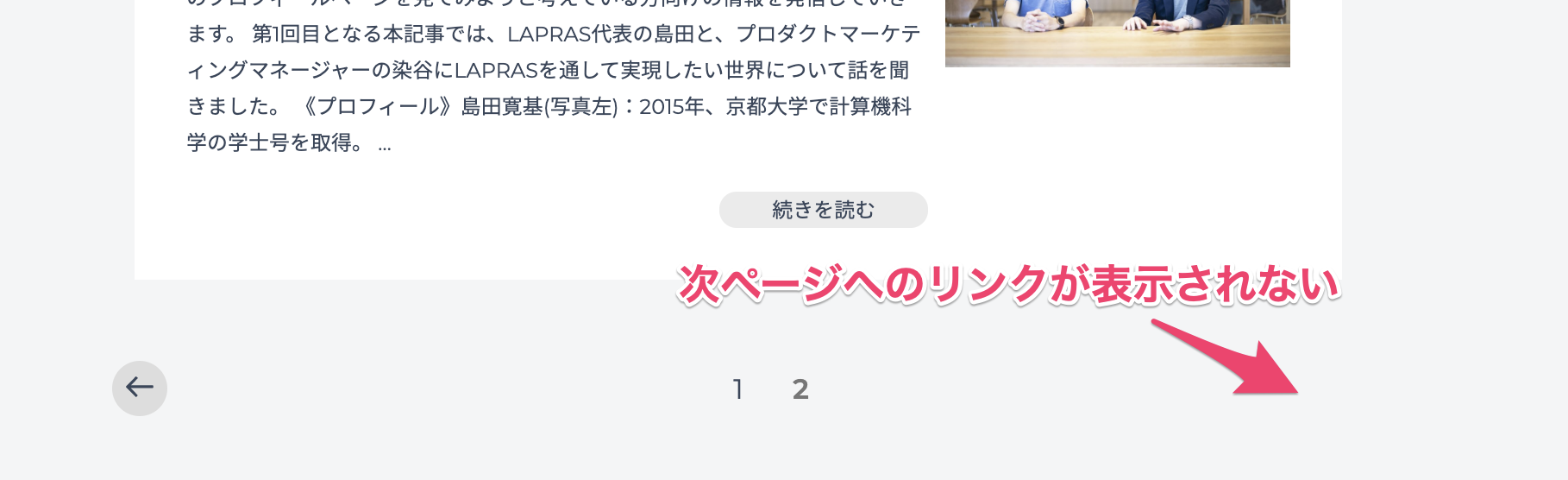
なので、次ページへのリンクがある場合は次のページへ移動し、リンクがなくなったらそこが最終ページだと判断すればよさそうです。
記事詳細ページを調べる
次に記事詳細ページの内容を見てみます。
このページからは記事のタイトル、公開日、カテゴリー、記事本文が取得できることがわかります。
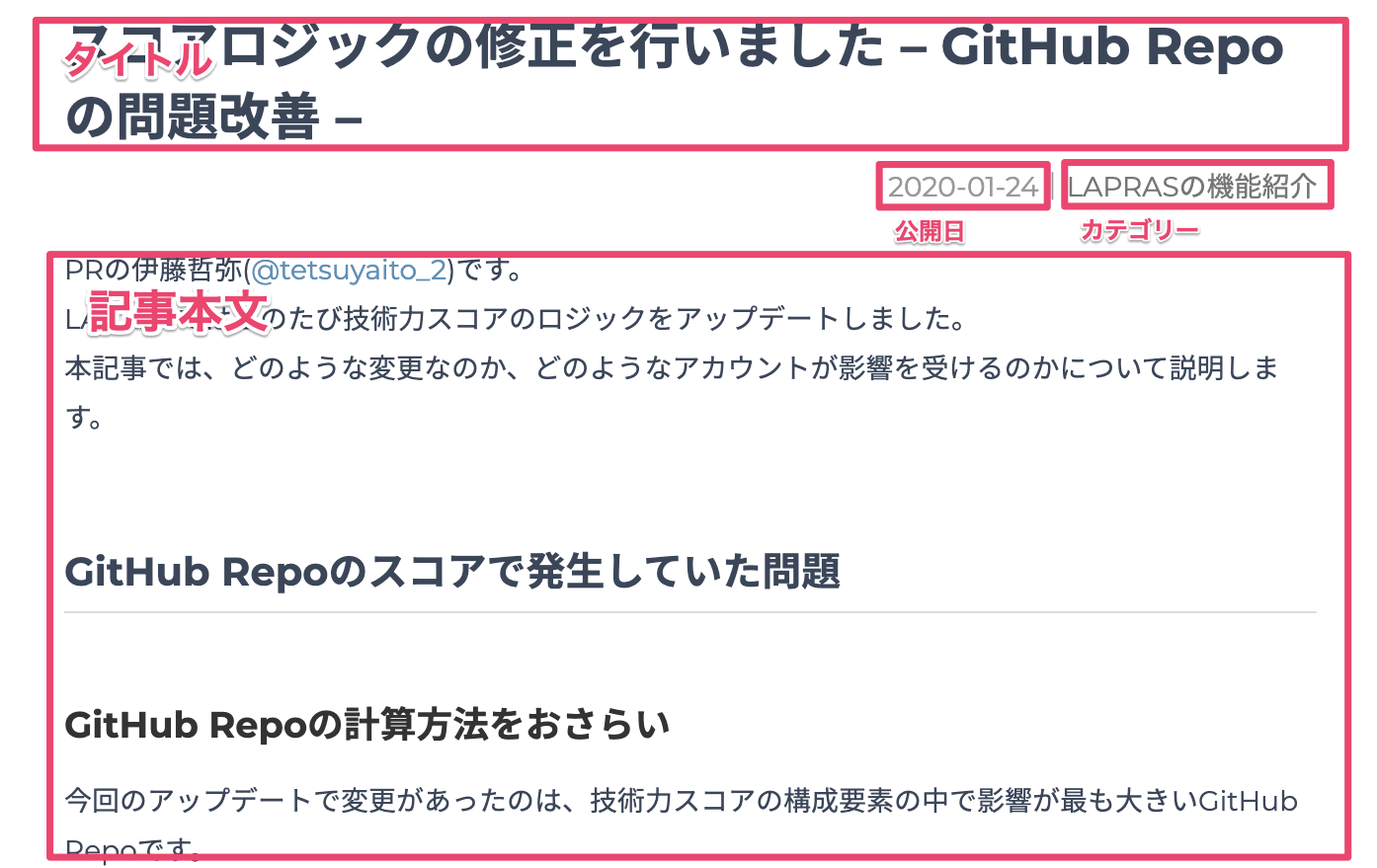
全ての記事を取得する目的に対しては、記事詳細ページから他のページへの移動は特に考えなくてよさそうです。
抽出するデータの構造をまとめる
先ほどのサイトの調査から、これらのデータが抽出できそうだということが分かりました。
- 記事
- タイトル
- 公開日
- カテゴリー
- 記事本文
また、 LAPRAS NOTE の全ての記事に対して上記のデータを抽出するためには以下のフローでサイトを辿ればいいことが分かりました。
- 公開されている記事の一覧ページへアクセスして記事詳細への URL を取得
1. 次ページへのリンクがあれば次ページへ移動して (1) と同様に記事詳細への URL を取得 - 記事詳細ページへアクセスして記事の情報を取得
2. クロールするページの HTML 構造を調査する
次に、クロール対象のページの HTML 構造を見ることで、対象のデータをどうやって抽出するかを調査していきます。
ここでは Web ブラウザの開発者ツールを利用します。
公開されている記事の一覧ページ
記事の一覧ページからは以下を抽出したいです。
- 記事詳細ページのリンク URL
- 次ページへのリンク URL
記事詳細ページのリンク URL を取得する
まずは記事詳細ページへのリンクを探すために、1つの記事と対応している要素を見つけます。
ページの HTML 構造を見ると、 post-item の class がセットされた div 要素が1つの記事の範囲と対応していることが分かりました。
また、該当の div.post-item の中の要素をみていくと、 h2 タグの直下にある a タグに記事詳細ページの URL がセットされていることが分かります。
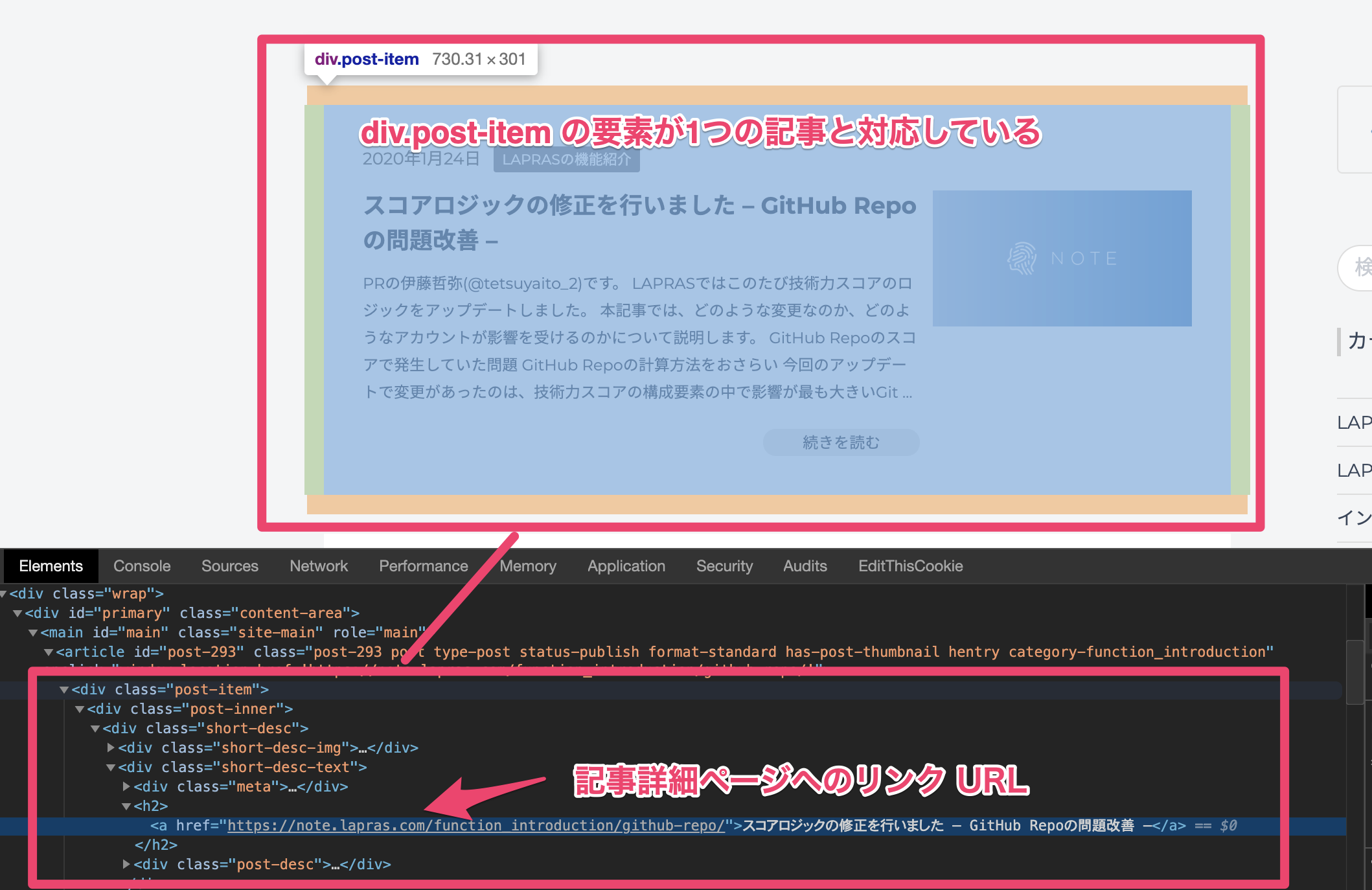
この取得したい a タグを指定するための CSS パスは div.post-item h2 > a ということになります。
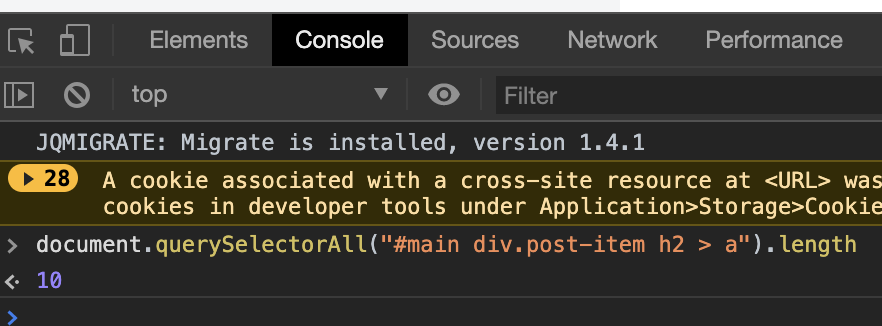
今の予想では記事一覧の 1 ページ目ではこの CSS パスにマッチする要素は 10 件取得できるはず ですが、他に関係ない URL が取得されないかを確認したいです。
例えば以下のような JavaScript のコードをブラウザのコンソールから実行してみて、 CSS セレクタにマッチする件数を確かめることができます。
document.querySelectorAll("#main div.post-item h2 > a").length
実際に、記事一覧ページの 1 ページ目を表示した状態でブラウザのコンソールから以下を実行すると 10 という結果が得られるので、先ほどの CSS パスで問題なさそうということが確認できました。
次ページへのリンク URL を取得する
次に、記事一覧ページの次ページへのリンク URL を探します。
nav.navagation.pagination の要素を見ると、ここが各ページへのリンクや次ページへのリンクを表示している領域だということが分かります。
この要素の中にある next と page-numbers の class を持った a タグに次ページへのリンク URL がセットされていることが分かります。
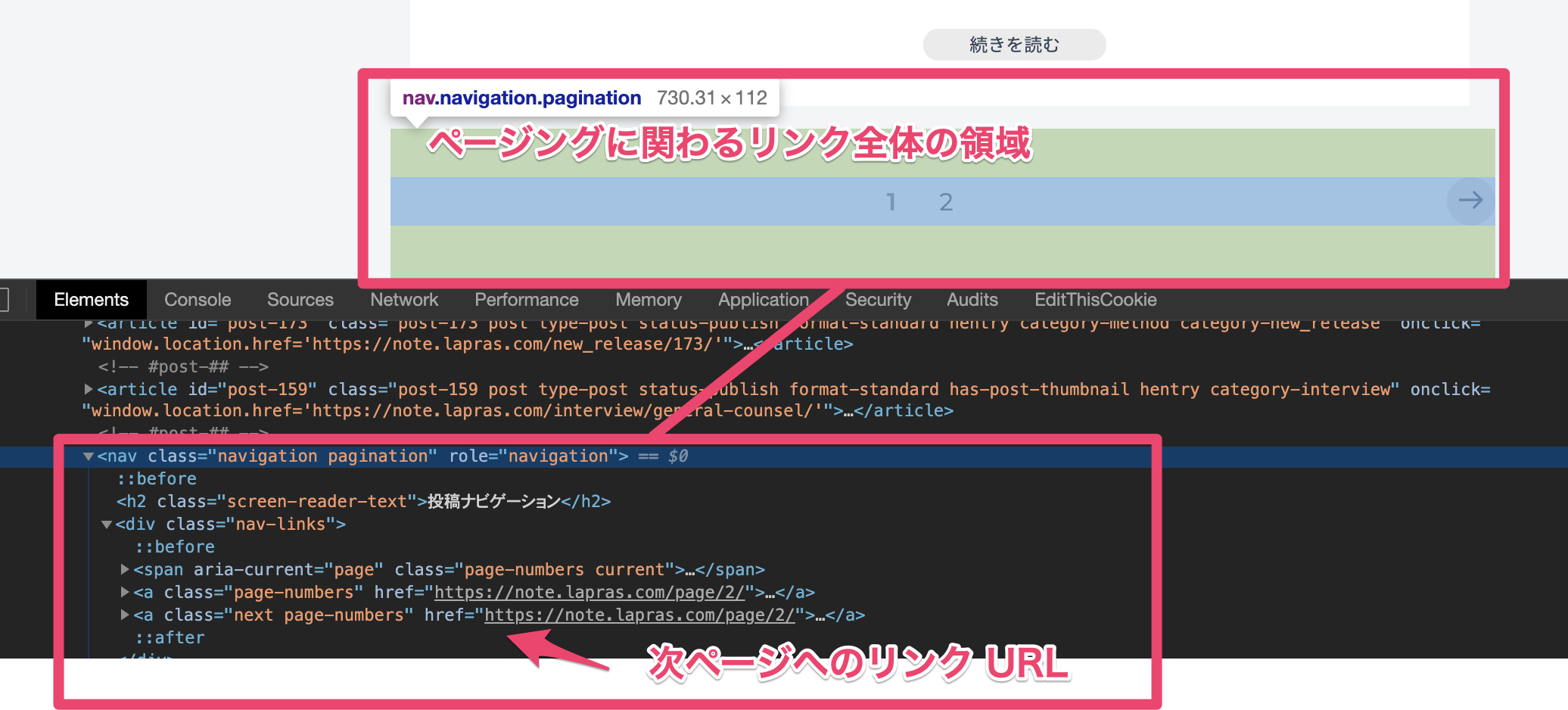
こちらを取得するための CSS パスは nav.navigation.pagination a.next.page-numbers ということになります。
こちらもブラウザのコンソールから実際に取得できる件数を調べてみます。
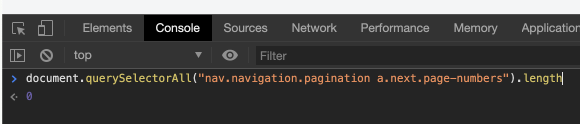
document.querySelectorAll("nav.navigation.pagination a.next.page-numbers").length
実行すると 1 と結果が得られたので目的のリンク URL が取得できているということで大丈夫そうです。

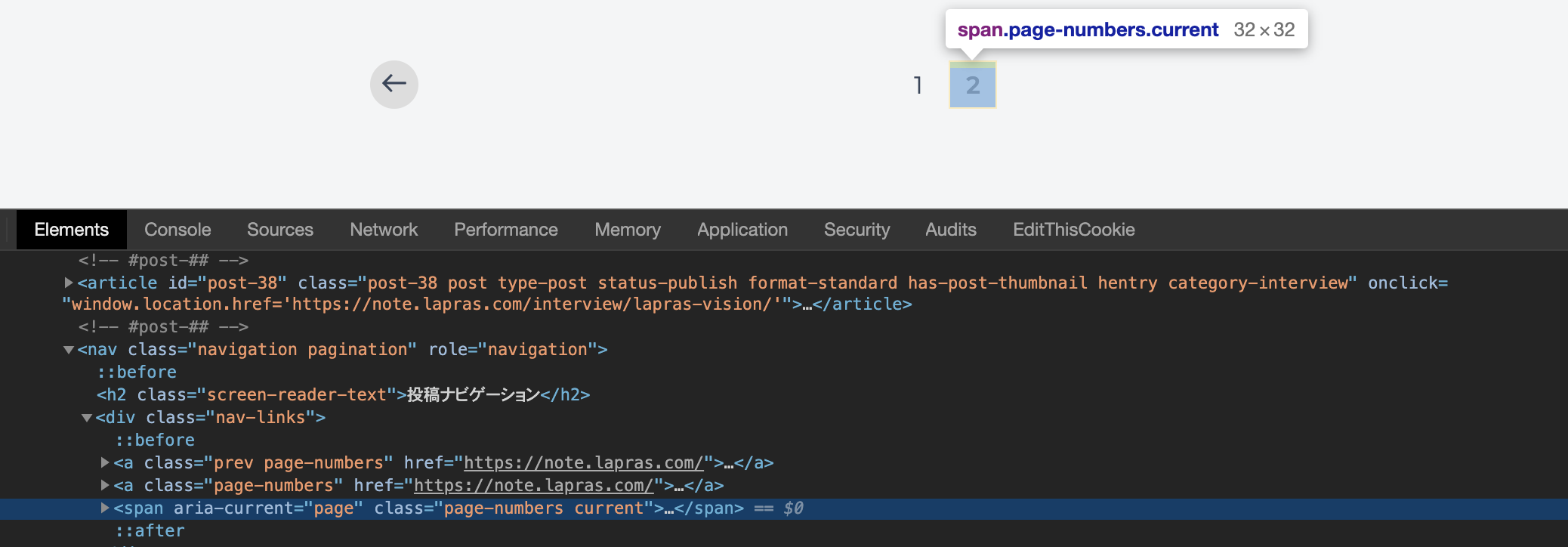
また、最終ページである 2 ページ目では次ページへのリンクの要素が表示されていないことが確認できます。
念のためコンソールから次ページへのリンクの要素を検索しても 0 の結果が得られました。
記事詳細ページ
記事詳細ページからは以下を抽出したいです。
- タイトル
- 公開日
- カテゴリー
- 記事本文
先ほどと同様に HTML 構造を調べて目的の要素への CSS パスを調べます。
手順は先ほどと同じなので省略しますが、以下の要素からデータを抽出すればよいことが分かりました。
- タイトル
h1
- 公開日
article header div.entry-meta
- カテゴリー
article header div.entry-meta a
- 記事本文
article div.entry-content
3. クローラーを実装する
ここまで調査した内容でクロールのためのロジックはほぼ明らかになっているのでそれをコードで実装していきます。
実装する言語は何を使ってもほとんどの場合で問題ありませんが、ここでは Python での実装例を書いていきたいと思います。
やることを整理
まずはベタにやることを列挙してみます。
# TODO: https://note.lapras.com/ へアクセスする
# TODO: レスポンス HTML から記事詳細の URL を取得する
# TODO: 次ページのリンクがあれば取得する
# TODO: 記事詳細ページへアクセスする
# TODO: レスポンス HTML から記事の情報を取得する
# TODO: URL
# TODO: タイトル
# TODO: 公開日
# TODO: カテゴリー
# TODO: 記事本文
# 取得されたデータを JSON 形式でファイルに保存する
クローラー実装時の注意点
実装時の注意点としては、クロール先サービスへ過度な負荷をかけないように適宜 sleep を入れてアクセスする間隔を調整します。
たいていの場合は目安として多くても1秒あたり1リクエスト程度に収まるようにしておくのがよいと思いますが、クロールにより対応先サービスをダウンさせてしまったりすると問題になるので、クロール先からのレスポンスがエラーになっていないかは常に確認するようにしましょう。
Python でベタに実装する
Python の場合は requests と Beautiful Soup を組み合わせてクローラーを書くことが多いです。
ライブラリの使い方は 10分で理解する Beautiful Soup も参考にしてみてください。
Scrapy などのクローラーを実装するフレームワークも存在していますが、クローラーの全体像を理解するためにはまずフレームワークを使わずに実装してみるのがオススメです。
一旦設計を深く考えずに、書きたい処理をベタにコードで表すとこんな感じになります。
import json
import time
import requests
from bs4 import BeautifulSoup
def parse_article_list_page(html):
"""
記事一覧ページをパースしてデータを抜き出す
:param html:
:return:
"""
soup = BeautifulSoup(html, 'html.parser')
next_page_link = soup.select_one("nav.navigation.pagination a.next.page-numbers")
return {
"article_url_list": [a["href"] for a in soup.select("#main div.post-item h2 > a")],
"next_page_link": next_page_link["href"] if next_page_link else None
}
def crawl_article_list_page(start_url):
"""
記事一覧ページをクロールして記事詳細の URL を全て取得する
:return:
"""
print(f"Accessing to {start_url}...")
# https://note.lapras.com/ へアクセスする
response = requests.get(start_url)
response.raise_for_status()
time.sleep(10)
# レスポンス HTML から記事詳細の URL を取得する
page_data = parse_article_list_page(response.text)
article_url_list = page_data["article_url_list"]
# 次ページのリンクがあれば取得する
while page_data["next_page_link"]:
print(f'Accessing to {page_data["next_page_link"]}...')
response = requests.get(page_data["next_page_link"])
time.sleep(10)
page_data = parse_article_list_page(response.text)
article_url_list += page_data["article_url_list"]
return article_url_list
def parse_article_detail(html):
"""
記事詳細ページをパースしてデータを抜き出す
:param html:
:return:
"""
soup = BeautifulSoup(html, 'html.parser')
return {
"title": soup.select_one("h1").get_text(),
"publish_date": soup.select_one("article header div.entry-meta").find(text=True, recursive=False).replace("|", ""),
"category": soup.select_one("article header div.entry-meta a").get_text(),
"content": soup.select_one("article div.entry-content").get_text(strip=True)
}
def crawl_article_detail_page(url):
"""
記事詳細ページをクロールして記事のデータを取得する
:param url:
:return:
"""
# 記事詳細へアクセスする
print(f"Accessing to {url}...")
response = requests.get(url)
response.raise_for_status()
time.sleep(10)
# レスポンス HTML から記事の情報を取得する
return parse_article_detail(response.text)
def crawl_lapras_note_articles(start_url):
"""
LAPRAS NOTE をクロールして記事のデータを全て取得する
:return:
"""
article_url_list = crawl_article_list_page(start_url)
article_list = []
for article_url in article_url_list:
article_data = crawl_article_detail_page(article_url)
article_list.append(article_data)
return article_list
def collect_lapras_note_articles():
"""
LAPRAS NOTE の記事のデータを全て取得してファイルに保存する
:return:
"""
print("Start crawl LAPRAS NOTE.")
article_list = crawl_lapras_note_articles("https://note.lapras.com/")
output_json_path = "./articles.json"
with open(output_json_path, mode="w") as f:
print(f"Start output to file. path: {output_json_path}")
json.dump(article_list, f)
print("Done output.")
print("Done crawl LAPRAS NOTE.")
if __name__ == '__main__':
collect_lapras_note_articles()
実装したコードはこちらのリポジトリで公開しています。
https://github.com/Chanmoro/lapras-note-crawler
使い捨てコードっぽい雰囲気が漂っていますが、 Basic 編としては一旦ここまでで解説を終わりたいとおもいます。
まとめ
さて、今回は 「クローラーの作り方 - Basic 編」 ということで、 LAPRAS NOTE のクローラー実装をテーマにして、クローラーを開発する時の一連の流れの基本を紹介しました。
僕がクローラーを開発する時は今回紹介したような手順で開発を進めています。
実装例にあげているコードは長期間メンテナンスし続けるクローラーとしてみるとまだまだ不足していることは多いですが、継続的にデータを更新するのではなく1回で一式のデータが取得できれば十分な場合など、簡易的な利用であればこれくらいのコードでも十分だと思います。
個人的には数回程度実行すれば十分な調査用のクローラーであれば Python を使わなくてもシェルスクリプトだけで簡単に実装してしまう場合もあります。
実際の仕事ではデータモデリングやクロールフローの設計、エラーの場合のハンドリングなど、継続的にクロールを繰り返してもデータが壊れないように維持するための開発にはるかに多くの時間をかけています。
LAPRAS アウトプットリレーの期間中にいくつか記事を書かせていただく予定ですが、次回の僕の記事では 「クローラーの作り方 - Advanced 編」 ということで今回の記事の内容を踏まえて、長期的にメンテナンスし続けるクローラーを開発するにはここからどういうところを気をつけて設計していけばいいか?というのをご紹介したいと思っていますので、お楽しみに!
明日の LAPRAS アウトプットリレー2日目は @nasum さんが書いてくれる予定です!こちらもお楽しみに!