はじめに
matplotとpandasを使ったグラフ作成です。
自分が研究でよく使うグラフを纏めました。
よろしければ使ってあげて下さい。
使用データ
flows.csvは以下のデータ形式
| date | observed | simulated |
|---|---|---|
| 1999/11/1 | 0.215 | 0.183 |
| 1999/11/2 | 0.176 | 0.173 |
| 1999/11/3 | 0.126 | 0.157 |
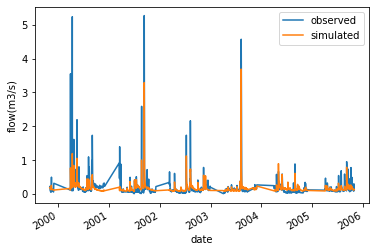
時系列グラフ
pandasで読み込んで表示するだけ
出力結果
ソースコード
import pandas as pd
path = "flows.csv"
# csvデータの読み込み
data = pd.read_csv(path)
# 日付データの変更
data["date"] = pd.to_datetime(data["date"])
# 日付データをインデックスに設定
data = data.set_index("date")
# 時系列データの表示
data.plot(xlabel='date', ylabel='flow(m3/s)')
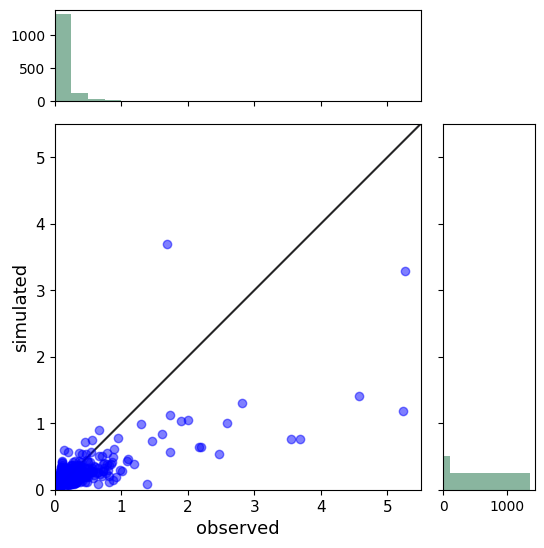
散布図
1対1の散布図とヒストグラムの作成。推定値と実測値の大小関係を表示。過大評価、過小評価の傾向を確認します。
ここを参考にしました。
出力結果
ソースコード
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def scatter_hist(df, x_label, y_label, ax, ax_histx, ax_histy):
x = df[x_label]
y = df[y_label]
# 表示する軸ラベルを限定
ax_histx.tick_params(axis="x", labelbottom=False)
ax_histy.tick_params(axis="y", labelleft=False)
# y=xの直線記述
ax.axline((-1,-1),(5000,5000), zorder=1,color='#252526')
##### 散布図作成 #####
ax.scatter(x, y, zorder=2, alpha=0.5, color='#0000FF')
# 軸範囲を制限
xymax = max(np.max(np.abs(x)), np.max(np.abs(y)))
ax.set_xlim(0,int(xymax)*1.1)
ax.set_ylim(0,int(xymax)*1.1)
# 軸ラベルフォントサイズ設定
ax.tick_params(axis='x', labelsize=11)
ax.tick_params(axis='y', labelsize=11)
# ラベルのフォントサイズ設定
ax.set_xlabel('observed', fontsize=13)
ax.set_ylabel('simulated', fontsize=13)
##### ヒストグラム作成 #####
# 階級幅作成
binwidth = 0.25 # 幅設定
lim = (int(xymax/binwidth) + 1) * binwidth
bins = np.arange(0, lim + binwidth, binwidth)
# 描画
ax_histx.hist(x, bins=bins, color='#89B59F')
ax_histy.hist(y, bins=bins, orientation='horizontal', color='#89B59F')
path = "flows.csv"
# csvデータの読み込み
data = pd.read_csv(path)
# 正方形の図を設定
fig = plt.figure(figsize=(6, 6), dpi=100)
# グラフを2*2の区画に分割
# それぞれの区画の幅の比はwidth_ratios,height_ratios
# その他のパラメータでグラフの大きさ,間隔調整
gs = fig.add_gridspec(2, 2, width_ratios=(4, 1), height_ratios=(1, 4),
left=0.1, right=0.9, bottom=0.1, top=0.9,
wspace=0.1, hspace=0.1)
# axを定義
ax = fig.add_subplot(gs[1, 0])
ax_histx = fig.add_subplot(gs[0, 0], sharex=ax)
ax_histy = fig.add_subplot(gs[1, 1], sharey=ax)
# グラフを描画(散布図,ヒストグラム)
scatter_hist(data, 'observed', 'simulated', ax, ax_histx, ax_histy)
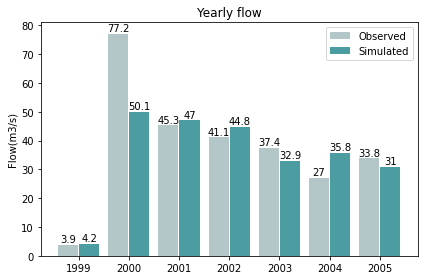
棒グラフで年毎の流量比較
年毎の総流量を実測値と推定値で比較。matplotlibのver3.5以降で使えます。
ここを参考にしました。
出力結果
ソースコード
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
path = "flows.csv"
# csvデータの読み込み
data = pd.read_csv(path)
# 日付データの変更
data["date"] = pd.to_datetime(data["date"])
# 日付データをインデックスに設定
data = data.set_index("date")
# 月毎のデータ合計
data = data.resample('Y').sum()
data = data.set_index(data.index.year)
# DataFrameをリスト化
labels = list(data.index)
observed_lst= [round(flow,1) for flow in data['observed']]
simulated_lst = [round(flow,1) for flow in data['simulated']]
x = np.arange(len(labels)) # ラベルの位置
width = 0.4 # バーの幅
gap = 0.01 # バーの間隔
fig, ax = plt.subplots()
flows1 = ax.bar(x - width/2-gap, observed_lst, width, label='Observed', color = '#b4c7c8')
flows2 = ax.bar(x + width/2+gap, simulated_lst, width, label='Simulated', color = '#4c9da2')
# ラベル,タイトル等の追加
ax.set_ylabel('Flow(m3/s)')
ax.set_title('Yearly flow')
ax.set_xticks(x, labels = labels) # ver3.5以降で追加
ax.legend()
# 棒グラフの上に数値を表示
ax.bar_label(flows1, padding=0.5)
ax.bar_label(flows2, padding=0.5)
# 無駄な余白を埋める
fig.tight_layout()
終わりに
随時追加予定