はじめに
Spark df でヒートマップを作るたびに何度も同じことを調べてるので、備忘録がてら関数にしておきます。
関数
Spark dfと、相関を調べるカラムを入れたリスト、2つを引数に取ります。
def sparkdf_to_heatmap(spark_df, col_lis):
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# 図の見た目指定
# 見た目を逐一変えたい場合は引数に入れ込む
# style_option from: 'paper', 'notebook', 'talk', 'poster'
style = 'poster'
color = 'Blues'
fig_width = 30
fig_height = 15
linewidth = .5
fmt = '.2f'
sns.set_context(style)
df_pd = spark_df.select('*').toPandas()
df_pick = df_pd.loc[:, col_lis]
fig, ax = plt.subplots(figsize=(fig_width, fig_height))
ax = sns.heatmap(df_pick.corr(), annot=True, cmap=color, linewidth=linewidth, fmt=fmt)
display(fig)
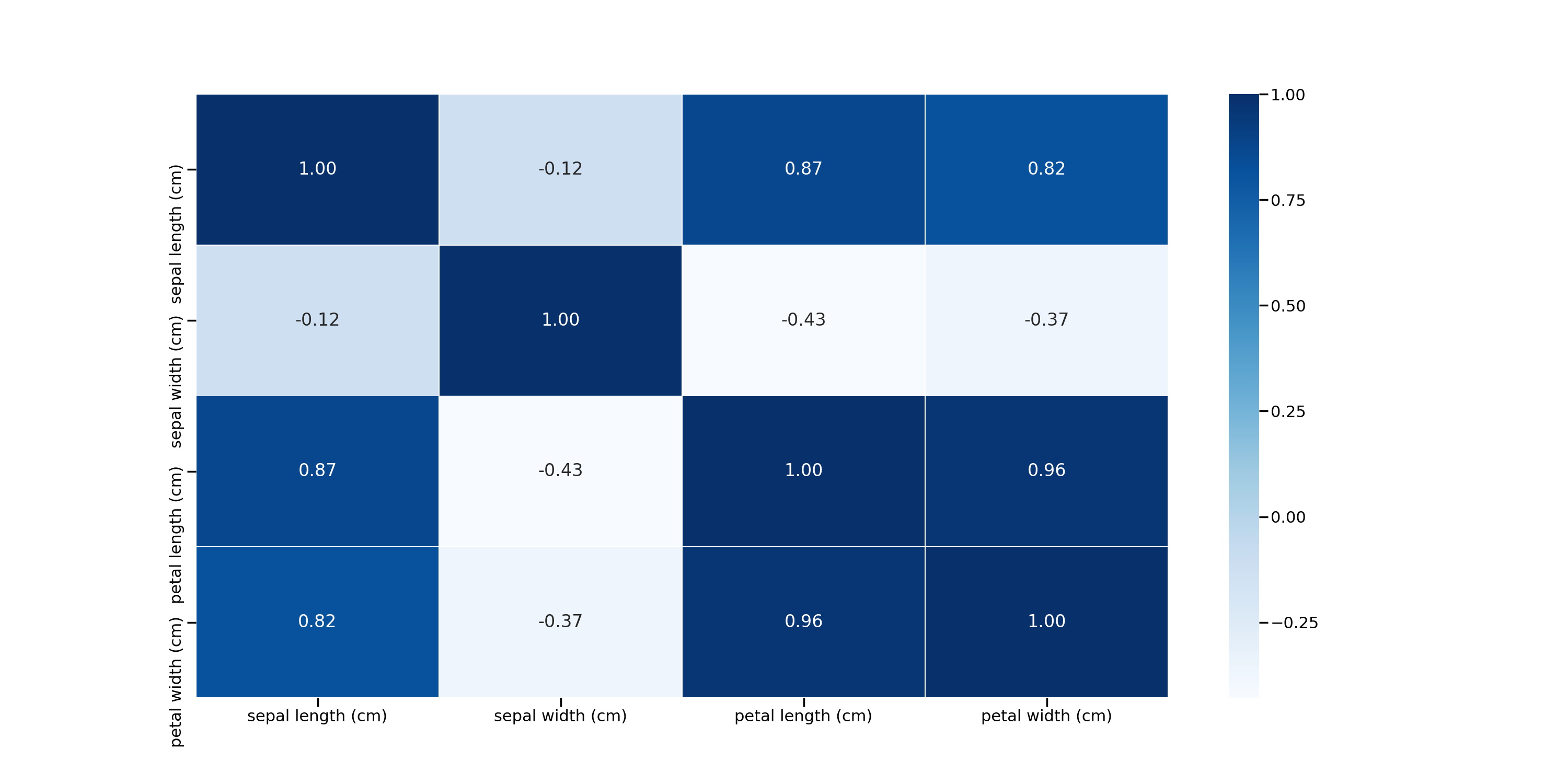
使用例
iris で試してみます。
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# Enable Arrow-based columnar data transfers
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
col_lis = iris.feature_names
iris_pd_df = pd.DataFrame(iris.data, columns=col_lis)
iris_spark_df = spark.createDataFrame(iris_pd_df)
sparkdf_to_heatmap(iris_spark_df, col_lis)
さいごに
Pandas df にするときにクラスタが走っちゃってるので頻繁に行う場合には要注意。小規模データでさっとカラムの相関を見たいときに。