この記事は fintalk Advent Calendar 2019 12日目の記事です.
たまにfinpyなどのイベントに参加させていただいている(まだ2回ぐらい)いるものです.
いつもお世話になっているので今回記事を書くことにしました.
今回紹介するのは私が決算情報などのデータを取るのを苦戦していた時に,ナイスタイミングで後輩が紹介してくれた CoARiJ から決算情報などを取り出し,Word2Vecにかけたいと思います.
CoARiJ
CoARiJ では決算情報などを取り出すことができます.pipでライブラリを使用することもできますが,今回はサイトからデータを取り出して使用しました.普通決算文書はPDFになっていますが,txtデータで格納されていますのでとても便利です.しかし,見た限りだと全てのデータは入っていないと思います.
Word2Vec
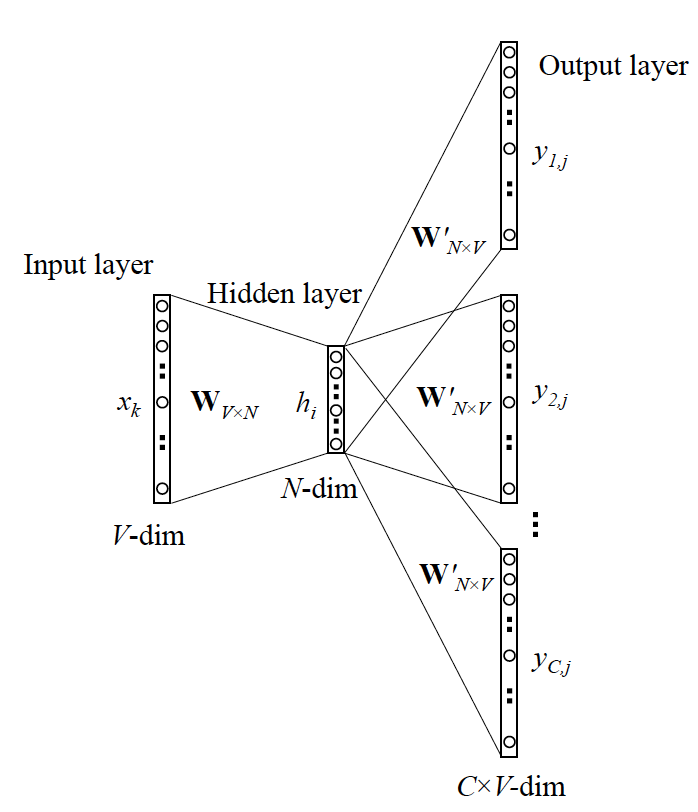
自然言語でよく使われる単語の分散表現を獲得する方法です.Word2VecはEncoder(Input layer → Hidden layer)とDecoder(Hidden layer → Output layer)からなります.
例えば「かわいい猫が歩く」みたいな文があった時,中心の単語「猫」を入力として,周辺単語「かわいい」と「歩く」を出力するように学習させます.
同様に「かわいい犬が歩く」のような文も使われますので,「犬」を入力として,周辺単語「かわいい」と「歩く」を出力するように学習させます.
これを繰り返していけば,Encoderでは「猫」と「犬」をなるべく近くに配置したほうが,正解してくれやすいと学習します.これがWord2Vecです.
プログラム
形態素解析
まずは文書を形態素解析します.形態素解析とは「かわいい猫が歩く」の文を「かわいい」「猫」「歩く」の単語ごとに分割することです.
MeCabなどが有名ですが,ここではJumanを使いました.
数字などは置き換え,長い文書でエラーがおきたのでそれらは排除しました.
sentences = []
for file_path in tqdm(file_list):
with open(file_path, 'r') as f:
lines = f.read()
lines = re.split(r'\n|。| | ', lines)
juman = Juman()
for line in lines:
if len(line) > 1000:
continue
r = []
word = re.sub(r'[,|。|.|、|\n| |[|]|\(|\)|【|】|注|△|「|」|]', '', line)
word = re.sub(r'[0年0月]', '', word)
word = re.sub(r'^\d', '', word)
word = re.sub(r'[0-9]+', '', word)
word = re.sub(r'\n', '', word)
word = re.sub(r' ', ' ', word)
result = juman.analysis(word)
for mrph in result.mrph_list():
if mrph.hinsi == "名詞" or mrph.hinsi == "形容詞":
if mrph.bunrui != "人名" and mrph.bunrui != "地名" and mrph.bunrui != "数詞":
word = mrph.genkei
word = re.sub(r'[0-9]+', '0', word)
r.append(word)
if len(r) <= 1:
continue
sentences.append(r)
sentencesにこんな感じにデータが分割されたと思います.

Word2Vec
Word2Vecライブラリのgensimを使用します.これはGPUを使用しませんが,マルチスレッドで実行して非常に高速です.
たったこれだけで実行ができます.パラメータはドキュメントのやつだったと思います.
model = word2vec.Word2Vec(sentences,
sg=1,
size=100,
min_count=5,
window=5,
negative=5,
iter=10)
結果
以下のコードで単語のcos類似度が高い単語を取り出すことができます.
model.wv.most_similar(positive=['車'], topn=10)


だいたいできてることが分かります.無い単語はエラーしますので注意してください.
まとめ
今回は決算情報をCoARiJから取り出し,Word2Vecを用いて単語の分散表現を獲得することをしました.今後は株価の予測や感情分析などをやっていけれたらなと思います.ありがとうございました.