テキスト分析(=検索に最適なフォーマットに変換するプロセス)を行ってくれるanalyzer。
Elasticsearchにおいて、最も重要な機能のうちのひとつです。
今回はそんなanalyerを使う前に、最低限把握しておきたい内容をまとめました。
環境
- OS: Windows10
- Elasticsearch: 7.9.1
- Kibana: 7.9.1
本題
最低限把握しておきたい内容を以下にまとめます。
1. analyzerを構成する3つの要素
analyzerはcharacter filter, tokenizer, token filterの3つから構成されており、それぞれの役割は以下の通りです。
| 名称 | 内容 |
|---|---|
| Character filters | 文字列に対し、Tokenizerで分割する前に必要な処理(追加、削除、変更)を行う。 前処理的ポジションで、使用は任意。 |
| Tokenizer | 文字列を単語レベルに分割する役割を持つ。 必須項目。 |
| Token filters | Tokenizerで分割された内容に対し、必要な処理(追加、削除、変更)を行う。 後処理的ポジションで、使用は任意。 |
例として、
『こゝろも踊る軽やかサーバー』
という文章を
- Character filters:icu_normalizer, kuromoji_iteration_mark
- Tokenizer:kuromoji_tokenizer
- Token filters:kuromoji_stemmer, ngram
でテキスト分析すると以下のようになります。
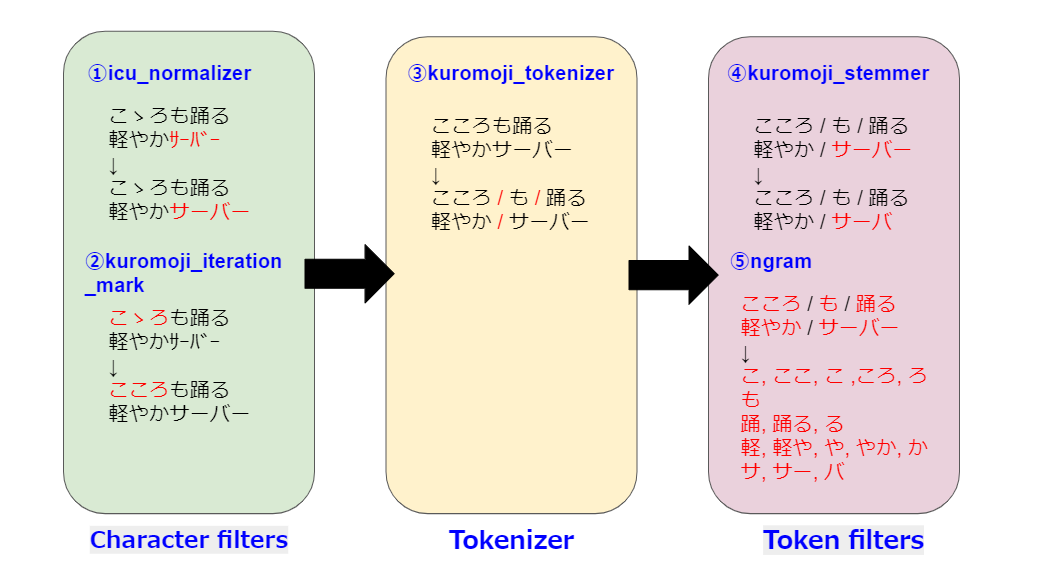
※各々の役割については、
に詳しく記載されていますので、そちらをご覧ください。
2. テキスト分析の対象
続いて、テキスト分析の対象になるのは何なのか把握しておきましょう。
- Elasticsearchに保存されているデータ
- クライアントに入力されて検索されるデータ
の2つになります。
上記2つは原則同じテキスト分析を用いるのが好ましいとされており、デフォルトでは同じ方法で分析されます。
が、どうしても異なる分析方法を使いたい場合は以下のように、インデックスを作成する際、mappingsでsearch analyzerを記述して、後者(=クライアントに入力されて検索されるデータ)の分析方法を別途指定します。
PUT my-index-000001
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
}
※上記はsearch_analyzer | Elasticsearch Reference [7.9] | Elasticの一部をそのまま拝借しました。
3. どうテキスト分析されるか確認する
対象が実際にどのようにテキスト分析されるか確認する方法も抑えておきましょう。
KibanaのDev Toolsをを開き、左側の入力欄に以下のように入力&実行します。
POST インデックス名(①)/_analyze
{
"analyzer": "使用したいanalyzer名(②)",
"text": "テキスト分析したい文字列(③)"
}
ここで、
- ①インデックス名:対象のインデックス名
- ②analyzer:独自で定義したanalyzer or Elasticsearchでデフォルトで使えるanalyzer(「4. デフォルトで使えるanalyzer」参照)
- ③text:テキスト分析したい文字列
と置き換えて実行するようにしてください。
例えば、「2. テキスト分析の対象」で出てきたインデックスに対し行う場合は、
- インデックス名:my-index-000001
- analyzer:autocomplete
- text:スラスラ書ける快適エディタ
となり、Kibanaでの実行内容は以下の通りとなります。
POST my-index-000001/_analyze
{
"analyzer": "autocomplete",
"text": "スラスラ書ける快適エディタ"
}
4. 設定なしで使えるanalyzer
Elasticsearchでは以下のanalyzerが独自に設定しなくても使えます。
(独自設定のサンプルについては、「2. テキスト分析の対象」に記載のインデックス定義(my-index-000001)が該当しますので、そちらをご参照ください。)
何も指定しない場合は、Standard Analyzerが使われます。
| 名称 | 指定方法(※) | 説明 |
|---|---|---|
| Standard Analyzer | standard | 文法ベースのトークン化を行う(デフォルト) |
| Simple Analyzer | simple | 数字、スペース、ハイフン、アポストロフィなどの文字でないもの(非文字)でテキストをトークンに分割した後、非文字を破棄し、大文字を小文字に変換する |
| Whitespace Analyzer | whitespace | 空白文字で分割を行う |
| Stop Analyzer | stop | 基本はSimple Analyzerと同じだが、ストップワード(the, a, forなど)を削除する |
| Keyword Analyzer | keyword | 入力文字列全体を1つのトークンとみなす |
| Language Analyzers | english、他 | 指定言語(リンク先のページに記載のもの)のテキスト分析を行う(日本語は対象外) |
| Fingerprint Analyzer | fingerprint | フィンガープリントアルゴリズムを用いる |
※「3. analyzerでの分析結果確認方法」のanalyzer(②)の位置に指定します。
5. 日本語分析に使えるプラグイン
日本語のテキスト分析を行うには、Elasticsearchがもともと搭載している機能だけでは不十分なため、別途プラグインを使用します。
代表的なのは、以下でしょうか。
必要なものをインストールして使用してください。
| 名称 | 説明 |
|---|---|
| Japanese (kuromoji) Analysis Plugin | atilikaによって作られた日本語形態解析エンジン Javaベース |
| Japanese (sudachi) Analysis Plugin | ワークス徳島人工知能NLP研究所によって作られた日本語形態解析エンジン こちらもJavaベース |
| ICU Analysis Plugin | tokenizerというよりは、ICU Normalization CharFilter を前処理に用いる |
kuromojiとICUについては、「1. analyzerを構成する3つの要素」でも一度記載していますが、
に、またsudachiについては、
に詳細に記載されていますので、そちらをご参照ください。
終わりに
analyzerの設定によって検索結果が大きく異なってきます。
まずはポイントを押さえて、正しく設定できるようにしていきたいところ。
参考
本文中に記載していませんが、参考にさせていただいたページ一覧です。
1. analyzerを構成する3つの要素
4. 設定なしで使えるanalyzer
- Built-in analyzer reference | Elasticsearch Reference [7.9] | Elastic
- ストップワード とは 意味/解説/説明 【stop words】 | Web担当者Forum