会社でNEXT AIという次のAI(最新動向)の流れを把握する取り組みがあり、最新技術検証的な取り組みをしています。個人的に良い検証結果が得られたので、こちらの記事で公開しようと思います。
【概要】
- claude-3-5-sonnet-20241022 API、gpt-4o APIを活用し、PDFの内容を構造的なテキストに変換する。構造的なテキストをvector DBのindexに登録しRAGの精度検証を実施
- RAGを構築しポイントごとに評価観点を設ける。評価ポイントは下記の【RAGの評価】を参照
- LangSmithにデータセットを登録し、RAGの最終回答を評価する
- 評価するケースは下記の3つのRAG
- claude-3-5-sonnet-20241022で前処理をしたRAG
- gpt-4oで前処理をしたRAG
- 前処理をしないRAG(PDFをロードしてそのままindexへ登録)
- 活用するPDFデータはインターネット上に公開されている農林水産省のPDFを活用
- ClaudeのPDF処理については、下記の【ClaudeのPDF処理】を参照
【ClaudeのPDF処理】
Claude PDFサポートを参照。
PDFサポートをしていないときは、PDFを画像に変換しvision APIを活用していた。
ClaudeがPDFサポートのAPIを公開して、PDFをそのままAPIのリクエストボディに含めてAPIを実行することができる。
2024/12時点では、gpt-4oはPDFをサポートしていないため、PDFを画像に変換して、gpt-4oのAPIを実行している。
下記の【精度結果】でClaudeとgpt-4oで精度に差が出た理由は、Claudeはテキストと画像の組み合わせでPDFの視覚的要素に関する内容を把握しているからだと思われる。
ClaudeがPDFからテキスト出力した結果を見ると、PDF内の関連性を把握してテキストを章立てで分かりやすくまとめて出力してくれる。
PDFの解像度や明確さはClaudeの解析精度に影響するので、PDF自体の解像度や明確さ(PDFの内容がぼやけて読み取りにくいか、PDFの内容が小さすぎて見にくいか、など)を確認してClaudeに前処理させると良い。
【背景】
RAGの構築は簡易的にできるが回答精度が高いRAGを構築することは難しい。
RAGの回答精度が期待値を超えることができずに導入を断念するクライアントが多い。
RAGの回答精度を上げるために何が重要で、まず何をすべきかを整理した方がRAGの導入はしやすい。
一般的に、PDFドキュメントをそのままロードしてindexへ登録してもRAGの回答精度は低い。
RAGの回答精度を高めるためにはDBへ登録する前のデータの前処理が重要。
LLMを使ってPDFのような構造化されていないデータを構造的なテキスト情報に変換するにも限界がある。
indexへ登録する前のデータをきれいにするため、人手の労力が必要となるケースが多い。
前処理工程で、人手の労力を極力減らすために、PDFの認識能力が高い Claude 3.5 Sonnet ( claude-3-5-sonnet-20241022)やgpt-4oを使って前処理を行いRAGの精度がどの程度向上するのかを検証
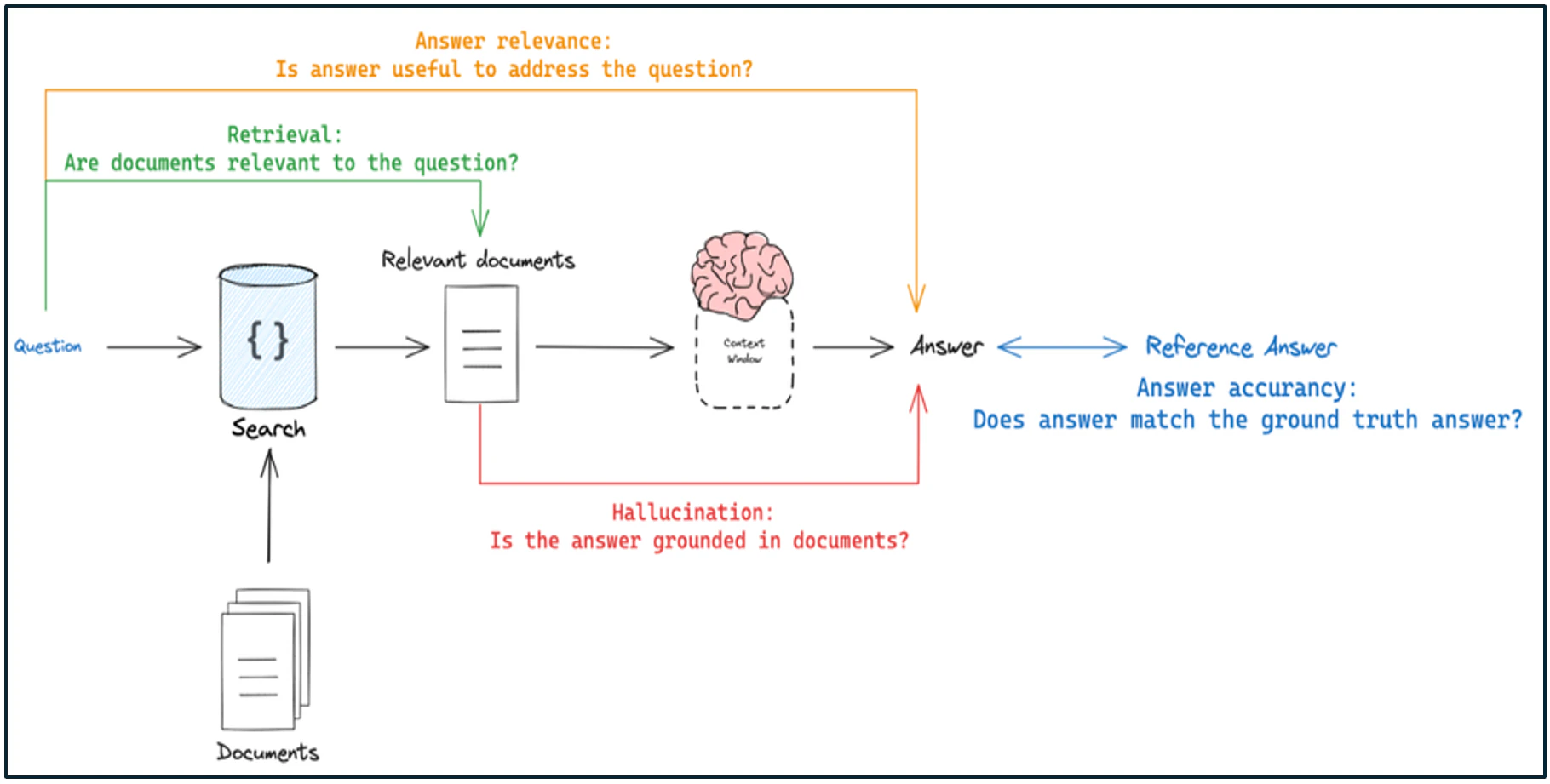
【RAGの評価】
下記の評価はLangSmith RAG Evaluationsを参考にしている。
-
Answer accurancy(最終的にLLMが生成した回答、クエリー、正解データ(模範回答)の3点セットをLLMにインプットし、クエリーに応じて正しい回答をしていることを検証)
-
Retrieval(クエリーとクエリーを元に類似検索したチャンクを検証。クエリーに応じたチャンクを取得できていることを検証)
-
Hallucination(類似検索を元に取得したチャンクから回答を生成していることを検証。チャンクの内容を無視、不要な情報を勝手に付与していないことを検証)
【方法】
一般的なRAGを構築しEmbeddingモデルは固定でOpenAIのtext-embedding-3-largeを利用。
回答合成のLLMはOpenAIのgpt-4o、4o-mini、4-turbo、3.5-turuboを利用してそれぞれのモデルを切り替えて精度を検証。
【前処理】
データの前処理でClaude or gpt-4oを活用し、データ整形後にindexへデータを登録。
サンプルで下記の農林水産省PDF 5Pを
Claudeで前処理する。
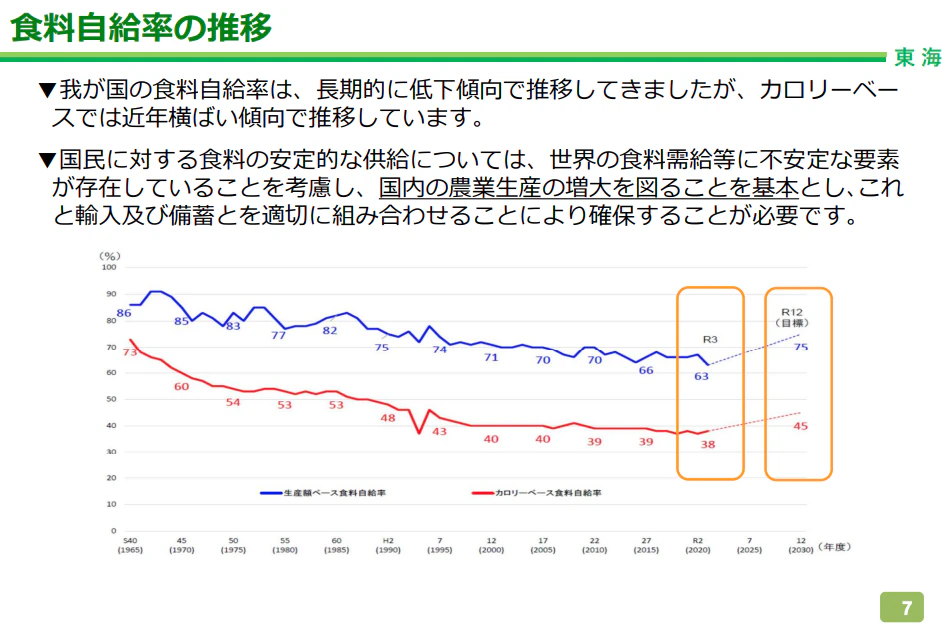
上記のPDFは下記のような構造的なテキスト(マークダウン形式)で出力することができる。
PDFの内容を構造的にテキスト化します。
# 東海農政局
## 食料自給率の推移
### 概要説明
1. 我が国の食料自給率は、長期的に低下傾向で推移してきましたが、カロリーベースでは近年横ばい傾向で推移しています。
2. 国民に対する食料の安定的な供給については、世界の食料需給等に不安定な要素が存在していることを考慮し、国内の農業生産の増大を図ることを基本とし、これと輸入及び備蓄とを適切に組み合わせることにより確保することが必要です。
### グラフデータ
食料自給率の推移(1965年度~2030年度)
#### 生産額ベース食料自給率の推移
1965年: 86%
1970年: 85%
1975年: 83%
1980年: 77%
1985年: 82%
1990年: 75%
1995年: 74%
2000年: 71%
2005年: 70%
2010年: 70%
2015年: 66%
2020年: 63%
2025年(目標): 75%
#### カロリーベース食料自給率の推移
1965年: 73%
1970年: 60%
1975年: 54%
1980年: 53%
1985年: 53%
1990年: 48%
1995年: 43%
2000年: 40%
2005年: 40%
2010年: 39%
2015年: 39%
2020年: 38%
2030年(目標): 45%
注:グラフは生産額ベース(青線)とカロリーベース(赤線)の2種類の自給率を示しており、2025年および2030年の値は目標値として点線で表示されています。
【評価用データセット】
LangSmithにCSV形式で、質問と質問の模範回答を記載する。
評価用のデータセットの件数は23件。評価用のデータ作成が手間だったので、さほど多くのデータを作成していない。
この23件のデータに対して、LLMが模範解答の内容と一致することを回答できるのかを測定。
input_input_question,output_output_answer
食料自給率の推移について。生産額ベースの食料自給率の2000年は何%でしょうか?,71%です。
食料自給率の推移について。1970年のカロリーベースの食料自給率は何%でしょうか?,60パーセントです。
食料自給率の推移について。カロリーベースの食料自給率が最も高い年は何年でしょうか?,1965年です。
食料自給率の推移について。生産性ベースの食料自給率が最も高い年は何年でしょうか?,1965年です。
農政を取り巻く状況の変化について。国内は2050年に人口はどれくらいになりそうでしょうか?,約1億190万人ほどです。
農政を取り巻く状況の変化について。世界の人口は2050年に何人くらいになりますか?,約98億人ほどです。
農政を取り巻く状況の変化について。世界は飲食料のマーケット規模は2015年から2030年でどれくらい変わる想定でしょうか?,2015年から2030年で、890兆円から1360兆円に成長する想定です。
農業従事者の減少・高齢化について。基幹的農業従事者の年齢構成の2020年の65歳から69歳までの人数を教えてください。,約14万人ほどです。
農業従事者の減少・高齢化について。各国の農業従事者の年齢構成の日本の各年齢に応じた割合を教えてください。,24歳以下は0.4%、25~49歳は10.4%、50~64歳は19.6%、65歳以上は69.6%です。
新規就農者の推移について。49歳以下の新規就農者の推移の平成30年の「親の経営に参加する・継ぐ」、「農業法人等に就職する」、「自分で起業して始める」のそれぞれの人数を教えてください。,平成30年の「親の経営に参加する・継ぐ」は9870人、「農業法人等に就職する」は7060人、「自分で起業して始める」は2360人です。
新規就農者の推移について。新規参入者の就農の理由は最も割合が高い理由は何でしょうか?そして、最も割合が低い理由は何でしょうか?,新規参入者の就農の理由で最も割合高い理由が「自ら采配を振れる」です。最も低い理由が「前職の技術を生かしたい」です。
農山漁村地域の過疎化・定住確保について。農山漁村地域に移住する場合の仕事で最も割合が高いものは何でしょうか?そして、最も割合が低いものは何でしょうか?,農山漁村地域に移住する場合の仕事で最も割合が高かったのは33.3パーセントの「現在と同じ仕事」です。最も低かったのは6.2パーセントの「非農林漁業の自営」です。
農山漁村地域の過疎化・定住確保について。農山漁村地域に移住する場合の仕事で最も割合が高いものは何でしょうか?そして、最も割合が低いものは何でしょうか?,農山漁村地域に移住する場合の仕事で最も割合が高かったのは45.3.3パーセントの「年地域への移動や地域内の移動などの交通手段が不便」です。最も低かったのは1.6パーセントの「その他」です。
食料の安定供給の確保について。食料安全保障強化のための重点対策の「生産資材等の価格高騰等による影響の緩和」について教えてください。,生産資材等の価格高騰等による影響の緩和について解説します。農林水産業の経営への影響の緩和:肥料、配合飼料、燃料の高騰へ対応、日本政策金融公庫による資金繰り支援。適正な価格形成と国民理解の醸成:国民理解醸成に向け情報発信、食品ロス削減・フードバンクへの支援 等
食料の安定供給の確保について。生産面の施策(品目別施策)について教えてください。,生産面の施策(品目別施策)について解説します。小麦・大豆:国内産小麦・大豆の需要拡大に向けた品質向上と安定供給、耐病性・加工適性等に優れた新品種の開発導入の推進、団地化・ブロックローテーションの推進、排水対策の更なる強化やスマート農業の活用による生産性の向上。畜産物:性判別技術や牛舎の空きスペースも活用した増頭推進、中小・家族経営も含めた生産性向上・規模拡大、繁殖雌牛などの増頭推進。野菜:水田を活用した新産地の形成や加工・業務用野菜の生産拡大、機械化一貫体系や環境制御技術の導入等を通じた生産性の向上、摂取量の拡大。果実:省力樹形や機械化作業体系の導入等を通じた労働生産性の向上、海外の規制・ニーズに対応した生産・出荷体制の構築
農林水産業の輸出力強化について。農林水産物・食品の輸出額の推移の2022年の「農作物」、「林産物」、「水産物」、「少額貨物」の金額を教えてください。,「農作物」は8870億円、「林産物」は638億円、「水産物」は3873億円、「少額貨物」は767億円です。
農林水産業の輸出力強化について。輸出支援プラットフォームで、2023年末までに立ち上げる国はどこでしょうか?,輸出支援プラットフォームについて、2023年末までに立ち上げる国は台湾、中国です。中国は国内で4拠点となります。
スマート農業の推進による成長産業化について。全国205地区でスマート農業実証プロジェクトを実施の露地野菜(キャベツ)について質問です。どのような技術を活用して、どのような効果がありましたか?,露地野菜(キャベツ)の収穫にドローンによるセンシングを活用し収穫時の収量予測を行いました。効果は労働時間が2割減少、単価が4割増加しました。
スマート農業の推進による成長産業化について。全国205地区でスマート農業実証プロジェクトを実施の果樹(温州みかん)について質問です。どのような技術を活用しましたか?技術を導入する前と後で効果がどのように変化しましたか?,果樹(温州みかん)にクラウド型かん水コントローラーを導入し、土壌水分データなどを基にかん水を遠隔制御しました。合わせて、ロボット搭載型プレ選果システムを導入し、AIで果皮障害糖を検出し、自動選果を行いました。これらの技術を導入する前は、労働時間が209時間/10aでしたが、労働時間が168時間/10aになりました。収量は2.4t/10aでしたが、収量が2.6t/10aになりました。結果的に労働時間が2割減少しました。
スマート農業人材の育成とデータ活用の促進について。スマートサポートチームは何をするのでしょうか?,実証で培われた技術・ノウハウを有する生産者、民間事業者等からなるスマートサポートチームによる、新技術を積極的に取り入れる産地の支援
みどりの食料システム戦略について。現状と今後の課題についてEUとアメリカはどのような取り組みを行いますか?,EUは「Farm to Fork戦略」(20.5)に取り組み、2030年までに化学農薬の使用及びリスクを50%減、有機農業を25%に拡大する予定です。アメリカは「農業イノベーションアジェンダ」(20.2)に取り組み、2050年までに農業生産量40%増加且つ環境フットプリント半減する予定です。
みどりの食料システム戦略について。目指す姿と都陸方向で2050年までに目指す姿について教えてください。,2050年までに目指す姿について解説します。・農林水産業のCO2ゼロエミッション化の実現、・低リスク農薬への転換、総合的な病害虫管理体系の確立・普及、・化学農薬の使用量(リスク換算)を50%低減、・輸入原料や化石燃料を原料とした化学肥料の使用量を30%低減、・耕地面積に占める有機農業の取組面積の割合を25%(100万ha)に拡大、・2030年までに食品製造業の労働生産性を最低3割向上、・2030年までに食品企業における持続可能性に配慮した輸入原材料調達の実現を目指す、・エリートツリー等を林業用苗木の9割以上に拡大、・ニホンウナギ、クロマグロ等の養殖において人工種苗比率100%を実現
みどりの食料システム戦略②について。戦略の「調達」ついて具体的に教えてください。,みどりの食料システム戦略②の戦略の「調達」ついて具体的に解説します。1:持続可能な資材やエネルギーの調達、2:地域・未利用資源の一層の活用に向けた取組、3:資源のリユース・リサイクルに向けた体制構築・技術開発。期待される取り組みや技術について。・地産地消型エネルギーシステムの構築、・改質リグニンを活用した高機能材料の開発、・食品残渣・汚泥等からの肥料成分の回収・活用、・新たなタンパク資源(昆虫等)の利用拡大 等
【ポイントでRAGを評価】
上記【RAGの評価】のポイントごとにRAGを評価する。
最終的な回答のaccuracyを測定できれば問題ないと思うので、評価のポイントはまずはAnswer accurancyのみでも問題ないと思う。
上記CSVのデータをRAGの評価ポイントでLLMに与え、模範解答に近い回答ができているかを確認する。
※RetrievalとHallucinationのポイントでは、データセットを活用しない。
【精度結果】
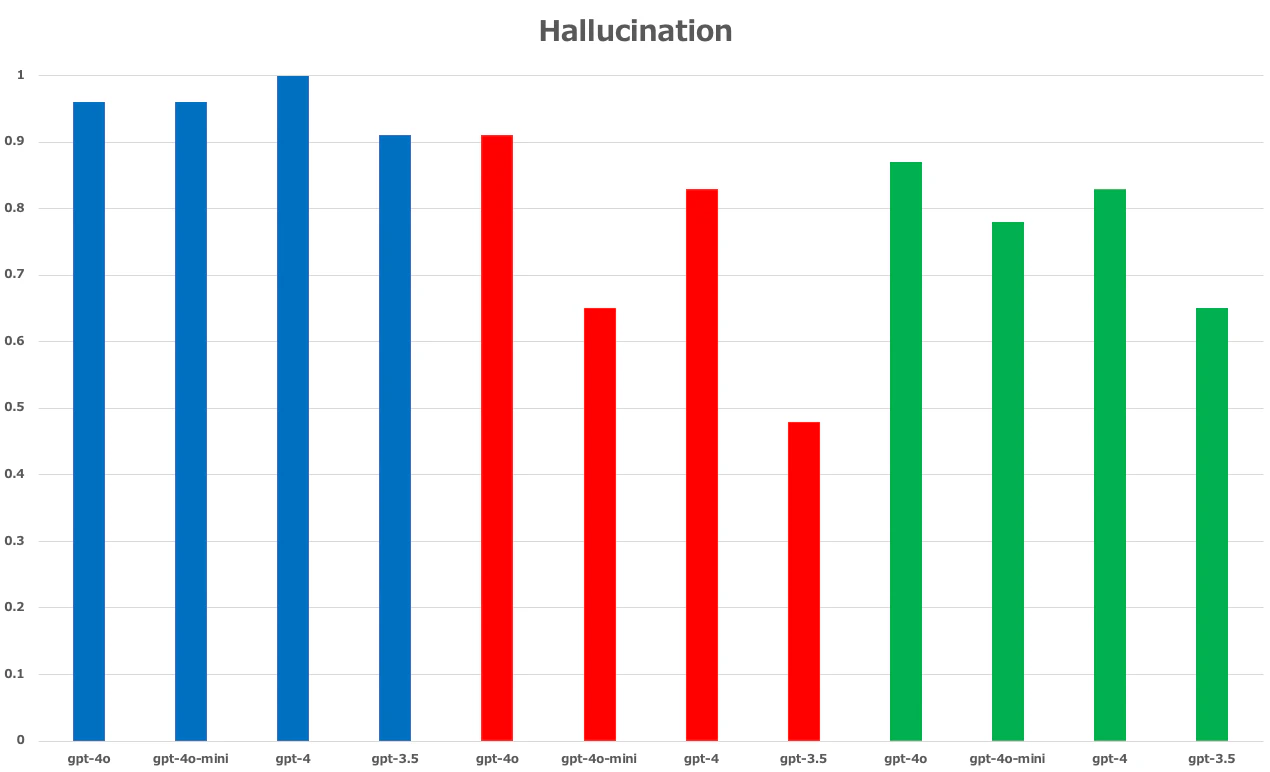
Claudeでデータの前処理を行ったRAGが最も精度が良かった。
23件のデータセットに対して、約8割正解した。
次に精度が良かったRAGがgpt-4oで前処理を行ったRAGである。
gpt-4oでの前処理は約5割正解している。正直商用利用する上では厳しい解答精度である。
前処理を行っていないRAGは当然の如く最下位。
使い物にならないRAGはindex登録前のデータ整形をほぼ何も行っていないと思われる。
RAGを構築する上で、まずはデータの前処理に注力した方が良いと思われる。
RAGの検索にセマンティック検索やハイブリット検索を検討するのはデータの前処理を正く行った後で、検討した方が良い。
本RAGはベーシックなRAGで検証しており、Claudeで前処理を行い回答合成がgpt-3.5のRAGでも前処理を行っていないRAGより格段に回答精度が高い。
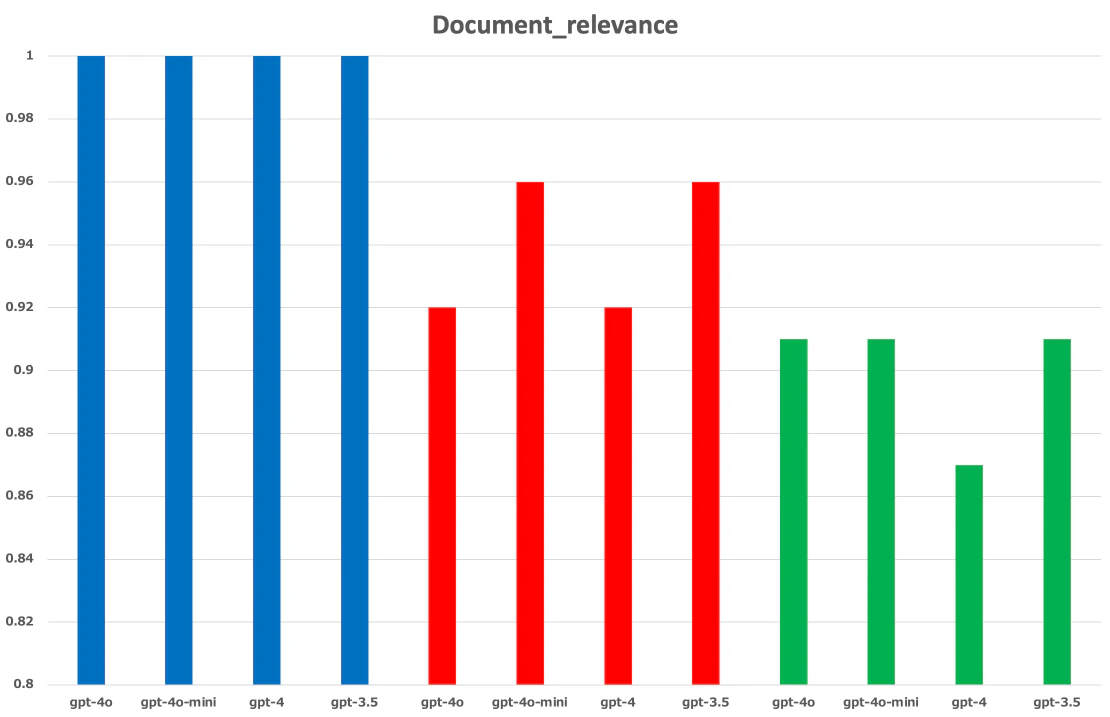
下記の精度結果を見ると、RAGを構築する上でindexにデータを登録する前段階のデータの前処理でRAGの品質が左右されると言っても過言ではない。
青:Claude3.5で前処理あり
赤:前処理なし
緑:gpt-4oで前処理あり
下記のスコアは%
【Answer accurancy】

【Hallucination】
【Document_relevance】
【考察】
前処理することにより、indexに登録するデータがきれいになるため、自ずとRAGのHallucinationやDocument Relevanceの精度も高くなる。
特にClaudeでPDFを前処理すると非常にきれいなデータ整形が行える。
実際に出力されたマークダウンテキストを見たら、Claudeの精度の高さに驚きました👍
Claudeで前処理したRAGで回答を間違えるパターンはPDF内に組み込まれている画像情報が小さいパターンは間違えやすい。
見にくい画像、画像自体が小さいときはClaudeで前処理を行っても正しくデータを整形することができなかった。
gpt-4oは一見きれいに構造的に出力できているが、所々で間違った出力をしていた。
間違った出力を散りばめてくるので、Claudeよりも人手の確認に工数がかかる。
【課題】
Claudeでの前処理は有用ではあるが、間違えずに完璧な出力は現状の技術では不可能なので、Claudeの間違えた出力については人手で赤ペンを入れて修正する必要がある。
複雑な資料であれば、前処理の構造化の精度が低下するため、RAGのindexに登録したい資料の内容をまずは確認した方が良いと思われる。
前処理で間違ったデータを出力した場合、システム的に自動で修正する方法がないため、間違いを効率的に検出して修正する仕組みを構築できれば高品質なRAGを低コストで運用することができると思われる。
最後に生成AIのアプリケーションを導入する際は、クライアントの期待値コントロールが非常に重要。
RAGは企業において有効な生成AIアプリケーションではあるが、生成AIは銀の弾丸ではないため、RAGを構築すれば自社のありとあらゆる情報をLLMが正確に回答することができる訳ではない。
エンドユーザーが求めている解答精度を明確にしてRAGを導入すべきである。