どうもCEさぼです。
1. はじめに
Pythonによるテーブルデータの取り扱いの練習のために、Twitter Analyticsからデータを取得し、DataFrameに格納し、簡単に分析してみました。
本当はTwitter API使いたかったんですが、めんどそうなので断念しました↓
内容は初心者向けです。
機械学習前のデータの整形やデータの取り扱いの練習にオススメかと思います。
2. 目的
いくつか問いを挙げて、それをクリアすることを目的にします。
今回は2020.1~4月までの4ヶ月間のツイートをすべて取得して行います。
Q1. 総ツイート数、1ヶ月・1日あたりのツイート数
Q2. インプレッション、RT、いいね、プロフィールクリック数合計
Q3. 各項目の最大値は?
Q4. 最大いいね、最大RTをもらったツイート内容は?
Q5. 各項目の相関
3. 環境、必要なもの
・Windows10
・Jupyter Lab(なかったらGoogle Colabでもいいと思います)
・自身のTwitterアカウント
4. Twitter Analyticsからツイートデータを取得
まずはTwitterアナリティクスにログインしましょう。
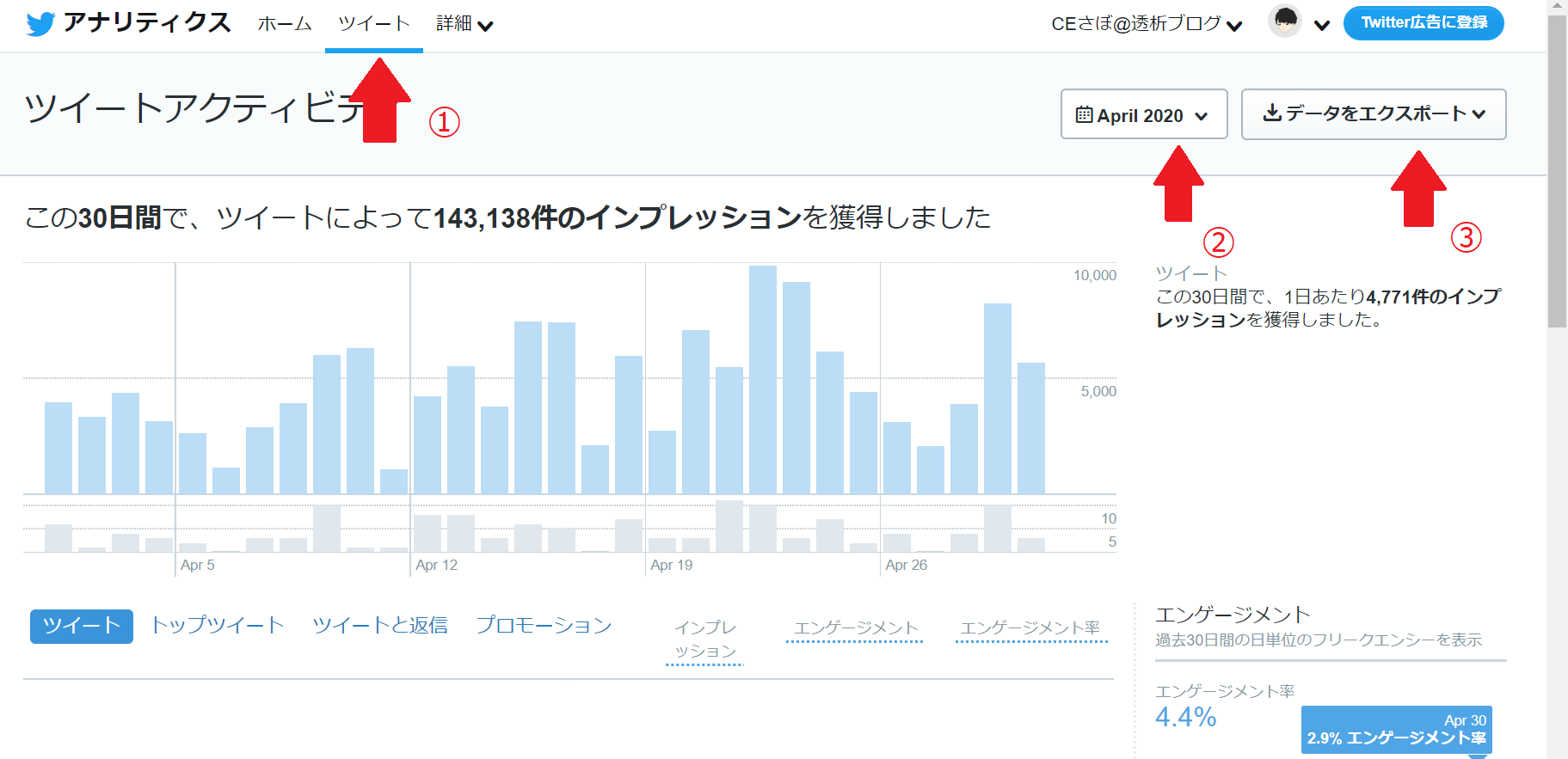
- ログインしたら①をクリックし画像の画面に移ります。
- 次に②を開いて、指定の月のツイートデータを選択
- ③でエクスポートしましょう。
1ヶ月ずつ、今回は4ヶ月分エクスポートしてみました。
5. データの読み込み
Google Colabの場合、データの読み込みは過去記事を見ると一瞬で分かります↓
【初心者向け】Google ColaboratoryでDataFrameにExcel・CSVファイルを読み込む
まずは必要なライブラリをインポートしましょう。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
次に1か月ごとにそれぞれDateFrameに格納します。
# TweetのデータをDataFrameに格納
df_January = pd.read_csv("January.csv")
df_February = pd.read_csv("February.csv")
df_March = pd.read_csv("March.csv")
df_April = pd.read_csv("April.csv")
※パスは任意のパスで指定してください
6. データの中身の確認
4つDataFrameができたので試しに中身を見てみましょう
df_January.head()
確認出来たらOK。
とりあえずDataFrameに格納できたけど、列名が気になりますね。
# 列名がどんなのかリストで取得してみる
df_January.columns.values
# output
array(['ツイートID', 'ツイートの固定リンク', 'ツイート本文', '時間', 'インプレッション', 'エンゲージメント',
'エンゲージメント率', 'リツイート', '返信', 'いいね', 'ユーザープロフィールクリック', 'URLクリック数',
'ハッシュタグクリック', '詳細クリック', '固定リンクのクリック数', 'アプリ表示', 'アプリインストール',
'フォローしている', 'ツイートをメール送信', 'ダイアル式電話', 'メディアの再生数', 'メディアのエンゲージメント',
'プロモのインプレッション', 'プロモのエンゲージメント', 'プロモのエンゲージメント率', 'プロモのリツイート',
'プロモの返信', 'プロモのいいね', 'プロモのユーザープロフィールクリック', 'プロモのURLクリック数',
'プロモのハッシュタグクリック', 'プロモの詳細クリック', 'プロモの固定リンクのクリック数', 'プロモのアプリ表示',
'プロモのアプリインストール', 'プロモのフォローしている', 'プロモのツイートをメール送信', 'プロモのダイアル式電話',
'プロモのメディアの再生数', 'プロモのメディアのエンゲージメント'], dtype=object)
arrayで返ってきました。
こんな項目あっても分析しきれないので、最小限に絞ってみます。
6. データの整形
6-1 4つのDataFrameを結合
# 結合したいDataFrameをlistで指定
combine = [df_January, df_February, df_March, df_April]
# concatでlistにしたDataFrameを縦に結合
tweets_df = pd.concat(combine)
concatはデフォだと縦に結合します。
機械学習の前処理でよく使うので覚えておくとよいです。
6-2 要らない列を削除=要る列のみを抽出
読み込んだデータを確認したときに40つも列がありました。今回の目的にはプロモの~とかはいりませんし、必要なものだけを抽出したいです。
単純に要らない列はdrop()で消しちゃえ!と思いましたが、今回の場合必要な列のみを取得した方が楽そうです。
# 指定の列のみ取得
tweets_df = tweets_df[["ツイート本文", "時間", "インプレッション", "リツイート", "いいね", "ユーザープロフィールクリック", "URLクリック数"]]
# sort_valuesはデフォは昇順
tweets_df = tweets_df.sort_values(by="時間")
6-3 列名の名前を変える
6-2のコードを書く際、日本語の列名だったため、いちいち文字変換を押すのがめんどくさかったです。
練習がてら列名を一括変更してみます。
このようなことが起こらないようにするためにはデータの読み込み時に列名を変えるのが良いですね。
# 列名を英語にする。リストを使って一括変更。
tweets_df.columns = ["tweet", "time", "inpression", "RT", "iine", "user_profile_click", "URL_click"]
7. 分析
Q1. 総ツイート数、1ヶ月・1日あたりのツイート数
これは行数をカウントすればよいだけです。
やり方はいろいろありますが、info()が便利です。
データの型とNull値もカウントしてくれます。
tweets_df.info()
# output
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tweet 486 non-null object
1 time 486 non-null object
2 inpression 486 non-null float64
3 RT 486 non-null float64
4 iine 486 non-null float64
5 user_profile_click 486 non-null float64
6 URL_click 486 non-null float64
4ヶ月で486ツイートでした。
では1ヶ月あたりは?4で割ればいいですね。
486/4
121.5ツイート/月でした。
Pythonは計算機としても使えます。
では1日あたりは?
121.5/30
4.05ツイート/日でした。
けっこう呟いてますね。
Q2. インプレッション、RT、いいね、プロフィールクリック数合計
合計をとりたい列を指定してsum()関数を使えば簡単です。
# axis=0は省略可
tweets_df[["inpression", "RT", "iine", "user_profile_click"]].sum(axis=0)
# output
inpression 411059.0
RT 180.0
iine 2454.0
user_profile_click 2594.0
dtype: float64
Q3. 各項目の最大値は?
ここで一回可視化してみましょうか。
可視化したいものが複数ある場合はsubplotを使うと別々に表示できます。
# 可視化してみる
tweets_df[["inpression", "RT", "iine", "user_profile_click"]].plot(subplots=True)

可視化するとデータの傾向が一気にわかりますね。
インプレッション5000以上が4つほど、RT10以上が1つ、いいね50以上が1つ、プロフクリックが200以上?今度はどんなツイートか気になってきます。
各項目の最大値をみていきましょう。
max()で簡単に出せます。
tweets_df.max()
# output
tweet 👍👍👍👍👍 https://t.co/5Wfe2kqh0x
time 2020-04-30 23:57 +0000
inpression 5838
RT 16
iine 82
user_profile_click 360
URL_click 275
数字のみ見ればよいかと。
Q4.最大いいね、最大RTをもらったツイート内容は?
列を指定し、idmax()を使います。
# いいねが最大値の行を取得
tweets_df["iine"].idxmax()
# output
432
行数が出るので行を指定して取り出します。
# いいね最大数の行を取得
tweets_df.iloc[432]
# output
tweet 新人に「穿刺と返血だけできるCEにはなるなよ」と言っておいた。なるべく早めに気付くといいな。
time 2020-04-20 06:24 +0000
inpression 5627
RT 7
iine 82
user_profile_click 128
URL_click 0
RTに対しても同じようにします。
# RTが最大値の行を取得
tweets_df["RT"].idxmax()
# output
417
# RT最大数の行を取得
tweets_df.iloc[417]
# output
tweet 【拡散希望】フォロワーさんの皆さんへ僕からのお願いがあります。臨床工学技士100人カイギの運...
time 2020-04-16 00:14 +0000
inpression 5276
RT 16
iine 27
user_profile_click 35
URL_click 0
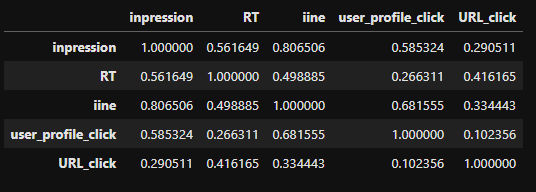
Q5. 各項目の相関
各項目の相関係数もcorr()で簡単に出せます。
デフォはpeasonで、methodでspearmanやkendallも指定できます。
corr = tweets_df.corr()
corr
seabornを使うとヒートマップという相関行列も出せます。
sns.heatmap(corr)

また、seabornを使わなくてもpandasのみ(しかも1行!)で、表示することもできるみたいです。
tweets_df.corr().style.background_gradient(axis=None)
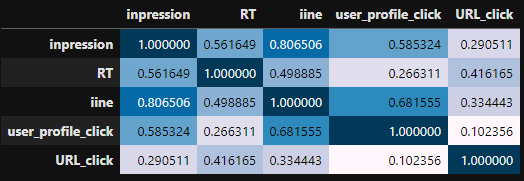
↑めっちゃいいですね。
いいねとインプレッションが相関があると言えそうです。
参考サイト
1)【Pythonによるデータ分析①】Pythonでツイッターのオリジナルデータから、拡散されやすいツイートを分析してみよう!
2)Pandasで合計を求めるsum関数の使い方-DeepAge
3)pandasのplotメソッドでグラフを作成しデータを可視化-note.nkmk.me
4)pandasで最大値・最小値の行名・列名を取得するidxmax, idxmin-note.nkmk.me
5)pandas.DataFrame, Seriesのインデックスを振り直すreset_index-note.nkmk.me
6)Pandas でデータフレームから特定の行・列を取得する-note.nkmk.me
7)【1行で】Pandasだけで相関行列をヒートマップ化する
8)pandas.DataFrameの各列間の相関係数を算出、ヒートマップで可視化-note.nkmk.me
この記事の4~6-2まで、マーケターDaiさんの記事1)をもとに作りました。
感謝申し上げます。