はじめに
タイトル通り、SparkSQL で時系列仮想データテーブルを作る関数です。以下のような方を想定。
- 最近 Spark さわり始めた
- 時系列データで Window 処理をバッチ的に行いたい
- SparkSQL で普通にクエリが書けると聞いたけど、
- MySQL でのいつものメソッドは使えなさそう
- PostgreSQL の Generate Series が使えればいいのに
関数
こんな感じで書きました。開始日、終了日、秒単位のインターバル、テーブルの行名を引数にしています。
def generate_series(day_start, day_end, sec_interval, col_name):
# day type: str
# day format: 'yyyy/MM/dd'
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# day_start から day_end までのタイムスタンプ df 作成
start, stop = spark\
.createDataFrame([(day_start, day_end)], ("start", "stop"))\
.select([col(c).cast("timestamp").cast("long") for c in ("start", "stop")])\
.first()
# 指定したインターバルで select
calendar_table = spark\
.range(start, stop, sec_interval)\
.select(col("id").cast("timestamp")\
.alias(col_name))
return calendar_table
使用例
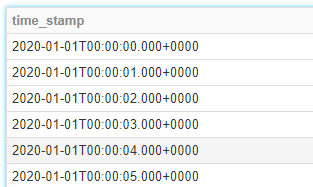
1秒ごと
start_date = '2020/01/01'
end_date = '2020/01/31'
# #1秒毎のテーブル
cal = generate_series(start_date, end_date, 1, 'time_stamp')
display(cal)
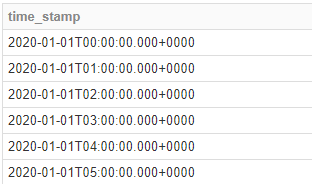
1時間ごと
start_date = '2020/01/01'
end_date = '2020/01/31'
# #1時間毎のテーブル
cal = generate_series(start_date, end_date, 60*60, 'time_stamp')
display(cal)
おわりに
とりあえずは動作しますが、、
- この関数使えば一発じゃん
- こんな非効率なことして…
という方、情報いただけると大変うれしいです。