導入
2024年3月14日、彼女自身の運営するサイトにてにて投稿された記事 「What I learned from looking at 900 most popular open source AI tools」 は、スタンフォード大学のコンピュータサイエンス専攻で修士号を取得し、NVIDIA、Snorkel AI、Netflixで機械学習ツールを構築した経験のあるコンピュータサイエンティストのChip Huyenによって書かれた。
この記事で,オープンソースAIの現状を845のGitHubリポジトリから分析して、AIスタック、開発者、中国の動向などを考察し、インフラよりアプリ開発が活発だが、過度な期待などに翻弄されるプロジェクトも多いと指摘する。
以下運営ホームページ
以下翻訳記事ページ
900の最も人気のあるオープンソースAIツールを見て学んだこと
4年前、私はオープンソースMLエコシステムの分析を行った。それ以来、ランドスケープは大きく変化したので、再びこのトピックに着目することにしたのだ。今回は、ファンデーションモデルを中心としたスタックに絞って調査を行った。
オープンソースAIリポジトリの完全なリストは、llama-policeでホストされている。このリストは6時間ごとに更新される。また、私のGitHubにあるcool-llm-reposリストでも、ほとんどのリポジトリを見つけることができる。
私は、これらのリポジトリを詳細に分析し、いくつかの興味深い傾向を発見した。まず、ファンデーションモデルの訓練に特化したツールが急増していることに気づいた。これらのツールは、大規模なデータセットを効率的に処理し、強力なモデルを構築することを可能にしているのである。
また、ファンデーションモデルの展開と利用を容易にするためのフレームワークも登場している。これらのフレームワークは、モデルの微調整やAPIの構築を簡素化し、開発者がより迅速にアプリケーションを構築できるようにしている。
さらに、ファンデーションモデルの解釈可能性と公平性に関するツールも増加傾向にある。これらのツールは、モデルの意思決定プロセスを分析し、バイアスを特定することで、より透明性の高いAIシステムの構築を支援している。
オープンソースコミュニティは、ファンデーションモデルの発展において重要な役割を果たしている。世界中の研究者や開発者が協力し合うことで、革新的なアイデアが生まれ、AIの可能性が広がっている。
ファンデーションモデルを中心としたオープンソースAIエコシステムは、今後も大きな進化を遂げていくことだろう。私は、このエキサイティングな分野の発展を見守り続けていきたいと思う。
目次データ
データ
- リポジトリを追加する方法
新しいAIスタック
- AIスタックの時間的変遷
- アプリケーション
- AIエンジニアリング
- モデル開発
- インフラストラクチャ
オープンソースAI開発者
- 一人で10億ドル企業?
- 100万のコミット
成長する中国のオープンソースエコシステム
速く生きて、若く死ぬ
私のお気に入りのアイデア
結論
データ
GitHubで「gpt」、「llm」、「generative ai」のキーワードを検索した。AIがこれほどまでに圧倒的に感じられるのは、それが事実だからだ。「gpt」だけでも118,000件の結果が返ってきた。
作業を簡単にするために、私は500スター以上のリポジトリに検索を限定した。「llm」で590件、「gpt」で531件、「generative ai」で38件の結果が得られたの。また、新しいリポジトリを見つけるために、GitHubのトレンドやソーシャルメディアも時折チェックした。
長い時間をかけて、896のリポジトリを発見した。そのうち、51件はチュートリアル(例: dair-ai/Prompt-Engineering-Guide)や集約されたリスト(例: f/awesome-chatgpt-prompts)であった。これらのチュートリアルやリストは役立つものの、私はソフトウェアにより興味がある。最終的なリストには含めたが、分析は845のソフトウェアリポジトリを対象に行った。
痛みを伴う作業ではあったが、報われる過程でもあった。人々が何に取り組んでいるのか、オープンソースコミュニティがいかに協力的であるか、そして中国のオープンソースエコシステムが西洋のそれとどれほど異なるかについて、はるかに深い理解を得ることができた。
リポジトリを追加する方法
間違いなく多くのリポジトリを見落としているはずだ。不足しているリポジトリはここから提出できる。リストは毎日自動的に更新されるのである。
500スター未満のリポジトリも自由に提出してほしい。私は引き続き追跡し、500スターに達した時点でリストに追加するのだ!
新しいAIスタック
AIスタックは、インフラストラクチャ、モデル開発、アプリケーション開発、アプリケーションの4つの層から成ると考えている。

- インフラストラクチャ スタックの最下層にあるのがインフラストラクチャで、サービング(vllm、NVIDIAのTriton)、コンピュート管理(skypilot)、ベクター検索とデータベース(faiss、milvus、qdrant、lancedb)などのツールが含まれる。
- モデル開発 この層では、モデリングと訓練のためのフレームワーク(transformers、pytorch、DeepSpeed)、推論の最適化(ggml、openai/triton)、データセットエンジニアリング、評価などを含む、モデル開発のためのツールを提供しているのだ。ファインチューニングを含め、モデルの重みを変更することに関わるものは全てこの層で行われる。
- アプリケーション開発 容易に利用可能なモデルがあれば、誰でもその上にアプリケーションを開発することができる。この層は過去2年間で最も活発な動きを見せており、今もなお急速に進化し続けている。この層はAIエンジニアリングとも呼ばれている。 アプリケーション開発には、プロンプトエンジニアリング、RAG、AIインターフェースなどが含まれる。
- アプリケーション 既存のモデルの上に構築された、多くのオープンソースアプリケーションが存在する。最も人気のあるアプリケーションのタイプは、コーディング、ワークフローの自動化、情報の集約などなのである。
これらの4つの層の外側には、モデルリポジトリというもう1つのカテゴリーがある。これは、企業や研究者が自らのモデルに関連するコードを共有するために作成したものなのである。このカテゴリーのリポジトリの例としては、CompVis/stable-diffusion、openai/whisper、facebookresearch/llamaなどがある。
AIスタックの時間的変遷
私は、各カテゴリーのリポジトリの累積数を月ごとにプロットしてみたのだ。Stable DiffusionとChatGPTの登場後、2023年には新しいツールが爆発的に増加した。2023年9月にはカーブが平坦化しているように見えるが、これには3つの潜在的な理由がある。
- 今回の分析では、少なくとも500のスターを持つリポジトリのみを対象としているが、これほど多くのスターを集めるにはある程度の時間を要する。
- 手の届きやすい果実のほとんどは既に収穫されている。残っているものを構築するにはより多くの努力が必要であり、それができる人は少ないのである。
- 人々は、生成AIの分野で競争力を持つことが難しいことに気づき、興奮が冷め始めているのだ。2023年初頭には、企業とのAIに関する会話は全て生成AIを中心に行われていたが、最近の会話はより現実的になってきているのである。scikit-learnに言及する企業もあったほどだ。数ヶ月後に再度検証し、これが本当なのかどうかを確認したいと思う。
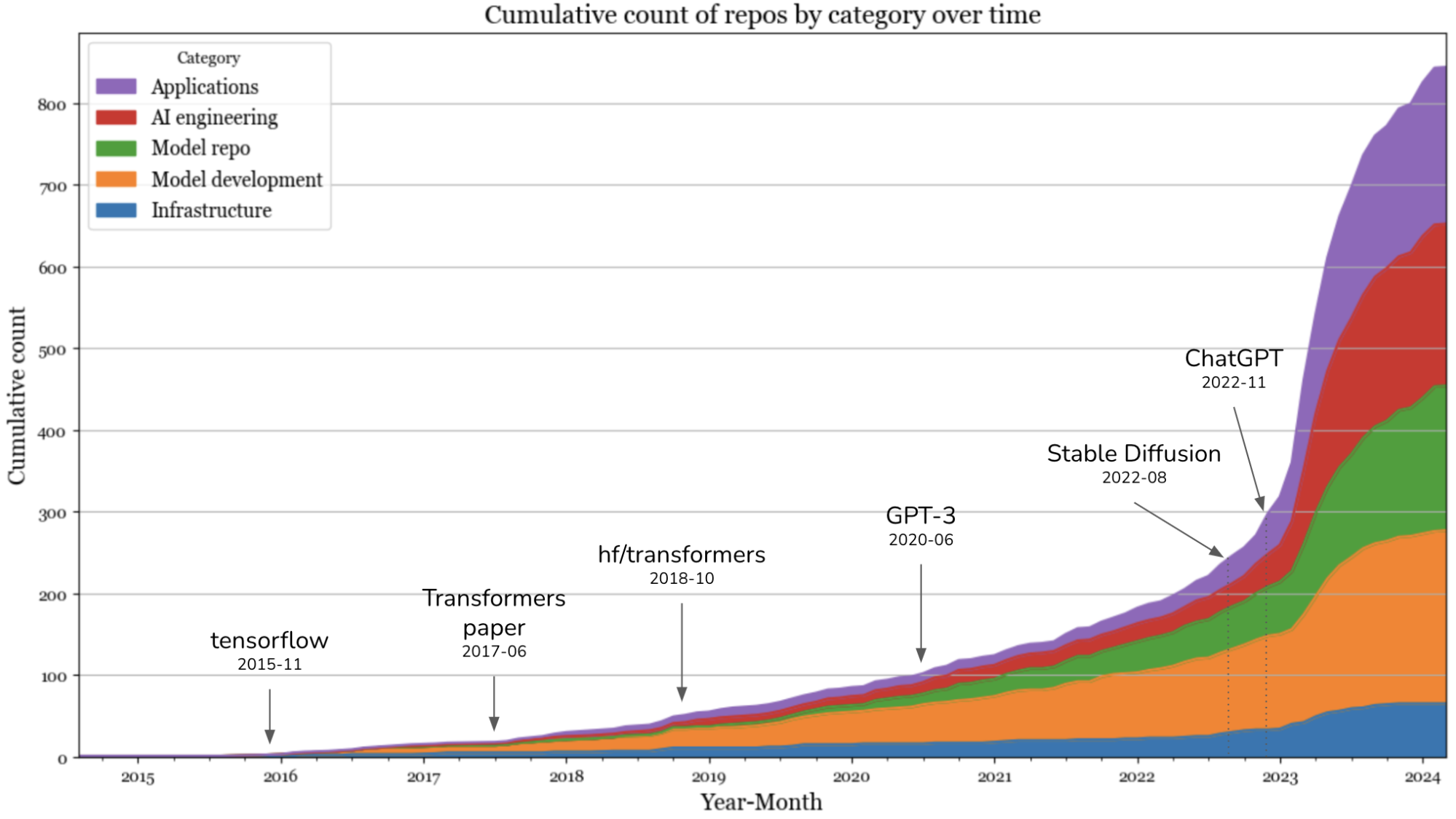
2023年には、アプリケーションとアプリケーション開発の層で最も大きな増加が見られた。インフラストラクチャ層でも多少の成長は見られたが、他の層で見られたようなレベルの成長からは程遠かったのだ。
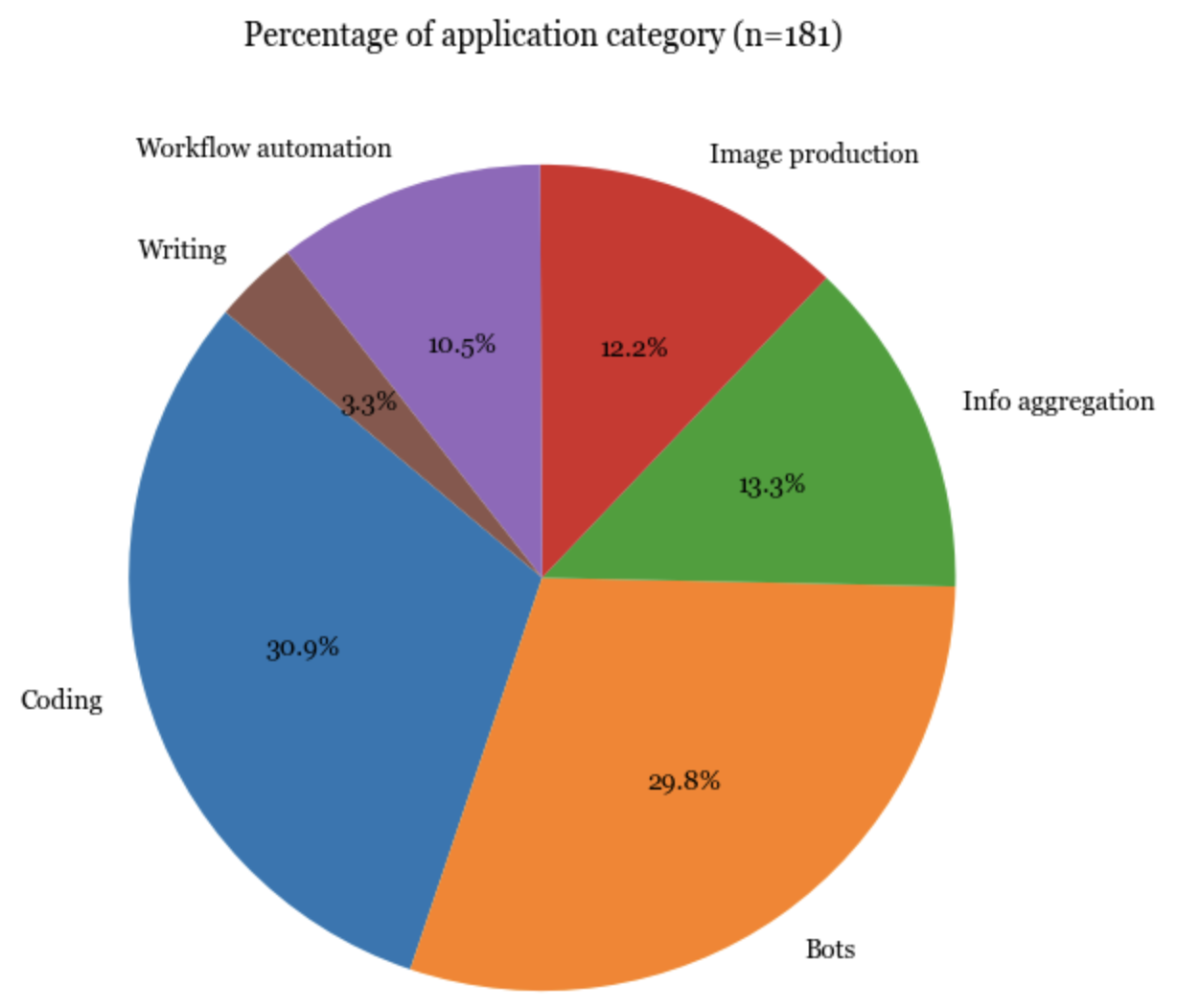
アプリケーション
最も人気のあるアプリケーションのタイプは、コーディング、ボット(例えば、ロールプレイング、WhatsAppボット、Slackボット)、情報の集約(例えば、「これをSlackに接続して、毎日のメッセージを要約するように頼もう」)であることは驚くに値しないのである。
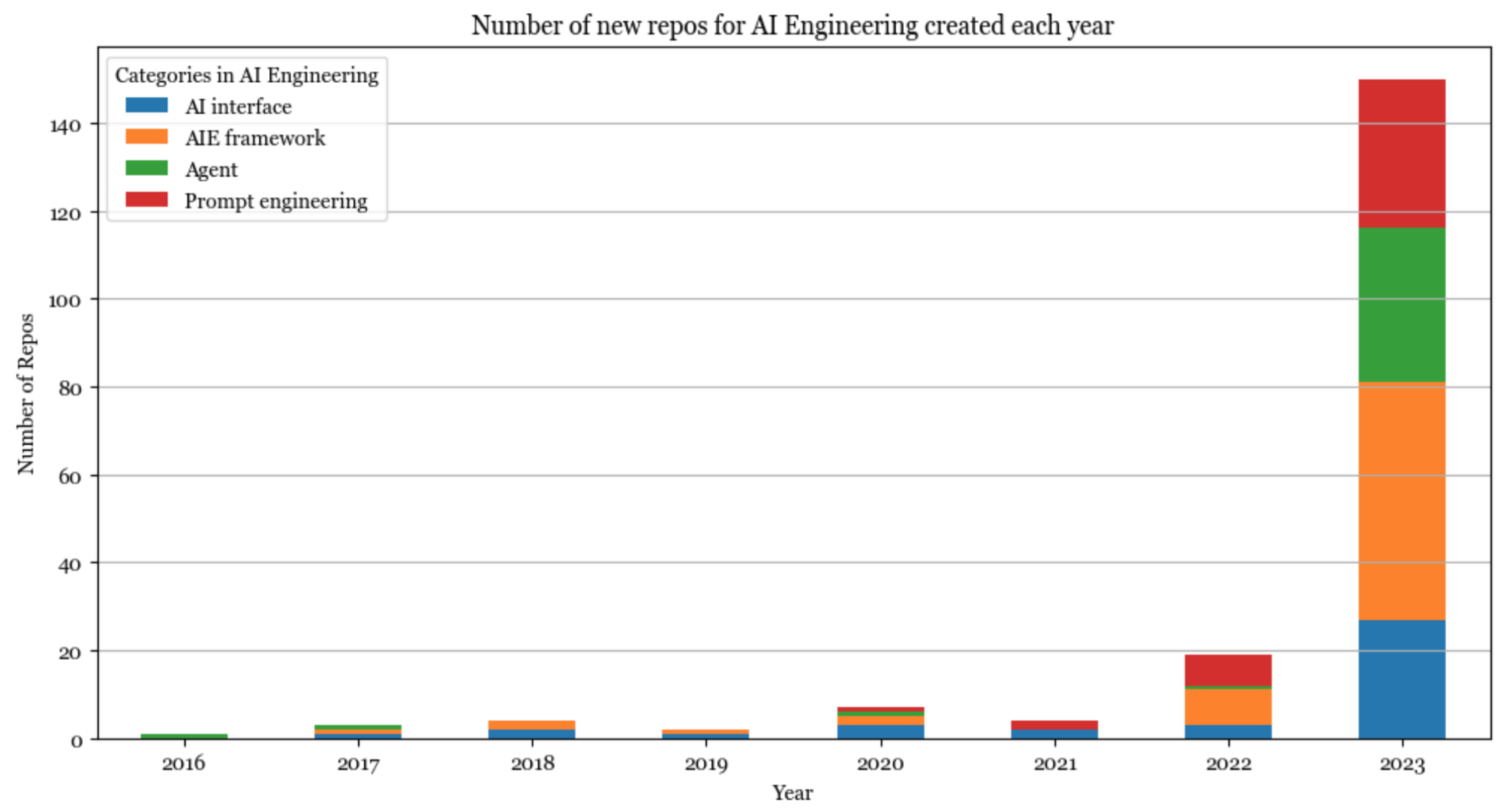
AIエンジニアリング
2023年はAIエンジニアリングの年であった。多くのツールが類似しているため、それらを分類するのは難しい。現在、私はそれらをプロンプトエンジニアリング、AIインターフェース、エージェント、AIエンジニアリング(AIE)フレームワークという4つのカテゴリーに分類している。
プロンプトエンジニアリングは、プロンプトを調整するだけでなく、制約付きサンプリング(構造化された出力)、長期記憶管理、プロンプトのテストと評価などを含む、はるかに広範囲なものなのだ。

AIインターフェースは、エンドユーザーがAIアプリケーションとやり取りするためのインターフェースを提供する。このカテゴリーに私は最も興奮しているのである。人気を集めているインターフェースには以下のようなものがある。
Webおよびデスクトップアプリ
ブラウジング中にユーザーがすばやくAIモデルを照会できるようにするブラウザ拡張機能。
Slack、Discord、WeChat、WhatsAppなどのチャットアプリを介したボット。
開発者がVSCode、Shopify、Microsoft Officeなどのアプリケーションに、AIアプリケーションを組み込むことができるプラグイン。プラグインアプローチは、ツールを使用して複雑なタスクを完了できるAIアプリケーション(エージェント)に一般的である。
AIEフレームワークは、AIアプリケーションの開発を支援するすべてのプラットフォームを包括する用語なのだ。それらの多くはRAGを中心に構築されているが、モニタリングや評価などの他のツールも提供しているのである。
エージェントは奇妙なカテゴリーで、多くのエージェントツールは、制約付き生成(モデルが事前に決められたアクションのみを出力できるなど)やプラグイン統合(エージェントがツールを使用できるようにするなど)を伴う洗練されたプロンプトエンジニアリングに過ぎないのだ。
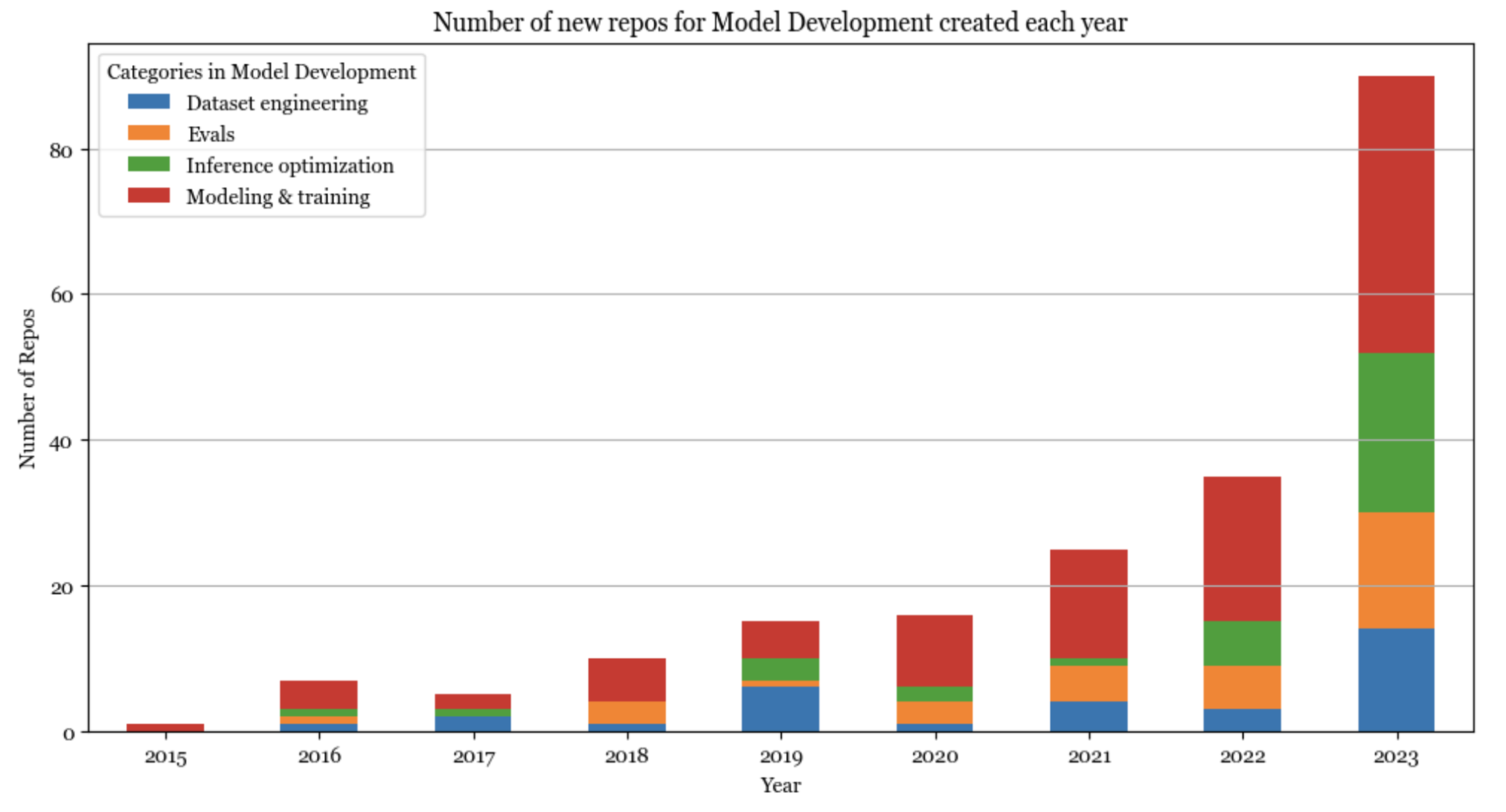
モデル開発
ChatGPT以前は、AIスタックはモデル開発が主流であった。2023年のモデル開発における最大の成長は、推論の最適化、評価、パラメータ効率の良いファインチューニング(モデリングと訓練の下にグループ化されている)への関心の高まりから来ているのだ。
推論の最適化は常に重要であったが、今日のファンデーションモデルの規模では、レイテンシとコストにとって不可欠なのである。最適化のための中核的アプローチは同じままだが(量子化、低ランク因子分解、プルーニング、蒸留)、特にトランスフォーマーアーキテクチャと新世代のハードウェアのために、多くの新しい手法が開発されているのだ。例えば、2020年には16ビット量子化が最先端と考えられていたが、今日では2ビット量子化、さらにはそれ以下の量子化も見られるのである。
同様に、評価は常に不可欠であったが、今日では多くの人がモデルをブラックボックスとして扱っているため、評価はさらに重要になっているのだ。比較評価(Chatbot Arenaを参照)やAI-as-a-judgeなど、多くの新しい評価ベンチマークと評価方法が存在するのである。
インフラストラクチャ
インフラストラクチャは、データ、コンピュート、およびサービング、モニタリング、その他のプラットフォーム作業のためのツールの管理に関するものである。生成AIがもたらしたすべての変化にもかかわらず、オープンソースのAIインフラストラクチャ層はほとんど変わっていない。これは、インフラストラクチャ製品が通常オープンソース化されていないためでもある。
このレイヤーの最も新しいカテゴリーは、Qdrant、Pinecone、LanceDBなどの企業によるベクターデータベースなのである。しかし、多くの人は、これは全くカテゴリーではないと主張しているのだ。ベクター検索は長い間存在していたのである。新しいデータベースをベクター検索のためだけに構築するのではなく、DataStaxやRedisなどの既存のデータベース企業が、データがすでに存在する場所にベクター検索を導入しているのだ。
オープンソースAI開発者
オープンソースソフトウェアは、多くのものと同様に、ロングテール分布に従うのだ。一握りのアカウントが大部分のリポジトリを管理しているのである。
一人10億ドル企業の可能性?
845のリポジトリが594のユニークなGitHubアカウントでホストされている。少なくとも4つのリポジトリを持つアカウントが20ある。これらの上位20アカウントは、リポジトリの195、つまりリスト上の全リポジトリの23%をホストしている。これらの195のリポジトリは、合計で165万のスターを獲得している。
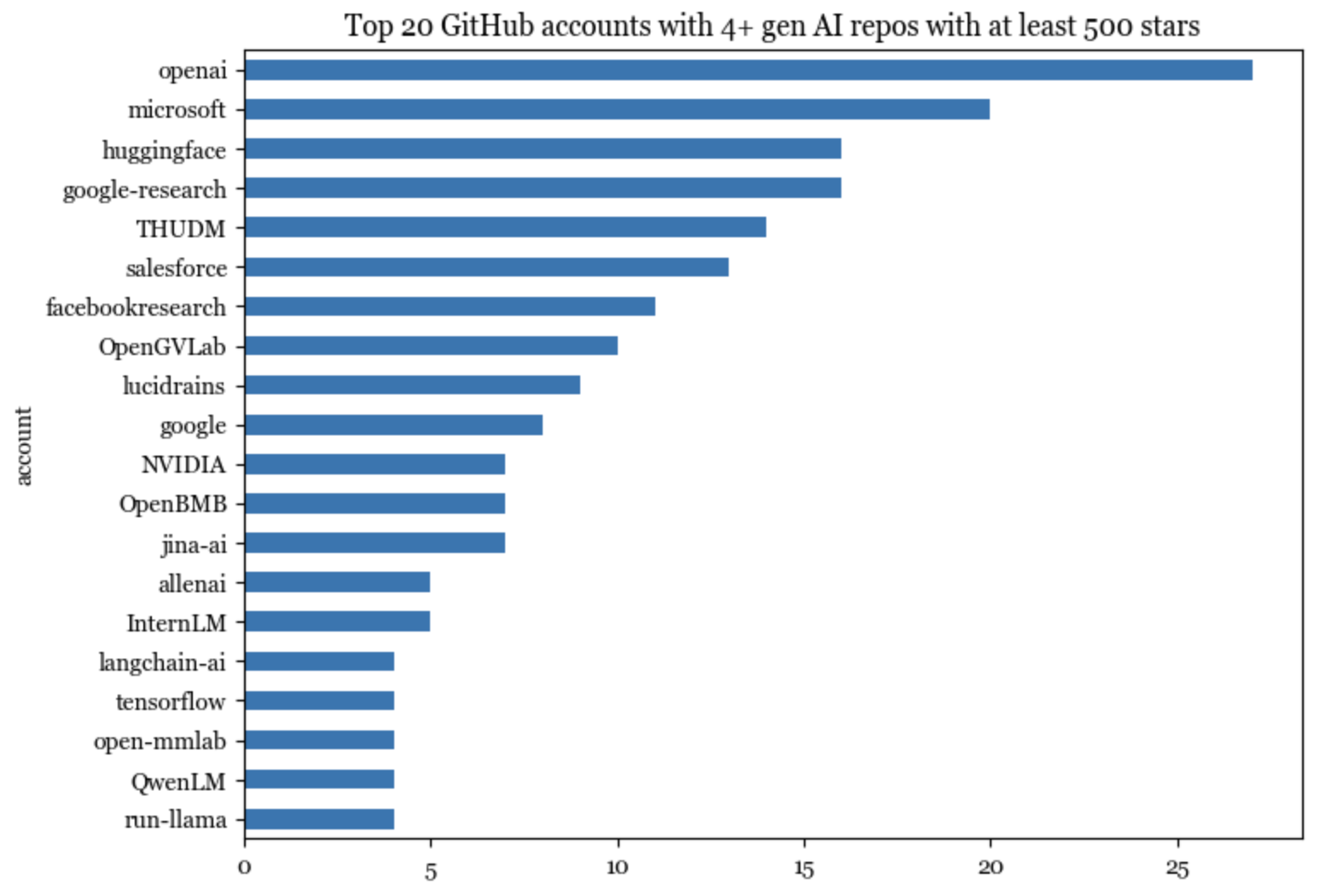
Githubでは、アカウントは組織または個人のどちらかになる。上位20アカウントのうち19は組織なのである。そのうちの3つは、Googleのもの(google-research、google、tensorflow)なのだ。
これらの上位20アカウントの中で唯一の個人アカウントはlucidrains なのである。最も多くのスターを獲得している上位20アカウント(生成AIリポジトリのみをカウント)の中で、個人アカウントは4つある。
lucidrains(Phil Wang):最先端のモデルを驚くほど高速に実装できる人物。
ggerganov(Georgi Gerganov):物理学の背景を持つ最適化の神。
Illyasviel(Lyumin Zhang):FoocusとControlNetの作成者で、現在スタンフォード大学の博士課程に在籍。
xtekky:gpt4freeを作成したフルスタック開発者。

当然のことながら、スタックの下位になればなるほど、個人が構築することは難しくなる。インフラストラクチャ層のソフトウェアは、個人のアカウントによって開始およびホストされる可能性が最も低く、一方でアプリケーションの半分以上が個人によってホストされている。

個人によって開始されたアプリケーションは、平均して、組織によって開始されたアプリケーションよりも多くのスターを獲得している。多くの非常に価値のある一人会社が現れるだろうと予想する人もいるのである(Sam Altmanのインタビューやredditでの議論を参照)。彼らは正しいかもしれないと私は思う。

100万のコミット
2万人以上の開発者がこれらの845のリポジトリに貢献している。彼らは合計で100万近くの貢献をしている!
そのうち、最も活発な50人の開発者は10万以上のコミットを行っており、平均して1人当たり2,000以上のコミットをしている。オープンソース開発者の上位50人の完全なリストはここで見ることができる。

成長する中国のオープンソースエコシステム
中国のAIエコシステムが米国のそれと分岐していることは、長い間知られていた(2020年のブログ記事でも言及した)。当時、私はGitHubが中国で広く使用されていないという印象を持っていたが、その見方は中国の2013年のGitHub禁止令に影響されていたのかもしれない。
しかし、この印象はもはや当てはまらない。GitHubには、中国の観客をターゲットにした非常に多くの人気のあるAIリポジトリがあり、その説明が中国語で書かれているほどなのである。Qwen、ChatGLM3、Chinese-LLaMAなど、中国語または中国語と英語のために開発されたモデルのリポジトリもある。
米国では多くの研究機関が言語モデルのためにRNNアーキテクチャから離れているが、RNNベースのモデルファミリーであるRWKVはまだ人気がある。
また、WeChat、QQ、DingTalkなど、中国で人気のある製品にAIモデルを統合する方法を提供するAIエンジニアリングツールもある。人気のあるプロンプトエンジニアリングツールの多くにも、中国語のミラーがあるのである。
GitHubの上位20アカウントのうち、6つは中国発のものである。
THUDM:清華大学の知識工学グループ(KEG)とデータマイニング。
OpenGVLab:上海人工知能研究所のGeneral Visionチーム。
OpenBMB:ModelBestと清華大学のNLPグループが設立したオープンラボ for Big Model Base。
InternLM:上海人工知能研究所から。
OpenMMLab:香港中文大学から。
QwenLM:Qwenモデルファミリーを公開しているアリババのAI研究所。
速く生きて、若く死ぬ
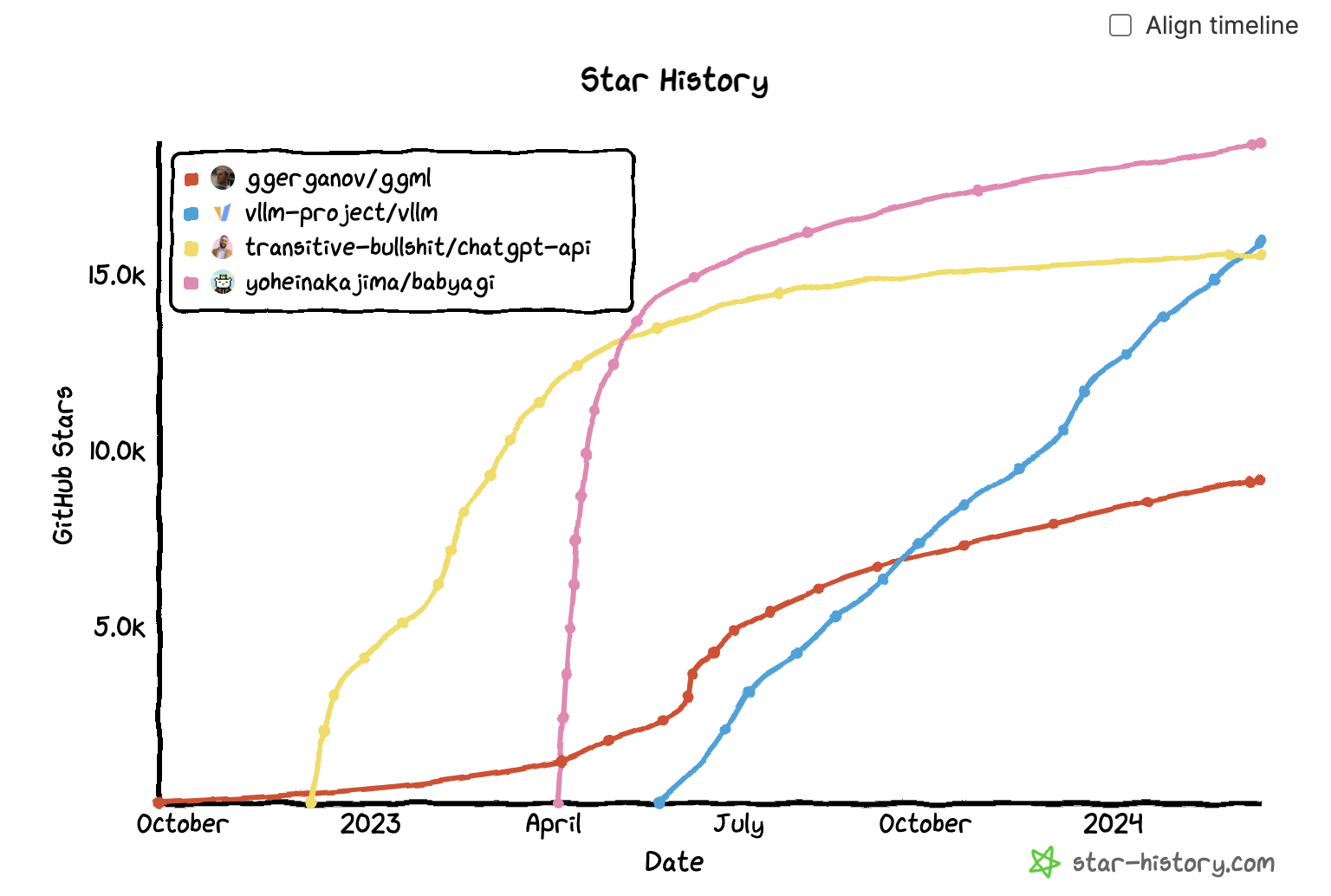
昨年私が見たあるパターンは、多くのリポジトリが一気に大量の注目を集めたが、すぐに下火になってしまった。私の友人の中には、これを「ハイプカーブ」と呼ぶ者もいるのだ。少なくとも500のGitHubスターを獲得したこれらの845のリポジトリのうち、158のリポジトリ(18.8%)は過去24時間に新しいスターを獲得しておらず、37のリポジトリ(4.5%)は過去1週間に新しいスターを獲得していないのである。
ここでは、そのような2つのリポジトリの成長軌跡を、より持続的なソフトウェアの成長曲線と比較した例を示すのだ。ここに示した2つの例は現在使用されていないが、コミュニティに何が可能かを示す上で価値があったと私は考えており、著者があれほど迅速に物事を進められたのは素晴らしいことだと思う。
私のお気に入りのアイデア
コミュニティによって、実に多くのクールなアイデアが開発されているのだ。私のお気に入りをいくつか紹介しよう。
バッチ推論の最適化:FlexGen、llama.cpp
Medusa、LookaheadDecodingなどの手法を用いたより高速なデコーダー
モデルのマージ:mergekit
制約付きサンプリング:outlines、guidance、SGLang
einopsやsafetensorsのように、1つの問題を非常にうまく解決するニッチなツール
結論
分析には845のリポジトリしか含めなかったが、私は数千のリポジトリを見てきた。これは、一見圧倒的に見えるAIエコシステムの全体像を掴むのに役立ったと思うのである。このリストが皆さんにとっても有用なものであることを願っている。私が見落としているリポジトリがあれば、ぜひお知らせいただきたい。リストに追加するつもりである!
最後に
この記事は、オープンソースAIの現状を845のGitHubリポジトリから丁寧に分析し、AIエコシステムの全体像を提示する。AIスタックの各層の動向や、開発者の活躍、中国のオープンソースコミュニティの成長など、その多角的な視点から行われる考察に驚かされる。
特に印象的だったのは、アプリケーション開発の活発さと、それを支える個人開発者の存在感についての指摘である。一人の開発者が10億ドル規模の価値を生み出す可能性があるという見方は、AIがもたらす変革の大きさを物語っているのである。これは、確かサムアルトマンも同じようなことを言っていたような気がする。
著者が挙げた、バッチ推論の最適化やモデルのマージなどの革新的なアイデアは、AIの効率化と応用の広がりを予感させる。イノベーションにおけるオープンソースコミュニティの力強さを実感させられた。AIの未来を占う上で、オープンソースの動向から目を離せないことを教えてくれている。