Prometheus とは
SoundCloud が中心になって開発しているプル型のリソース監視ソフトウェアです

アーキテクチャを見ると複雑そうに見えますが、Prometheus はセットアップがめちゃくちゃ簡単です
全体を理解する
Prometheus でできること
監視の機能としてはあんまり目新しいものはないですが、監視対象が動的に変更されるようなスケーラブルな環境のリソース監視を意識した設計になっています
- 監視対象のサーバーから情報を取得 & 保管
- 保管済みデータに対して集計クエリを発行できる
- しきい値を超えた場合のアラート (メール、Slack、がんばればTwilioで電話)
- 柔軟なアラート設定 (同じエラーはまとめて通知とかの設定ができる)
登場人物
Prometheus で監視の仕組みを入れるためには、以下の2つだけ知っていればとりあえず使えます
| 名称 | 説明 |
|---|---|
| exporter | 監視対象サーバー上で動かすプログラム テキスト形式でリソース情報を公開するWeb API のようなもの 監視対象のリソース毎に exporter が用意されている |
| prometheus | 監視サーバーのプログラム 定期的に全ての exporter をポーリングしてリソース情報を収集する 監視したデータは prometheus 内の DB に保持される |
それぞれ Docker イメージが提供されているので、以下の手順だけで特に複雑な設定は不要で動きます
- 監視したいサーバーで exporter の Docker コンテナを動かす
- 監視データ保管用のサーバーで Prometheus の Docker コンテナを動かす
exporter の種類
監視対象のサーバー上では、監視したいリソースの種類ごとに exporter を動かすことになります
各ミドルウェアのベンダーごとに exporter を公開してくれていてたくさん種類があります
https://prometheus.io/docs/instrumenting/exporters/
ちなみに過去にGPUマシンのリソース監視を入れた時には以下の2つの exporter を各GPUマシン上で動かしてます
| 名称 | 説明 |
|---|---|
| node_exporter | CPU、メモリなど物理マシンの情報を取得するための exporter https://github.com/prometheus/node_exporter |
| nvidia_exporter | GPUの利用使用状況を取得するための exporter https://github.com/Nextremer/nvidia_exporter nvidia-smi で表示されるデータを取得できる tankbusta/nvidia_exporter をフォークして GPU のデバイスIDも取得できるように改良 |
exporter から取得されるデータ
例えば node_exporter が公開しているデータに直接 curl でアクセスしてみると、こんなデータが返ってきます
アクセス時点のリソースの測定値をテキスト形式で返却されているだけです
Prometheus サーバーは定期的にこのデータを収集しDBにこの値を格納していきます
$ curl http://hogehoge:9100/metrics
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000111075
go_gc_duration_seconds{quantile="0.25"} 0.000244251
go_gc_duration_seconds{quantile="0.5"} 0.000264236
go_gc_duration_seconds{quantile="0.75"} 0.000295209
go_gc_duration_seconds{quantile="1"} 0.000693045
go_gc_duration_seconds_sum 187.504344849
go_gc_duration_seconds_count 237336
・・・
アプリの情報も exporter みたいにしたい!
概要が理解できると多分こういうことがやりたくなるはずです
その時点のユーザー数とか、登録数とか
アプリの統計情報を取得するための Json 形式の API を用意しておけば exporter と統合するのは簡単です
kibana でよくやるような、アプリログに出力されたデータから集計するためには Prometheus の FAQ を見てみたら "mtail使え!" と書いてました
ログを収集してメトリクス に変換するようなものですね
https://prometheus.io/docs/introduction/faq/#how-to-feed-logs-into-prometheus?
https://github.com/google/mtail
データを可視化する
監視対象から取得されたデータは、Prometheus 内の時系列データベースに保存されます
Prometheus サーバーにデフォルトで付いている GUI を使うと、こんな感じにグラフが表示できます
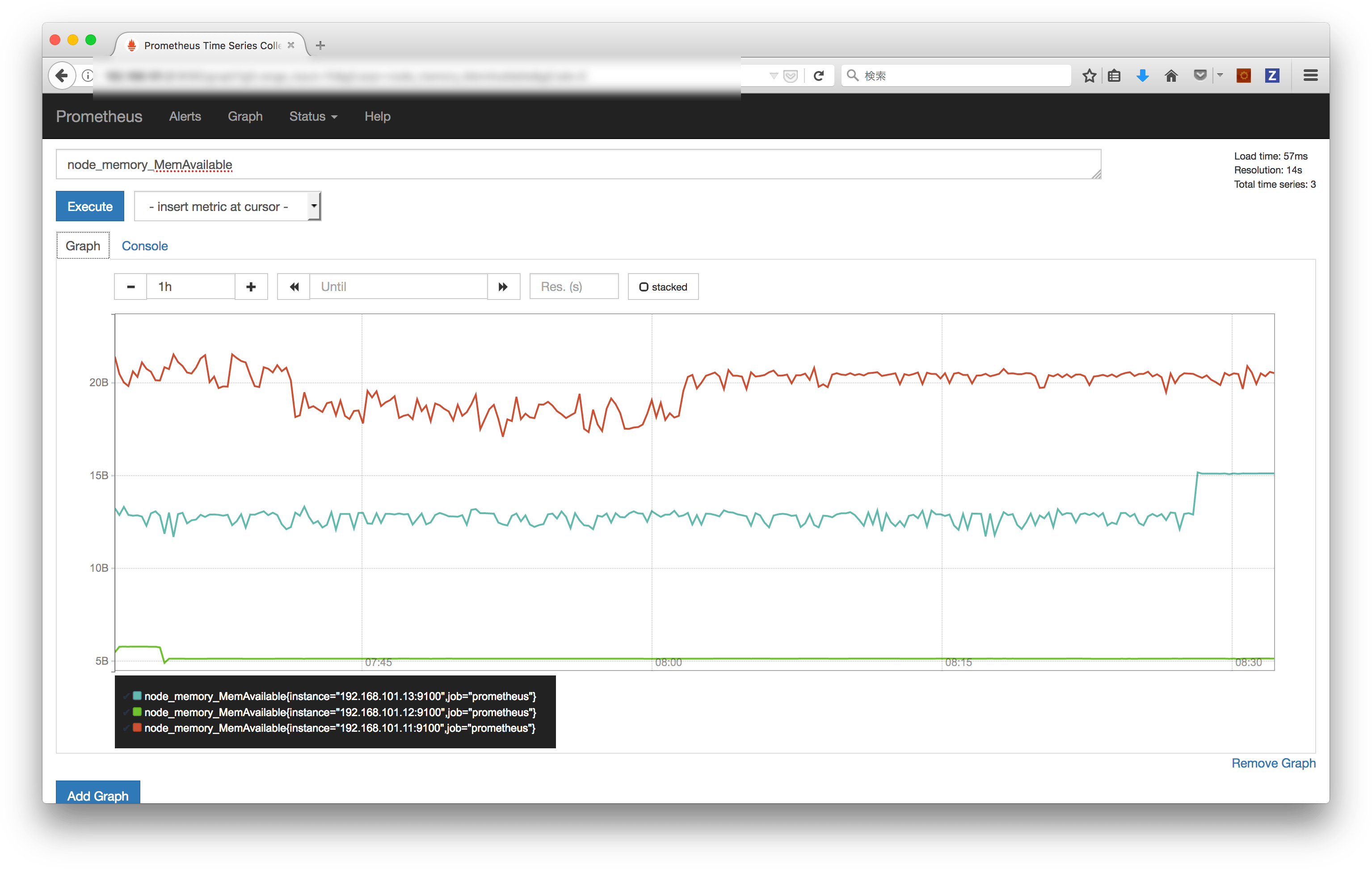
データの取得には Prometheus のクエリを使います
これがなかなか難しいですが、ググればだいたいのことは誰かが解説してくれているものが見つかるので、クエリを自分で組み立てられなくてもとりあえずは困らないはずです
例えば、各マシンのCPU使用率を取得するためには以下のようなクエリを書きます
100 - (avg by (instance) (irate(node_cpu{mode="idle", instance=~"^%s:.+"}[5m])) * 100)
Grafana で可視化する
Prometheus のデフォルト GUI だと非常に見た目がしょぼくて機能も少ないです
Prometheus 自体のメイン機能は監視サーバーとDBの役割なのでそこは仕方ないでしょう
Grafana という可視化ツールと組み合わせると、イケてる見た目で非常に使いやすくなります
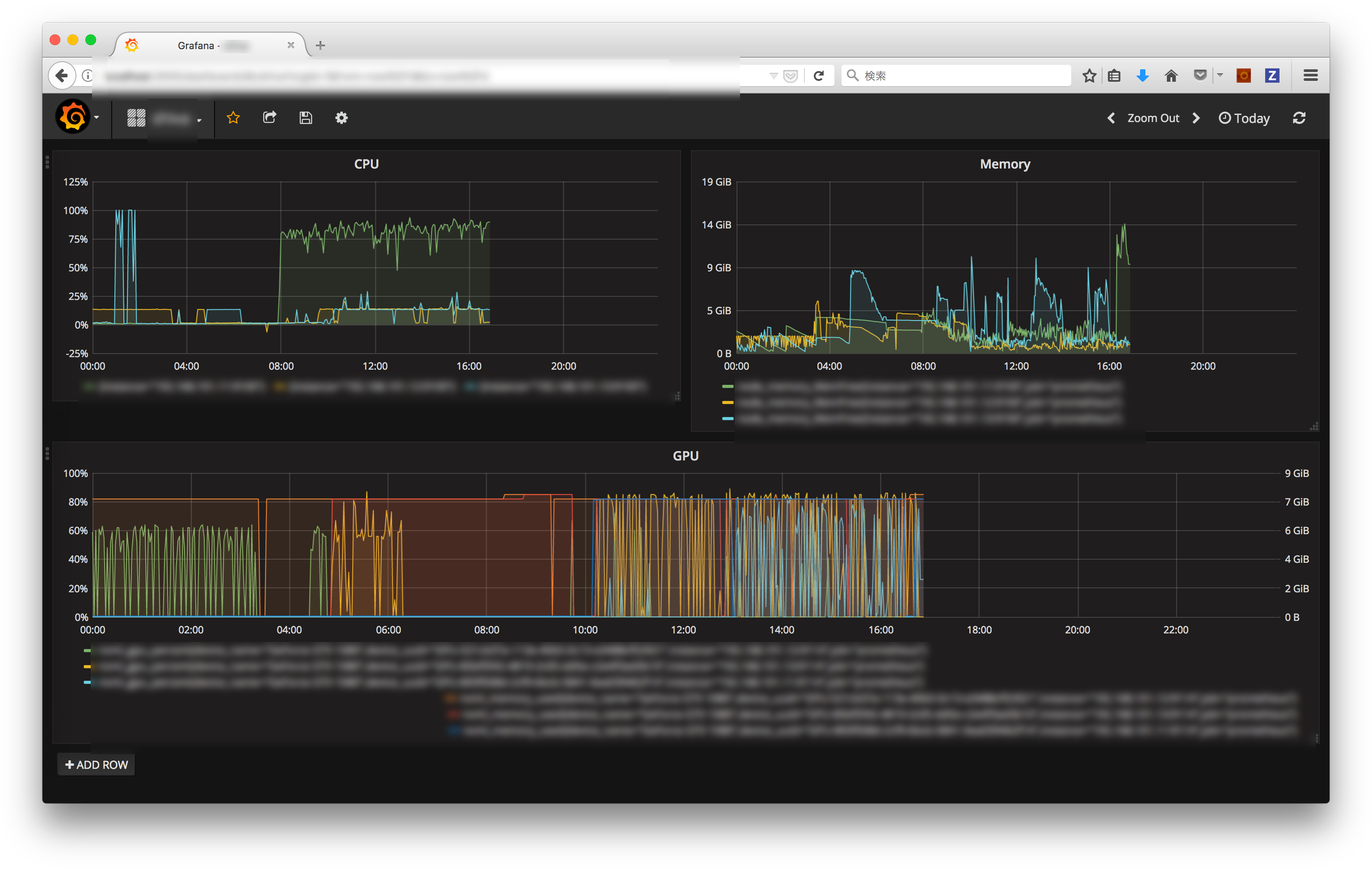
Prometheus と Grafana の関係は、elasticsearch と Kibana の関係のような感じです
※Grafana の解説 10分で理解する Grafana の記事も書きました!
https://qiita.com/Chanmoro/items/a23f0408f0e64658a775
もう一歩踏み込みたい方は
こちらの記事が非常にわかりやすいのでこの次に読んでみましょう!
次世代監視の大本命! Prometheus を実運用してみた
以上、快適なリソース監視ライフを!