1.概要
今回は、自動作問系のWebアプリ作成過程を記事にしていきます。
「フレームワークに基づくタスク指向型対話システム」の作成と迷いましたが、また別の機会で作成にチャレンジしたいと思います。
今回作成したWebアプリの簡単な要件は以下の通りです。
- 入力されたテキストに基づいたクイズを作成
- 作成できる問題数は最大3つ
- 日本語NLPライブラリ「GiNZA」を利用して固有表現・主語を抽出
- Herokuを利用して公開(※ 今回作成したアプリはHerokuのメモリ上限を超過してしまうため、長時間稼働できず。)
2.目標設定
本アプリ及び本記事の作成にあたっての個人目標を記載します。
- HTML・CSSの基礎を理解する
- テキストから自然なクイズ(問題)を出題する手法を勉強する
3.実行環境
OS:Linux(Ubuntu 18.04LTS)
エディタ:Visual Studio Code
言語:python 3.9.2
4.Pythonパッケージのバージョン
今回利用したPythonパッケージのバージョンを記載します。
blis==0.7.4
catalogue==1.0.0
certifi==2021.5.30
charset-normalizer==2.0.4
click==7.1.2
cymem==2.0.5
Cython==0.29.24
dartsclone==0.9.0
Flask==2.0.1
ginza==4.0.6
idna==3.2
itsdangerous==2.0.1
ja-ginza==4.0.0
Jinja2==3.0.1
MarkupSafe==2.0.1
murmurhash==1.0.5
numpy==1.21.2
packaging==21.0
pathy==0.6.0
plac==1.1.3
preshed==3.0.5
pydantic==1.8.2
pyparsing==2.4.7
requests==2.26.0
smart-open==5.2.1
sortedcontainers==2.1.0
spacy==2.3.7
spacy-legacy==3.0.8
srsly==1.0.5
SudachiDict-core==20210802
SudachiPy==0.5.2
thinc==7.4.5
tqdm==4.62.2
typer==0.3.2
typing-extensions==3.10.0.2
urllib3==1.26.6
wasabi==0.8.2
Werkzeug==2.0.1
5.どんなアプリが完成したのか?
どんなアプリが完成したのかをスクリーンショットを用いながら紹介したいと思います。
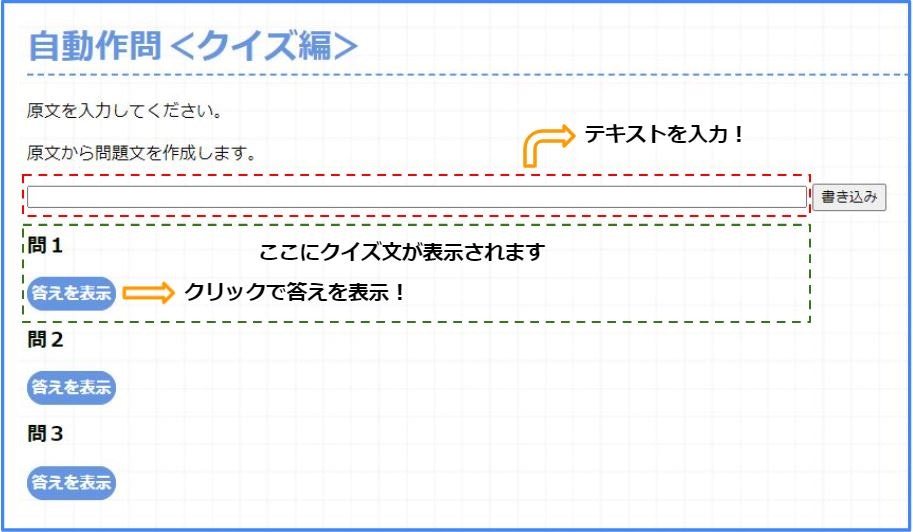
①初期画面
こちらは最初に表示される画面です。
テキスト入力欄や問題文が出力される箇所が表示されています。
<実際の画面>
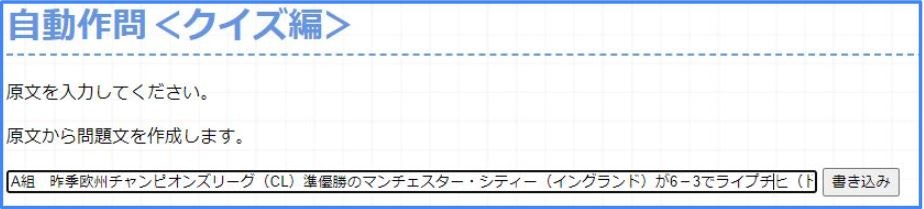
②テキスト欄にテキストを入力
クイズ文を生成するため、まずはテキストを入力します。
今回は以下のテキストを入力します。
<テキスト>
「A組 昨季欧州チャンピオンズリーグ(CL)準優勝のマンチェスター・シティー(イングランド)が6-3でライプチヒ(ドイツ)との打ち合いを制した。」
[引用記事:【欧州CL】マンC打ち合い制す リバプールはミランに競り勝つ]
(https://www.nikkansports.com/soccer/world/news/202109160000060.html)
<実際の画面>
③クイズ文を表示
テキストを入力した後、「書き込み」ボタン or __Enterキー__を押すことでクイズ文が表示されます。
下記の通り、入力されたテキストに基づいたクイズ文の作成ができました。
<クイズ文>
「a組 昨季欧州チャンピオンズリーグ準優勝の6-3でライプチヒとの打ち合いを制したのはどこ?」
<実際の画面>

④クイズの答えを表示
「答えの表示」ボタンをクリックすることで、答えが表示できます。
<実際の画面>

クイズ作成例
ここでは、様々なテキストを入力して作成できたクイズ文の例を紹介します。
作成例①
<テキスト>[引用記事:【欧州CL】マンC打ち合い制す リバプールはミランに競り勝つ]
(https://www.nikkansports.com/soccer/world/news/202109160000060.html)
「リバプール(イングランド)が3-2でACミラン(イタリア)に競り勝った。」
<クイズ文>
「3-2でacミランに競り勝ったのはどこ?」
<答え>
「リバプール」
<自己評価>
自然なクイズ文が生成できていると思います。
しかし、クイズ文のみを見て「リバプール」と答えるのはすこし難しそうですね。
入力したテキストにもう少し情報(5W1Hなど)が加わっていればより良いクイズ文が作成できたと思います。
作成例②
<テキスト>[引用記事: 麻生派は河野、岸田両氏が支持対象 高市氏も容認]
(https://www.sankei.com/article/20210916-55VAC7QYYFIERM3YGJ6PBRCHII/)
「麻生太郎副総理兼財務相は16日、自身が率いる自民党麻生派(志公会、53人)の緊急総会で、17日告示の党総裁選で派として支持する候補者の一本化を見送る考えを示した。」
<クイズ文>
「16日自身が率いる自民党麻生派の緊急総会で17日告示の党総裁選で派として支持する候補者の一本化を見送る考えを示したのは誰?」
<答え>
「財務相」
<自己評価>
自然なクイズ文は作成できました。
また、具体的なクイズ内容ですので比較的答えやすいクイズ文ができました。
しかし、答えが「財務相」となってしまいました。正解ではあるのですが、、「麻生太郎副総理兼財務相」と表示してほしかったです。ここは、コードの修正が必要ですね。
作成例③
<テキスト>[引用記事: 石破茂氏と河野太郎氏をつないだ菅首相が決断! 自民党総裁選で安倍氏・麻生氏と“全面戦争”]
(https://news.yahoo.co.jp/articles/52f9344fe1e9a451f8e371b1f493021dae8d9129)
「自民党総裁選(17日告示・29日投開票)への対応について、「白紙」で引っ張ってきた石破茂元幹事長は結局、出馬を見送る方向となった。15日の石破派の臨時総会で対応を説明するというが、石破氏は河野太郎行革担当相を支援する見通し。石破氏と河野氏の2人をつないだのは、ナント菅首相らしい。」
<クイズ文①>
「自民党総裁選への対応について「白紙」で引っ張ってきた結局出馬を見送る方向となったのは誰?」
<クイズ文②>
「15日の石破派の臨時総会で対応を説明するというが河野太郎行革担当相を支援する見通しのは誰?」
<答え>
①元幹事長
②石破氏
<自己評価>
今回は入力したテキストから2つのクイズ文が作成されました。
クイズ文①は微妙に日本語がおかしくなっていますが、どちらも意味の分かるクイズ文となっています。
しかし、ここでも答えが上手く出力できませんでした。クイズ文①の答えは「石破元幹事長」となってほしかった。
〇〇(人名)+ △△(役職)を一語として上手く認識できていないため、このような表示になっています。
6.ディレクトリ構造
Qgen/
├ static/
│ └ stylesheet.css
├ templates/
│ └ index.html
├ app.py
└ Question_Generator.py
7.コードの説明(Question_Generator.py)
ここでは、クイズ文作成を行うコード(Question_Generator.py)の中身を説明したいと思います。
コードの書き方が汚いかもしれませんが、お許しください。
7.0 ライブラリの読み込み
import spacy
import ginza
import re
7.1 入力文の前処理を行う関数
まずは、入力文に対して前処理を行う関数を作成します。
今回、行う前処理は以下の通りです。
- ()、[]内の文字を削除
- 改行の削除
- 大文字を全て小文字にする
- 「。」、「?」を区切り文字として文章を分割しリスト化
# 入力文の前処理を行う関数
# 引数(text): 任意のテキスト
# 返り値(sentences): 1文章を1要素としたリスト
def text_preprocessing(text):
text_pre = re.sub("\(.+?\)|\[.+?\]|\n", "", text) # [〇〇],(〇〇)という表現、改行は削除する
text_pre = text_pre.lower() # 文章をすべて小文字にする
sentences = re.split("[。?]", text_pre) # 。、?を区切り文字として文章を分割
sentences.pop(-1) # 最後の要素(空白)を削除
return sentences
7.2 文章の主語を取得する関数
文章中の主語が答えとなるクイズ文であれば比較的自然なクイズ文が作れそうだと思ったので、主語を抽出する関数を作成します。
# 文章の主語を取得する関数
# 引数1(sentence) : 1文章ごとのリスト
# 引数2(nlp) : spacy.load('ja_ginza')
# 返り値(subject_list): 主語が格納されたリスト
def parse_document(sentence, nlp):
doc = nlp(sentence)
tokens = []
## 参照しやすいようにトークンのリストを作る
for sent in doc.sents:
for token in sent:
tokens.append(token)
## 主語のリスト
subject_list = []
for token in tokens:
## 依存関係ラベルがnsubj or iobjであれば「<見出し語>:<係り先の見出し語>」をリストに追加する。
if token.dep_ in ["nsubj", "iobj"]:
subject_list.append(token.lemma_)
return subject_list
[参考記事: GiNZA+Elasticsearchで係り受け検索の第一歩]
(https://acro-engineer.hatenablog.com/entry/2019/12/06/120000)
7.3 「〇〇氏」を1語として連結するための関数
政治のニュース記事などにおいて、「〇〇氏」などの表現が多く使われています。
現時点のGiNZAの固有表現抽出において、「〇〇氏」を1語として上手く認識することはできません。
そのため、「〇〇」と「氏」を1語に連結させる処理を行う関数を作成します。
この関数の処理内容は後ほど、この関数が使われる際に説明します。
# 「〇〇氏」を1語として認識するための関数
# 引数1(keywords) : 固有表現が1語ずつ格納されたリスト
# 引数2(keywords_label) : 固有表現の種類が1語ずつ格納されたリスト
# 引数3(pos) : 挿入位置情報
# 返り値(keywords) : 処理後の固有表現のリスト
# 返り値(keywords_label) : 処理後の固有行表現の種類のリスト
def name_extract(keywords ,keywords_label, pos):
for i ,keyword in enumerate(keywords):
if keyword == "氏":
num = i
break
else:
num = 0
if num != 0:
keywords_ex = keywords[num-1:num+1] # 「氏」と連結する要素を取り出す
keywords_ex = "".join(keywords_ex) # 連結して「〇〇氏」という1語にする
del keywords[num-1:num+1] # 「〇〇」と「氏」の要素を削除
label = keywords_label[num-1] # 「〇〇」のラベルを一時保存
keywords.insert(pos,keywords_ex) # posの位置に「〇〇氏」を挿入
del keywords_label[num-1:num+1] # 「〇〇」「氏」のラベル(種類)は排除
keywords_label.insert(pos, label) # posの位置に「〇〇」のラベルを挿入
return keywords, keywords_label
7.4 クイズ文を生成する関数
これまでに作成した関数などを用い、クイズ文を生成する関数を作成します。
この関数のコードは少し長くなってますので、適度に切り分けながら説明していきます。
今回、以下のテキストを入力文として例に説明していきます。
石破氏は15日、自身が顧問を務める石破派(水月会、17人)の臨時会合で、出馬を断念し河野ワクチン担当相を支持すると明らかにした。
※本節で記載するコードはすべて同じ関数内のコードとなります。
def QuestionGenerator(text):
まず、クイズ文、答え、答えの種類を格納するための空リストを作成します。
question = [] # クイズを格納
answer = [] # 答えを格納
answer_label = [] # 答えの種類
次に、入力されたテキストの前処理を行います。
出力結果を見てみると、()内の文字が削除されています。
今回は1文章のみなので、リストの要素数は1になります。2文章であれば要素数2、3文章であれば要素数3...といった感じです。
sentences = text_preprocessing(text)
## 出力結果
## sentences: ['石破氏は15日、自身が顧問を務める石破派の臨時会合で、出馬を断念し河野ワクチン担当相を支 持すると明らかにした']
次に、1文章ごとに処理を行うfor文を作成します。
for idx, sentence in enumerate(sentences):
次に、GiNZAによる文章の解析を行います。
# GiNZAによる解析
nlp = spacy.load('ja_ginza')
doc = nlp(sentence) # 解析
次に文章を文節に区切ったリストを作成します。このリストはクイズの答えが含まれた文節を削除する際に用いることになります。
# 文節ごとに区切ったリストを作成し、型変換(spacy ⇒ str型)
change_phrases = []
phrases = ginza.bunsetu_spans(doc) # 文節ごとに区切ったリスト
for i in range(len(phrases)):
change_phrases.append(str(phrases[i]))
## 出力結果
## change_phrases: ['石破氏は', '15日、', '自身が', '顧問を', '務める', '石破派の', '臨時会合で、', '出馬を', '断念し', '河野ワクチン担当相を', '支持すると', '明らかに', 'した']
次は、文章中の主語の抽出です。
以下の出力結果の通り、今回は「氏」と「自身」が主語と判定されました。
# 主語の抽出
subject_list = parse_document(sentence, nlp)
## 出力結果
## subject_list: ['氏', '自身']
次に、GiNZAによる「固有表現」と「その固有表現の種類」の抽出を行います。「固有表現の種類」の例として以下のようなものが挙げられます。
- Person:人
- Date:日時
- Position_Vocation:役職
- Country:国
- Company:企業
「固有表現」はkeywordsに、「固有表現の種類」はkeywords_labelに格納します。
keywords と keywords_label のそれぞれの要素は対応関係にあります。
後ほど、この「固有表現の種類」に従ってクイズ文の言い回しを決定します。
(例)
- 石破 ⇒ Person
- 15日 ⇒ Date
- ワクチン担当相 ⇒ Position_Vocation
# GiNZAによる固有表現の抽出
keywords = []
keywords_label = []
for ent in doc.ents:
keywords.append(ent.text)
keywords_label.append(ent.label_)
## 出力結果
## keywords: ['石破', '氏', '15日', '顧問', '河野', 'ワクチン担当相']
## keywords_label:['Person', 'Title_Other', 'Date', 'Position_Vocation', 'Person', 'Position_Vocation']
先ほど得られたkeywordsの中身を見てみると、「石破」と「氏」が分かれています。本来、「氏」は敬称ですので「石破氏」といった風に1語としたいのですが、1語に出来ていません。
そのため、「石破」と「氏」を連結させます。
この処理により、「石破氏」を1語として認識できた新たなkeywordsとkeywords_labelが得られます。
# 「〇〇氏」を1語として認識するための処理
count = keywords.count("氏") # keywordsに「氏」が何個含まれているか確認する
for i in range(0, count):
keywords, keywords_label = name_extract(keywords,keywords_label, i)
## 出力結果
## keywords: ['石破氏', '15日', '顧問', '河野', 'ワクチン担当相']
## keywords_label: ['Person', 'Date', 'Position_Vocation', 'Person', 'Position_Vocation']
続いては、文章からクイズの答えを抽出するための処理を行います。
今回、答えとして抽出される単語の条件は以下の通りとなります。
固有表現も主語もGiNZAを使えば簡単に抽出できるので大変便利です。
- 固有表現である
- 文章の主語である
処理後、以下のリストが得られます。
answer :クイズ文の答え
answer_label:答えの種類
answer_copy: answerのコピー(一時的に利用)
answer_label_copy: answer_labelのコピー(一時的に利用)
# 固有表現かつ主語である単語を抽出
answer_copy = [] # answerのコピー用
answer_label_copy = [] # answerのコピー用
for i, keyword in enumerate(keywords):
if len(subject_list) == 0: # 主語が無い文章は処理を行わない
break
elif subject_list[0] in keyword: # 最初に現れた主語を対象とする
answer.append(keywords[i]) # 回答のリストを格納
answer_label.append(keywords_label[i]) # 回答のラベルを格納
answer_copy.append(keywords[i])
answer_label_copy.append(keywords_label[i])
## 出力結果
## answer : ['石破氏']
## answer_label: ['Person']
## answer_copy : ['石破氏']
## answer_label: ['Person']
続いて、先ほど取得したanswer_label_copy、answer_copyを用いてクイズ文を生成します。
処理後、以下のクイズ文が生成されました。
<クイズ文>
「15日、自身が顧問を務める石破派の臨時会合で、出馬を断念し河野ワクチン担当相を支持すると明らかにしたのは誰?」
ここでの簡単な処理の流れは以下の通りです。
①答えの種類を取得
②答えの種類が「Person」or 「Position_Vocation」であるかを判定
<真の場合>
③答えが含まれた文節を除去
④「のは誰?」という疑問形を連結
⑤リストに追加
<偽の場合>
③答えを削除
for i, label in enumerate(answer_label_copy):
if label == "Person" or label == "Position_Vocation":
key = answer_copy[i] # 答えを格納
# 答えが含まれた文節を除去
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
## 出力結果
## extract_phrase: 15日、自身が顧問を務める石破派の臨時会合で、出馬を断念し河野ワクチン担当相を支持すると明らかにした
# 疑問形を連結
question_text = extract_phrase + "のは誰?"
question.append(question_text)
## 出力結果
## question: ['15日、自身が顧問を務める石破派の臨時会合で、出馬を断念し河野ワクチン担当相を支持すると明らかにしたのは誰?']
else:
answer.pop(i)
7.5 クイズ文を一つずつ取り出し、ストップワードを削除する関数
ここでは、これまでで作成したクイズ文からストップワードを削除します。このタイミングでストップワードを削除するのが正しいのかは分かりませんが、今回はこのタイミングでストップワードを削除します。
また、入力テキストからクイズ文が生成できなかった場合は「エラー」という文字列を返すようにします。
ここまでで、Question_Generator.pyは完成です。
# 問題文を一つずつ取り出し、ストップワードを削除する関数
# 引数(text) : 任意のテキスト
# 返り値1(Question) :クイズ文(ストップワード削除)
# 返り値2(answer) :クイズ文の答え
def processing_question_text(text):
question, answer = QuestionGenerator(text)
nlp = spacy.load('ja_ginza')
wakati_doc = [] # 分かち書きされた問題文のリスト
for txt in question:
wakati_text = []
doc = nlp(txt)
for sent in doc.sents:
for token in sent:
wakati_text.append(token.orth_)
wakati_doc.append(wakati_text)
# ストップワードの削除
Question = []
stopwords = ["しかし", "、", "また"]
for i in range(len(wakati_doc)):
changed_words = [word for word in wakati_doc[i] if word not in stopwords]
changed_words = "".join(changed_words)
Question.append(changed_words)
# クイズ文がなければ「エラー」という文字列を返す
if len(Question) == 0:
Question.append("エラー")
if len(answer) == 0:
answer.append("エラー")
return Question, answer
7.6 コード全体
import spacy
import ginza
import re
import pprint as p
# 入力文の前処理を行う関数
# 引数(text): 任意のテキスト
# 返り値(sentences): 1文章を1要素としたリスト
def text_preprocessing(text):
text_pre = re.sub("\(.+?\)|\[.+?\]|\n", "", text) # [〇〇],(〇〇)という表現、改行は削除する
text_pre = text_pre.lower() # 文章をすべて小文字にする
sentences = re.split("[。?]", text_pre) # 。、?を区切り文字として文章を分割
sentences.pop(-1) # 最後の要素(空白)を削除
return sentences
# 文章の主語を取得する関数
# 引数1(sentence) : 1文章ごとのリスト
# 引数2(nlp) : spacy.load('ja_ginza')
# 返り値(subject_list): 主語が格納されたリスト
def parse_document(sentence, nlp):
doc = nlp(sentence)
tokens = []
## 参照しやすいようにトークンのリストを作る
for sent in doc.sents:
for token in sent:
tokens.append(token)
## 主語のリスト
subject_list = []
# subject_tag = []
for token in tokens:
## 依存関係ラベルがnsubj or iobjであれば「<見出し語>:<係り先の見出し語>」をリストに追加する。
if token.dep_ in ["nsubj", "iobj"]:
# subject_list.append(f"{token.lemma_}:{tokens[token.head.i].lemma_}")
subject_list.append(token.lemma_)
# subject_tag.append(token.tag_)
return subject_list
# 「〇〇氏」を1語として認識するための関数
# 引数1(keywords) : 固有表現が1語ずつ格納されたリスト
# 引数2(keywords_label) : 固有表現の種類が1語ずつ格納されたリスト
# 引数3(pos) : 挿入位置情報
# 返り値(keywords) : 処理後の固有表現のリスト
# 返り値(keywords_label) : 処理後の固有行表現の種類のリスト
def name_extract(keywords ,keywords_label, pos):
for i ,keyword in enumerate(keywords):
if keyword == "氏":
num = i
break
else:
num = 0
if num != 0:
keywords_ex = keywords[num-1:num+1] # 「氏」と連結する要素を取り出す
keywords_ex = "".join(keywords_ex) # 連結して「〇〇氏」という1語にする
del keywords[num-1:num+1] # 「〇〇」と「氏」の要素を削除
label = keywords_label[num-1] # 「〇〇」のラベルを一時保存
keywords.insert(pos,keywords_ex) # posの位置に「〇〇氏」を挿入
del keywords_label[num-1:num+1] # 「〇〇」「氏」のラベル(種類)は排除
keywords_label.insert(pos, label) # posの位置に「〇〇」のラベルを挿入
return keywords, keywords_label
# クイズ文を生成する関数
# 引数(text) :任意のテキスト
# 返り値1(question) :クイズ文が格納されたリスト
# 返り値2(answer) :答えが格納されたリスト
def QuestionGenerator(text):
question = [] # クイズを格納
answer = [] # 答えを格納
answer_label = [] # 答えの種類
sentences = text_preprocessing(text)
for idx, sentence in enumerate(sentences):
# GiNZAによる解析
nlp = spacy.load('ja_ginza')
doc = nlp(sentence) # 解析
# 文節ごとに区切ったリストを作成し、型変換(spacy ⇒ str型)
change_phrases = []
phrases = ginza.bunsetu_spans(doc) # 文節ごとに区切ったリスト
for i in range(len(phrases)):
change_phrases.append(str(phrases[i]))
print("文節区切り:", change_phrases) # 確認用
# 主語の抽出
subject_list = parse_document(sentence, nlp)
print("主語:", subject_list)
# GiNZAによる固有表現の抽出
keywords = []
keywords_label = []
for ent in doc.ents:
keywords.append(ent.text)
keywords_label.append(ent.label_)
# 「〇〇氏」を1語として認識するための処理
count = keywords.count("氏") # keywordsに「氏」が何個含まれているか確認する
for i in range(0, count):
keywords, keywords_label = name_extract(keywords,keywords_label, i)
# 固有表現かつ主語である単語を抽出
answer_copy = []
answer_label_copy = []
for i, keyword in enumerate(keywords):
if len(subject_list) == 0: # 主語が無い文章は処理を行わない
break
elif subject_list[0] in keyword: # 最初に現れた主語を対象とする
answer.append(keywords[i]) # 回答のリストを格納
answer_label.append(keywords_label[i]) # 回答のラベルを格納
answer_copy.append(keywords[i])
answer_label_copy.append(keywords_label[i])
# クイズ文を生成する処理
for i, label in enumerate(answer_label_copy):
if label == "Person" or label == "Position_Vocation":
key = answer_copy[i] # 答えを格納
# 答えが含まれた文節を除去
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
print("extract_phrase:", extract_phrase) # 確認用
# 疑問形を連結
question_text = extract_phrase + "のは誰?"
question.append(question_text)
elif label == "Country" or label == "Animal_Part" or label == "Province" or label == "Company" or label == "Game" or label == "Pro_Sports_Organization":
key = answer_copy[i]
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
question_text = extract_phrase + "のはどこ?"
question.append(question_text)
elif label == "Government" or label == "Military" or label == "International_Organization" or label == "Political_Organization_Other" or label == "Plan":
key = answer_copy[i]
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
question_text = extract_phrase + "のはどこの組織?"
question.append(question_text)
elif label == "Event_Other" or label == "Doctrine_Method_Other" or label == "Conference" or label == "Book" or label == "Product_Other":
key = answer_copy[i]
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
question_text = extract_phrase + "のは何?"
question.append(question_text)
elif label == "Mountain":
key = answer_copy[i]
extract_phrase = [ s for s in change_phrases if not key in s ]
extract_phrase = "".join(extract_phrase)
question_text = extract_phrase + "のはどこの山?"
question.append(question_text)
else:
answer.pop(i)
return question, answer
# 問題文を一つずつ取り出し、ストップワードを削除する関数
# 引数(text) : 任意のテキスト
# 返り値1(Question) :クイズ文(ストップワード削除)
# 返り値2(answer) :クイズ文の答え
def processing_question_text(text):
question, answer = QuestionGenerator(text)
nlp = spacy.load('ja_ginza')
wakati_doc = [] # 分かち書きされた問題文のリスト
for txt in question:
wakati_text = []
doc = nlp(txt)
for sent in doc.sents:
for token in sent:
wakati_text.append(token.orth_)
wakati_doc.append(wakati_text)
# ストップワードの削除
Question = []
stopwords = ["しかし", "、", "また"]
for i in range(len(wakati_doc)):
changed_words = [word for word in wakati_doc[i] if word not in stopwords]
changed_words = "".join(changed_words)
Question.append(changed_words)
# クイズ文がなければ「エラー」という文字列を返す
if len(Question) == 0:
Question.append("エラー")
if len(answer) == 0:
answer.append("エラー")
return Question, answer
8. コード内容(app.py)
このコードはシンプルな作りなのであまり説明はいらないですね。
ここでは、Question_Generator.pyの関数を呼び出します。
そして、クイズ文が格納されたリスト、格納されたリストを取得し、それぞれtext, answerに渡します。
from flask import Flask, request, render_template
import Question_Generator
import os
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'GET':
return render_template('index.html')
elif request.method == "POST" :
form_input = request.form['input']
text, answer = Question_Generator.processing_question_text(form_input)
if len(text) == 1:
return render_template('index.html',
test_input=text[0], test2_input="", test3_input="",
answer1=answer[0], answer2="", answer3="")
if len(text) == 2:
return render_template('index.html',
test_input=text[0], test2_input=text[1], test3_input="",
answer1=answer[0], answer2=answer[1], answer3="")
if len(text) >= 3:
return render_template('index.html',
test_input=text[0], test2_input=text[1], test3_input=text[2],
answer1=answer[0], answer2=answer[1], answer3=answer[2])
if __name__ == '__main__':
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
9 コード内容(index.html)
index.htmlの中身です。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel='stylesheet' href="./static/stylesheet.css">
</head>
<body>
<div class="bg_pattern Paper_v2"></div>
<h1>自動作問<クイズ編></h1>
<form method="post" action="">
<p>原文を入力してください。</p>
<p>原文から問題文を作成します。</p>
<input name="input" id="input" type="text" size="100" maxlength="1000">
<input name="Button1" type="submit" value="書き込み">
</form>
<h3>問1</h3>
<p> {{ test_input }}</p>
<div class="hidden_box">
<label for="label1">答えを表示</label>
<input type="checkbox" id="label1"/>
<div class="hidden_show">
<!--非表示ここから-->
<p>{{ answer1}}</p>
<!--ここまで-->
</div>
</div>
<h3>問2</h3>
<p>{{ test2_input}}</p>
<div class="hidden_box">
<label for="label2">答えを表示</label>
<input type="checkbox" id="label2"/>
<div class="hidden_show">
<!--非表示ここから-->
<p>{{ answer2}}</p>
<!--ここまで-->
</div>
</div>
<h3>問3</h3>
<p>{{ test3_input}}</p>
<div class="hidden_box">
<label for="label3">答えを表示</label>
<input type="checkbox" id="label3"/>
<div class="hidden_show">
<!--非表示ここから-->
<p>{{answer3}}</p>
<!--ここまで-->
</div>
</div>
</body>
</html>
10.コード内容(stylesheet.css)
stylesheet.cssの中身です。
/*チェックは見えなくする*/
.hidden_box input {
display: none;
}
/*中身を非表示にしておく*/
.hidden_box .hidden_show {
height: 0;
padding: 0;
overflow: hidden;
opacity: 0;
transition: 0.4s;
}
/*クリックで中身表示*/
.hidden_box input:checked ~ .hidden_show {
padding: 10px 0;
height: auto;
opacity: 1;
}
/*ボタン装飾*/
.hidden_box label {
padding: 3px;
font-weight: bold;
font-size: 15px;
border: solid 1.5px #6594e0;
cursor :pointer;
border-radius: 100vh;
color: #fff;
background-color: #6594e0;
margin-top: 3px;
}
/* 答えの文字を装飾 */
.hidden_show {
font-weight: bold
}
/* ページタイトルの装飾 */
h1 {
color: #6594e0;/*文字色*/
/*線の種類(点線)2px 線色*/
border-bottom: dashed 2px #6594e0;
}
/* 背景の装飾(方眼紙) */
.bg_pattern {
position: fixed;
top: 0;
left: 0;
width: 100vw;
height: 100vh;
background-color: #fff;
z-index: -1;
}
.Paper_v2 {
background-image:
repeating-linear-gradient(to bottom,
transparent 25px,
rgba(0, 0, 0, 0.04) 26px, rgba(0, 0, 0, 0.04) 26px,
transparent 27px, transparent 51px,
rgba(0, 0, 0, 0.04) 52px, rgba(0, 0, 0, 0.04) 52px,
transparent 53px, transparent 77px,
rgba(0, 0, 0, 0.04) 78px, rgba(0, 0, 0, 0.04) 78px,
transparent 79px, transparent 103px,
rgba(0, 0, 0, 0.04) 104px, rgba(0, 0, 0, 0.04) 104px,
transparent 105px, transparent 129px,
rgba(0, 0, 0, 0.04) 130px, rgba(0, 0, 0, 0.04) 130px),
repeating-linear-gradient(to right,
transparent 25px,
rgba(0, 0, 0, 0.04) 26px, rgba(0, 0, 0, 0.04) 26px,
transparent 27px, transparent 51px,
rgba(0, 0, 0, 0.04) 52px, rgba(0, 0, 0, 0.04) 52px,
transparent 53px, transparent 77px,
rgba(0, 0, 0, 0.04) 78px, rgba(0, 0, 0, 0.04) 78px,
transparent 79px, transparent 103px,
rgba(0, 0, 0, 0.04) 104px, rgba(0, 0, 0, 0.04) 104px,
transparent 105px, transparent 129px,
rgba(0, 0, 0, 0.04) 130px, rgba(0, 0, 0, 0.04) 130px);
}
11.作成したWebアプリをデプロイ(Heroku)
このWebアプリを公開するためHerokuにデプロイします。
本記事では、デプロイまでの方法は記載はしません。
※今回作成したアプリはHerokuのメモリ上限を超過してしまうため、長時間稼働できませんでした。
12.全体を通しての振り返り
本記事では任意のテキストからクイズを作成するWebアプリの作成を目標として、クイズ作成までの手順説明から結果、自己評価までを行いました。本章では、クイズ作成に取り組んだことで得られたこと、課題、今後の目標をまとめていきます。
【得られたこと】
- HTML・CSSの基礎部分を理解できた
- GiNZAは便利なライブラリ(主語・固有表現の抽出が容易にできる)
- 主語を正確に認識できれば自然なクイズ文は作成可能
- 答えの種類(Person, Date, Book....)それぞれでクイズ文の言い回しが変わるため、if文だけですべてに対応するのは難しい
【課題】
- 「〇〇(人名)+ △△(敬称・役職名等..)」をどのようにして1語として認識させるか(今回は「〇〇+氏」しか対応できていていない)
- 答えに合わせた適切な言い回しをいかに実現するか
- 体現止めで書かれたテキストの場合、不自然なクイズ文が生成される。この問題をどう解決するか
【今後の目標】
- 多種多様なテキストに対応できるクイズ生成アプリの作成
- テキスト以外のデータ(画像・動画・音声)からクイズ文を生成するアプリの作成
13.最後に
今回は、任意のテキストからクイズ文を生成するWebアプリを作成することができました。正直、精度は高くなくクイズ文が上手く生成できない、不自然な日本語になる、などの課題も残りました。
この課題に上手く対応するには、大量のデータで学習した生成モデルを利用するしかないのかな、と思っています。
まだまだ自分の知らない手法があるかもしれないので、今後も勉強していきながら自動作問に挑戦していきます!
ここまで読んでいただきありがとうございました。