はじめに
皆さん、自粛生活楽しんでますか?
自分は大学に入れないので、家で研究と全く関係ないプログラミングの勉強をして過ごしてます。研究より楽しい...
それと、読書をする時間も増えました。
読書と言っても小説家になろうを読んでいる割合が高いんですけどね。
というわけで、そんな自粛生活を少しでも快適にするべく、
小説家になろうの作品を、縦書きで、数話まとめて読める
そんなWebAPIを作ってみました。
動作
今回作ったWebAPIは、
-------- なろう小説API --------
指定した単語で小説を検索
↓
総合ポイントの最も高い作品を選択、NCODEを取得
↓
-------- なろう小説API --------
↓
指定した範囲の話をスクレイプ
↓
縦書きで小説っぽい形のHTMLに整形
↓
提供
という流れで処理をしています。
スマホからアクセスすると以下のように見えます。横スクロールで読めます。(無職転生 10話より)

PCから

実装
Python
まずはPythonから、
スクレイピングはrequestsとreだけで乗り切り、サーバー部分はFlaskを使います。
# -*- coding: utf-8 -*-
from flask import Flask
from requests import get
import re
app = Flask(__name__)
def narou_html(keyword, num=1, pivot='e'):
honbun_ = ""
item = get(
f"https://api.syosetu.com/novelapi/api/?out=json&of=t-n&lim=1&order=hyoka&word={keyword}"
).json()[1]
url = "https://ncode.syosetu.com/"
ncode = item["ncode"]
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.76 Safari/537.36'
}
t = get(url + ncode, headers=headers).text
slist = []
sl = re.findall('<dl class="novel_sublist2">(.+?)</dl>',
t.replace("\n", ""))
for i in sl[-num:] if pivot == 'e' else sl[:num +
1] if pivot == 's' else sl[
int(pivot) - 1:int(pivot) +
num - 1]:
groups = re.search(
'<a href="/(.+?)/">(.+?)</a></dd><dt class="long_update">(.+?)[(?:<span)|(?:</dt>)]',
i)
slist.append({
"title": groups.group(2),
"href": groups.group(1),
"long_update": groups.group(3)
})
for s in range(len(slist)):
t = get(url + slist[s]["href"], headers=headers).text
honbun = re.search(
'<p class="novel_subtitle">(?:.|\s)+?<div id="novel_honbun"(?:.|\s)+?</p>\n</div>',
t).group(0)
bcnt = 0
shonbun = honbun.splitlines()
for j, i in enumerate(shonbun):
if i[:2] == "<p":
groups = re.search("<p.*?>(.+?)</p>", i)
i = groups.group(1)
if j == 0:
i = '<h3>' + i + '</h3>\n'
elif groups.group(1) == "<br />":
continue
elif i[0] == "=":
if len(set(i)) == 1:
if bcnt % 2 == 0:
i = '<br><div id="wrapper">'
else:
i = '</div><br>'
bcnt += 1
elif i[0] == '「' and honbun_[-14] != '」':
i = '<br><br>' + i
if i[-1] == '」':
i += '<br><br>'
honbun_ += i + '<br>\n'
honbun_ += "<br>" * 25 + "\n"
trdict = str.maketrans({
'→': '↓',
'-': '|',
"-": "|",
'1': '一',
'1': '一',
'2': '二',
'2': '二',
'3': '三',
'3': '三',
'4': '四',
'4': '四',
'5': '五',
'5': '五',
'6': '六',
'6': '六',
'7': '七',
'7': '七',
'8': '八',
'8': '八',
'9': '九',
'9': '九',
'0': '〇',
'0': '〇',
})
honbun_ = '''<html>
<head>
<meta name="viewport" content="initial-scale=1.3,minimum-scale=1.3">
<style>
body {
margin-top: 3.5%;
margin-bottom: 3%;
white-space: break-all;
-ms-writing-mode: tb-rl;
writing-mode: vertical-rl;
text-orientation: upright;
font-family: "Noto Serif JP", serif;
font-size: 85%;
}
#wrapper {
font-family: sans-serif;
border:solid 1px;
}
</style>
<title>''' + item["title"] + '''</title>
<link href="https://fonts.googleapis.com/css?family=Noto+Serif+JP&display=swap&subset=japanese" rel="stylesheet">
</head>
<body>
''' + honbun_[:-93].translate(trdict) + '''</body>
</html>'''
return honbun_
@app.route("/")
def hello_world():
return "Usage: http://ip-address:port(default:5000)/search_word/start_pont/number_of_stories"
@app.route('/<keyword>/<pivot>/<num>')
def html_(keyword, pivot, num):
html = narou_html(keyword, int(num), pivot)
return html
if __name__ == "__main__":
app.run(host="0.0.0.0")
※8/31 スクショ後少し書き換えたので、同じ見た目にはなりません。
実行後、
http://localhost:5000/検索ワード/後述/後述(実行端末からのみ) もしくは http://実行端末のローカルIPアドレス:5000/検索ワード/後述/後述
で読むことが出来ます。
後述の部分は、
前の方は、sで1話から、eで最新話から、数字で指定した部分から、
後ろは、何話返すか、
を指定できます。
GAS(Google Apps Script)
LINEボット化するべくHerokuに上げてみたのですが、なにやらHerokuのサーバーからだと小説家になろうはスクレイピングできない様子でしたので、GASで書き直しました。
Javascript自体あまり書かないのですが、その上GAS独自の関数など、コードは短いながらも試行錯誤がしんどかったです。特に普段Jupyterの即実行!即応答!に慣れてしまっているのでログがまともに表示できないのが致命的でした。
LINEボットとして使用するために、2つプロジェクトを使って、
1つはLINEの応答用、
2つ目は上記のPythonコードと同様のWebAPI用
としました。
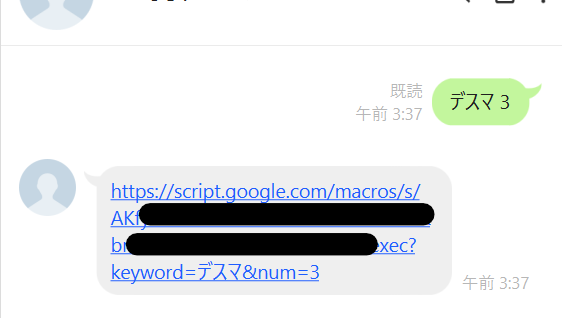
メッセージを送ると、1つ目のプロジェクトがURLを返信し、そのURLにアクセスすると2つ目のプロジェクトが小説を整形したページを提供する。
という流れです。
これが無料で出来るGASすごい。けど遅い。
1つ目はURLを返すだけなのでGASでのLINEボットの作り方を解説しているサイトを見てもらうことにして、2つ目のコードだけ載せます。
また、こちらでは最新話から指定した話数返すところまでしか実装していない等、Python版より簡略化しています(というよりPython側をこれを書いたより後に改良しました)。
function doGet(e) {
var keyword = e.parameter.keyword; //検索ワード
var num = parseInt(e.parameter.num); //話数
var getUrl = "https://api.syosetu.com/novelapi/api/?out=json&of=t-n&lim=1&order=hyoka&word="+keyword;
var response = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
var json = JSON.parse(response)[1];
var title = json["title"]
var ncode = json["ncode"]
getUrl = "https://ncode.syosetu.com/"+ncode;
response = UrlFetchApp.fetch(getUrl).getContentText('UTF-8').replace(/[\r\n]+/g,"");
var items = response.match(/<dl class="novel_sublist2">(.+?)<\/dl>/gm);
items = items.slice(items.length-num,items.length);
var slist = [];
for (var i = 0;i<num;i++){
slist.push(items[i].match(/(<a href="\/)(.+?)(\/">)/)[2]); //指定した話のhrefを収集
}
var honbun = ""
//以下整形time
for (var s = 0;s<num;s++){
getUrl = "https://ncode.syosetu.com/"+slist[s];
response = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
var honbun_ = response.match(/<p class="novel_subtitle">(?:.|\s)+?<div id="novel_honbun"(?:.|\s)+?<\/p>\n<\/div>/)[0];
var sphon=honbun_.split(/[\r\n]+/g);
for (var i = 0, len=sphon.length;i<len;i++){
if (sphon[i].slice(0,2) == "<p"){
var groups = sphon[i].match(/(<p.*?>)(.+?)(<\/p>)/);
var temp = groups[1] + groups[2].replace(/(\d{2,4})/g, '<span class="text-combine">$1<\/span>') + groups[3];
if(i == 0){
temp = '<h3>' + temp + '</h3>';
Logger.log(temp);
}
honbun += temp + "\n"
}
else{honbun += sphon[i] + "\n";}
}
honbun += "</br></br>";
}
honbun = '<html>\n<head>\n <title>' + title + '</title>\n</head>\n<font size="5"><style>\n body {\n -ms-writing-mode: tb-rl;\n writing-mode: vertical-rl;\n text-orientation: upright;\n font-family: "游明朝", YuMincho, "Hiragino Mincho ProN W3", "ヒラギノ明朝 ProN W3", "Hiragino Mincho ProN", "HG明朝E", "MS P明朝", "MS 明朝", serif;\n }\n\n .text-combine {\n -webkit-text-combine: horizontal;\n -ms-text-combine-horizontal: all;\n text-combine-upright: all;\n }\n</style>\n\n<body>\n' + honbun + ' \n</body>\n</font>\n</html>'
var html = HtmlService.createHtmlOutput(honbun); //よくわからない。文字列の状態のHTMLをHTMLとして表示するための準備的なやつ?
return html;
}
公開 → ウェブアプリケーションとして導入
して、生成されたアドレス + ?keyword=検索ワード&num=話数
にアクセスすることで縦書きに整形されたページが表示されます。(LINEボットでは1つ目プロジェクトでこのアドレスを返信させてます。)
まとめ
読書が捗るぅ…
HTMLは素人なので気に入らなかったら改造しておくれ…
……使用する際は、小説家になろうのサーバーに大きな負担がかからないように節度を持った使い方をお願いします。