はじめに
深層学習に関する研究の多くは予測精度の向上に焦点を当てているが、どんなときに予測を誤ってしまうのかを検出するにはどうしたら良いかというテーマについての研究も数多くなされている。この記事ではガウス過程を考えることで、モデルの予測の誤りを検出する研究を紹介する。ただし、厳密な理論の部分にはできるだけ触れないようにする。
ガウス過程とは
噛み砕いて言えば、ガウス過程とは学習データを入力したら、モデルの最適なパラメータを一つ出力してくれる関数の確率分布のことである。通常、あるモデルにデータを学習させると最適なパラメータをもつモデルが得られるが、もう一度モデルのパラメータを初期化し学習させると、先ほどとは異なるパラメータを持つモデルが得られる。これらのパラメータが、ある確率分布に従ってサンプルされたものと考えるのがガウス過程である。
ガウス過程を考えるメリット
ガウス過程を考える最大のメリットは、モデルの予測の不確かさを捉えることができる点にある。例えば、学習データの不足している場合、予測はモデルごとに大きくばらつくことが予想される。一方で、十分に学習データがある場合には、予測のばらつきは小さくなることが予想される。モデルの予測のばらつきを不確かさとして考えれば、予測の誤りを検出できるようになる。
これは、応用上極めて重要なことで、自動運転など予測の結果が人間の安全を脅かすような状況において、確信を持てずに予測をした場合に警告を出すようにし、人間に直接確認を促すようにすることで、重大な事故を未然に防ぐことができるようになる。
深層学習は他にも医療や製造業等、様々な分野での応用が期待されていることから、モデルの予測の不確かさを知ることはこれから注目されていくのではないかと考えている。
研究の紹介
ガウス過程とはデータに対するパラメータの事後確率分布だと説明した。データセットをZ=(X,Y)とし、パラメータを$W$とするとこの事後確率分布は$p\left(W\mid(X,Y)\right)$となる。しかし、直接求めることは難しいのでたくさんのパラメータを求めることで、その分布の特性を求めるというのが多くの研究に共通することである。
ベイズ変分推論を用いた研究
何個ものパラメータを求めるのは計算コストが高く実践的ではない。そこでベイズ変分推論を用いてその問題を解決しようという研究がある。ベイズ変分推論とは$p\left(W\mid(X,Y)\right)$をパラメータ$\theta$で表される、ある確率分布$q\left(W;\theta\right)$で近似する手法のことである。
Dropoutを用いた手法
私の知る限りでは、深層学習においてベイズ変分推論を適用した最初の研究は[1]である。この研究では$q\left(W;\theta\right)$をDropoutの確率分布としている。これはDropoutを適用させて学習させてできたモデルについて、Dropoutによって表現されるモデルの一つ一つが、別々に学習させてできたものとみなせるようになるというアイデアを使っている。これについての詳しい説明は[2]に書いてあり、簡単に説明すると次のように各層にDropoutを適用させると、ある構造のモデルが得られる。
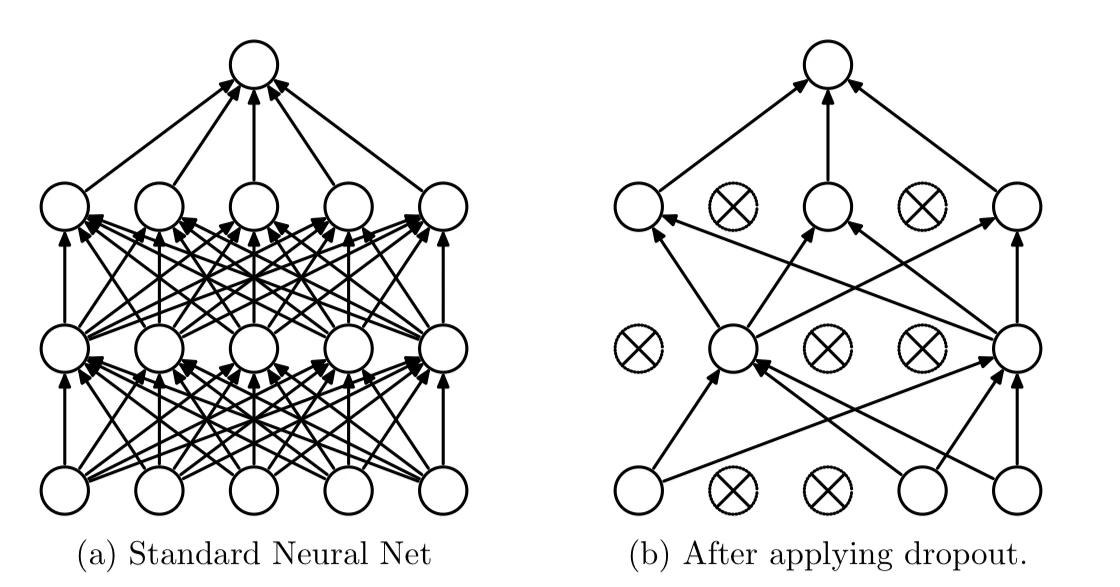
左がDropoutを適用する前で、右が適用後である。Dropoutによって出力を0にするノードの組み合わせによってモデルの構造のバリエーションを表現している。このDropoutによってどのノードを0にするのかをパラメータとするモデルの確率分布$q\left(W;\theta\right)$を使いモデルのパラメータの事後確率分布を近似的に求めようというのが[1]である。
また、Dropoutを使ったベイズ変分推論については[3]でも言及されており、その実験の方がわかりやすいので、その結果を紹介する。
Dropoutの実験結果
[3]におけるDropoutの効果の検証にあたっては、DenseNetをセグメンテーション用のデータセットであるCamvidについて学習させている。その後、テスト時に一枚の入力画像に対して、何度もDropoutを適用させ、その分散を計算し予測の不確かさとしている。

画像の下に書いてある通り、左から入力、正解、予測、(d)は飛ばして、(e)がDropoutの分散値である。一番下の結果を見ると、歩道の部分(青色)の予測が誤っていることがわかる。それに対して、(e)は赤くなっており、これは予測が誤りやすい部分に対してきちんと誤りやすさを捉えることができていることを意味している。
このようにベイズ変分推論を用いることによりパラメータの分布を近似でき、予測の誤りやすさを捉えることができるのである。ベイズ変分推論に関する研究は他に[4]があるが、紹介するだけにとどめておく。
アンサンブルを用いた手法
いくつもモデルを用意するのは大変だけど、用意しさえすれば分布($p\left(W\mid(X,Y)\right)$)の特性がわかるなら力技で用意してしまえというのがアンサンブル[5]である。M個のモデルに対して入力の不確かさを次のように定義している。
$$\sum_{m=1}^{M}KL\left(p_{\theta_m}(y\mid x)\mid\mid p_E(y\mid x)\right)\tag{1}$$
ただし、
$$p_E(y\mid x)\overset{def}{=}M^{-1}\sum_{m=1}^{M}p_{\theta_m}(y\mid x)$$
KLとはKLDivergenceのことで、二つの確率分布に対して定義される量である。二つの分布が似ていれば小さく、そうでなければ大きくなる性質がある。また必ず正であり、完全に一致すれば0になる。
MNISTデータセットに対して、上記の式を使った実験結果が次の図である。

(a)の上の図は、MNISTを学習させた後、MNISTのテストデータに対する(1)の計算結果のヒストグラムで、下の図はNotMNISTデータを入力としたときの(1)のヒストグラムである。期待されることとして、この手法によって入力がMNISTならば分散は小さく、notMNISTであるデータであれば分散が大きくなることである。なぜならば、学習しているデータに対する予測は、どのパラメータも同じような予測をするのに対し、学習していないデータに対する予測は、どのパラメータも異なることが期待されるからである。
結果を見てみると、MNISTのテストデータは分散値のヒストグラムはかなり低いところに多く存在していることがわかる。一方で、NotMNISTデータは学習用データとは似ていないため分散値のヒストグラムはより大きくなっていることがわかる。また、用意する学習済みモデルの数が多いほどより分散値が大きくなっており、MNISTのテストデータと分離できることをここでは主張している。同様に(b)はSVHNとCIFAR-10を使った実験結果であり、こちらも同じような結果が得られている。
この論文の結論として、5つのモデルを用意すれば十分にモデルの不確かさが得られるとしている。これは理論的に言えば$p\left(W\mid(X,Y)\right)$の特性が5つのモデルでわかるということであろう。またここでは紹介しなかったが、論文ではDropoutとの精度の比較をしており、それを上回るということを主張しており不確かさを得るためにベイズを考える必要はないのではないかとも主張している。この根拠として[6]を合わせて引用しているが、この論文については深層学習におけるOverconfidence という問題にまとめてある。
Multiple-Hypotheses Networks
何個ものモデルを用意するのは大変だし、Dropoutも検証時に何度もサンプリングする必要があって大変だった。そんなこんなで、この二つの問題を解決するのではないかと考えられたのがMultiple-Hypotheses Networks[7][8]である。このモデルは、M個の予測を同時に出力するという特徴がある。それらの一つ一つの予測を別々のモデルで学習させたものとみなし、不確実性を出力している。最適化においてはWinner Takes-All Lossと呼ばれる方法が用いられ、ここのモデルの予測をより多様にする効果があるという。
[7]の実験結果
[7]では回帰タスクであるOptical Flowに対して適用させている。回帰ではモデルは予測値のみを出力するため、その予測の不確実性は出力しない。そのため、回帰においては特にモデルの予測の不確実性を知ることは非常に価値のあることである。

上の実験結果は左から入力、予測、不確実性である。見ての通り車の陰になっている箇所が赤くなっており、周りに比べて相対的に不確実性が大きくなっている。一方で、車は相対的に薄い青色になっており、確信を持って予測しているのだということがわかる。このように一つのモデルが複数の予測を出力させるような構造をもたせても、きちんと不確実性を出力できることがわかる。
まとめ
いくつかの研究を紹介したが、実験の評価方法は統一されておらずどれが一番いいのかについてはわからない。理論上アンサンブルはDropoutの上位互換であるが計算量の観点から一概にそれがいいということはできないだろう。一方で、[5]に書いてあるように果たして本当にベイズを考える必要があるのか疑問である。その根拠として分類について言えば、モデルの出力はそのまま予測の誤りやすさとして考えることができるからである。さらに、それは新しいアルゴリズムを実装する必要がなくモデルも変える必要がない点は、応用上の保守管理の観点から大きなメリットであろう。
ちなみに、信頼度がそのまま予測の誤りやすさとして捉えることができるのだが、それをセグメンテーションタスクにおいて可視化してみたらどうなるのかというのは気になると思う。そこで[3]のDropoutの可視化と比較してみたのが次の図である。
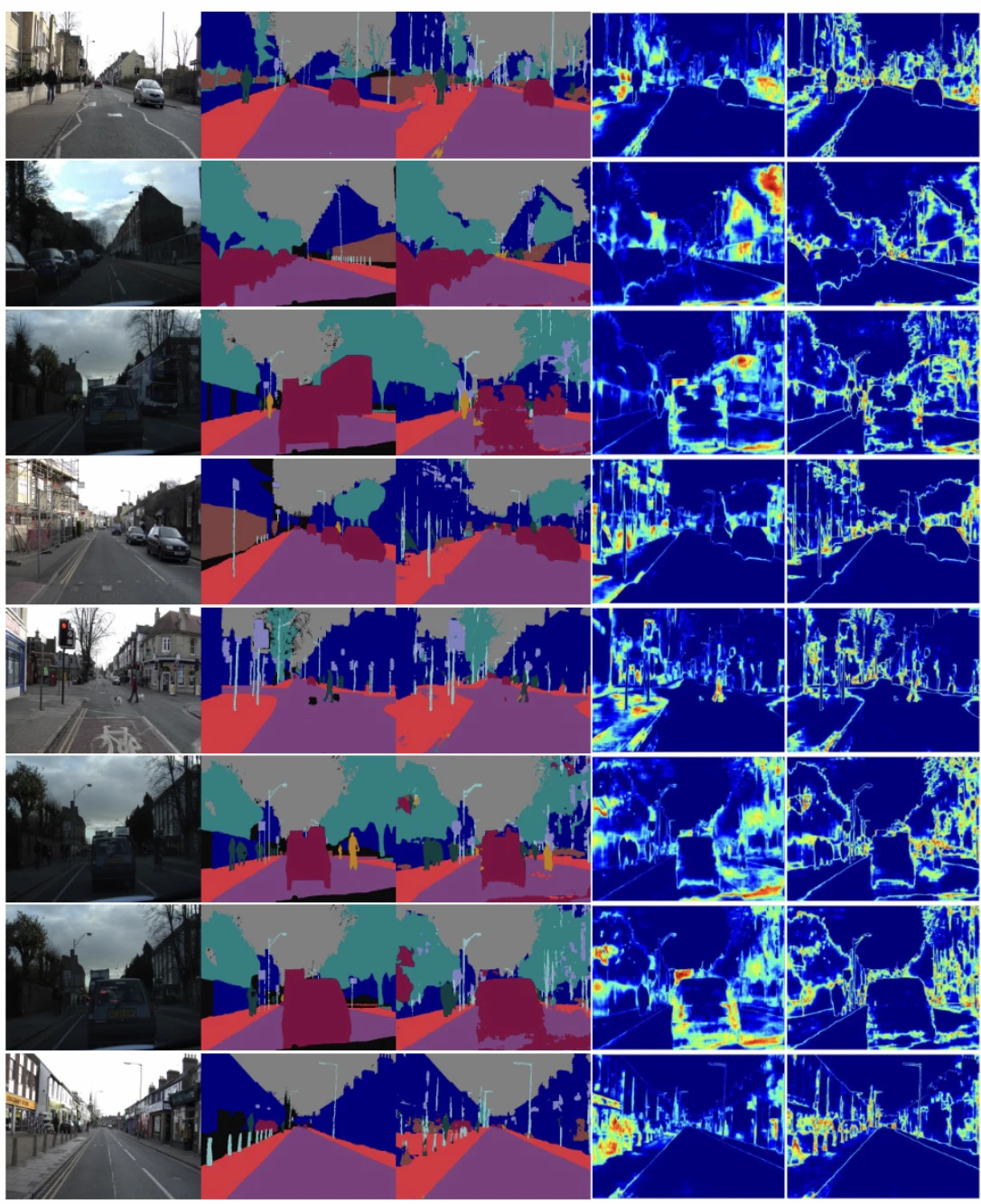
左から入力、ラベル、予測Dropout、信頼度(Softmaxの最大値)である。見ての通り、予測が誤っている箇所の信頼度は低い傾向にあり、道路と歩道の境界部分は分類が困難な箇所だが、信頼度が小さくなっていることがわかる。
以上の結果からも個人的には分類においてベイズを考える必要はないのではないかと思っている。なぜならば[6]の通り、モデルの出力自体が予測の誤りやすさとして解釈できるからである。
参考文献
[1] Z. Ghahramani Y. Gal.Dropout as a Bayesian approximation: representing modeluncertainty in deep learning. In Proceedings of International Conference on MachineLearning, 2016.
[2] A. Krizhevsky I. Sutskever-R. Salakhutdinov N. Srivastava, G. Hinton. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. The Journal of MachineLearning Research, 15(1), 2014.
[3] Y. Gal A. Kendall. What Uncertainties Do We Need in Bayesian Deep Learningfor Computer Vision? In Proceedings of Neural Information Processing System,2017.
[4] A. Maurin M. Olsen K. Shridhar, F. Laumann. Bayesian Convolutional Neural Networks with Variational Inference. arXiv preprint arXiv:1704.02798, 2018.
[5] C. Blundell B. Lakshminarayanan, A. Pritzel. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In Proceedings of Neural InformationProcessing System, 2017.
[6] Y. Sun Q.Weinberger C. Guo, G. Pleiss.On Calibration of Modern Neural Networks. In Proceedings ofInternational Conference on Learning Representations,2017.
[7] S. Galesso A. Klein-O. Makansi F. Hutter T. Brox E. Ilg, O. Cicek. Uncertainty Estimates and Multi-Hypotheses Networks for Optical Flow. arXiv preprintarXiv:1802.07095, 2018.
[8] R. DiPietro M. Baust-F. Tombari N. Navab G. Hager C. Rupprecht, I. Laina.Learn-ing in an Uncertain world: Representing Ambiguity through Multiple Hypotheses.In Proceedings of International Conference on Computer Vision, 2017.