背景
今年度、メトリクスに関して学んだのもあって、いろいろデータ分析を試してみたい衝動に駆られている。そんなこと思いながらネットサーフィンしていると、競艇のデータは公式がまとめてくれてるので、簡単そうな気がした。
ここで、できること
以下のような、テーブルが出来上がる。
| nIndex | 場所 | 日付 | 題名 | 第 | 何日目 | 空白列 | 年月日 |
|---|---|---|---|---|---|---|---|
| 1 | 芦屋 | 3/16 | DММボートちゃんね | 第 | 6日 | 24-03-16 | |
| 2 | 下関 | 3/16 | ヴィーナスシリーズ第 | 第 | 5日 | 24-03-16 | |
| 3 | 丸亀 | 3/16 | 大阪スポーツカップ | 第 | 4日 | 24-03-16 | |
| 4 | 尼崎 | 3/16 | 第22回報知ローズカ | 第 | 4日 | 24-03-16 | |
| 5 | 住之江 | 3/16 | ボートピア梅田開設1 | 第 | 2日 | 24-03-16 |
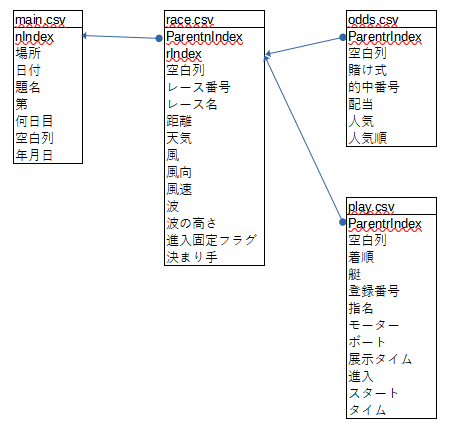
テーブル構造は、こんな感じ。
コード
勢いで書いてみた。こんな書き方いかんやろーって思いつつ、勢いなので。。
公式から落とせる競艇データは、lzh形式で圧縮されているので、下記リンクと同じやり方で解凍している。
https://qiita.com/Carl_Jonson/items/27d5ed344bd8e9ed4c2b
# 必要なライブラリをインポート
import urllib.request
import shutil
from datetime import datetime, date, timedelta
import subprocess
import re
import os
import csv
# 途中で変わっちゃったりしないように、今日の日付を配列に入れる
dt_today = datetime.today()
# テーブル化する情報を格納する配列を用意する、一緒にヘッダだけ入れる
maindat = [["nIndex", "場所", "日付", "題名", "第", "何日目", "空白列", "年月日"]]
racedat = [["ParentnIndex", "rIndex", "空白列", "レース番号", "レース名", "距離", "天気", "風", "風向", "風速", "波", "波の高さ", "進入固定フラグ", "決まり手"]]
playdat = [["ParentrIndex", "空白列", "着順", "艇", "登録番号", "指名", "モーター", "ボート", "展示タイム", "進入", "スタート", "タイム"]]
oddsdat = [["ParentrIndex", "空白列", "賭け式", "的中番号", "配当", "人気", "人気順"]]
# どれだけの期間データを取るか指定する
syutokukikan = 90
# 出力先のファイルを定義する
export_maindat = "main.csv"
export_racedat = "race.csv"
export_playdat = "play.csv"
export_oddsdat = "odds.csv"
# maindatテーブルのIndexを作成
m_index = 0
r_index = 0
# 必要な日数分、ループ
for count in range(1, syutokukikan):
# count 日前の日付を引き算して生成
calcdate = dt_today - timedelta(days = count)
# 生成した日付を使い、urlを生成
tgturl = 'https://www1.mbrace.or.jp/od2/K/' + calcdate.strftime('%Y%m') + '/k' + calcdate.strftime('%y%m%d') + '.lzh'
# ついでにファイル名も生成
gfilename = 'k' + calcdate.strftime('%y%m%d') + '.lzh'
tfilename = 'k' + calcdate.strftime('%y%m%d') + '.txt'
# urllib.requestを使ってダウンロードする
urllib.request.urlretrieve(tgturl, gfilename)
# 7zipを使って、解凍をする
subprocess.run("7z.exe e " + gfilename)
# テキストファイルを読み込む
f = open(tfilename, 'r')
textdata = f.readlines()
# 行数分ループする、カウンタも取得する
for ncnt, singledata in enumerate(textdata):
if '[成績]' in singledata:
# [成績]という文字が含まれる場合、場所とかを示していると判断する
# スラッシュと半角スペースが重なっている場合、その直後の半角スペースを消す
buf = singledata.replace('/ ', '/')
# [成績]の文字はいらんので消す
buf = buf.replace('[成績]', '')
# 全角スペースを消す
buf = buf.replace(' ', '')
# 連続する半角スペースを一つにする
buf = re.sub(r'\s+', ' ', buf)
# indexを足す
m_index = m_index + 1
buf = str(m_index) + " " + buf
# 日付を足す
buf = buf + " " + calcdate.strftime('%y-%m-%d')
# スプリットして配列にして、格納する
maindat.append(buf.split(" "))
elif len(singledata) > 10 and len(singledata.replace('-', '')) == 1 :
# -------------------------- って行を区切りとして識別する
# 全角スペースを消す
buf = textdata[ncnt - 2].replace(' ', '')
# 侵入固定の文字が含まれる場合、文字消して末尾に追加する
if '進入固定' in buf:
buf = buf.replace('進入固定', '') + " " + '進入固定'
# 風速10m以上だと区切れなくなるので、無理やりスペース足す
pprr = re.match(r'.*[1-9][0-9]m', buf)
if pprr:
buf = buf[:pprr.span()[1] - 3] + " " + buf[pprr.span()[1] - 3:]
# 2つ上の配列にあるレース情報の連続する半角スペースを一つにする
buf = re.sub(r'\s+', ' ', buf)
# indexを足す
r_index = r_index + 1
buf = str(m_index) + " " + str(r_index) + " " + buf
# 決まり手が記載されている行のデータをとって、buffer文字に足す
buf2 = re.sub(r'\s+', ' ', textdata[ncnt - 1])
buf = buf + " " + buf2.split(" ")[13]
# スプリットして配列にして、格納する
racedat.append(buf.split(" "))
# 選手データを、ループして抜き出す
for pcnt in range(1, 7):
# 全角スペースを消す
buf = textdata[ncnt + pcnt].replace(' ', '')
# K . のデータが含まれている場合、それ以降の文字列を消す
if 'K .' in buf:
buf = buf[:buf.find('K .')]
# . .のデータが含まれている場合、その文字列を消す
if '. .' in buf:
buf = buf.replace('. .', '')
# 連続する半角スペースを一つにする
buf = re.sub(r'\s+', ' ', buf)
# indexを足す
buf = str(r_index) + " " + buf
# スプリットして配列にして、格納する
playdat.append(buf.split(" "))
# 8行目からループしてオッズのデータを取得
ocnt = 7
# 3連続で「連」か「勝」の文字が出てこない場合には処理を止める、判定をするための変数を初期化
outcnt = 0
# 賭け式を保持しておくバッファを初期化する
kake_buf = ""
# 末尾までループ(念のため、止まるように)
while ocnt < len(textdata):
# カウンタ加算
ocnt = ocnt + 1
# 後々のことも考えてバッファに入れる
buf = textdata[ncnt + ocnt]
# 何も文字が無い行は、カウンタ追加してスキップする
if len(buf) <= 1:
# 未検出カウンタを追加
outcnt = outcnt + 1
if outcnt >= 3:
break
else:
continue
# レース不成立の場合は、処理終了
if 'レース不成立' in buf:
break
# 賭け式が不成立の場合は、データ出力しない
if '不成立' in buf:
continue
# 賭け式が記載されていない場合は、ひとつ前の賭け式と同じと判断する(連と勝がない場合は、未記載と判断する)
if not '連' in buf and not '勝' in buf:
buf = " " + kake_buf + " " + buf
# 未検出カウンタを追加
outcnt = outcnt + 1
if outcnt >= 3:
break
else:
# カウンタを初期化
outcnt = 0
# 賭け式の文字列を設定
buf2 = re.sub(r'\s+', ' ', buf)
kake_buf = buf2.split(" ")[1]
# 「R」の文字が検出された場合、ループを終わる
if 'R' in buf:
break
# 連続する半角スペースを一つにする
buf = re.sub(r'\s+', ' ', buf)
# indexを足す
buf = str(r_index) + " " + buf
# 複勝の時だけ処理する
if '複勝' in buf:
# 扱いやすいように、いったん配列に入れる
bufarray = buf.split(" ")
# 1着の複勝データの書き込み
p1array = [bufarray[0], bufarray[1], bufarray[2], bufarray[3], bufarray[4]]
oddsdat.append(p1array)
# 配列の要素数が少ない場合には処理しない
if len(bufarray) >= 7:
p2array = [bufarray[0], bufarray[1], bufarray[2], bufarray[5], bufarray[6]]
oddsdat.append(p2array)
else:
# スプリットして配列にして、格納する
oddsdat.append(buf.split(" "))
# テキストを閉じる
f.close()
# ゴミを掃除する
os.remove(gfilename)
os.remove(tfilename)
# CSVで出力する main
if os.path.isfile(export_maindat):
os.remove(export_maindat)
with open(export_maindat, 'w', newline="") as f:
writer = csv.writer(f)
writer.writerows(maindat)
# CSVで出力する race
if os.path.isfile(export_racedat):
os.remove(export_racedat)
with open(export_racedat, 'w', newline="") as f:
writer = csv.writer(f)
writer.writerows(racedat)
# CSVで出力する play
if os.path.isfile(export_playdat):
os.remove(export_playdat)
with open(export_playdat, 'w', newline="") as f:
writer = csv.writer(f)
writer.writerows(playdat)
# CSVで出力する odds
if os.path.isfile(export_oddsdat):
os.remove(export_oddsdat)
with open(export_oddsdat, 'w', newline="") as f:
writer = csv.writer(f)
writer.writerows(oddsdat)