はじめに
Azure Advent Calendar 2020 の12日目のエントリーです!
Azure Learn を掘っていたら、手っ取り早く Azure Machine Learning と AutoML を試せる題材があったのでハンズオン形式でまとめました。
ターゲット
- 非エンジニア・データ分析初心者
- 機械学習難しそうだけどちょっと気になる
- Azure ほとんど触ったことない
- データサイエンティスト
- Azure Machine Learning の AutoML 機能が気になってる
- どんな感じで構築したモデルのメトリクスを見れるのか知りたい
スコープ
- Azure Machine Learning ワークスペース構築
- Notebook と Computing 設定
- 実データを用いて AutoML で回帰モデル構築
- モデルのデプロイ
- デプロイしたモデルのテスト
用意するもの
- Azure Machine Learning を利用可能な Azure Subscription
背景
データ分析プロジェクトはとにかくトライアンドエラーで進めていくことが多いと思います。ステップを列記するとこんな感じでしょうか?
- 課題定義
- 実ビジネスで解消したい課題の整理
- データ分析でのゴール設定
- 仮説立案
- データ分析
- データ収集・前処理
- データ探索
- アルゴリズム選定
- モデル構築
- 検証・チューニング
- 本番運用
- モデル再評価スキームの策定
- 機械学習パイプライン設計・構築
- CI/CDパイプライン設計・構築
それぞれ円滑に進めるためには高い専門性が必要ですが、ハードルを下げるサービスが日進月歩で拡充しています。データサイエンティストの職人技だった一部領域を自動化できるようになったり、分析基盤が MLOpsといわれる領域もカバーするようになったり、などなど。
Azure でこの辺りの中核になっているサービスが、Azure Machine Learning であり、その機能である AutoML というわけです。
Azure Machine Learning とは
- 機械学習モデルのトレーニング、デプロイ、自動化、管理、追跡までできるデータ分析環境
- 便利機能いろいろ
- AutoML 機能でモデル作成 (= 本稿のスコープ)
- VS Code 拡張機能使ってリソース管理/実装
- Azure Machine Learning Designer でドラッグアンドドロップで ML パイプラインをデプロイ
- コンソールから豊富に選べる Jupyter Notebook サンプル
- 様々な計算リソースを数分で利用、スケールアウトも簡単
- 各種オープンソースツールと連携
- Scikit-learn, TensorFlow, PyTorch, Ray RLlib, Kubeflow, mlflow などなど
- 各種 Azure サービスとも連携
- Azure Machine Learning Pipeline や Azure DevOps でモデルの改良や運用管理

- Azure Machine Learning Pipeline や Azure DevOps でモデルの改良や運用管理
AutoML とは
- 前処理済みのデータから最適なMLモデルをいい感じに作成
- アルゴリズムの選定とハイパーパラメーターチューニングを自動化
- 一行もコード書かずにモデルを作成
- とはいえパラメーターに関するちょっとした知識は必要

- とはいえパラメーターに関するちょっとした知識は必要
Azure Machine Learning 初期設定
まずは AutoML 実行の手前、Dataset の作成までの手順です。
ワークスペース作成
検索窓から Machine Learning を検索し、クリック。

新規ワークスペースの追加をクリック

検証用なので新しくリソースグループを作ります。ワークスペース名を任意で設定したら、確認及び作成に進み、検証に成功しましたと出たら作成をクリックします

こちらの画面に移った後、ちょっと待ちます。デプロイ完了と出たらOKです
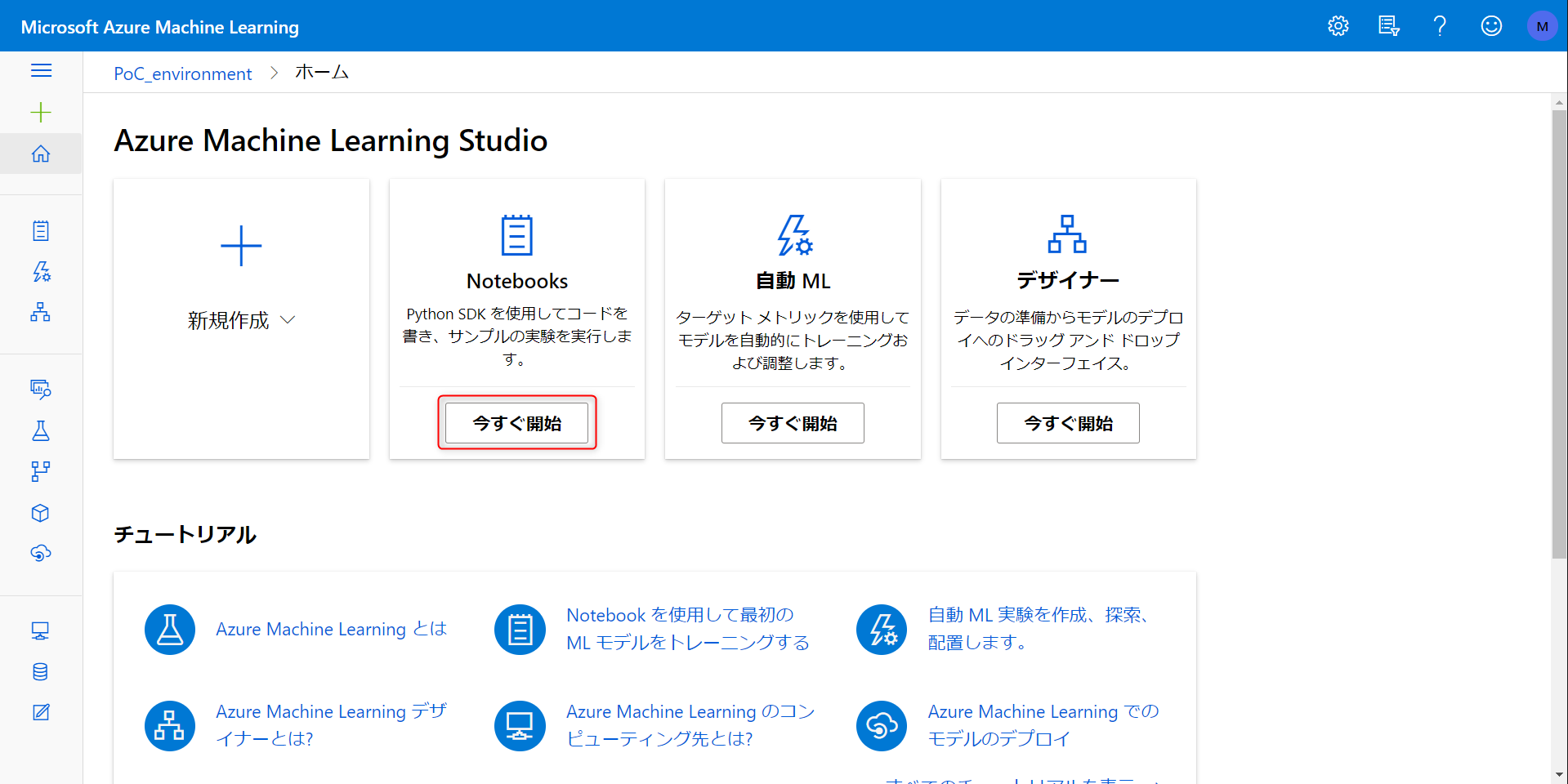
Notebook とコンピューティングの作成
こちらがホーム画面。とりあえず Notebook を立ち上げてみます。
名称とファイルタイプを選びます。
Notebook だけでなく普通のテキストファイルも書き込めるようです。混成チームでタスク共有したりするときはなんだかんだでマークダウン書くだけでも障壁になることもあるので便利そう。

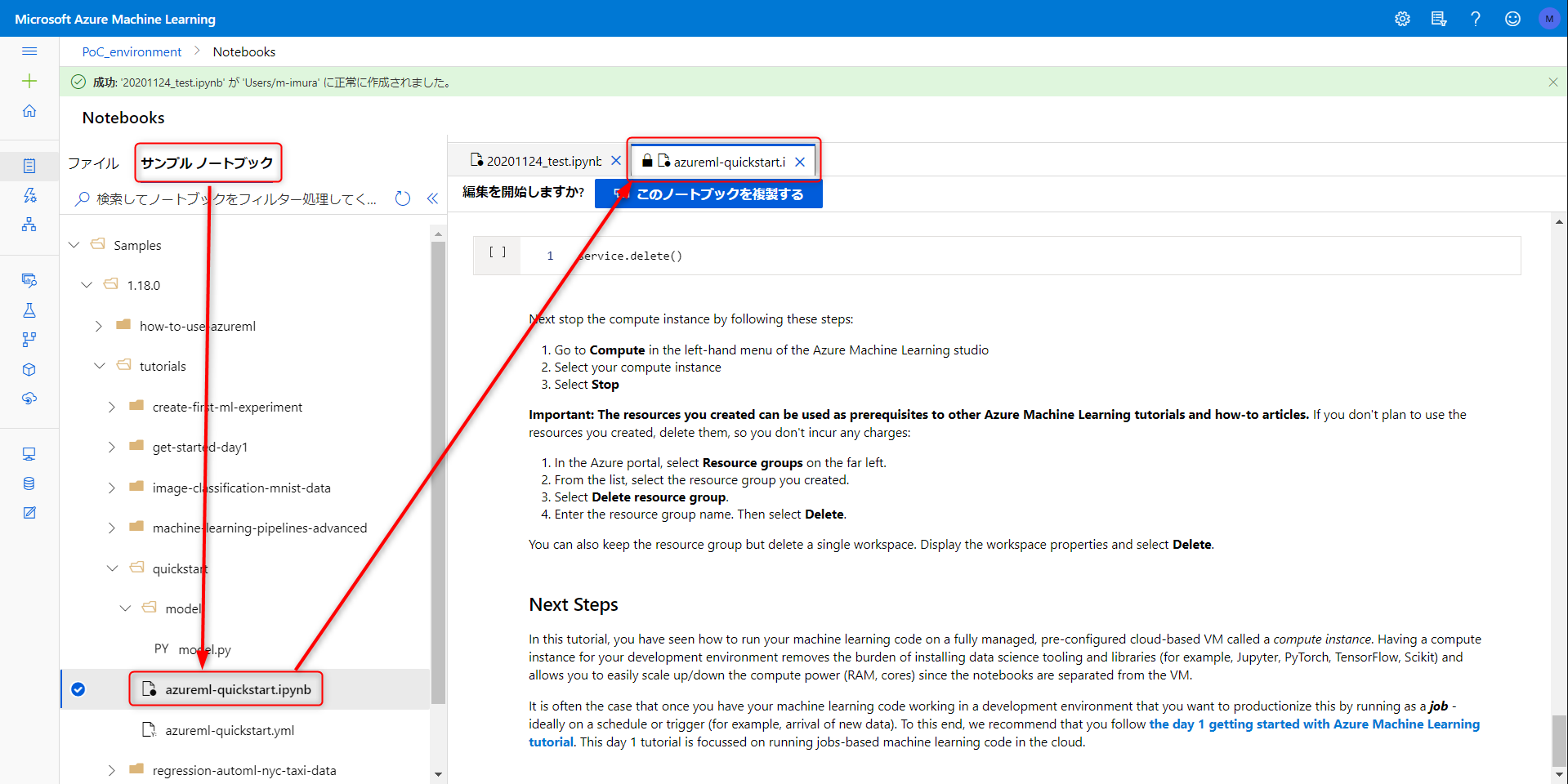
サンプルノートブックにはそのまま使えそうなものがたくさん。別タブで開かれるので気軽に情報を参照できます。
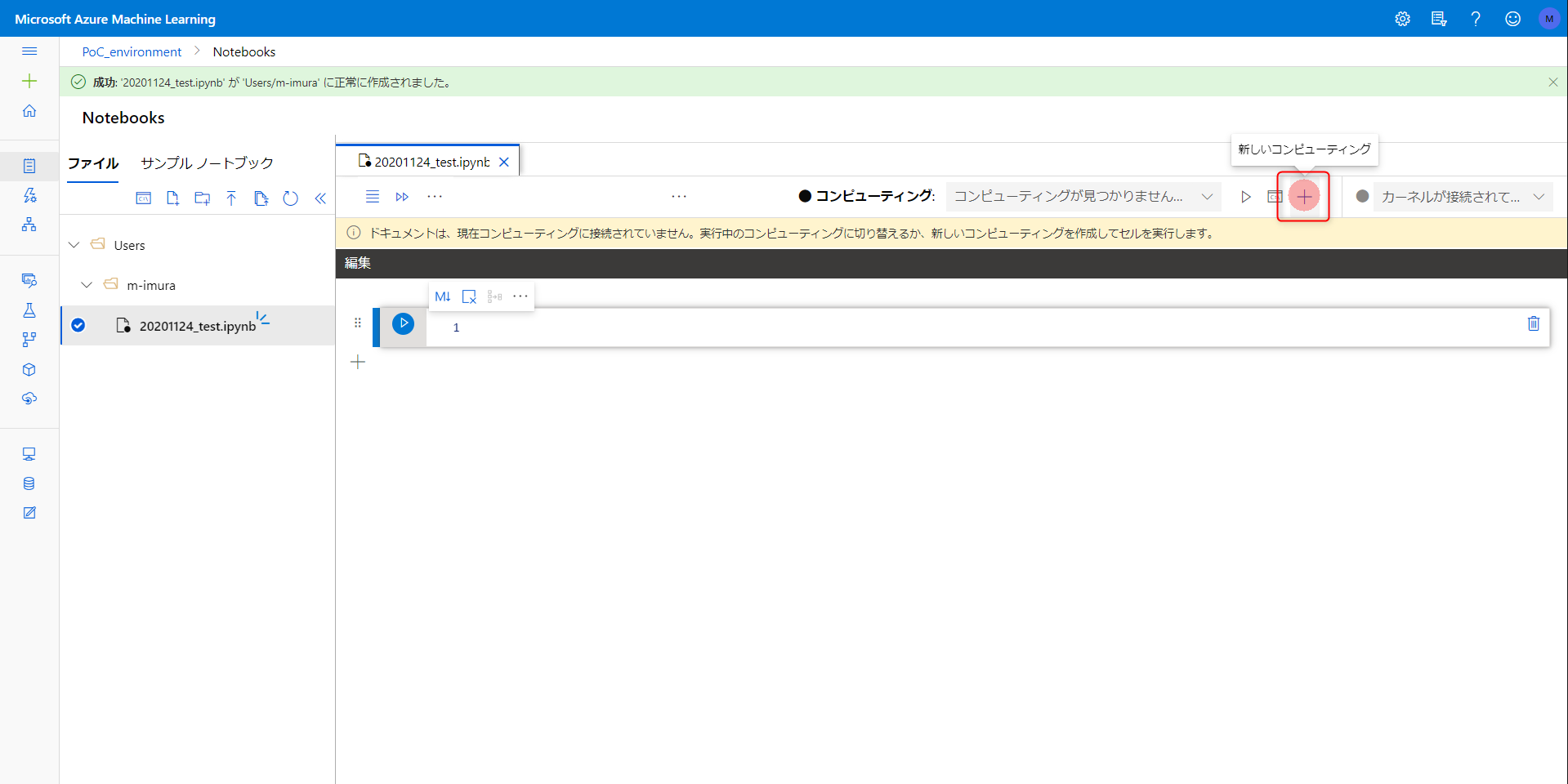
コンピューティングリソースがないと出ます。つくりましょう。
VM の選択画面に映ります。検証用なのでコストのカラムをクリックして価格順にソート、一番安価なインスタンスを選択します。(一時間当たり 0.1 USD ってめちゃくちゃ安い...)

VS code 使用時には SSH アクセスを有効化する必要あり。今回は VNET インジェクションも不要なのでこの内容で作成をクリック
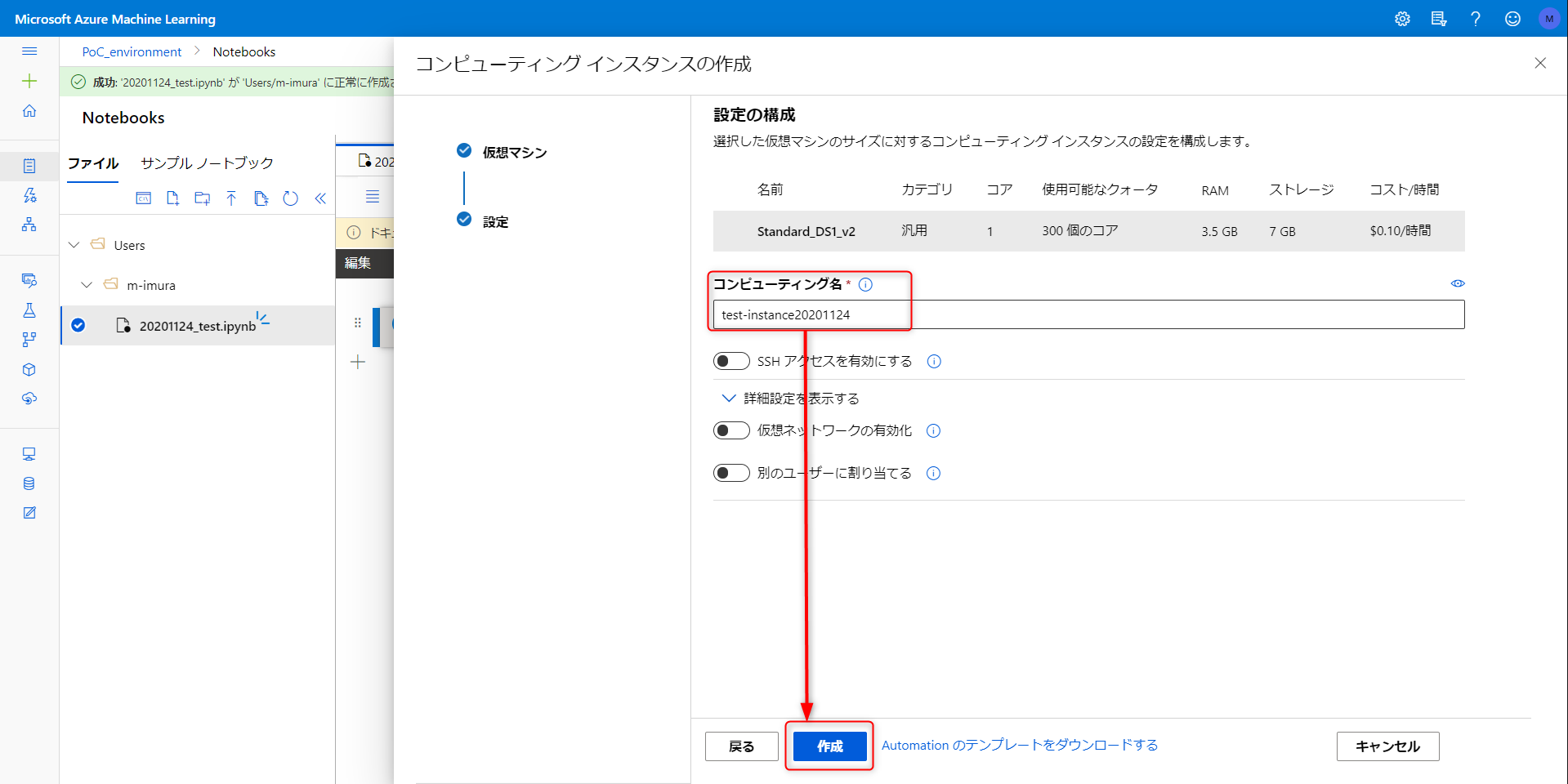
しばらく待つとコンピューティング左側のアイコンが緑色になります。
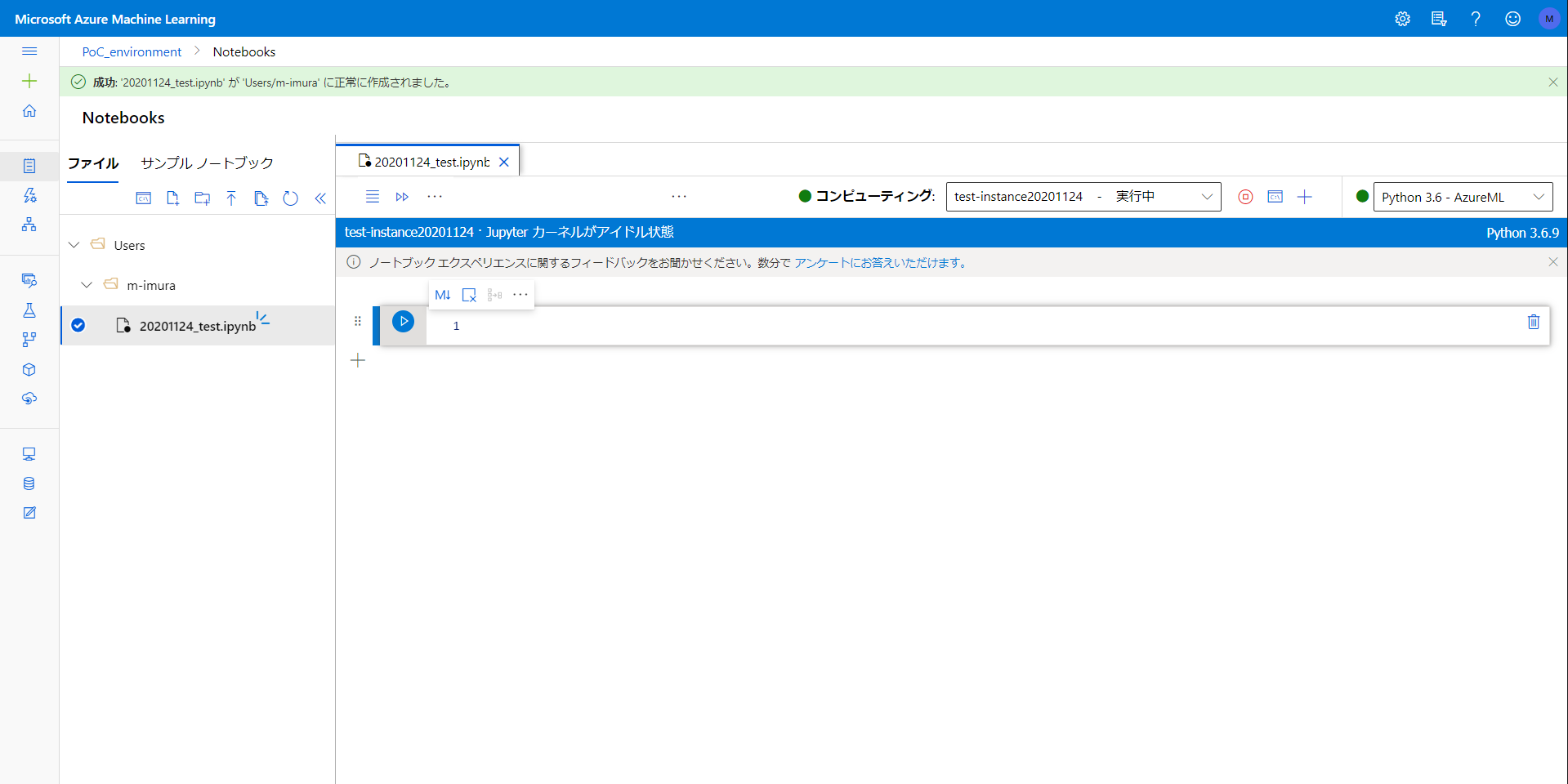
もう普通に Notebook として使える感じです。言語は R も選べるみたいですね

備考:コンピューティングが停止している場合は以下からアクセスできます
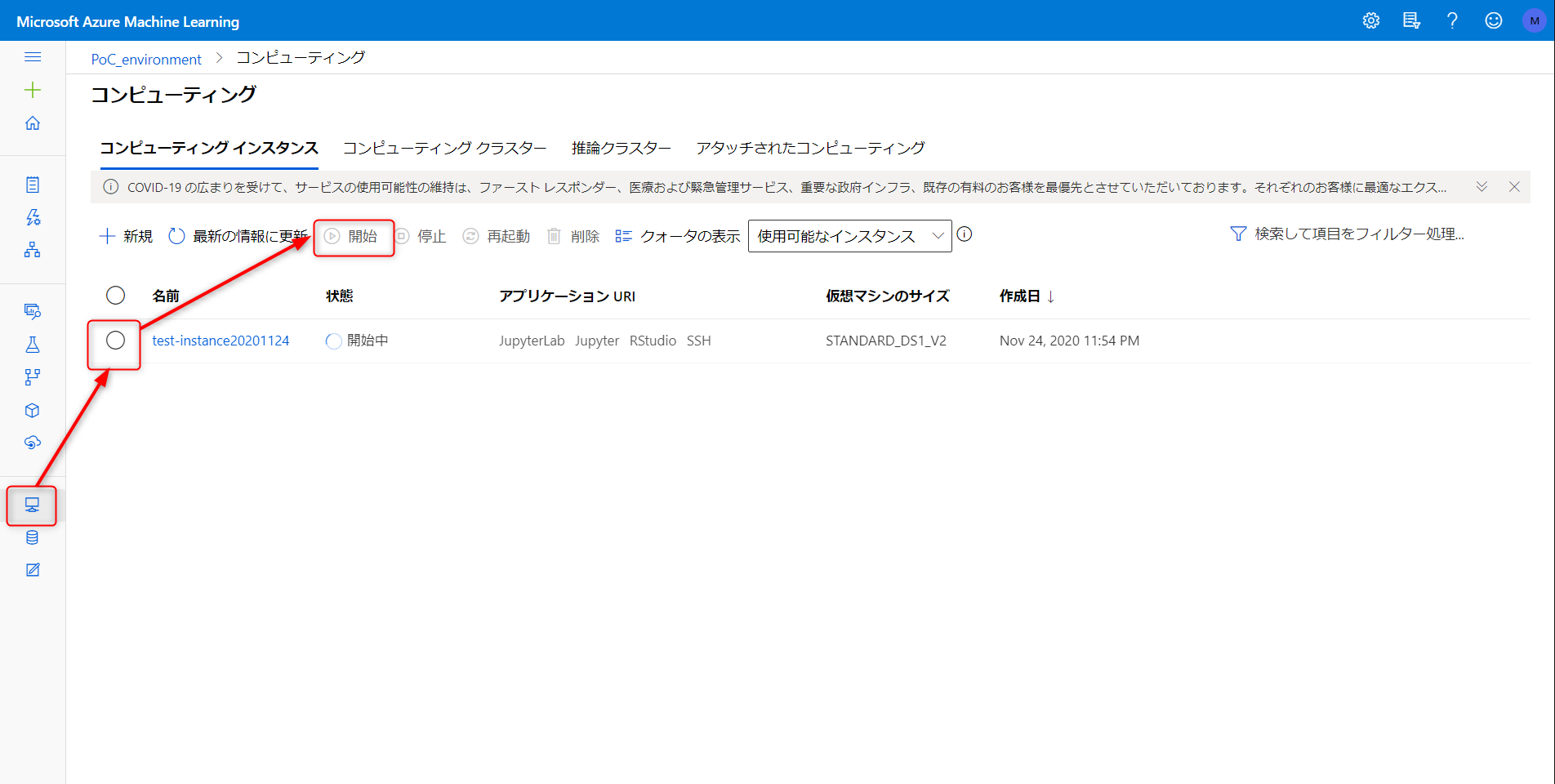
データセットの作成
今回利用するのは気象情報が付与されたレンタルサイクルログデータのCSV。
- ワシントン D.C 周辺の自転車レンタルログ
- 気象データもマージ済みのCSV
- 自転車のレンタル数が予測対象です。
-
https://aka.ms/bike-rentals

整理されたデータです
| カラム名 | 概要 |
|---|---|
| day |
月間通算日番号 |
| mnth |
月番号 |
| year |
年。2011 or 2012 |
| season |
季節番号。春夏秋冬で4つ |
| holiday |
祝日 or not |
| weekday |
曜日。 0-6 の整数値 |
| workingday |
就業日 or not |
| weathersit |
天気。晴、曇り、雨で3つ |
| temp |
気温指標 #1 (正規化済み) |
| atemp |
気温指標 #2 (正規化済み) |
| hum |
湿度指標 (正規化済み) |
| windspeed |
風速指標 (正規化済み) |
| rentals |
自転車のレンタル数 (目的変数) |
データベース → 登録されたデータセット → データセットの作成 → Web ファイルと進みます。

以下パラメータを入力、次へをクリック。データの欄に以下 URL を貼り付け
https://aka.ms/bike-rentals
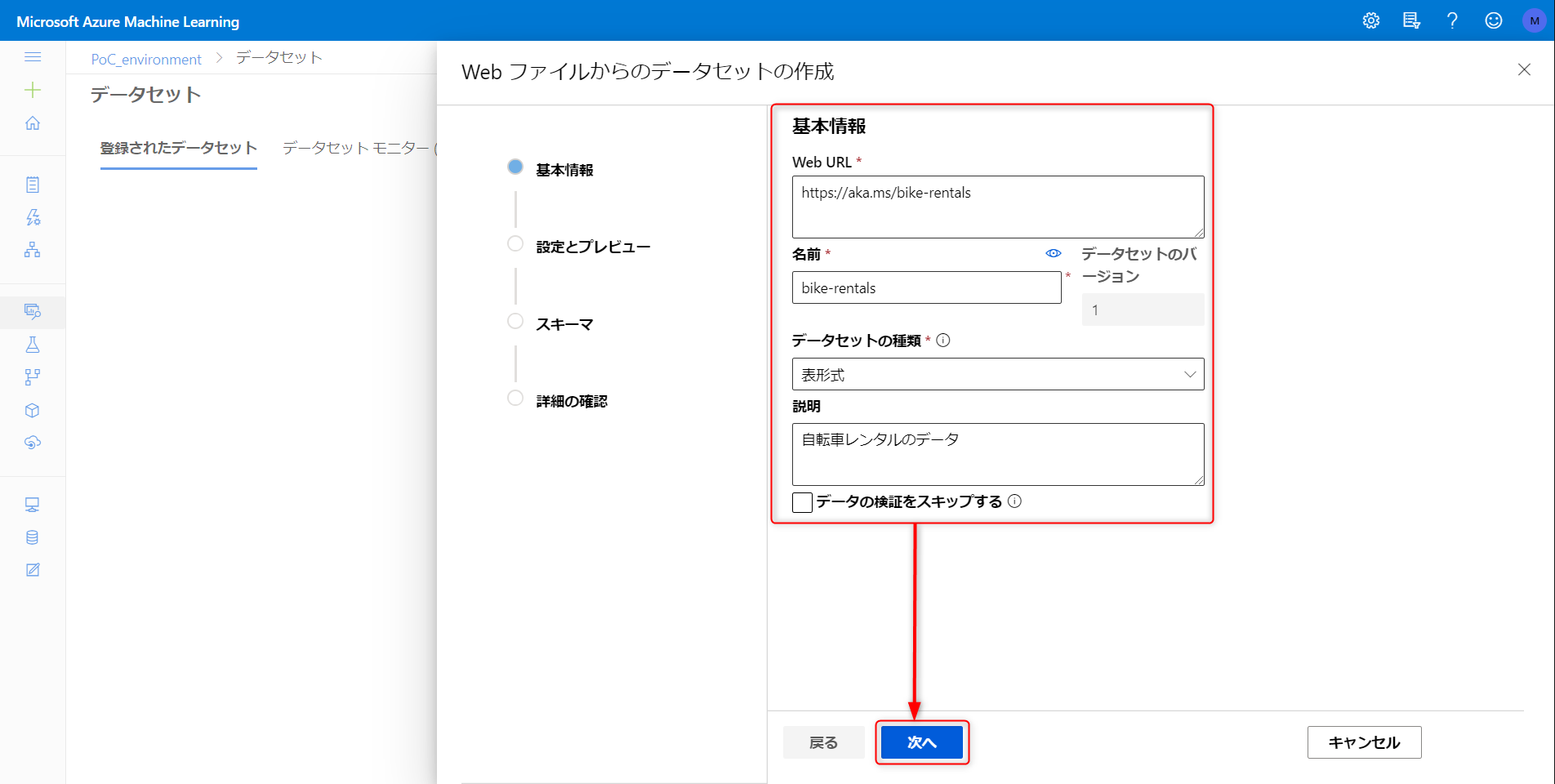
以下のように記載、次へをクリック。
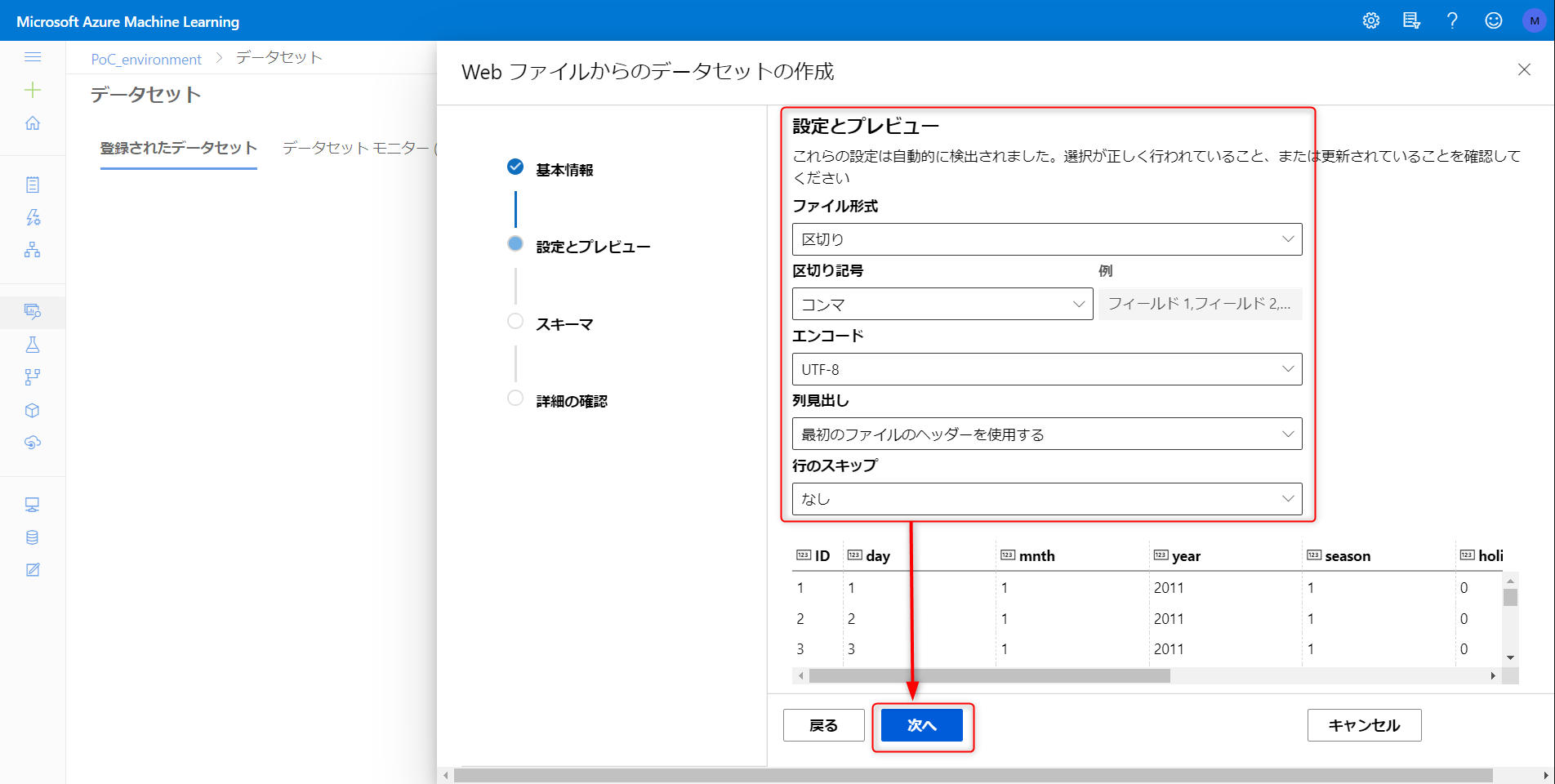
スキーマは自動類推されるみたいですね。one-hot encoding するカラムの指定とかも不要。右にスクロールするとプレビューを見られます。データセットに含む必要のないカラムがあれば除外し、次へをクリック、そのまま進めばデータセットの作成完了です。

AutoML
登録したデータセットを用いて AutoML でモデルを作成していきます。
モデル作成手順
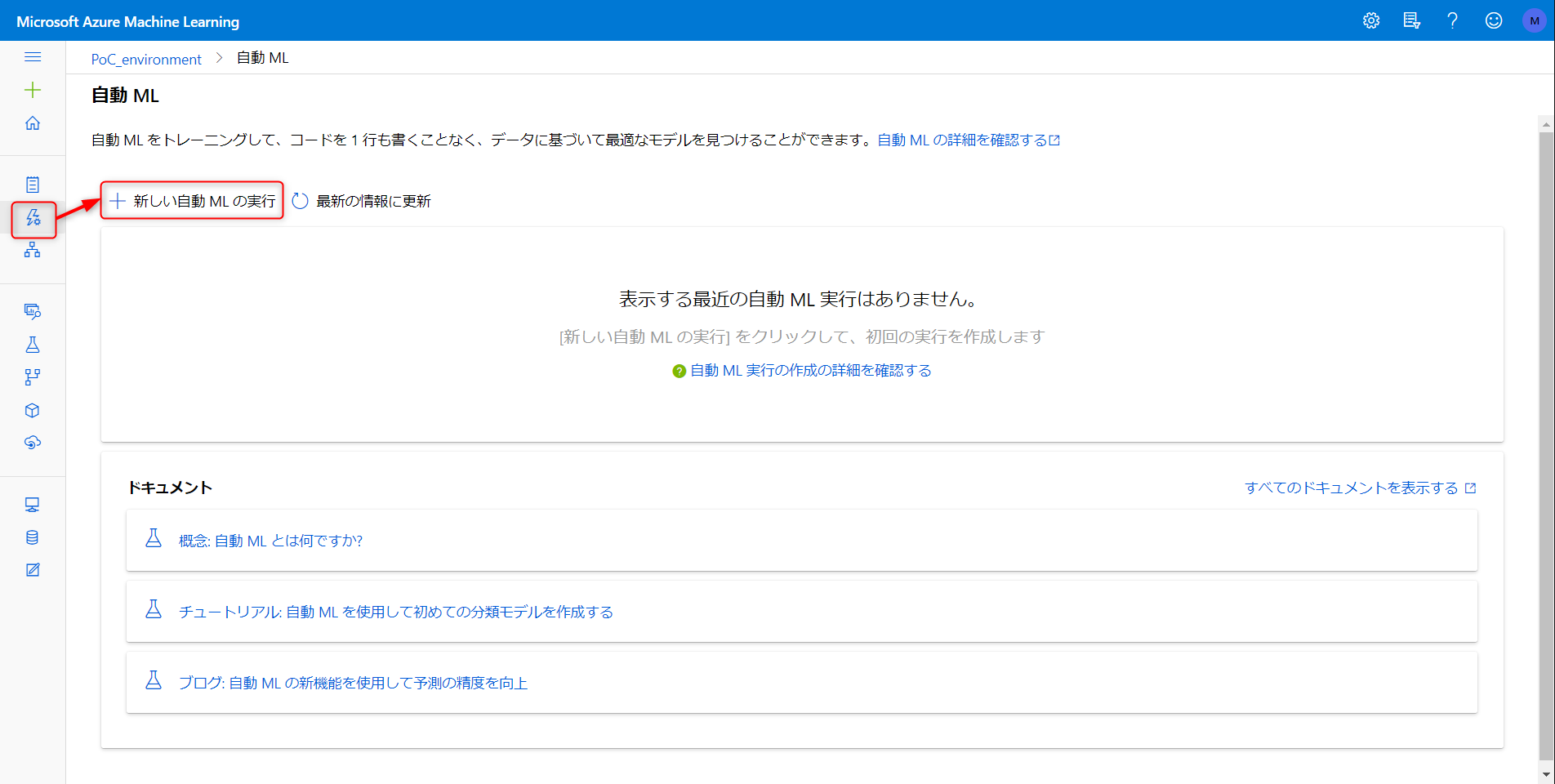
自動 ML → 新しい自動 ML の実行へと進む
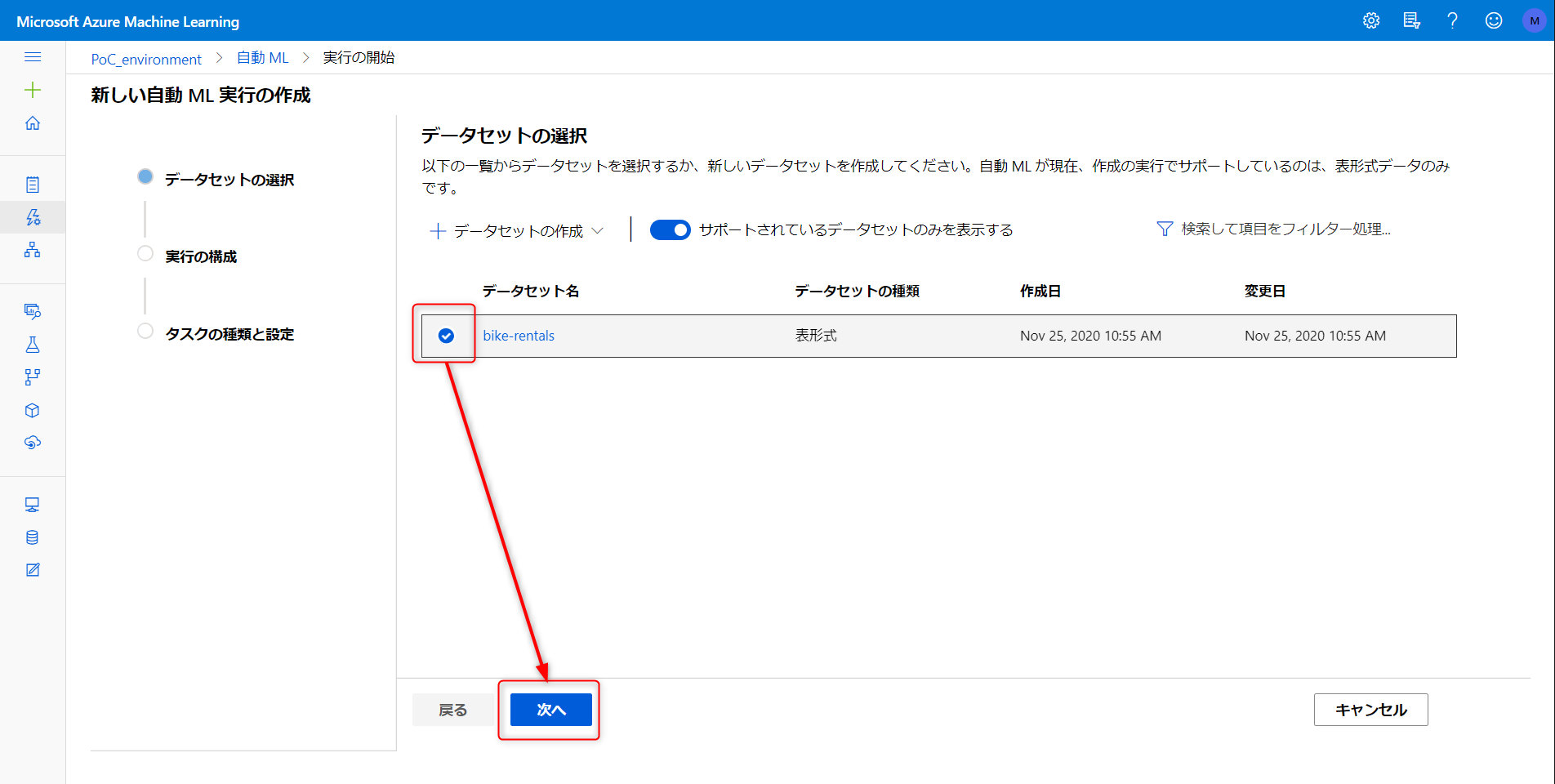
先ほど作成したデータセットを選択、次へをクリック
実験名称と予測したい列を入力、新しいコンピューティングをクリック

トレーニング用のクラスタの設定画面。最小ノード数を 0 にしておくとトレーニングジョブが実行中でない場合に課金が発生しないようになります。小さいデータセットなので最大ノード数は 1 に設定。完了したら次へをクリック

追加の構成設定を表示するをクリックし、評価指標や検証方法などを指定、保存。

画面遷移後、終了をクリックすると実験がスタートします

備考:回帰モデルの設定項目概要
設定項目の超概要です。さしあたり自分が利用するデータについて妥当性が判断できるくらいのざっくりとして知識があればいいんじゃないかなと思います (思いたい)
-
プライマリメトリック
- 自動的にモデルを作る際に指標とするパラメータのこと
- 予測と値の差がどのくらい離れているかの指標
- 今回は正規化された平均平方二乗誤差 (nRMSE)を選択
- AutoML の回帰で利用できるメトリック
- R2 スコア
- 一番直感的に理解しやすい指標。モデルの絶対評価指標としてよく使われる
- 0 から 1 の値をとる
- 自然に起こる確率をもとにしたモデルでは 0
- 100% 予測と値が一致してれば 1
- 正規化された平均絶対誤差 (nMAE)
- 予測と値の絶対値の平均を正規化したもの
- 回帰におけるもっとも基本的な指標
- データに対するロバスト性が高い
- 変化に対してモデルの挙動を安定させたいときに
- 正規化された平均平方二乗誤差 (nRMSE)
- 誤差の事情を平均して平方根をとったものを正規化したもの
- 統計の世界ではこれが一般的らしい
- 大きく予測値から外れた値に対して強い罰則
- スピアマン相関
- データに対して順位しか付けられないときに
- R2 スコア
- 最適なモデルの説明
- 各特徴量の影響度をみたいのでオンに
- 自動的にモデルを作る際に指標とするパラメータのこと
-
ブロックされたアルゴリズム
- 大規模データセット扱う場合、モデリングに時間がかかる処理を避けたい場合に
- 出来るだけ多くのアルゴリズムで試したいので今回は特に設定しない
-
終了条件
- トレーニングジョブ時間
- トレーニング完了までに許容する時間の上限値
- メトリック スコア閾値
- 指定したプライマリメトリックに対して設定する閾値
- この数値を上回ったら実験を自動終了してくれる
- トレーニングジョブ時間
-
検証
- K分割交差検証
- サンプルデータを K 個に等分、そのうち一つをテストデータ、その他でトレーニング
- テスト/トレーニングのペアを順繰りにセット、実行してモデルを検証
- 全部のデータが1回テストされるので公平
- データセットが意図的にパーティション分割されてる場合は注意が必要
- モンテカルロ交差検証
- データの一部をランダムに引っ張ってきてトレーニングセットに、残りをテストに
- これを複数回やってモデルを検証
- より偏ったモデルになる可能性も
- トレーニングと検証の分割
- 手動でデータ分割の割合をしてい
- 自動
- よしなにやってくれる
- K分割交差検証
実行結果比較
以下は実験の一覧。各実験で生成された最適なモデルを比較できます。列の編集やグラフの追加でダッシュボードのカスタマイズできます。
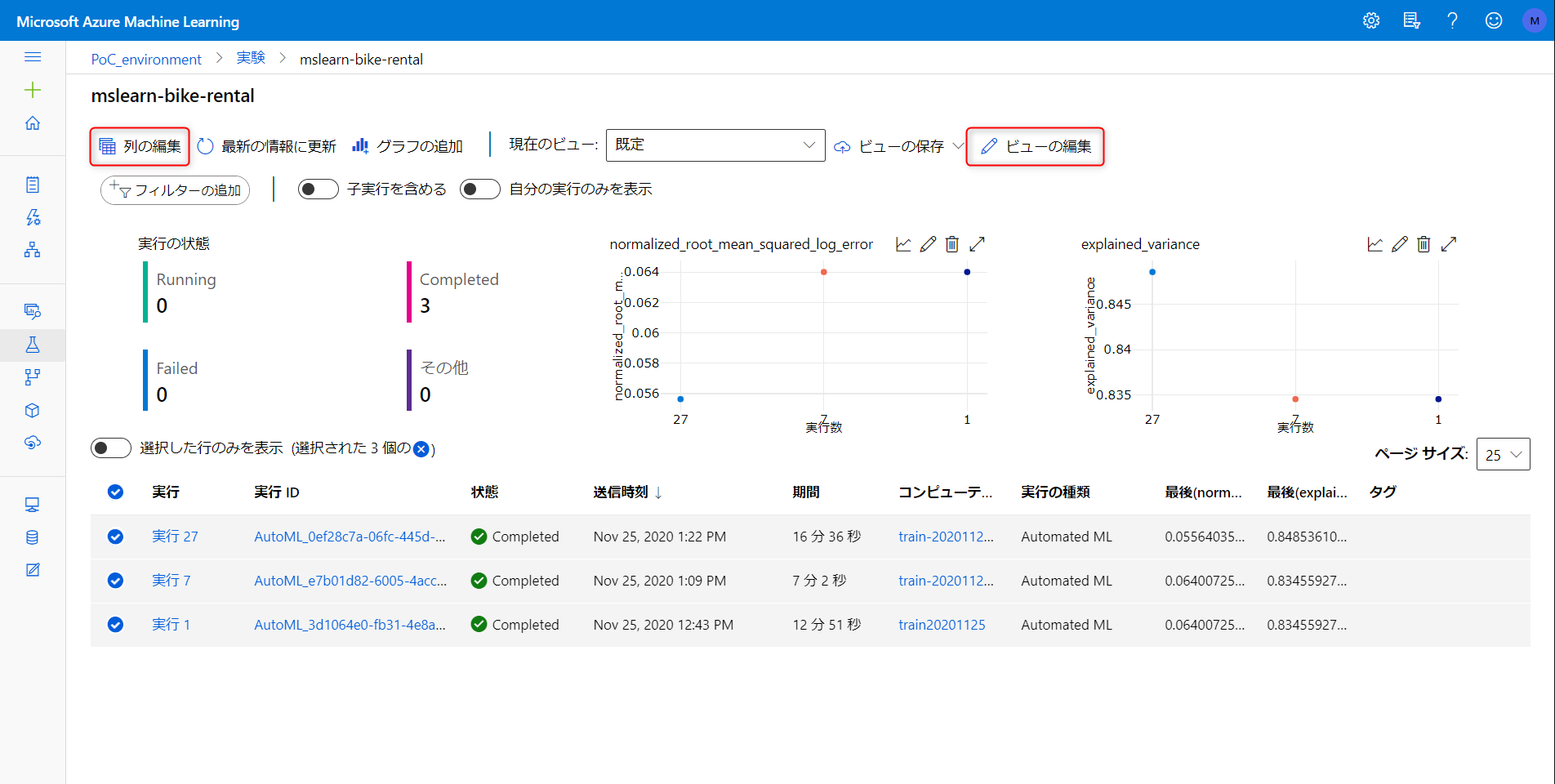
設定パラメータでの結果を比較するため、以下3パターンでテストしてみました。すべて実験名 mslearn-bike-rental で実行しています。
| 実行番号 | コンピューティング | 最大ノード数 | ジョブ時間 | スコア閾値 | 結果-実行時間 | 結果-最適モデル | 結果-最適モデルのスコア値 |
|---|---|---|---|---|---|---|---|
| #1 | STANDARD_D1_V2 | 1 | 0.25 (15分) | 0.08 | 12分51秒 | MaxAbsScaler, LightGBM | 0.07989 |
| #7 | Standard_DS3_v2 | 10 | 0.25 (15分) | 0.08 | 7分2秒 | MaxAbsScaler, LightGBM | 0.07989 |
| #27 | Standard_DS3_v2 | 10 | 0.25 (15分) | 0.07 | 16分35秒 | VotingEnsemble | 0.07623 |
#1 は考えうる最小構成のコンピューティングで実行、#2 はデフォルト設定のコンピューティングリソースで実行した場合。15分のうちクラスタの立ち上げに数分かかることを考慮すると内部処理は相当早くなっているみたいです。
#3 は #2 と同じコンピューティングでより精度目標を高く設定した場合。最適モデルが VotingEnsenmle になってるので、複数の学習済みモデルを作って多数決で推論結果を求めたモデルが最適のモデルでしたよ、ということになります。
実験 - 詳細
実験名をクリックするとこの画面に遷移します

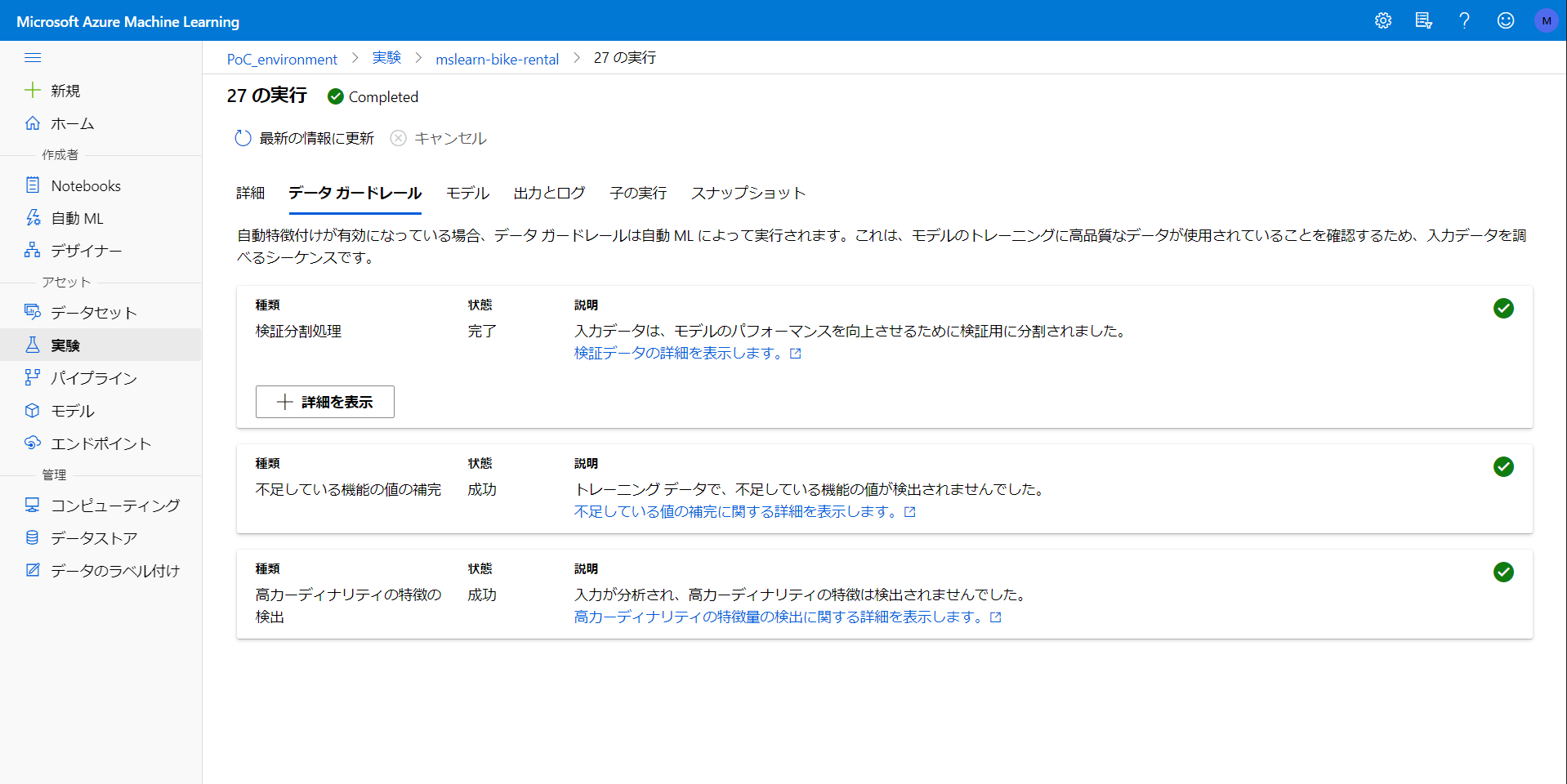
実験 - データガードレール
どんな条件でクロスバリデーションや欠損値保管が実行されたかを確認できます
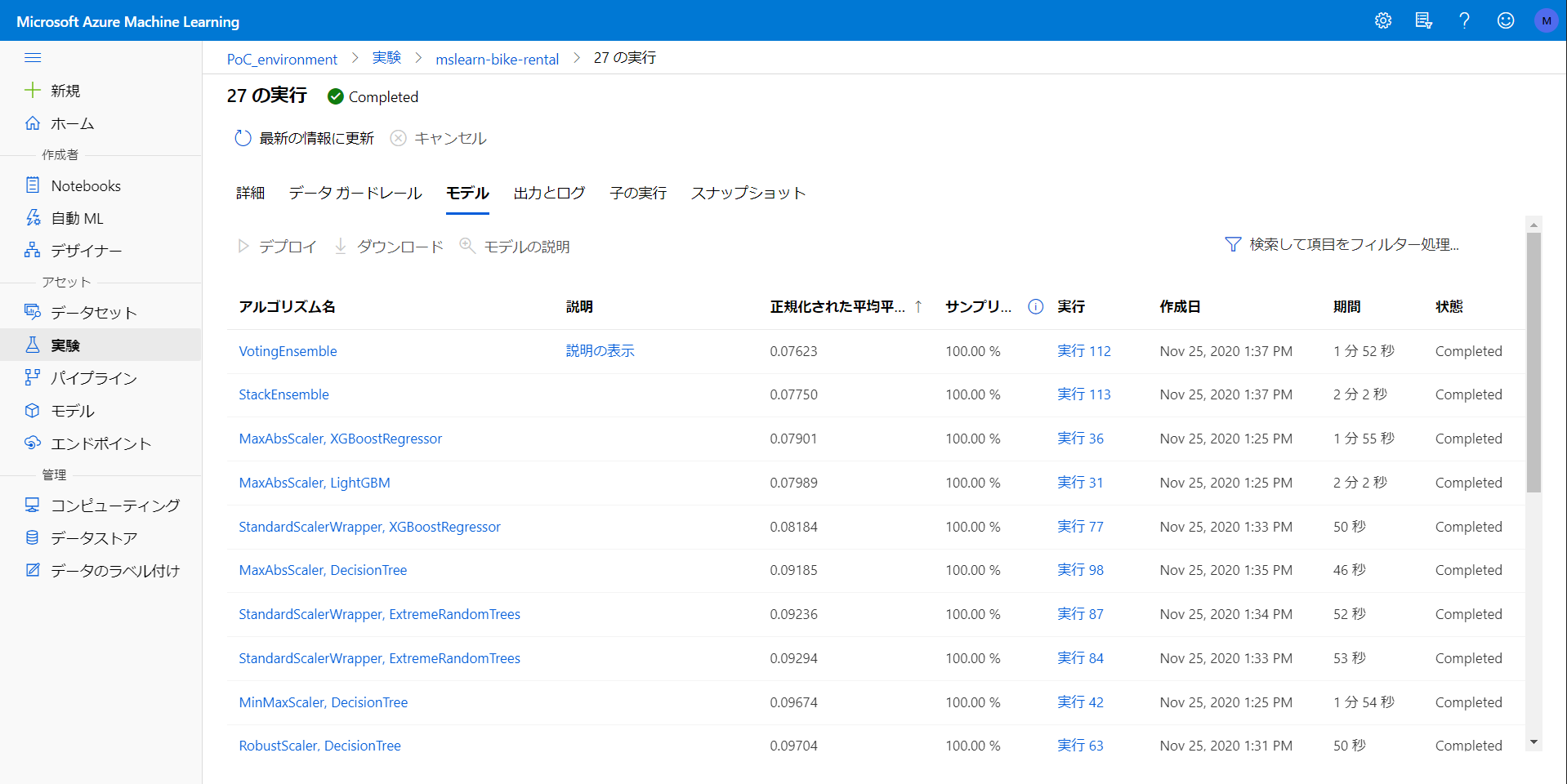
実験 - モデル
テストされたすべてのモデルの比較ができます。それぞれのモデルのダウンロードも可能
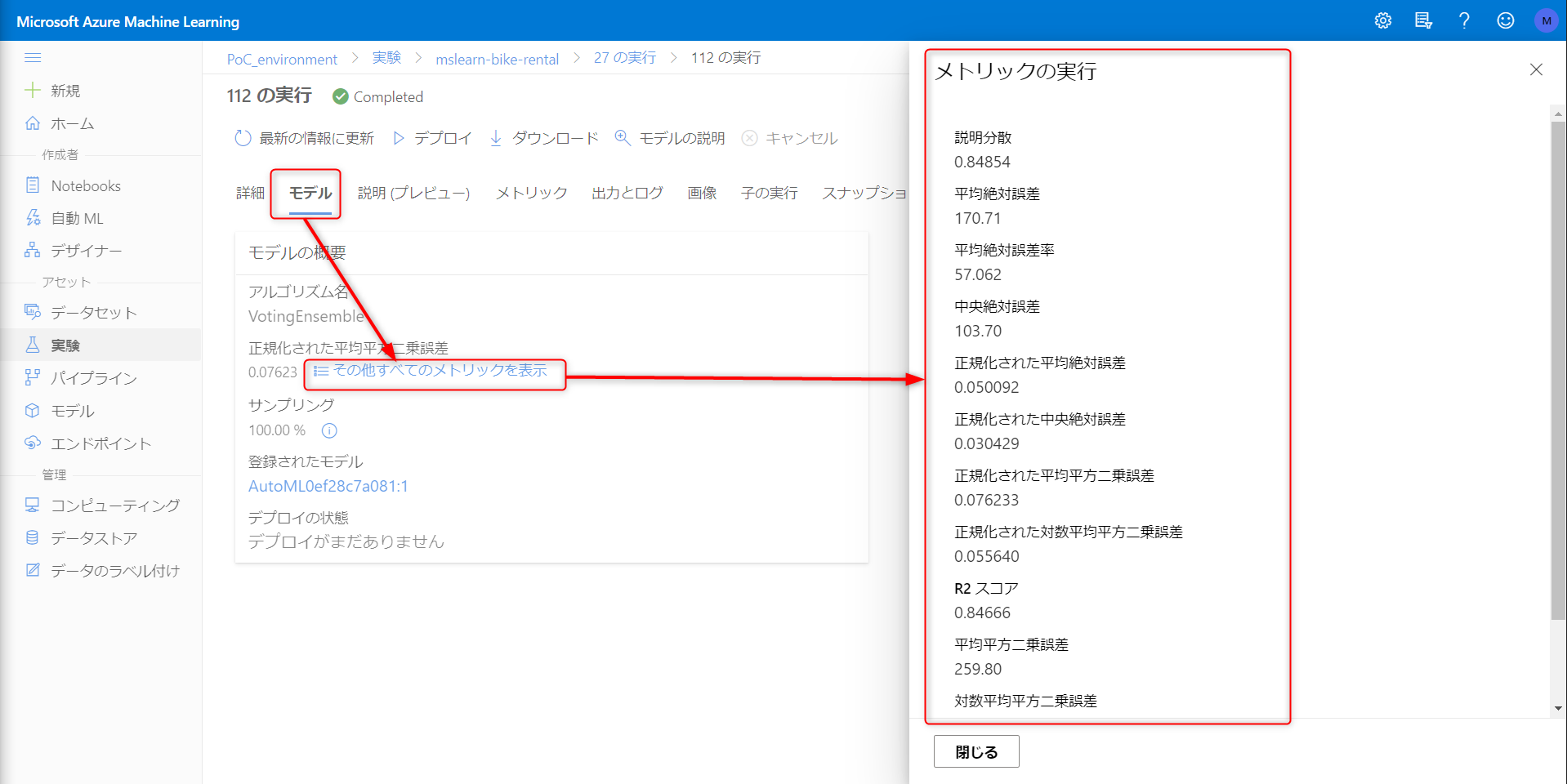
モデル - 概要
特定のアルゴリズムをクリックするとこちらの画面に遷移します。各種メトリクスの確認できます。
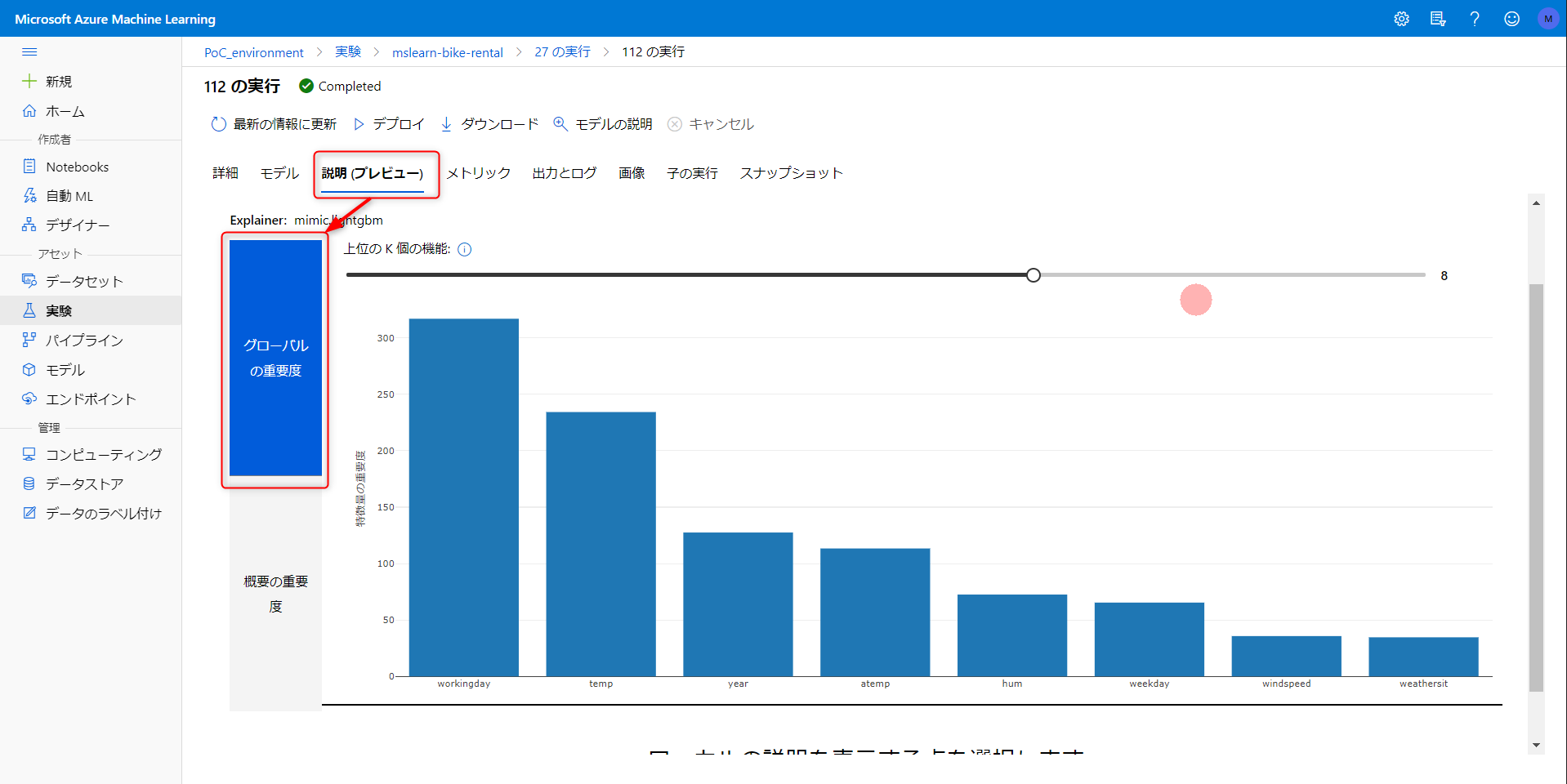
モデル - 特徴量重要度
- workingday
- 重要度高いのはイメージ通り
- レンタルバイクの用途は設置場所によって様々なはず。もっと背景を知りたいところ。
- temp や hum などの天候を表す指標はレンタル日から前の日との差分を指標としても面白いかも
- Year は説明変数とするのは不自然?
- weathersit や season は取り扱いが難しそう…
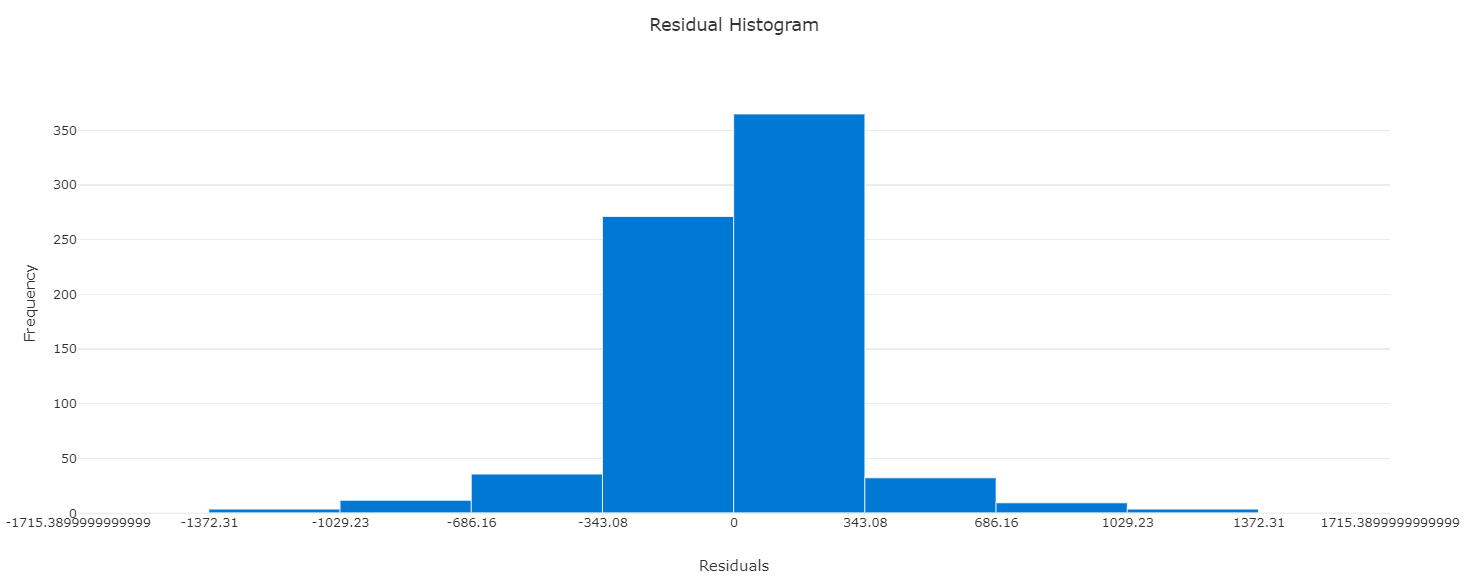
モデル - 残差ヒストグラム
- メトリックタブで確認できます
- 予測と値の誤差のばらつきですね
- 理想的にはゼロ付近で正規分布
- そうでない場合は何らかの規則性や分散の偏りをチェックして手立てを考える
- bin 数は変えられないみたいです (2020年12月)
モデル - Predicted vs True
- これもメトリックタブ
- 上のグラフのX軸は実際の値、Y軸は予測値
- 理想的には緑の点線 (実際の値 = 予測値)
- 下は実際の値のヒストグラム
- これも bin 変えられない?

モデルのデプロイ
前項で作成した Voting Ensemble のモデルをデプロイします。
実験 → 実験名 → 実行ID → アルゴリズム名と進みます

デプロイをクリック。運用ステージでは AKS でのデプロイが良いそうですが、テスト環境ということで ACI サービスをコンピューティングリソースに指定、認証を有効にし、デプロイをクリック

エンドポイント → 使用と進み、REST エンドポイントと主キーを控えておきます。(デプロイ成功の表示からエンドポイントURLが表示されるまでタイムラグがあるので注意)

サービスのテスト
作成しておいた Notebook を開き、

Notebook の1セル目に以下スクリプトを入力、セルが選択されている状態で shift + enter を押すとスクリプトを実行できます。
endpoint = '{生成したREST エンドポイント名に置き換え}'
key = '{生成した主キーに置き換え}'
import json
import requests
# テスト用の5日間分の気象予報データ設定
x = [[1,1,2022,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446],
[2,1,2022,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539],
[3,1,2022,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309],
[4,1,2022,1,0,2,1,1,0.2,0.212122,0.590435,0.160296],
[5,1,2022,1,0,3,1,1,0.226957,0.22927,0.436957,0.1869]]
# データフレームを JSON に変換
input_json = json.dumps({"data": x})
# リクエストの書式と認証方式を指定
headers = {"Content-Type":"application/json",
"Authorization":"Bearer " + key}
# リクエスト送信
response = requests.post(endpoint, input_json, headers=headers)
# エンドポイントからレスポンスあったら結果を表示
if response.status_code == 200:
y = json.loads(response.json())
print("Predictions:")
for i in range(len(x)):
print (" Day: {}. Predicted rentals: {}".format(i+1, max(0, round(y["result"][i]))))
else:
print(response)
以下の返り値を得られます。問題なくデプロイされているようですね。

さいごに
デプロイまでコード一行も書かずに進められるのは驚きです。
1時間もあれば一通り試せるので是非。このままだと課金が発生してしまうので、エンドポイントの削除とNotebookに紐づくインスタンスの停止は忘れずに。
参照
Azure Machine Learning のドキュメント
Azure Learn 記事:Azure Machine Learning で自動機械学習を使用する
利用データ:Capital Bikeshare
Understanding Cross Validation